MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。是一个可扩展、高性能,开源,无模式的分布式文档存储数据库。他支持的数据结构非常松散,是一种类似于json的格式叫BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
MongoDB是目前在IT行业非常流行的一种非关系型数据库(NoSQL),其灵活的数据存储方式备受当前IT从业人员的青睐。MongoDB很好的实现了面向对象的思想(OO思想),在MongoDB中每一条记录都是一个Document对象。MongoDB最大的优势在于所有的数据持久操作都无需开发人员手动编写SQL语句,直接调用方法就可以轻松的实现CRUD操作。
主要特点:
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- MongoDB安装简单。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=”Sameer”,Address=”8 Gandhi Road”)来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
业务场景
传统的关系型数据库Mysql,在数据操作的三高需求以及应对web2.0的网站需求面前,显得力不从心。
三高:High performance - 对数据库高并发读写的需求
- High Storage - 对海量的数据高效存储和访问的需求
- High Scalability && High Availability - 对数据库的高可扩展的高可用性的需求
具体的应用场景如:
- 1)社交场景,使用MongoDB存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
- 2游戏场景,使用MongoDB存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问。
- 3)物流场景,使用MongoDB存储订单信息,订单状态在运送过程中会不断更新,以MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
- 4)物联网场景,使用MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
- 5视频直播,使用MongoDB存储用户信息、点赞互动信息等。
什么时候使用Mongodb
在架构选型上,除了上述的三个特点外,如果你还犹豫是否要选择它?可以考虑以下的一些问题:
应用不需要事务及复杂join支持
新应用,需求会变,数据模型无法确定,想快速迭代开发
应用需要2000-3000以上的读写QPS(更高也可以)
应用需要TB甚至PB级别数据存储
应用发展迅速,需要能快速水平扩展
应用要求存储的数据不丢失
应用需要99.999%高可用
应用需要大量的地理位置查询、文本查询
如果上述有1个符合,可以考虑MongoDB,2个及以上的符合,选择MongoDB绝不会后悔。
体系结构
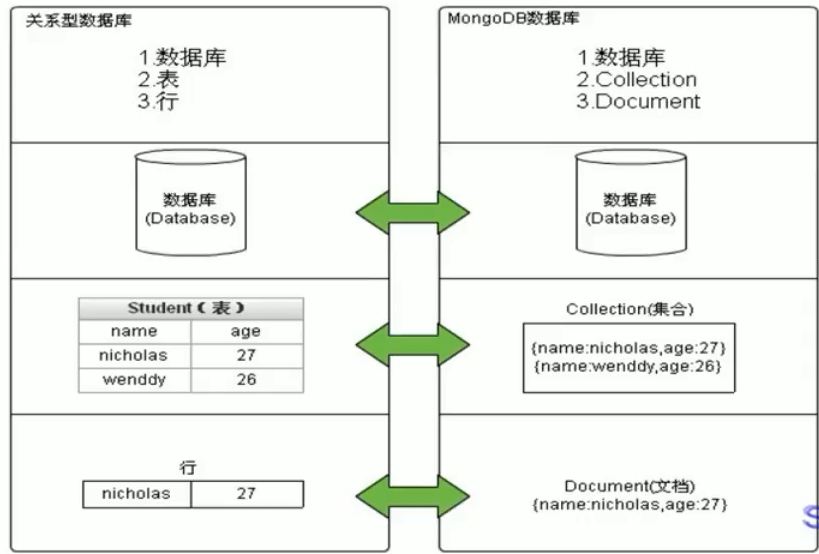
| SQL术语解释 | Mongodb术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| 嵌入文档 | MongoDB通过嵌入式文档来替代多表连接 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
数据类型
MongoDB的最小存储单位就是文档(document)对象。文档(document)对象对应于关系型数据库的行。数据在MongoDB中以 BSON(Binary-JSON)文档的格式存储在磁盘上。 BSON(Binary Serialized Document Format)是一种类json的一种二进制形式的存储格式,简称Binary JSON。BSON和JSON一样,支持 内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。 BSON采用了类似于 C 语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的三个特点,可 以有效描述非结构化数据和结构化数据。这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想。 Bson中,除了基本的JSON类型:string,integer,boolean,double,null,array和object,mongo还使用了特殊的数据类型。这些类型包括 date,object id,binary data,regular expression 和code。每一个驱动都以特定语言的方式实现了这些类型,查看你的驱动的文档来获取详 细信息。
安装MongoDB
MongoDB有多个安装版本,在官网即可下载。
https://www.mongodb.com/try/download/community 社区免费版下载链接
yum install libcurl openssl wget -y #安装所需工具
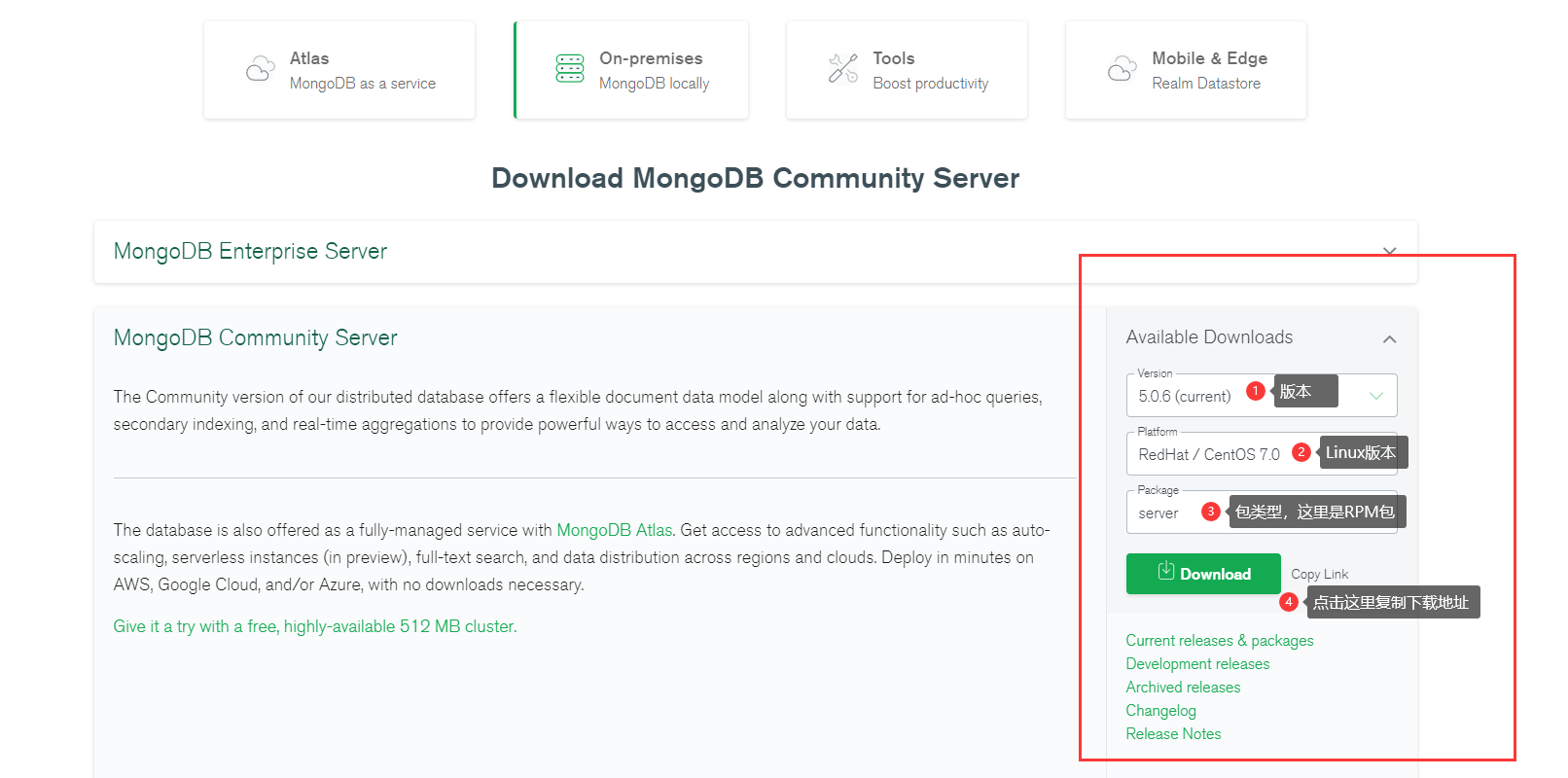
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-5.0.6.tgz#下载tar包,功能齐全,一次安全全部功能。
检查是否安装成功
#Mongodb启动后会初始化以下两个目录/var/lib/mongodb #数据存储目录/var/log/mongodb #日志文件目录mongod #输入命令查看是否有效mongod --dbpath /var/lib/mongo --logpath /var/log/mongodb/mongod.log --fork #启动mongodb服务mongod -f /etc/mongod.conf #启动mongodb服务tail -10f /var/log/mongodb/mongod.log #查看启动信息

MongoDB后台管理Shell
前面安装了server和shell版本,我们可以通过mongo命令,进入MongoDB自带的交互式JavaScript shell,用来对MongDB进行操作和管理的交互式环境。
mongo
由于它是一个JavaScript shell,您可以运行一些简单的算术运算:
安装Mongodb图形化界面
配置文件
vim /etc/mongod.confsystemLog:#MongoDB发送所有日志输出的目标指定为文件# #The path of the log file to which mongod or mongos should send all diagnostic logging informationdestination: file#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径path: /var/log/mongodb/mongod.log#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。logAppend: truestorage:#mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。##The directory where the mongod instance stores its data.Default Value is "/data/db".dbPath: /var/lib/mongojournal:#启用或禁用持久性日志以确保数据文件保持有效和可恢复。enabled: trueprocessManagement:#启用在后台运行mongos或mongod进程的守护进程模式。fork: truenet:#服务实例绑定的IP,默认是localhostbindIp: 127.0.0.1#bindIp#绑定的端口,默认是27017port: 27017
数据库常用命令
案例需求
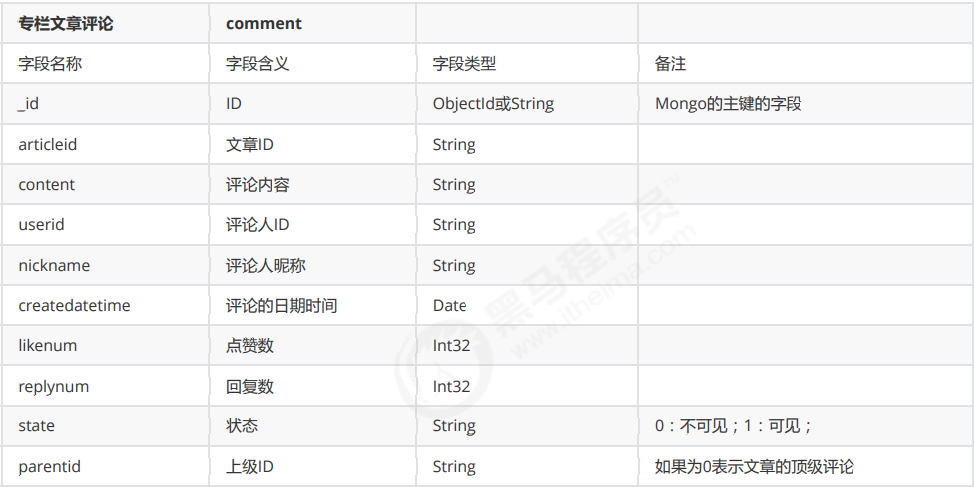
数据导入
下载数据包,文件夹名称一定要是dump,输入命令:
mongorestore#查询当前文件夹中是否有dump,并且将数据导入到数据库
查看/创建/删除数据库
查看与创建
show dbsshow databases#查看有权限查看的所有的数据库use 数据库名称#选择数据库,如果数据库不存在则自动创建use articledb#创建article数据库db#可以看到当前所在的数据库

数据库名创建规则
- 不能是空字符串(””)。
- 不得含有’ ‘(空格)、.、$、/、\和\0 (空字符)。
- 应全部小写。
- 最多64字节。
注意:Mongodb中,集合只有在内容插入后才会创建!此时就集合是保存在内存中的,除非有数据才被保存到磁盘中,也就是才会被真正创建。 MongoDB 中默认的数据库为 test,如果你没有选择数据库,集合将存放在 test 数据库中。
删除数据库
db.dropDatabase(数据库名称)#提示:主要用来删除已经持久化的数据库
自带的三个数据库
- admin:从权限的角度来看,这是”root”数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特 定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息
集合的创建与删除
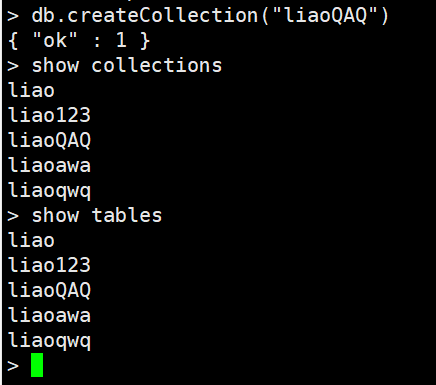
集合,类似关系型数据库中的表。 可以显示的创建,也可以隐式的创建。创建/查看集合
演示集合的显式创建 ```c db.createcollection(集合名称)在当前数据库中创建集合
show collections show tables
查看当前库中的表
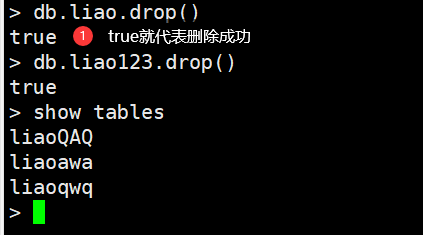
<br />**集合的命名规范: **- 集合名不能是空字符串""。- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。- 集合名不能以"system."开头,这是为系统集合保留的前缀。- 用户创建的集合名字不能含有保留字符。- 有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。- 除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。<a name="HagNU"></a>### 集合的删除```cdb.collection.drop()或db.集合.drop()#删除集合,当返回true就是删除成功
数据库的CRUD(增删改查)
文档(document)的数据结构和 JSON 基本一样。 所有存储在集合中的数据都是 BSON 格式。
文档的插入
单个文档插入
使用insert() 或 save() 方法向集合中插入文档,语法如下:
这里是隐式创建
db.comment.insert({"articleid":"100000","content":"今天天气真好","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null})#WriteResult({ "nInserted" : 1 })#和SQL类型的语法比较像,这样就插入一条数据。

提示:
1)comment集合如果不存在,则会隐式创建
2)mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了。
3)插入当前日期使用 new Date()
4)插入的数据没有指定 _id ,会自动生成主键值
5)如果某字段没值,可以赋值为null,或不写该字段。
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线”_”开头的键是保留的(不是严格要求的)。
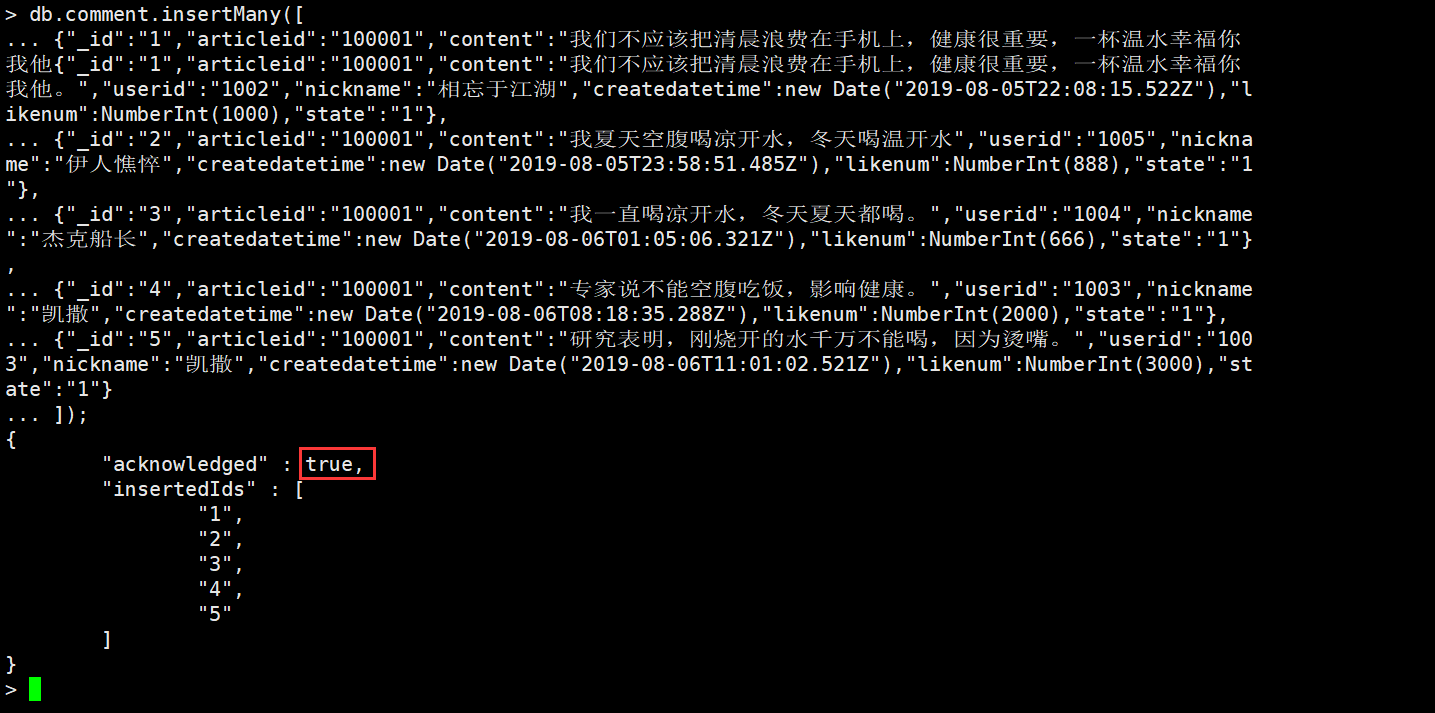
多个文档插入
db.comment.insertMany([{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}]);
提示:
插入时指定了 _id ,则主键就是该值。
如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。
因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理。如(了解):
try {db.comment.insertMany([{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08-05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08-06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}]);} catch (e) {print (e);}
文档的查询
#查询数据的语法格式如下:db.collection.find(<query>, [projection])
| 参数 | 类型 | 描述 |
|---|---|---|
| query | document | 可选。使用查询运算符指定选择筛选器。若要返回集合中的所有文档,请省略此参数或传递空文档 ( {} )。 |
| projection | document | 可 选。指定要在与查询筛选器匹配的文档中返回的字段(投影)。若要返回匹配文档中的所有字段, 请省略此参数。 |
查询所有
db.comment.find()或db.comment.find({})#查询comment表中全部的数据
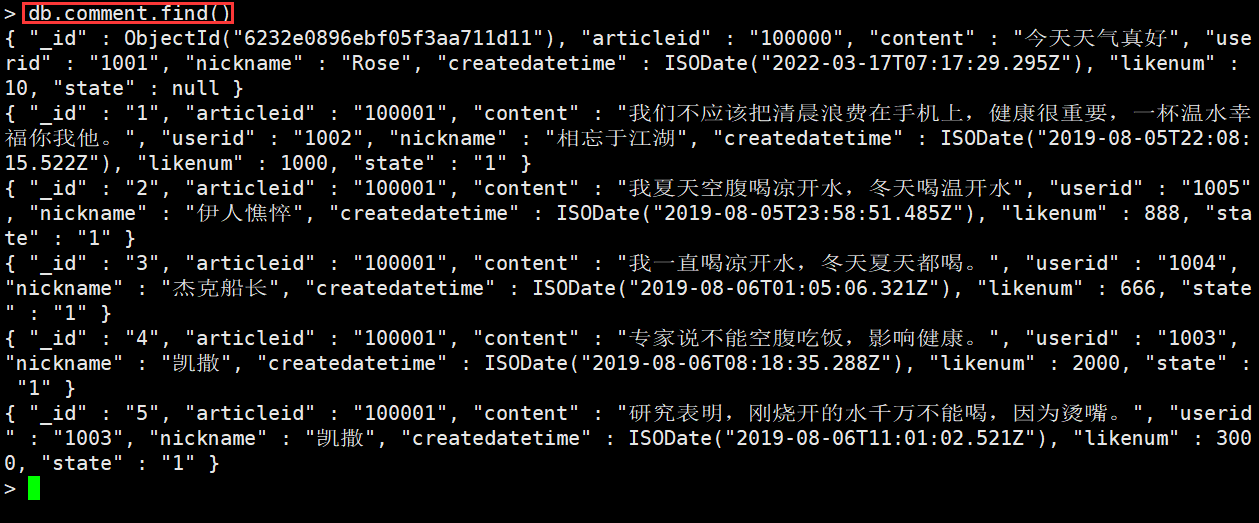
这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段, MongoDB会自动创建,其类型是ObjectID类型。
如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型。
条件查询
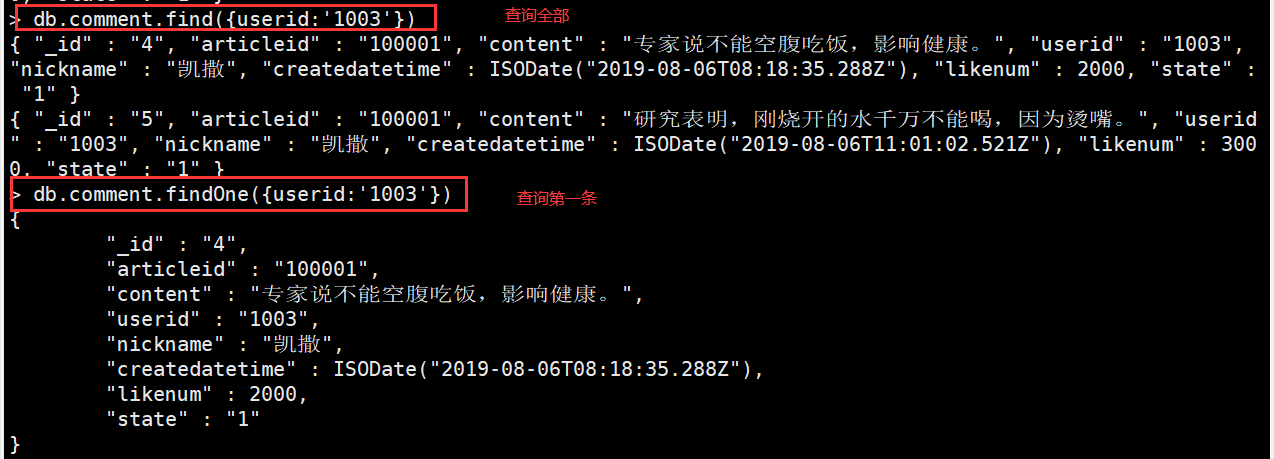
按照一定的条件进行查询
db.comment.find({userid:'1003'})#查询符合条件的记录,返回所有字段,并打印全部db.comment.findOne({userid:'1003'})#查询符合条件的记录,返回所有字段,只打印符合的第一条
投影查询
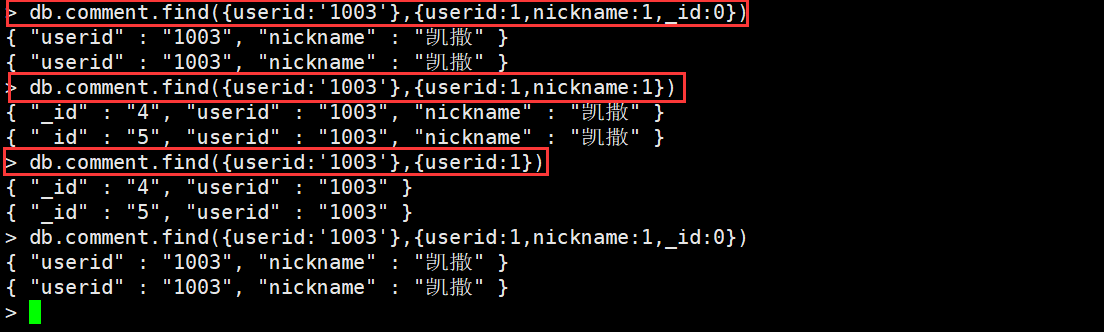
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。
db.comment.find({userid:'1003'},{userid:1})#查询符合条件的记录,并且只显示userid部分db.comment.find({userid:'1003'},{userid:1,nickname:1})#查询符合条件的记录,并且只显示userid和nickname部分#默认会显示_id,我们可以将它去掉db.comment.find({userid:'1003'},{userid:1,nickname:1,_id:0})db.comment.find({},{userid:1})#没有查询条件,只显示userid
后面的0和1,可以理解为false和true。为1时是显示,为0时是不显示
文档的更新修改
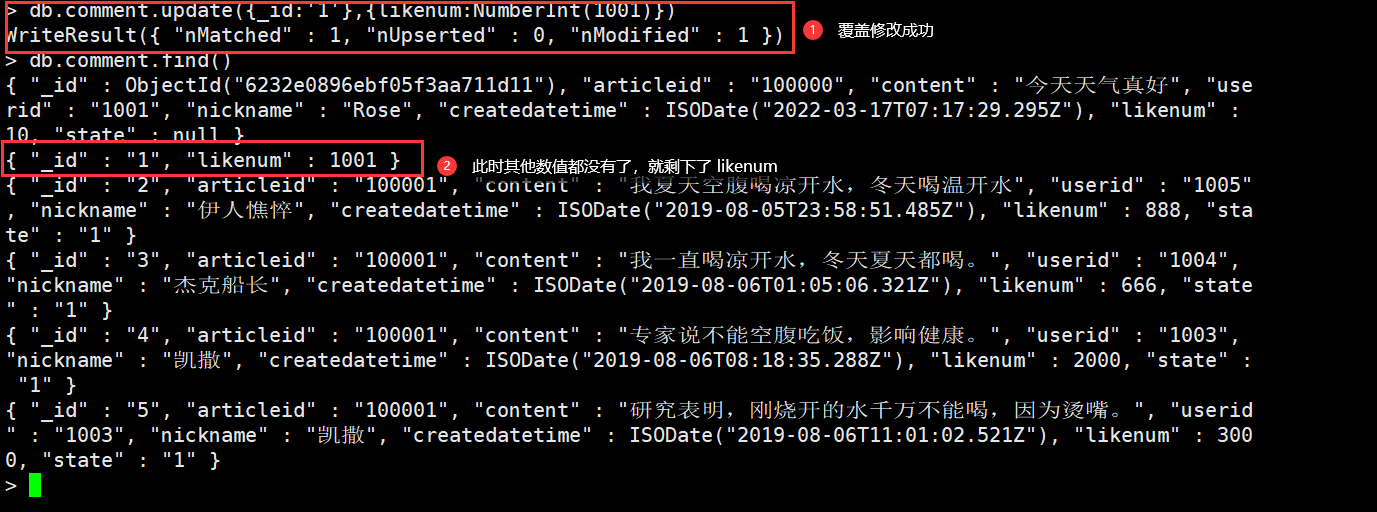
覆盖修改
将该文档中修改的记录全部覆盖式的修改
db.comment.update({_id:'1'},{likenum:NumberInt(1001)})#覆盖修改numberintdb.comment.find()#查询当前文档的全部记录
局部修改
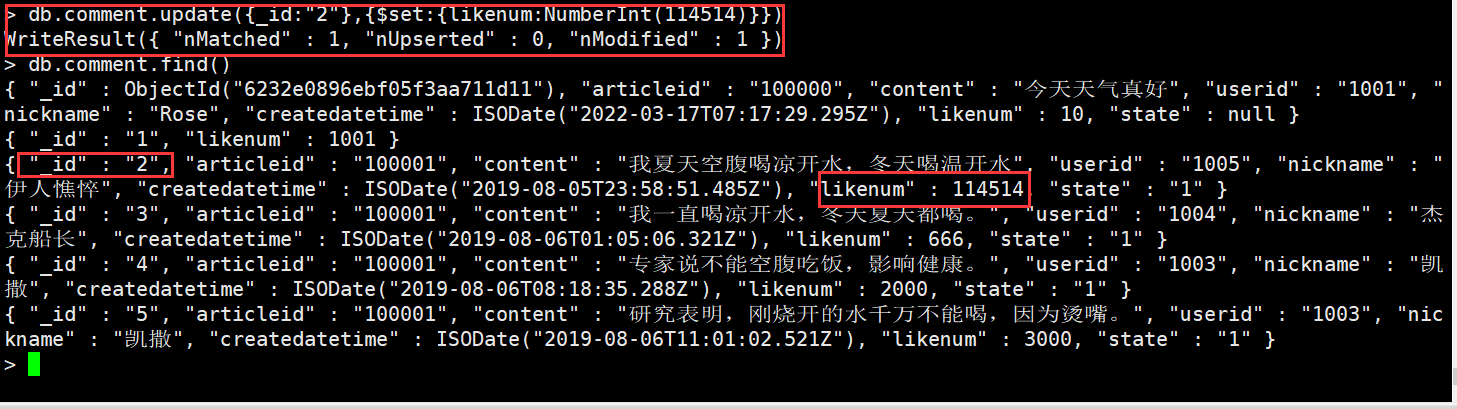
为了解决上面的问题,我们需要用到$set来实现
db.comment.update({_id:"2"},{$set:{likenum:NumberInt(114514)}})#局部修改,相对于覆盖修改多一个$set
批量修改
更新所有用户为 1003 的用户的昵称为 凯撒大帝 。
db.comment.update({userid:"1003"},{$set:{nickname:"凯撒大帝"}},{multi:true})#批量修改,需要多写一个{multi:true}#提示:如果不加后面的参数,则只更新符合条件的第一条记录
列值增长的修改
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 $inc 运算符来实现。
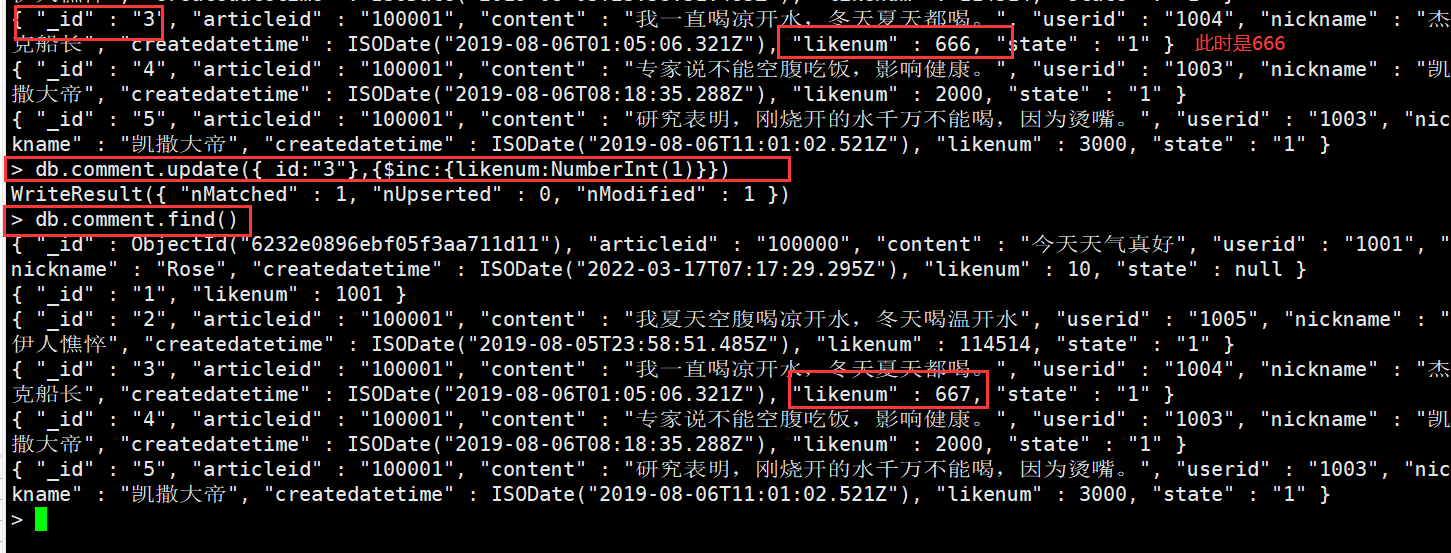
需求:对3号数据的点赞数,每次递增1
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})#对该数值进行自增 1
文档的删除
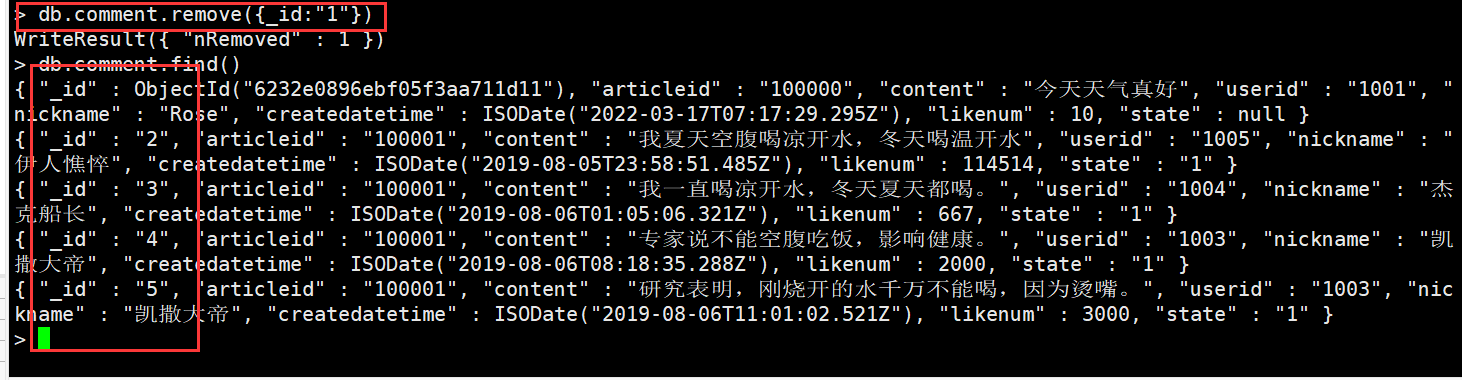
删除文档
db.comment.remove({})#将当前库中数据全部删除db.comment.remove({_id:"1"})#只删除_id=1的记录
文档的分页查询
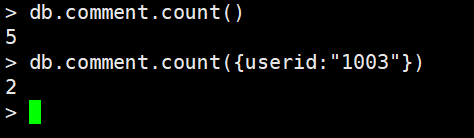
统计记录数量
db.comment.count()#查询所有数量db.comment.cout({userid:"1003"})#带有条件进行查询数量
count()方法默认情况下返回符合条件的全部记录条数
分页列表查询
可以使用limit()方法来读取指定数量的数据,使用skip()方法来跳过指定数量的数据。
db.comment.find().limit(3)#查询所有的记录,只返回前3条db.comment.find().skip(3)#查询所有的记录,不显示前3条
limit默认值是20,skip默认值是0


排序查询
sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用 于降序排列。
对userid降序排列,并对访问量进行升序排列
db.comment.find().sort({userid:-1,likenum:1})#-1时为降序,1时为升序
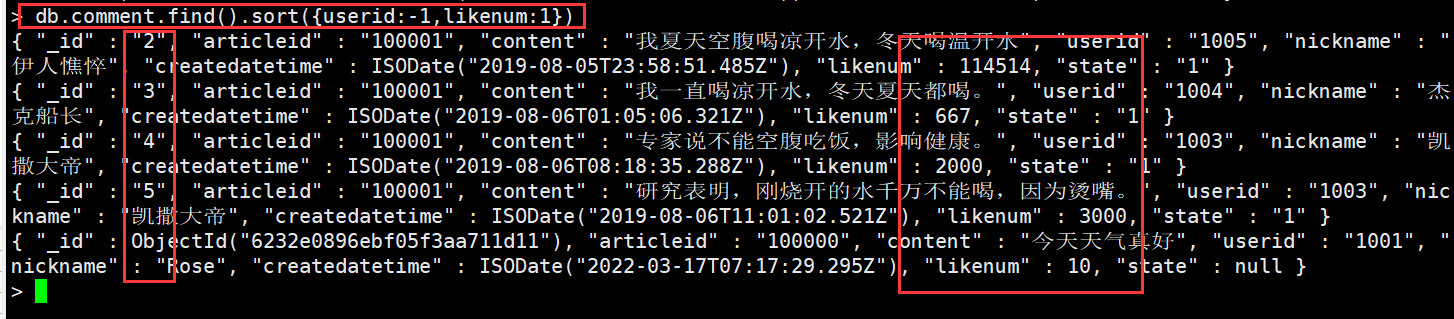
skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关。
文档的更多查询
正则查询
正则什么地位就不用多说了,正则能多好用多复杂,正则查询就有多好用,多复杂。
db.comment.find({content:/开水/})#查询评论内容包含“开水”的所有文档

比较查询
对于数值进行比较查询,不过不能用 > < >= <= 需要用 gt lt gte lte ne
$gt 大于$lt 小于$gte 大于等于$lte 小于等于$ne 不等于db.comment.find({likenum:{$gt:NumberInt(2000)}})#查询点赞数量大于2000的
包含查询
包含使用$in操作符。
不包含使用$nin操作符。
db.comment.find({userid:{$in:["1003","1004"]}})#查询评论的集合中userid字段包含1003或1004的文档db.comment.find({userid:{$nin:["1003","1004","1005"]}})#查询评论集合中userid字段不包含1003,1004和1005的文档
条件连接查询
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相当于SQL的and)
$and:[ { },{ },{ } ]
db.comment.find({$and:[{likenum:{$gt:NumberInt(500)}},{likenum:{$lte:NumberInt(3000)}}]})#查询评论集合中likenum大于等于500 并且小于3000的记录
如果两个以上条件之间是或者的关系,我们使用 操作符进行关联,与前面 and的使用方式相同
$or:[ { },{ },{ } ]
db.comment.find({$or:[{likenum:{$gt:NumberInt(200)}},{userid:{$gte:NumberInt(1003)}}]})#查询评论集合中likenum大于等于200 并且userid大于等于1003的记录
常用命令小结
选择切换数据库:use articledb插入数据:db.comment.insert({bson数据})查询所有数据:db.comment.find();条件查询数据:db.comment.find({条件})查询符合条件的第一条记录:db.comment.findOne({条件})查询符合条件的前几条记录:db.comment.find({条件}).limit(条数)查询符合条件的跳过的记录:db.comment.find({条件}).skip(条数)修改数据:db.comment.update({条件},{修改后的数据}) 或db.comment.update({条件},{$set:{要修改部分的字段:数据})修改数据并自增某字段值:db.comment.update({条件},{$inc:{自增的字段:步进值}})删除数据:db.comment.remove({条件})统计查询:db.comment.count({条件})模糊查询:db.comment.find({字段名:/正则表达式/})条件比较运算:db.comment.find({字段名:{$gt:值}})包含查询:db.comment.find({字段名:{$in:[值1,值2]}})或db.comment.find({字段名:{$nin:[值1,值2]}})条件连接查询:db.comment.find({$and:[{条件1},{条件2}]})或db.comment.find({$or:[{条件1},{条件2}]})
索引
索引概述
索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。 如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文档数。 索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排 序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
官网文档:https://docs.mongodb.com/manual/indexes/
MongoDB索引使用B树数据结构(确切的说是B-Tree,MySQL是B+Tree)
索引类型
单字段索引
MongoDB支持在文档的单个字段上创建用户定义的升序/降序索引,称为单字段索引(Single Field Index)。 对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引。 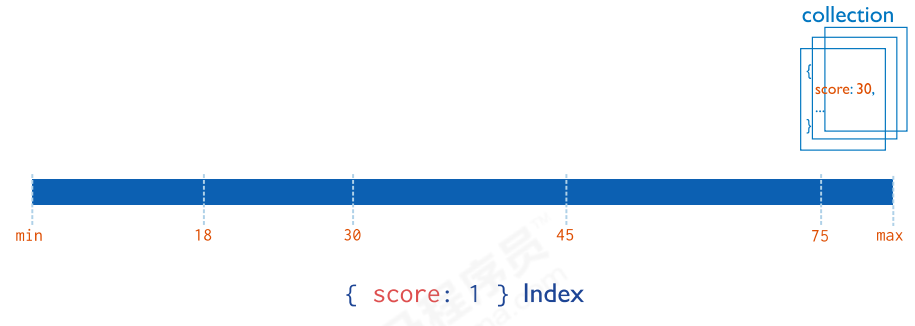
复合索引
MongoDB还支持多个字段的用户定义索引,即复合索引(Compound Index)。 复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由 { userid: 1, score: -1 } 组成,则索引首先按userid正序排序,然后 在每个userid的值内,再在按score倒序排序。 
其他索引
地理空间索引(Geospatial Index)、文本索引(Text Indexes)、哈希索引(Hashed Indexes)。
地理空间索引(Geospatial Index)
为了支持对地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:返回结果时使用平面几何的二维索引和返回结果时使用球面 几何的二维球面索引。
文本索引(Text Indexes)
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如“the”、“a”、“or”), 而将集合中的词作为词干,只存储根词。
哈希索引(Hashed Indexes)
为了支持基于散列的分片,MongoDB提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内的值分布更加随机,但只支 持相等匹配,不支持基于范围的查询。
索引的操作
索引的查看
返回一个集合中的所有索引的数组。
db.comment.getIndexes()#查看索引
我们现在没有创建任何索引,但是还是查到一个。因为这个索引比较特殊,是系统自动给你创建的,并且无法删除
索引的创建
在集合上创建索引。
db.comment.createIndex({userid:1})#单字段索引db.comment.createIndex({userid:1,nickname:-1})#复合索引
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex() ,之后的版本使用了 db.collection.createIndex() 方法, ensureIndex() 还能用,但只是 createIndex() 的别名。
参数:
| Parameter | Type | Description |
|---|---|---|
| keys | document | 包含字段和值对的文档,其中字段是索引键,值描述该字段的索引类型。对于字段上的升序索引,请 指定值1;对于降序索引,请指定值-1。比如: {字段:1或-1} ,其中1 为指定按升序创建索引,如果你 想按降序来创建索引指定为 -1 即可。另外,MongoDB支持几种不同的索引类型,包括文本、地理空 间和哈希索引。 |
| options | document | 可选。包含一组控制索引创建的选项的文档。有关详细信息,请参见选项详情列表。 |
options(更多选项)列表:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名 称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索 引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
索引的删除
说明:可以移除指定的索引,或移除所有索引
db.comment.dropIndex({userid:1})#删除单个索引。在括号内部,创建时写的什么,删除时就写什么。.db.comment.dropIndexes()#删除当前表全部索引。括号内什么都不用写。
提示: _id 的字段的索引是无法删除的,只能删除非 _id 字段的索引。

若有收获,就点个赞吧
0 人点赞
