awk
取列 统计计算
awk 是一个处理文本的编程语言工具,能用简短的程序处理标准输入或文件、数据排序、计算以及 生成报表等等。
在 Linux 系统下默认 awk 是 gawk,它是 awk 的 GNU 版本。可以通过命令查看应用的版本:ls -l /bin/awk 基本的命令语法:awk option ‘pattern {action}’ file
其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。 花括号用于根据特定的模式对一系列指令进行分组。
awk 处理的工作方式与数据库类似,支持对记录和字段处理,这也是 grep 和 sed 不能实现的。 在 awk 中,缺省的情况下将文本文件中的一行视为一个记录,逐行放到内存中处理,而将一行中的 某一部分作为记录中的一个字段。用 1,2,3…数字的方式顺序的表示行(记录)中的不同字段。用 $后跟数字,引用对应的字段,以逗号分隔,0 表示整个行。
支持的选项
| 选项 | 描述 |
|---|---|
| -f program-file | 从文件中读取 awk 程序源文件 |
| -F fs | 指定 fs 为输入字段分隔符 |
| -v var=value | 变量赋值 |
| —posix | 兼容 POSIX 正则表达式 |
| —dump-variables=[file] | 把 awk 命令时的全局变量写入文件, 默认文件是 awkvars.out |
| —profile=[file] | 格式化 awk 语句到文件,默认是 awkprof.out |
支持的模式
| 模式 | 描述 |
|---|---|
| BEGIN{ } | 给程序赋予初始状态,先执行的工作 |
| END{ } | 程序结束之后执行的一些扫尾工作 |
| /regular expression/ | 为每个输入记录匹配正则表达式 |
| pattern && pattern | 逻辑 and,满足两个模式 |
| pattern || pattern | 逻辑 or,满足其中一个模式 |
| ! pattern | 逻辑 not,不满足模式 |
| pattern1, pattern2 | 范围模式,匹配所有模式 1 的记录,直到匹配到模式 2 |
而动作呢,就是下面所讲的 print、流程控制、I/O 语句等。
内置变量
| 变量名 | 描述 |
|---|---|
| FS | 输入字段分隔符,默认是空格或制表符 |
| OFS | 输出字段分隔符,默认是空格 |
| RS | 输入记录分隔符,默认是换行符\n |
| ORS | 输出记录分隔符,默认是换行符\n |
| NF | 统计当前记录中字段个数 也能当做最后一行 |
| NR | 统计记录编号,每处理一行记录,编号就会+1 |
| FNR | 统计记录编号,每处理一行记录,编号也会+1,与 NR 不同的是,处理第二个 文件时,编号会重新计数。 |
| ARGC | 命令行参数数量 |
| ARGV | 命令行参数数组序列数组,下标从 0 开始,ARGV[0]是 awk |
| ARGIND | 当前正在处理的文件索引值。第一个文件是 1,第二个文件是 2,以此类推 |
| ENVIRON | 当前系统的环境变量 |
| FILENAME | 输出当前处理的文件名 |
| IGNORECASE | 忽略大小写 |
| SUBSEP | 数组中下标的分隔符,默认为”\034” |
示例1:
1.从文件读取awk程序处理文件
# vi test.awk{print $2}# tail -n3 /etc/services |awk -f test.awk48049/tcp48128/tcp49000/tcp
2.指定分隔符,打印指定字段
默认以空格分隔
打印第二字段,默认以空格分隔:tail -n3 /etc/services |awk '{print $2}'指定冒号为分隔符打印第一段awk -F ':' '{print $1}' /etc/passwd指定多个分隔符作为同一个分隔符处理tail -n3 /etc/services |awk -F'[/#]' '{print $3}'tail -n3 /etc/services |awk -F'[/#]' '{print $1}'tail -n3 /etc/services |awk -F'[/#]' '{print $2}'tail -n3 /etc/services |awk -F'[/#]' '{print $3}'tail -n3 /etc/services |awk -F'[ /]+' '{print $2}'
[]元字符的意思是符号其中任意一个字符,也就是说每遇到一个/或#时就分隔一个字段,当用多个 分隔符时,就能更方面处理字段了。
取出指定行的某列内容
tail /etc/services | awk 'NR==2{print $2}' | column -t #使文本对其#取出第二行 第二列的内容
交换内容位置并修改分隔符
awk -F":" -vOFS=- '{print $NF,$2,$4,$6}' /etc/passwd#设置分隔符为: 设置显示的分隔符为 - 打印输出
取出IP地址
ip a s enp7s0 | awk -F"[/ ]+" 'NR==3{print $3}'
3.变量赋值
awk -v a=123 'BEGIN{print a}'系统变量作为 awk 变量的值:a=123awk -v a=$a 'BEGIN{print a}'
4.输出awk全局变量到文件
seq 5 |awk --dump-variables '{print $0}'
5.BEGIN和END
| 模式 | 含义 | 应用场景 |
|---|---|---|
| BEGIN{} | 里面的内容会在awk读取文件之前执行 | 1.进行简单的统计,计算,不涉及读取文件 2.用来处理文件之前,添加一个表头 3.用来定义awk变量 |
| END{} | 里面的内容会在awk读取文件之后执行 | 1.awk进行统计,一般过程:先进行计算,最后END里面输出结果 2.awk使用数组,用来输出数组结果 |
BEGIN 模式是在处理文件之前执行该操作,常用于修改内置变量、变量赋值和打印输出的页眉或标 题。 例如:打印页眉
tail /etc/services |awk 'BEGIN{print "Service\t\tPort\t\t\tDescription\n==="}{print $0}'
END模式是在程序处理完才会执行。 例如:打印页尾
tail /etc/services |awk '{print $0}END{print "===\nEND......"}'
统计文件中有多少个空行
awk '/^$/{i++}END{print i}' /etc/services
计算某一列的总和
seq 100 | awk '{sum=sum+$1}END{print sum}'
6.格式化输出awk命令到文件
同时打印输出页眉和页尾
tail /etc/services |awk --profile 'BEGIN{print"Service\t\tPort\t\t\tDescription\n==="}{print $0}END{print "===\nEND......"}'
7./re/正则匹配
| 正则 | awk正则 | 指令 |
|---|---|---|
| ^ 表示以…开头的行 | 某一列的开头 | $3~/^liao/ |
| $ 表示以…结尾的行 | 某一列的结尾 | $3~/aa$/ |
| ^$ 表示空行 | 某一列是空 |
匹配包含 tcp 的行:
tail /etc/services |awk '/tcp/{print $0}'
匹配开头是 blp5 的行:
tail /etc/services |awk '/^blp5/{print $0}'
匹配第一个字段是 8 个字符的行:
tail /etc/services |awk '/^[a-z0-9]{8} /{print $0}'
如果没有匹配到,请查看你的 awk 版本(awk —version)是不是 3,因为 4 才支持{}
找出第3列以2开头的行,并显示第1列,第3列 最后一列
awk -F":" '$3~/^2/ {print $1 $2 $NF}' /etc/passwd
8.逻辑and or 和 not
匹配记录中包含 blp5 和 tcp 的行:
tail /etc/services |awk '/blp5/ && /tcp/{print $0}'
匹配记录中包含 blp5 或 tcp 的行:
tail /etc/services |awk '/blp5/ || /tcp/{print $0}'
不匹配开头是#和空行:
awk '! /^#/ && ! /^$/{print $0}' /etc/httpd/conf/httpd.confawk '! /^#|^$/' /etc/httpd/conf/httpd.confawk '/^[^#]|"^$"/' /etc/httpd/conf/httpd.conf
9.匹配范围
显示指定时间范围内的IP
awk '/11:20:00/,/11:25:00/{print $1}'
tail /etc/services |awk '/^blp5/,/^com/'
对匹配范围后记录再次处理,例如匹配关键字下一行到最后一行:
seq 5 |awk '/3/,/^$/{printf /3/?"":$0"\n"}'另一种判断真假的方式实现:seq 5 |awk '/3/{t=1;next}t'
1 和 2 都不匹配 3,不执行后面{},执行 t,t 变量还没赋值,为空,空在 awk 中就为假,就不打印 当前行。匹配到 3,执行 t=1,next 跳出,不执行 t。4 也不匹配 3,执行 t,t 的值上次赋值的 1, 为真,打印当前行,以此类推。(非 0 的数字都为真,所以 t 可以写任意非 0 数字) 如果想打印匹配行都最后一行,就可以这样了:
seq 5 |awk '/3/{t=1}t'
10.awk数组
- 统计日志
- 统计IP出现次数
- 统计每种状态码出现次数
- 统计用户被攻击的次数
- 统计攻击者IP出现次数
- 统计每个ip消耗的流量
awk中,字母会被识别为变量,如果只是想使用字符串需要使用双引号引起来
| shell数组 | awk数组 | |
|---|---|---|
| 形式 | array[0]=oldboy0 array[1]=oldboy1 |
array[0]=oldboy0 array[1]=lodboy1 |
| 使用 | echo ${array[0]} ${array[1]} |
print array[0] array[1] |
| 批量输出 | for i in ${array[*]} do echo $i done |
for(i in array) print i,array[i] 此时i输出的是数组下标 |
打印awk数组
awk 'BEGIN{a[0]="qwq";a[1]="awa"; for(i in a) print a[i]}'
计算数组数量
awk -F"[/.]+" '{array[$2]++}END{for(i in array)print i,arry[i]}' url.txt
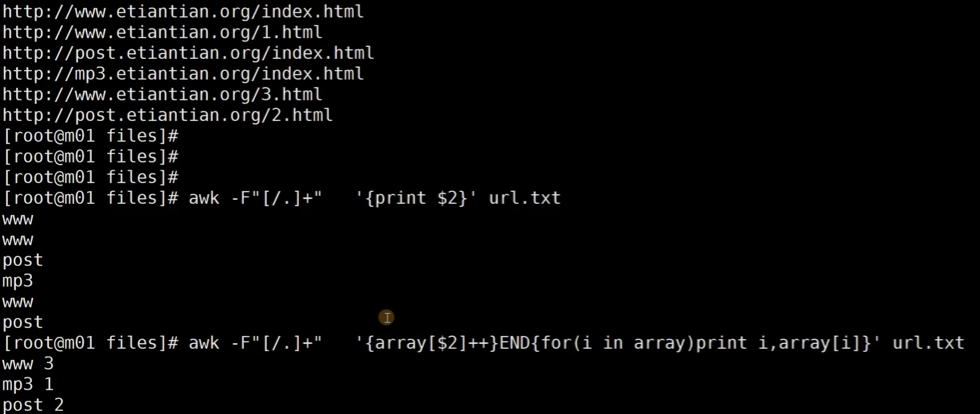
array[]++ 你要统计什么,里面就装什么
array[www]++ 3
array[post]++ 2
array[mp3]++ 1
计算日志中状态码数量
awk '$4~/[0-9][0-9][0-9]/{array[$4]++}END{for(i in arrayprint i,arry[i])}' httpd.log
内置变量
FS和OFS
在程序开始前重新赋值 FS 变量,改变默认分隔符为冒号,与-F 一样。
awk 'BEGIN{FS=":"}{print $1,$2}' /etc/passwd |head -n5#也可以使用-v 来重新赋值这个变量:awk -vFS=':' '{print $1,$2}' /etc/passwd |head -n5 # 中间逗号被换成了 OFS 的默认值#由于 OFS 默认以空格分隔,反向引用多个字段分隔的也是空格,如果想指定输出分隔符这样awk 'BEGIN{FS=":";OFS=":"}{print $1,$2}' /etc/passwd |head -n5
取行
NR
awk 'NR>=2 && NR<=5' data7.txt #取出文件中的2到5行
取列
-F 指定分隔符即可
11.if判断
df -h | awk -F"[ ]+" '{if($5>=15) print $5,$6}' #如果磁盘空间大于15%则显示挂载位置和挂载百分比
查询一段文字,单词字母数量是否大于4个
echo I am maliao I like linux and centos! | awk -F"[! ]" '{for(i=1;i<=NF;i++) if(length($i)>=4) print $i}'

若有收获,就点个赞吧
0 人点赞
