ELK:ES
ES下载与安装
ES简称:全文检索服务,分布式搜索引擎服务
官网:开源搜索:Elasticsearch、ELK Stack 和 Kibana 的开发者 | Elastic
下载地址:Download Elasticsearch | Elastic
只需要在下载界面,下载指定系统的安装包即可!
注意:ELK需要JDK为11的工具包,在下载时,会一并下载JDK11的工具包,如果你当前已经有11以上的工具包了,则无任何影响。如果你没有,会默认使用包里的JDK11。

windows的安装:
直接下载,解压即可!
/bin目录下的 双击elasticsearch.bat,即可开启服务。

Linux安装:
下载tar.gz,但是不能用root用户进行解压运行的操作,可以自己添加一个用户
useadd liao123 #添加用户passwd 123456 #设置密码tar -zxf elasticsearch-7.16.3-linux-x86_64.tar.gz #解压
解压完成后,目录如下:

并且Linux同理,没有JDK11的话也会使用文件夹中的JDK。
- bin:启动ES服务脚本目录
- config:ES配置文件的目录
- data:ES的数据存放目录
- jdk:ES提供需要指定的jdk目录
- lib:ES依赖第三方库的目录
- logs:ES的日志文件
- modules:模块的目录
- plugins:插件目录
ES的启动
进入bin目录下,看他的文件:
./elasticsearch #启动服务./elasticsearch -d #后台启动服务ps aux | grep elastic #查找进程,使用kill即可杀死进程
此时就启动服务了。
我们再开一个终端使用命令来查看服务是否正常启动
netstat -ntlp #查看端口curl http://localhost:9200 #查看网页
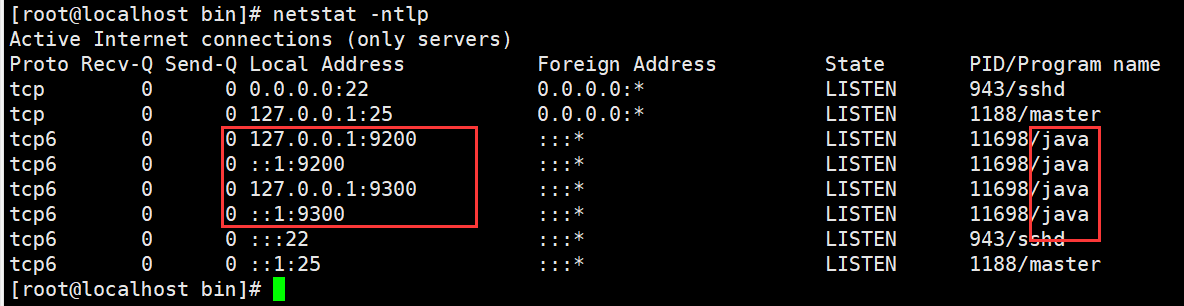
此时出现四个java进程,有9200和9300端口

curl命令使用过后,出现以下字符,则开启正常。
开启远程连接方式
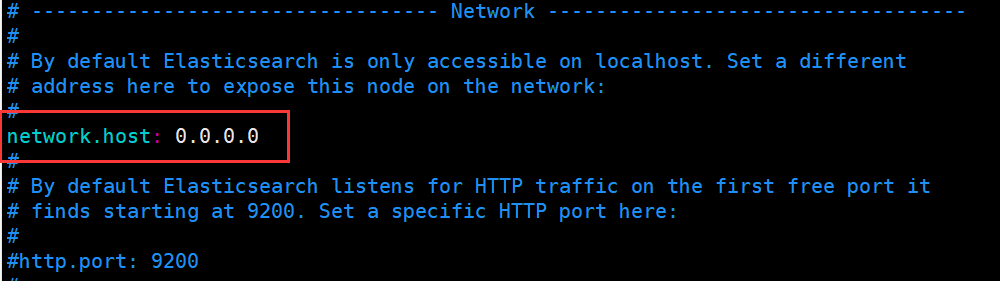
1.进入配置文件修改配置
vim config/elasticsearch.yml #进入该文件
将此处改为0.0.0.0
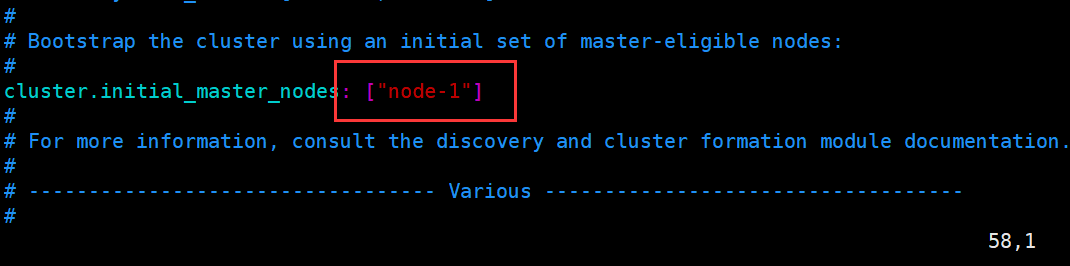
2.修改为非集群模式
将node-2去掉,仅剩下node-1
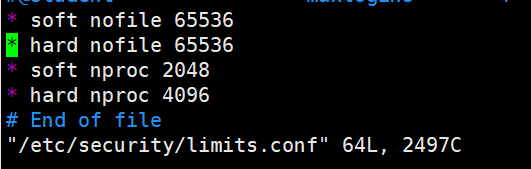
3.修改内存配置
vim /etc/security/limits.conf #shell#添加以下配置
然后停止已经开启的服务,重新登录该非管理员账号,然后再次启动!即可。
使用命令或者直接进入网页进行查看
curl http://localhost:9200http://192.168.200.132:9200
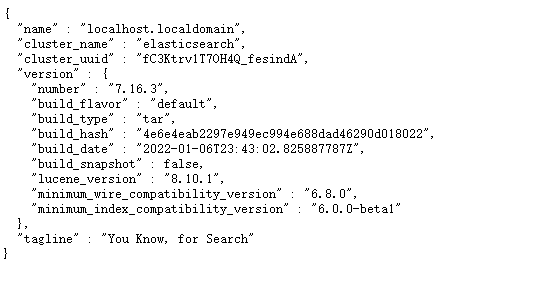
此时就打开了远程连接
ES的docker安装
docker服务的安装:CentOS Docker 安装 | 菜鸟教程 (runoob.com)
systemctl start docker #启动dockerdocker pull elasticsearch:7.14.0 #拉取镜像docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.14.0 #启动镜像#run 启动镜像#-p 指定宿主机和容器的端口映射#-d 后台运行#-e "discovery.type=single-node" #以单节点方式运行/单击模式运行
此时就启动服务了可以通过指令查看
docker ps #查看正在运行的容器服务
浏览器 IP+端口 进入查看是否有信息。有了即为运行成功。
ELK:Kibana
Kibaan是一个针对Elasticsearch 的开源分析以及可视化平台,使用kibana可以查询查看并与存储在ES索引的数据进行交互,使用kibana能执行高级的数据分析并能以图表,表格和地图的形式查看数据
Kibana安装与启动
1.到官网下载Download Kibana Free | Get Started Now | Elastic
2.以普通用户的权限上传/解压文件
tar -zxf kibana-7.16.3-linux-x86_64.tar.gz
3.修改配置
vim 安装目录/config/kibana.yml#修改server.host和elasticsearch.hosts

4.启动kibana
./bin/kibana #运行服务
5.网页进入查看
IP:5601/app/home
点击Explore on my own
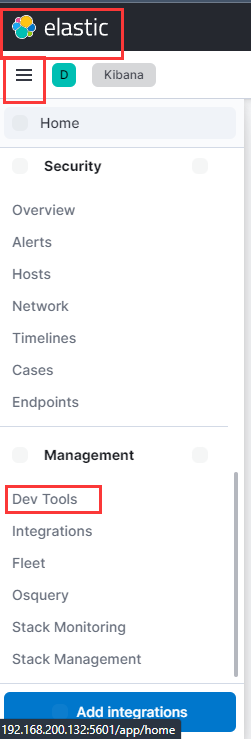
6.进入Dev tools
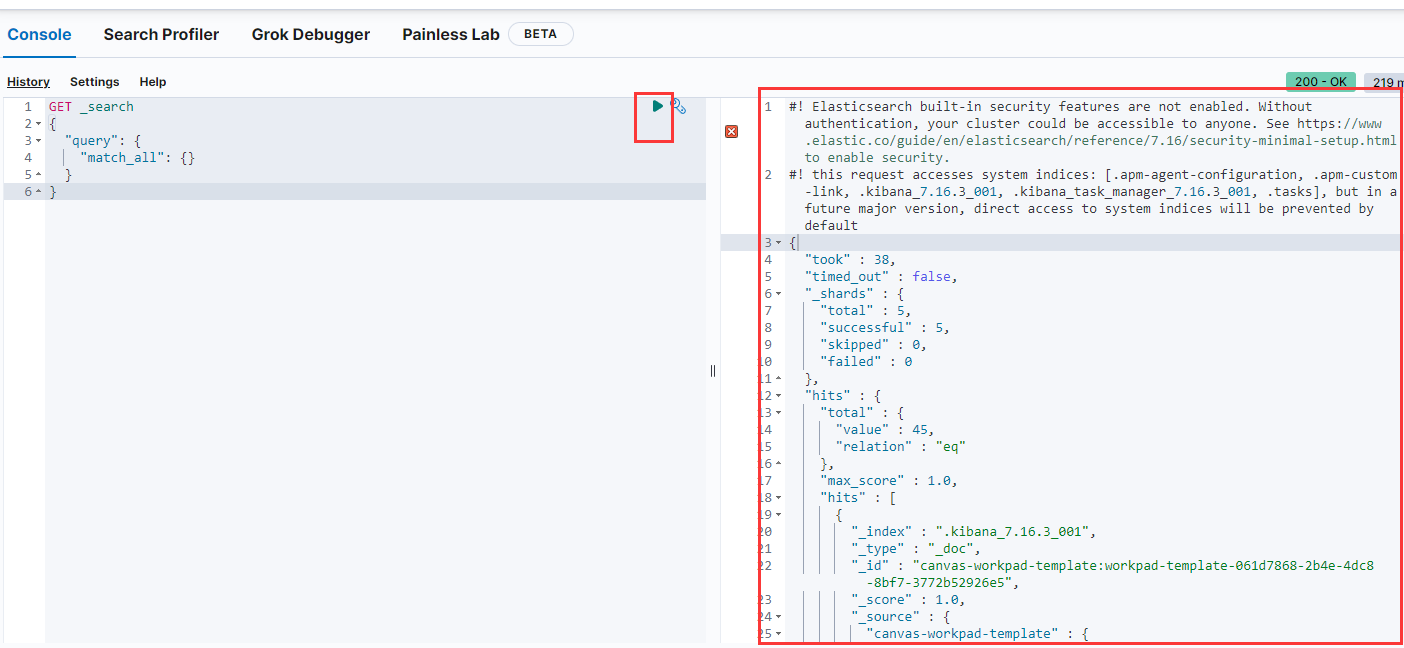
7.点击绿色按钮,出现右面的字符则开启成功
Kibana的docker安装
1.首先先给传统安装的服务关闭,然后拉取Kinbana
docker pull kibana:7.14.0
2.运行启动Kibana容器
docker run -d --name Kibana -p 5601:5601 kibana:7.14.0
3.进入Kibana进行配置
docker exec -it 48de2e51fc730f /bin/bash #通过bash进入容器内vi config/kibana.yml #进入容器内后,编辑配置文件#将IP填写为你服务器的IP,保存退出
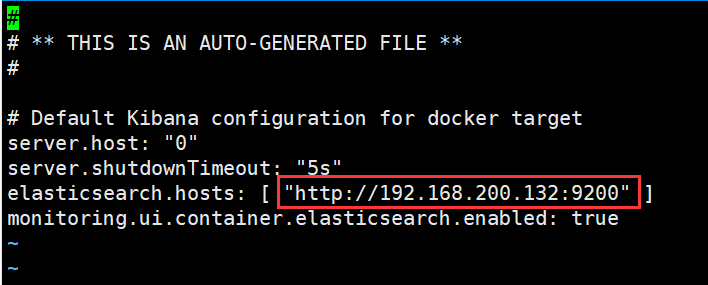
4.重启并查看是否启动成功
进入网页并且进入Dev tools 查看是否有结果。
Kibana数据卷免配置
上面的我们启动Kibana容器后,还需要再进入容器修改配置。我们使用docker的数据卷功能,设置映射文件即可。
1.复制出来配置文件
docker cp 82b8e331248fcbcae:/usr/share/kibana/config/kibana.yml .#复制该容器中的指定文件到宿主机的当前目录下。docker rm -f 82b8e331248fcbcae #删除之前打开的容器
2.映射文件
docker run -d --name Kibana -p 5601:5601 -v /root/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.14.0#-v 数据卷映射文件 将容器的文件以宿主机当前的文件进行映射 记得要写绝对路径
3.查看是否能打开网页即可
ELK:compose安装
docker-compose让我们所有的服务以项目的方式结合在一起。使得服务可以一键启动。
1.首先删除前两个容器
docke rm -f 容器ID
2.创建docker-compose文件
version: "3.8"volumes:data:config:plugin:networks:es:services:elasticsearch:image: elasticsearch:7.14.0ports:- "9200:9200"- "9300:9300"networks:- "es"environment:- "discovery.type=single-node"- "ES_JAVA_OPTS=-Xms512m -Xmx512m"volumes:- data:/usr/share/elasticsearch/data- config:/usr/share/elasticsearch/config- ./ik-7.14.0:/usr/share/elasticsearch/pluginskibana:image: kibana:7.14.0ports:- "5601:5601"networks:- "es"volumes:- /root/kibana.yml:/usr/share/kibana/config/kibana.yml
Postman客户端工具
前面安装了kibana就是官网的获取请求的工具,当然也有非官方的的请求工具。Postman是一款强大的网页调试工具,提供了强大的webapi和http请求调试。软件功能强大界面简介。
ELK:ES集群的概念
集群
一个集群就是由一个或多个节点组织在一起。或是由同一个多个服务器运行同一个软件。它们共同拥有整个数据,并一起为你提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字就是默认elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字来加入这个集群。
节点
一个节点是集中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。
索引
一组相似文档的集合
映射
用来定义索引存储文档的结构,如:字段,类型等。
文档
索引中的一条记录,可以被索引的最小单元。
分片
Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引“可以被放置到集群中的任何节点上。
复制
index的分片中的一份和多份的副本。
集群的搭建
集群规划
1.准备三个节点
- 注意
- 所有节点集群名称必须一致 cluster.name
- 每个节点必须有一个唯一的名字 node.name
- 开启每个节点的远程连接 network.host:0.0.0.0
- 指定集群中所有节点通信列表 discover.seed_hosts: node-1 node-2 node-3 相同
- 允许集群初始化master节点节点数:
- 集群最少几个节点可用
- 开启每个节点跨域访问
elasticsearch.yml文件编写
#指定集群名称cluster.name: es-cluster#指定节点名称,每个节点名字唯一node.name: node-1#开放远程连接network.host: 0.0.0.0#指定使用发布地址进行集群间的通信network.publish_host: 192.168.200.132#指定web端口http.port: 9201#指定tcp端口transport.tcp.port: 9301#指定所有节点的tcp通信discovery.seed_hosts: ["192.168.200.132:9301","192.168.200.132:9302","192.168.200.132:9303"]#指定可以初始化集群的节点名称cluster.initial_master_nodes: ["node-1","node-2","node-3"]#集群最少几个节点可用getway.recover_after_nodes: 2#解决跨域问题http.cors.enabled: truehttp.cors.allow-origin: "*"
Windows集群搭建
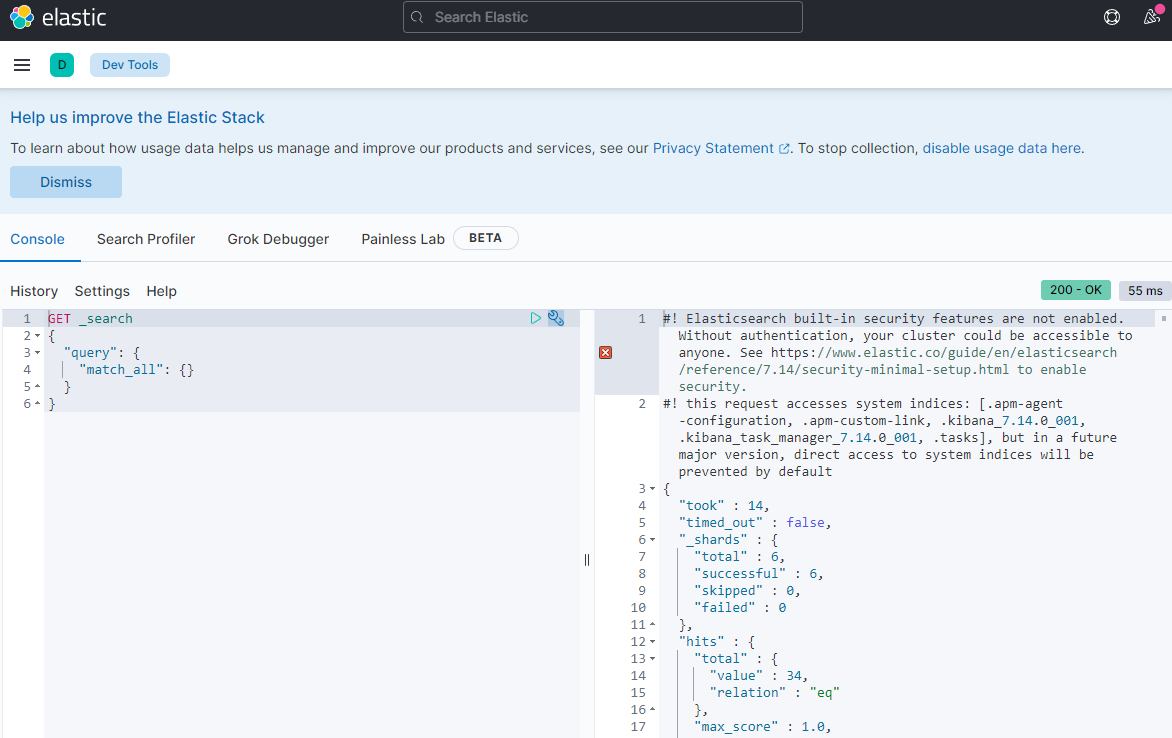
下载解压elasticsearch,并且复制三份。
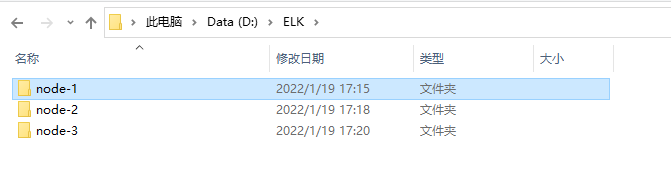
进入node文件夹,config文件夹,进入elasticsearch.yml中进行配置:
node-1:
#节点 1 的配置信息:#集群名称,节点之间要保持一致cluster.name: my-elasticsearch#节点名称,集群内要唯一node.name: node-1001node.master: truenode.data: true#ip 地址network.host: localhost#http 端口http.port: 1001#tcp 监听端口transport.tcp.port: 9301#discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]#discovery.zen.fd.ping_timeout: 1m#discovery.zen.fd.ping_retries: 5#集群内的可以被选为主节点的节点列表#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]#跨域配置#action.destructive_requires_name: truehttp.cors.enabled: truehttp.cors.allow-origin: "*"
node-2:
#节点 2 的配置信息:#集群名称,节点之间要保持一致cluster.name: my-elasticsearch#节点名称,集群内要唯一node.name: node-1002node.master: truenode.data: true#ip 地址network.host: localhost#http 端口http.port: 1002#tcp 监听端口transport.tcp.port: 9302discovery.seed_hosts: ["localhost:9301"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5#集群内的可以被选为主节点的节点列表#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]#跨域配置#action.destructive_requires_name: truehttp.cors.enabled: truehttp.cors.allow-origin: "*"
node-3:
#节点 3 的配置信息:#集群名称,节点之间要保持一致cluster.name: my-elasticsearch#节点名称,集群内要唯一node.name: node-1003node.master: truenode.data: true#ip 地址network.host: localhost#http 端口http.port: 1003#tcp 监听端口transport.tcp.port: 9303#候选主节点的地址,在开启服务后可以被选为主节点discovery.seed_hosts: ["localhost:9301", "localhost:9302"]discovery.zen.fd.ping_timeout: 1mdiscovery.zen.fd.ping_retries: 5#集群内的可以被选为主节点的节点列表#cluster.initial_master_nodes: ["node-1", "node-2","node-3"]#跨域配置#action.destructive_requires_name: truehttp.cors.enabled: truehttp.cors.allow-origin: "*"
从node1到3逐个启动bin/elasticsearch.bat。
查询集群情况GET http://127.0.0.1:1001/_cluster/health
Linux集群搭建①
1.创建三个虚拟机,并且配置好ip 进入hosts文件中
192.168.200.132 linux1192.168.200.133 linux2192.168.200.134 linux3
2.下载解压软件
# 解压缩tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module# 改名mv elasticsearch-7.8.0 es-cluster
将软件分发到其他节点: linux2, linux3
3.用户与权限
useradd es #新增 es 用户passwd es #为 es 用户设置密码userdel -r es #如果错了,可以删除再加chown -R es:es /opt/module/es #文件夹所有者
4.修改文件配置
修改/opt/module/es/config/elasticsearch.yml 文件,分发文件。
# 加入如下配置#集群名称cluster.name: cluster-es#节点名称, 每个节点的名称不能重复node.name: node-1#ip 地址, 每个节点的地址不能重复network.host: linux1#是不是有资格主节点node.master: truenode.data: truehttp.port: 9200# head 插件需要这打开这两个配置http.cors.allow-origin: "*"http.cors.enabled: truehttp.max_content_length: 200mb#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 mastercluster.initial_master_nodes: ["node-1"]#es7.x 之后新增的配置,节点发现discovery.seed_hosts: ["linux1:9300","linux2:9300","linux3:9300"]gateway.recover_after_nodes: 2network.tcp.keep_alive: truenetwork.tcp.no_delay: truetransport.tcp.compress: true#集群内同时启动的数据任务个数,默认是 2 个cluster.routing.allocation.cluster_concurrent_rebalance: 16#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个cluster.routing.allocation.node_concurrent_recoveries: 16#初始化数据恢复时,并发恢复线程的个数,默认 4 个cluster.routing.allocation.node_initial_primaries_recoveries: 16
修改/etc/security/limits.conf ,分发文件
# 在文件末尾中增加下面内容es soft nofile 65536es hard nofile 65536
修改/etc/security/limits.d/20-nproc.conf,分发文件
# 在文件末尾中增加下面内容es soft nofile 65536es hard nofile 65536\* hard nproc 4096\# 注: * 带表 Linux 所有用户名称
修改/etc/sysctl.conf
# 在文件中增加下面内容vm.max_map_count=655360sysctl -p #重新加载
逐一启动
cd /opt/module/es-cluster#启动bin/elasticsearch#后台启动bin/elasticsearch -d
测试集群
192.168.200.132:9200/_cat/nodes
Linux搭建ELK集群
ELK是3个开源软件的缩写,分别为Elasticsearch 、 Logstash和Kibana , 它们都是开源软件。不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具,目前由于原本的ELK Stack成员中加入了Beats工具所以已改名为Elastic Stack。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据3大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,Client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往Elasticsearch上去。
Kibana也是一个开源和免费的工具,Kibana可以为 Logstash和 ElasticSearch提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、CPU、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
| 机器名称 | 版本 | 规格 |
|---|---|---|
| elk-1 | centos7.9 | 2h4g 50G |
| elk-2 | centos7.9 | 2h4g 50G |
| elk-3 | centos7.9 | 2h4g 50G |
基础操作
三台机器都做如下操作
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel #yum安装java#三台分别修改名称vim /etc/hosts #添加host192.168.218.158 elk-01192.168.218.159 elk-02192.168.218.160 elk-03#下载elasticsearchwget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.rpmrpm --install elasticsearch-6.0.0.rpm #安装elasticsearchsystemctl daemon-reload #重启启动项配置文件systemctl enable elasticsearch.service #设置开启自启
三台机器的单独操作
master节点【node.master: true node.data: false】
#elk-1 第一台机器vim /etc/elasticsearch/elasticsearch.yml #只需做部分配置cluster.name: ELK #设置集群的名称node.name: elk-1 #设置节点名称node.master: true #指定该节点是否有资格被选举成为master,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。node.data: false #指定该节点是否存储索引数据network.host: 192.168.218.158 #设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。http.port: 9200 #es对外访问的http端口,默认9200discovery.zen.ping.unicast.hosts: ["elk-1","elk-2","elk-3"]
data节点【node.master: false node.data: true】
#elk-2 第二台机器vim /etc/elasticsearch/elasticsearch.yml #只需做部分配置cluster.name: ELK #设置集群的名称node.name: elk-2 #设置节点名称node.master: falsenode.data: true #指定该节点是否存储索引数据network.host: 192.168.218.159 #设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。http.port: 9200 #es对外访问的http端口,默认9200discovery.zen.ping.unicast.hosts: ["elk-1","elk-2","elk-3"]
client节点【node.master: false node.data:false】
#elk-3 第三台机器vim /etc/elasticsearch/elasticsearch.yml #只需做部分配置cluster.name: ELK #设置集群的名称node.name: elk-3 #设置节点名称node.master: falsenode.data: false #指定该节点是否存储索引数据network.host: 192.168.218.160 #设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。http.port: 9200 #es对外访问的http端口,默认9200discovery.zen.ping.unicast.hosts: ["elk-1","elk-2","elk-3"]
master节点:普通服务器即可(CPU 内存 消耗⼀般)
data节点:主要消耗磁盘,内存
client节点:普通服务器即可(如果要进⾏分组聚合操作的话,建议这个节点内存也分配多⼀点)
此时才能启动,统一启动。如果之前提前开启了,一定要再统一重启。
查看集群
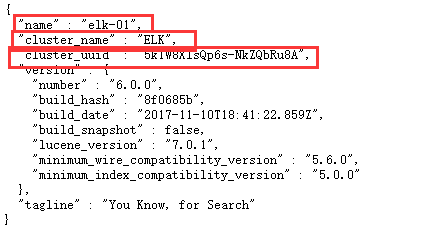
打开网页,ip:9200。
- name:设置的服务es服务名称
- cluster_name:集群名称
- cluster_uuid:集群uuid,正常来说三台应该一样
curl 192.168.218.158:9200/_cluster/health?pretty{"cluster_name" : "ELK","status" : "green", #为green则代表健康没问题,yellow或者red 则是集群有问题"timed_out" : false, #是否有超时"number_of_nodes" : 3, #集群中的节点数量"number_of_data_nodes" : 1, #集群中data节点的数量"active_primary_shards" : 0,"active_shards" : 0,"relocating_shards" : 0,"initializing_shards" : 0,"unassigned_shards" : 0,"delayed_unassigned_shards" : 0,"number_of_pending_tasks" : 0,"number_of_in_flight_fetch" : 0,"task_max_waiting_in_queue_millis" : 0,"active_shards_percent_as_number" : 100.0}
搭建Kibana
#在elk-01 节点wget https://artifacts.elastic.co/downloads/kibana/kibana-6.0.0-x86_64.rpmrpm -ivh kibana-6.0.0-x86_64.rpmwget http://nginx.org/packages/centos/7/x86_64/RPMS/nginx-1.16.1-1.el7.ngx.x86_64.rpmrpm -ivh nginx-1.16.1-1.el7.ngx.x86_64.rpmvim /etc/nginx/nginx.confupstream elasticsearch {zone elasticsearch 64K;server elk-01:9200;server elk-02:9200;server elk-03:9200;}server {listen 8080;server_name 192.168.218.158;location / {proxy_pass http://elasticsearch;proxy_redirect off;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;}access_log /var/log/es_access.log;}vim /etc/kibana/kibana.ymlserver.port: 5601server.host: 192.168.218.158elasticsearch.url: "http://192.168.218.158:8080"systemctl restart nginx kibana
配置监听
#在elk-02 节点wget https://artifacts.elastic.co/downloads/logstash/logstash-6.0.0.rpmrpm -ivh logstash-6.0.0.rpmvim /etc/logstash/logstash.ymlhttp.host: "192.168.218.159"#增加logstash权限chmod 644 /var/log/messageschown -R logstash:logstash /var/log/logstashchown -R logstash /var/lib/logstash/#配置logstash收集syslog日志vim /etc/logstash/conf.d/syslog.confinput { #定义日志源file {path => "/var/log/messages" #定义日志来源路径 目录要给644权限,不然无法读取日志type => "systemlog" #定义类型start_position => "beginning"stat_interval => "3"}}output { #定义日志输出elasticsearch {hosts => ["192.168.218.158:9200"]index => "system-log-%{+YYYY.MM.dd}"}}ln -s /usr/share/logstash/bin/logstash /usr/bin#创建软连接,方便使用logstash命令logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/syslog.conf --config.test_and_exit#为ok则代表没问题systemctl start logstash #启动Logstash服务
- —path.settings : 用于指定logstash的配置文件所在的目录
- -f : 指定需要被检测的配置文件的路径
- —config.test_and_exit : 指定检测完之后就退出,不然就会直接启动了。选项的意思是解析配置文件并报告任何错误
curl '192.168.218.159:9200/_cat/indices?v'#查看日志索引curl -XGET/DELETE '192.168.218.158:9200/system-log-2022.04.11?pretty'#获取/删除指定索引详细信息
配置system Web监听
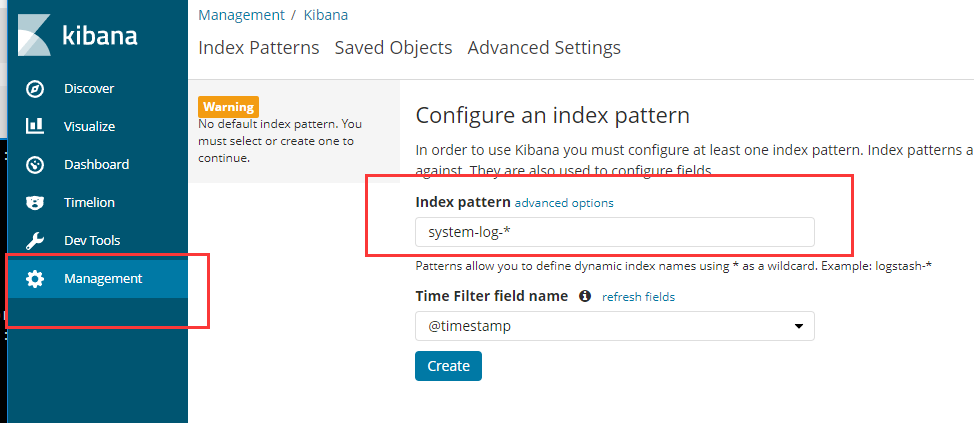
配置完成后,选择Discover,进入“Discover”页面后,无法查找到日志信息,这种情况一般是时间的问题,单击右上角信息切换成查看当天的日志信息。
我这里正常则不做调整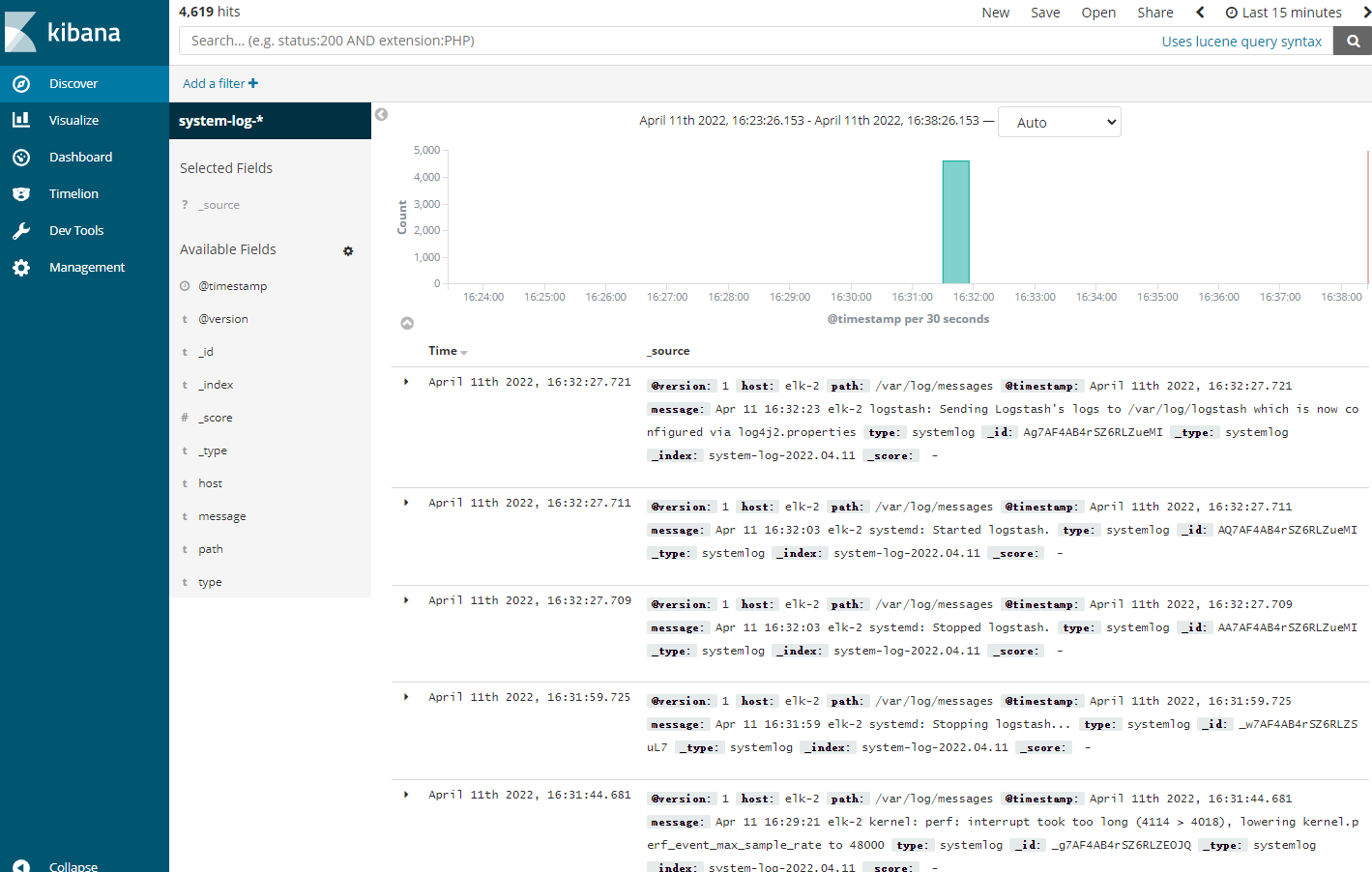
配置nginx监听
#elk-2上操作wget http://nginx.org/packages/centos/7/x86_64/RPMS/nginx-1.16.1-1.el7.ngx.x86_64.rpmrpm -ivh nginx-1.16.1-1.el7.ngx.x86_64.rpmvim /etc/logstash/conf.d/nginx.confinput { #从日志文件输入file {path => "/tmp/elk_access.log"start_position => "beginning"type => "nginx"}}filter {grok {match => { "message" => "%{IPORHOST:http_host} %{IPORHOST:clientip} - %{USERNAME:remote_user} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:http_verb} %{NOTSPACE:http_request}(?: HTTP/%{NUMBER:http_version})?|%{DATA:raw_http_request})\" %{NUMBER:response} (?:%{NUMBER:bytes_read}|-) %{QS:referrer} %{QS:agent} %{QS:xforwardedfor} %{NUMBER:request_time:float}"}}geoip {source => "clientip"}}output {stdout { codec => rubydebug } #这是标准输出到终端,可以用于调试看有没有输出,注意输出的方向可以有多个elasticsearch { #输出到kafkahosts => ["192.168.218.159:9200"]index => "nginx-test-%{+YYYY.MM.dd}"}}logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/nginx.conf --config.test_and_exitvim /etc/nginx/conf.d/elk.confserver {listen 80;server_name elk.com;location / {proxy_pass http://192.168.218.158:5601;proxy_set_header Host $host;proxy_set_header X-Real-IP $remote_addr;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;}access_log /tmp/elk_access.log main2;}echo "192.168.218.159 elk.com" >> /etc/hosts #添加host配置vim /etc/nginx/nginx.conf #额外添加log_format main2 '$http_host $remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$upstream_addr"$request_time';#systemctl restart nginxcurl elk.comcurl 'elk-02:9200/_cat/indices?v'
配置Web nginx监听
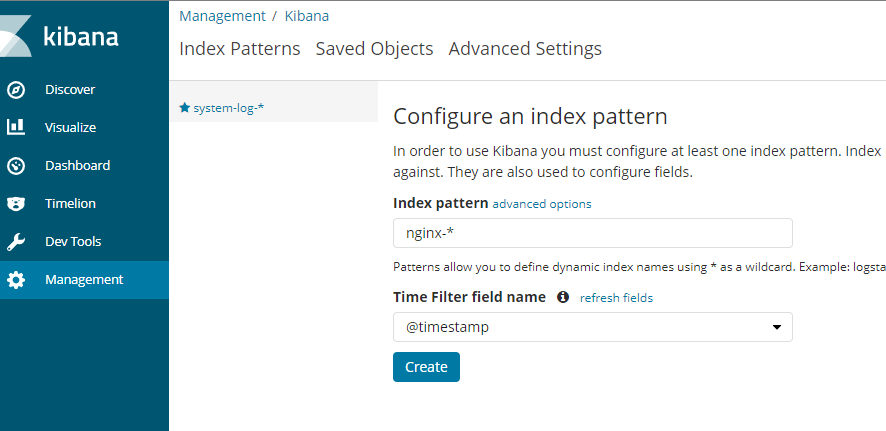
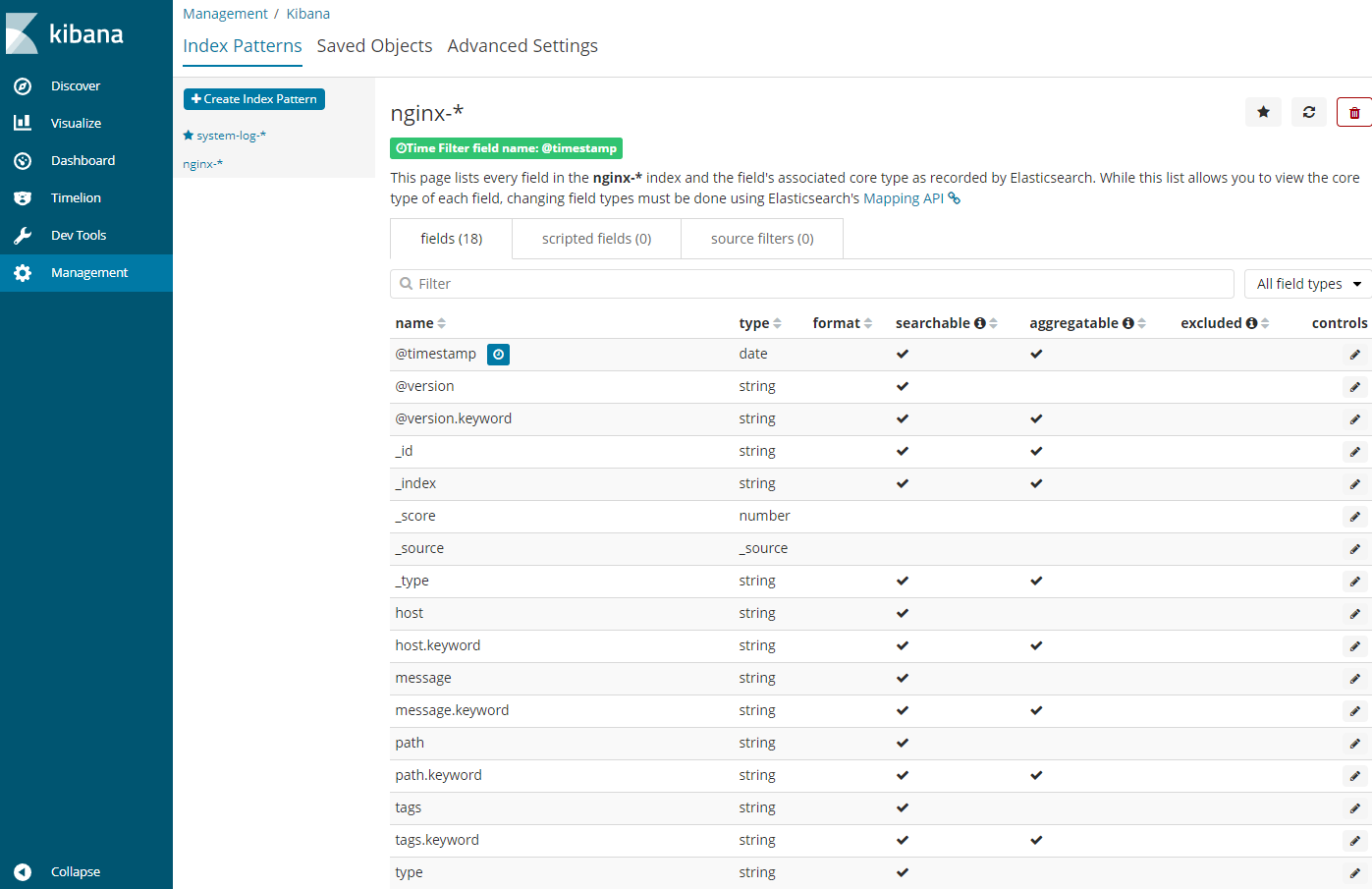
配置beats监听
#elk-03节点上操作wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.0-x86_64.rpmrpm --install filebeat-6.0.0-x86_64.rpmvim /etc/filebeat/filebeat.ymlfilebeat.prospectors:enabled: truepaths:- /var/log/yum.log //此处可自行改为想要监听的日志文件output.elasticsearch:hosts: ["elk-01:9200","elk-02:9200","elk-03:9200"]systemctl start filebeatcurl 'elk-01:9200/_cat/indices?v'
Elk+Kafka+Zookeeper 构建高并发分布式日志收集系统
Kafk
Apache kafka是消息中间件的一种,是一种分布式的,基于发布/订阅的消息系统。能实现一个为处理实时数据提供一个统一、高吞吐、低延迟的平台,且拥有分布式的,可划分的,冗余备份的持久性的日志服务等特点。
高吞吐量的分布式发布订阅消息系统(MQ)。消息队列。
- 通过磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
- 支持通过kafka服务器和消费机集群来分区消息
kafka与elk
业务层可以直接写入到kafka队列中,不同担心elasticsearch的写入效率问题。比如java,php等。
kafka术语
kafka是一个消息队列服务器。kafka服务称为broker (中间人) ,消息发送者称为producer (生产者),消息接收者称为consumer(消费者)通常我们部署多个broker以提供高可用性的消息服务集群.典型的是3个broker,消息以topic的形式发送到broker,消费者订阅topic,实现按需取用的消费模式;创建topic(话题)需要指定replication-factor(复制数目,通常=broker数目);每个topic可能有多个分区(partition),每个分区的消息内容不会重复
- kafka-broker 中间人
- webserver/logstash-producer 消息生产者/消息发送者
- elasticsearch-consumer 消费者
- logs-topic 话题
- replication-facter 复制数目-中间人存储消息的副本数
Zookeeper
ZooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,提供的功能包括∶配置维护、分布式同步等。Kafka的运行依赖ZooKeeper。也是java微服务里面使用的一个注册中心服务。
ZooKeeper主要用来协调Kafka的各个broker,不仅可以实现bioker的负载均衡,而且当增加了broker或者某个broker故障了,ZooKeeper将会通知生产者和消费者,这样可以保证整个系统正常运转。
在Kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况与消费者当前消费的状态信息都会保存在ZooKeeper中。
kafka集群安装与Zookeeper配置
zk启动的端口为2181、2888、3888
官网下载tar包wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gzmkdir /usr/zookeepertar -zvxf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/zookeepervim /usr/zookeeper/apache-zookeeper-3.7.0-bin/conf/zoo.cfg #进入配置文件添加以下内容dataDir=/data/zookeeper/datadataLogDir=/data/zookeeper/logsclientPort=2181tickTime=2000initLimit=20syncLimit=10server.1=192.168.218.158:2888:3888server.2=192.168.218.159:2888:3888server.3=192.168.218.160:2888:3888mkdir -p /data/zookeeper/{data,logs} #创建文件夹#配置节点标识,为了不让echo 1 > /data/zookeeper/data/myid #创建myid文件 myid好按顺序排 这是第一台机器echo 2 > /data/zookeeper/data/myid #这是第二台机器echo 3 > /data/zookeeper/data/myid #这是第三台机器cat >> /etc/profile <<EOF #配置环境变量export ZOOKEEPER_HOME=/usr/zookeeper/apache-zookeeper-3.7.0-binexport PATH=$ZOOKEEPER_HOME/bin:$PATHEOF使环境变量生效source /etc/profileecho $ZOOKEEPER_HOME
- dataDir zk数据存放目录。
- dataLogDir ZK日志存放目录。
- clientPort 客户端连接ZK服务的端口。
- tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
- initLimit 允许follower连接并同步到Leader的初始化连接时间,当初始化连接时间超过该值,则表示连接失败。
- syncLimit Leader与Follower之间发送消息时如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
- server.1=192.168.19.20:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。
sh /usr/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start #启动zookeepersh /usr/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh status #查看节点状态sh /usr/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 192.168.218.159:2181 #选其中一个节点作为客户端连接其他节点即可
Kafka配置
kafka启动的端口为9092
mkdir /usr/kafkamkdir -p /data/kafka #创建文件夹mkdir -p /data/kafka/logs #创建文件夹wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.1/kafka_2.12-2.8.1.tgztar -zxf kafka_2.12-2.8.1.tgz -C /usr/kafkacp /usr/kafka/kafka_2.12-2.8.1/config/server.properties{,.bak} #制作备份vim /usr/kafka/kafka_2.12-2.8.1/config/server.properties #进入配置文件broker.id=1 #broker的IDlisteners=PLAINTEXT://192.168.218.158:9092 #监听地址num.network.threads=3 #处理消息的最大线程数,一般情况下不要去修改num.io.threads=8 #处理磁盘io的线程数socket.send.buffer.bytes=102400 #socket的发送缓冲区socket.receive.buffer.bytes=102400 #socket接收缓冲区socket.request.max.bytes=104857600 #请求最大值log.dirs=/opt/data/kafka/logs #log日志文件num.partitions=6 #分区num.recovery.threads.per.data.dir=1 #kafka会使用可配置的线程池来处理日志片段offsets.topic.replication.factor=1 #断分偏移量transaction.state.log.replication.factor=1 #传输日志的复制状态transaction.state.log.min.isr=1 #传输日志最小的信息log.retention.hours=168 #数据存储的最大时间log.segment.bytes=1073741824 #topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖log.retention.check.interval.ms=300000 #检查文件大小检查的周期时间zookeeper.connect=192.168.218.158:2181,192.168.218.159:2181,192.168.218.160:2181 #zookeeper连接,维护集群状态zookeeper.connection.timeout.ms=18000 #连接超时group.initial.rebalance.delay.ms=0#注意修改不一样的地方#第一个节点的broker.id=0listeners=PLAINTEXT://192.168.218.158:9092#第二个节点的broker.id=1listeners=PLAINTEXT://192.168.218.159:9092#第三个节点的broker.id=2listeners=PLAINTEXT://192.168.218.160:9092
启动kafka
cd /usr/kafka/kafka_2.12-2.8.1nohup bin/kafka-server-start.sh config/server.properties >> /var/log/kafka-server.log 2>&1 & #放入后台启动bin/kafka-server-stop.sh #关闭kafka
kafka配置测试
- 创建主题
cd /usr/kafka/kafka_2.12-2.8.1bin/kafka-topics.sh --create --bootstrap-server 192.168.218.158:9092 --replication-factor 3 --partitions 2 --topic test_topic1#老版本--bootstrap-server 换成 zookeeper
- create: 创建
- bootstrap-server: 引导服务器
- replication-factor: 设置副本
- partitions: 设置分区
- topic: 设置topic名称
测试使用
- 查看Topic(主题)
我们可以通过命令列出指定Broker的topic信息
cd /usr/kafka/kafka_2.12-2.8.1bin/kafka-topics.sh --list --bootstrap-server 192.168.218.158:9092 #因为是集群,所以从任何节点都可以看到topicbin/kafka-topics.sh --list --bootstrap-server 192.168.218.159:9092bin/kafka-topics.sh --list --bootstrap-server 192.168.218.160:9092
3,发送接收消息
bin/kafka-console-producer.sh --broker-list 192.168.218.158:9092 --topic test_topic1 #此时进入topic,可以发送消息>123>qwq#输入一些信息bin/kafka-console-consumer.sh --bootstrap-server 192.168.218.159:9092 --topic test_topic1 --from-beginning #此时其他端口连接上后,也能接收到信息(消费者)123qwq#重新设置消费bin/kafka-console-consumer.sh --bootstrap-server 192.168.218.158:9092 --topic test_topic1#设置消费者组bin/kafka-console-consumer.sh --bootstrap-server 192.168.218.158:9092 --topic test_topic1 --group agroupbin/kafka-console-consumer.sh --bootstrap-server 192.168.218.159:9092 --topic test_topic1 --group agroup
可能会出现报错:
WARN [Producer clientId=console-producer] Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)原因集群环境执行需要加上所有IP,如下:bin/kafka-console-producer.sh --broker-list elk-01:9092,elk-02:9092,elk-03:9092 --topic test_topic1
主题的操作
bin/kafka-topics.sh --list --zookeeper 192.168.218.159:2181 #列出集群中所有的topicbin/kafka-topics.sh --describe --zookeeper 192.168.218.159:2181 --topic test_topic1 #查看test_topic1这个主题的详情
zk作用
broker在zk中注册
kafka的每个broker(相当于一个节点,相当于一个机器)在启动时,都会在zk中注册,告诉zk其brokerid,在整个的集群中,broker.id/brokers/ids,当节点失效时,zk就会删除该节点,就很方便的监控整个集群broker的变化,及时调整负载均衡。
sh /usr/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkCli.sh -server 192.168.218.159:2181ls /brokers/ids[0, 1, 2]topic在zk中注册在kafka中可以定义很多个topic,每个topic又被分为很多个分区。一般情况下,每个分区独立在存在一个broker上,所有的这些topic和broker的对应关系都有zk进行维护ls /brokers/topics/test-ken-io/partitions[0]consumer(消费者)在zk中注册注意:从kafka-0.9版本及以后,kafka的消费者组和offset信息就不存zookeeper了,而是存到broker服务器上。所以,如果你为某个消费者指定了一个消费者组名称(group.id),那么,一旦这个消费者启动,这个消费者组名和它要消费的那个topic的offset信息就会被记录在broker服务器上。,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。因此kafka提供了另一种解决方案:增加__consumeroffsets topic,将offset信息写入这个topicls /brokers/topics/__consumer_offsets/partitions[0, 1, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 6, 7, 8, 9]
将logstash中的数据发送到kafka
vim /etc/logstash/conf.d/syslog.confinput {file {path => "/var/log/messages"type => "systemlog"start_position => "beginning"stat_interval => "3"}}output {kafka {bootstrap_servers => "192.168.218.158:9092,192.168.218.159:9092,192.168.218.160:9092"topic_id => "test_topic1" #这里也可以写别的,会自动帮你创建。也可以填写已经创建的compression_type => "snappy"}}logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/syslog.conf --config.test_and_exit#logstash -f /etc/logstash/conf.d/syslog.conf #启动Logstash配置,如果无法使用,使用该命令bin/kafka-topics.sh --list --bootstrap-server 192.168.218.158:9092 #查看topic#此时就可以接收到消息了echo 123 >> /var/log/messagesbin/kafka-console-consumer.sh --bootstrap-server 192.168.218.159:9092 --topic test_topic1 --from-beginning
好了,我们将logstash收集到的数据写入到了kafka中了,在实验过程中我使用while脚本测试了如果不断的往kafka写数据的同时停掉两个节点,数据写入没有任何问题。
那如何将数据从kafka中读取然后给我们的es集群呢?
cat /etc/logstash/conf.d/syslog2.conf #创建配置文件input {kafka {bootstrap_servers => "192.168.218.159:9092,192.168.218.158:9092,192.168.218.160:9092"topics => ["test_topic1"]consumer_threads => 5decorate_events => true}}output {elasticsearch {hosts => ["192.168.218.159:9200"]index => "test-system-messages-%{+YYYY.MM.dd}"}}logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/syslog2.conf --config.test_and_exit#logstash -f /etc/logstash/conf.d/syslog2.conf #启动Logstash配置,如果无法使用,使用该命令#logstash -f /etc/logstash/conf.d/ & #或者一键启动
curl 'elk-02:9200/_cat/indices?v' 查看是否有新的日志
#参考文档https://www.jianshu.com/p/147f072abe0ahttps://blog.csdn.net/weixin_30707875/article/details/98614772https://blog.csdn.net/rightlzc/article/details/106638231https://blog.51cto.com/feko/2735797https://blog.csdn.net/qq_41582883/article/details/115875783

若有收获,就点个赞吧
0 人点赞
