如何设置开机启动命令
/etc/rc.d/rc.local
Linux常见目录及其作用?
/ 根目录
bin 存放二进制文件,系统基本命令
boot 存放linux系统核心文件 存储启动文件
etc 服务器各种程序配置文件
var 存放运行时需要嘎比俺的数据文件 也是大文件的溢出区 比如各种服务的日志文件等
/var/log 各种服务默认存放日志地点
/var/log/message 记录系统重要信息的日志文件 当系统错误可以查看该文件
sbin 超级二进制文件 一般为root用户使用的系统命令
usr 通常用来存放服务器安装的各种软件 安装完毕会形成对应的指令
dev 各种系统硬件目录 因为linux中万物皆文件 所以那怕是硬件也是以文件形式存在到该目录中
home 存放用户文件的根目录
proc 内存映射目录 该目录可以查看系统的相关信息
lib 存放文件系统中程序运行所需要的库和内核模块 类似dll文件
mnt 存放临时文件系统的安装点
OSI七层模型的分层与应用
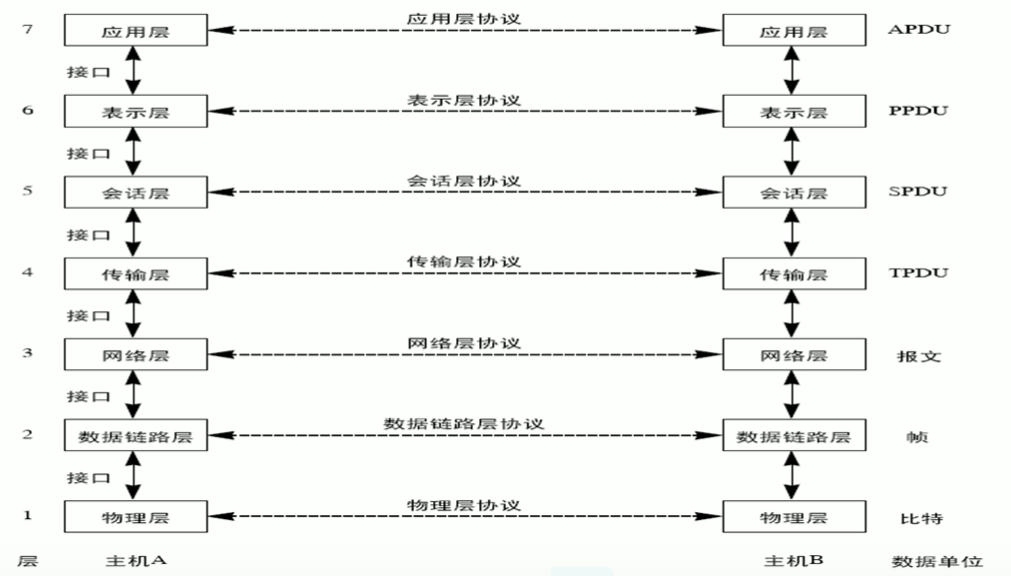
应用层:
为用户提供服务,给用户一个操作界面
表示层:
数据提供表示,比如图片,视频,声音,点击鼠标。
加密 ssh非对称加密
压缩
会话层:
确定数据是否需要进行网络传递
传输层:
对报文进行发送时分组,接收时组装。因为IPV4协议一个包最大就2的16次方
传输协议的选择:TCP/UDP。
TCP:传输控制协议,可靠,面向连接的传输协议。
UDP:用户数据报协议,不可靠,面向无连接的传输协议。
端口封装
差错校验
网络层:
IP地址编址
路由选择:静态路由和动态路由
数据链路层:
MAC地址编址 寻址
物理层:
数据实际传输
电气特性定义
TCP/IP四层模型与作用

应用层:
HTTP FTP SNMP DNS
传输层:
TCP/UDP
网络层:
ICMP IP ARP
数据链路和物理层:
PPP PPPOE
Linux权限管理
Linux权限与安全
- 注意权限分离(Linux系统权限、数据库权限不要掌握在同一个部门)
- 权限在满足使用的情况下,最小优先
- 减少使用root用户,尽量用“普通用户+sudo提权”进行日常操作重要系统文件,如:/etc/passwd、/etc/shadow、/etc/fstab、/etc/sudoers等,日常建议使用chattr锁定,需要操作时再打开
- 使用脚本检测系统中新增的SUD、SGD文件
- 可以利用工具(如chkrootkit)等检测rootkit脚本
- 开启SSH服务秘钥对登录,修改SSH服务端口
简述Linux权限划分原则
文件基本权限
通过 ll 查看文件
第一列是文件类型 -:普通文件 d:文件夹 l:连接文件
文件的权限含义:r 可读(cat) w 可写(vi) x 可执行(./)。
目录的权限含义:r 查看目录内容权限 w 目录中内容的增删复制剪切 x 是否能进入目录
权限的修改:chmod [augo][+-=] [rwx] filename chmod 644 filename
权限的分配原则:
给文件或目录分配权限时,先考虑所有者和所属组。
遵循最小化权限原则,用啥权限给啥权限。权限越小越安全。
修改目录以及子文件归属或权限时,注意递归。
文件基本权限是最常用,也是最有效的Linux安全防护手段。
默认权限:
umask 0022 也可以通过/etc/profile中修改。
umask计算:
用户创建文件夹权限值=初始创建文件夹默认值-umask的预设值
755=777-022
用户创建文件权限值=初始创建文件默认值-umask的预设值
644=666-022
特殊权限:
SUID SGID尽量别碰,不要人为设置。我们还需要定期检查服务器中是否存在该权限文件。
ACL权限,不可以取代基本权限。
sudo权限:
visodo 或者 /etc/sudoer
给予sudo权限时,尽量授予具体的命令选项参数,避免出现过度授权和权限溢出的问题。
sudo -k # 清除密码认证状态
sudo -u sshd whoami # 以任意形式执行命令
sudo权限的设置:
设置用户:
visudo进入文件,添加用户 liao ALL=(ALL) ALL
设置用户组:
usermod -aG wheel liao #将liao添加到用户组wheel中
设置无需密码执行命令:
liao ALL=(ALL) ALL,NOPASSWORD: /usr/sbin/yum, /usr/sbin/shutdown, /usr/sbin/reboot
sudo su和su的区别:
su直接切换到root,需要输入root密码
sudo su 临时使用root权限,需要使用当前用户密码。
文件系统属性权限:
lsatter -a 显示所有文件和目录
lsatter -d 若目标为目录,列出目录属性,不显示目录下文件属性
chattr [+-] i 不允许删除改名
chattr [+-] a 只能在文件中增加数据,但不能删除不能修改数据,包括root
Linux备份策略
如果一个系统没有任何备份策略,请写出一个较为全面合理的备份方案。
每日备份的数据(异地备份)
Mysql数据库(主从备份之外,增量备份一次)
每周备份的数据(异地备份)
Mysql数据库(完整备份)
重要系统数据
网页数据
其他服务相关数据
网站服务器每天日志数量较大,如何备份?
使用日志管理工具:logrotate
logrotate /var/log/boot.log
日志切割
日志轮替:1-10天,当11天,删除第1天。当12天,删除第2天。
Apache服务配置文件自带日志切割功能,但是需要通过脚本进行轮替。
需要备份的系统目录
/etc/ # 系统配置文件
/home/ # 用户家目录
/root/ # root用户目录
/var/spool/mail/ # 邮件目录
/var/spool/cron/ # 定时任务
/var/spool/at/ # 定时任务
Mysql数据库目录备份
RPM包安装的Mysql:/var/lib/mysql
源码包安装的: /usr/local/mysql/data
Apache服务备份
网站内容: /var/www/html /usr/local/apache2/htdocs/
配置文件: /etc/httpd/conf/httpd.conf /usr/local/apache2/conf/httpd.conf
日志文件: /var/log/httpd/ /usr/local/apache2/logs
备份策略
完成备份
cp,tar,dump/xfsdump
增量备份 以前一次备份作为参照
差异备份 以第一次备份作为参照
备份频率
实时备份:如Mysql主从同步。
定时备份:如每天,每周备份,一般通过“脚本+定时任务”实现。
备份存储位置
基本原则:不要把鸡蛋放在同一个篮子里
既要本地备份,也要异地备份,甚至可以多次备份。
Linux的Raid
简述Raid0,Raid1,Raid5的特点与原理
Raid0 (独立磁盘冗余阵列)
必须使用两块或两块以上硬盘组成
每块硬盘的大小必须一致
是所有动态磁盘中,数据读写最快的
损坏几率相对最高
没有磁盘容错功能
Raid1
一部分用来接收存储数据,一部分用来备份数据。
由两块或2的倍数硬盘组成
每块大小必须一致
磁盘使用率只有50%,写入速度最快
拥有磁盘容错功能
Raid5
将全部的Raid5,每个各使用其1/n。当有一块损坏,就可以通过其他盘奇偶校验区的数据推算出损坏的数据。
由三块和三块以上硬盘组成
每块硬盘大小必须一致
磁盘利用率是n-1块盘
利用奇偶校验,拥有磁盘容错功能
Raid6
1u的服务器就只能放三块硬盘,所以常用Raid5,2u才能用Raid6。成本就随之提高。
是Raid5的增强版
由4块或以上硬盘组成
每块硬盘大小必须一致
磁盘利用率是n-2块盘
支持磁盘容错,可以支持2块硬盘损坏
Raid10
必须有4块等大小的硬盘组成。
两两组成Raid1,再组成Raid0。
兼顾Raid0和Raid1的特点,中和了两种的缺点
软Raid与硬Raid的区别
软Raid:是由操作系统模拟的Raid,一旦硬盘损坏,操作系统就会损坏,Raid会丧失作用。
硬Raid:是由独立于硬盘之外的,硬件Raid卡组成。就算硬盘损坏,也不会导致Raid卡损坏,磁盘容错才能起作用。
Linux资源查看
Linux中有许多系统资源需要监管,请问有哪些命令可以查看?
查看CPU
- top # 展示系统CPU 内存信息
- uptime # 展示系统平均负载
- vmstat # 报告和采样内存,IO,CPU信息总览
- procinfo # 展示CPU和中断信息
- ps -o # 特定选择统计进程
查看内存
- vmstat # 报告和采样内存,IO,CPU信息总览
- top # 展示系统CPU 内存信息 M 切换为内存排序
- free -h # 统计和采样内存信息
- /proc/meminfo # 内存信息统计
- sar -r # 报告和采样内存信息
查看网络
- ifconfig # 配置网络接口和统计其数据
- ip a # 配置网络接口,路由统计其数据
- netstat -ntlp# 统计网络协议栈和接口信息
- ss # 系统套接字信息
查看磁盘
- vmstat -D # 特性选项统计磁盘I/O信息
- iostat # 统计设备和分区磁盘I/O信息
- iotop # 列出进程磁盘I/O信息
- lsof # 列出进程打开文件,目录信息
综合检测工具
dstatyum install -y dstatdstat --top-cpu 3 3 # 3秒查询一次 看谁占用CPU最高 查询3次dstat --top-mem 1 3 # 1秒查询一次 看谁占用内存最高 查询3次
Linux启动流程
Centos7
服务器加电,加载BIOS信息,BOS进行系统检测
加载启动引导程序(grub2)
由grub2加载系统内核,内核重新自检
由grub2加载inintamfs虚拟文件系统
内核初始化,以加载动态模块的式加载部分硬件的驱动
内核启动系统的第一个进程,也就是systemd
Linux系统优化
如何进行Linux系统优化
禁用不需要的服务
使用ntsysv命令
避免直接使用root用户,普通用户通过sudo授权操作
通过chattr锁定重要系统文件>/etc/passwd
>/etc/shadow
>/etc/group
>/etc/gshadow
>/etc/inittab
配置国内yum源,加快下载速度
配置系统同时打开最大文件数
默认是1024并发,但nginx能达到5w的并发
vi /etc/profile
ulimit -SHm 65535
同步时间服务器
ntpdate ntp1.aliyun.com
通过crond定时任务,让时间同步命令每60分钟执行一次
更改ssh服务器端口,配置ssh秘钥登录
配置合理的Iptables防火墙规则
配置合理的SElinux安全上下文
指定合理的监控策略 监控SUID SGID
定时备份系统重要文件
Shell编程
文本截取类
http://www.baidu.com/index.htmlhttps://www.atguigu.com/index.htmlhttp://www.sina.com.cn/1024.htmlhttps://www.atguigu.com/2048.htmlhttp://www.sina.com.cn/4096.htmlhttps://www.atguigu.com/8192.htmlcat b.txt | cut -d "/" -f 3 | sort | uniq -c | sort -nrcat b.txt # 打印文字cut -d "/" -f 3 # 以"/"为切割 -f 截取第3段sort # 第一次排序uniq -c # 统计重复行sort -nr # 从大到小排序
# 统计当前服务器正在连接的IP地址,并按照连接次数排序netstat -an | grep ESTABLISHED | awk '{print $5}' | cut -d ":" -f 1 | sort -n | uniq -c | sort -nr
创建随机数
随机字符串生成
/dev/random 依赖系统中断生成随机字符串,可以保证数据的随机性但生成数据慢,会占用系统进程资源
/dev/urandom 不依赖系统中断生成随机字符串,生成数据速度快但数据随机性不足
tr: 可以对来自标准输入的字符进行替换,压缩和删除。它可以将一组字符变成另一组字符。
#!/bin/bashif [ ! -d /atguigu ] #如果目录没有建立thenmkdir /atguiguficd /atguigufor (( i=1;i<=10;i++ )) # 创建循环dofilename=$(tr -dc 'A-Za-z0-9' < /dev/urandom | head -c 6)touch "$filename"_gg.txtdone
echo $(($RANDOM%1000)) 生成随机数
网站检测
批量检查多个网站是否可以正常访问,要求使用shell数组实现,检测策略尽量模拟用户真实访问模式。
-o: 将命令输出保存在指定文件。
-s: Silent模式。不输出任务内容。
-w: 按指定格式输出内容,例如:-w %{http_code}: 输出状态码
—connect-timeout: 连接超时时间
#!/bin/bashweb=(http://www.atguigu.comhttps://www.qq.comhttps://www.baidu.com1.1.1.1) # 自定义数组for i in ${web[*]}docode=$(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' $i | grep -E "200|302") # 检测curl状态码# 检测网站 -o内容保存在null文件 5秒超时时间 按照格式输出 过滤200和302状态if [ "$code" != "" ] # 如果不为空thenecho "$i is ok" >> /root/ok.logelsesleep 3 # 会出现卡顿的情况 我们过一会再访问code=$(curl -o /dev/null -s --connect-timeout 5 -w '%{http_code}' $i | grep -E "200|302") # 再次curlif [ "$code" != "" ]thenecho "$i is ok" >> /root/ok.logelseecho "$i is error" >> /root/error.logfifidone
Nginx面试题
Apache和Nginx各自的优缺点,应该如何选择。
Apache优缺点:
基于select模型,同步IO模型
Apache和rewrite(重写)功能比nginx强大
Apache功能模块多
存在时间长,教程多,bug相对少
动静态解析都超稳定
缺点:
由于工作模式是同步阻塞型,导致资源消耗高,并发能力差。
Nginx优缺点:
基于epoll模型,异步IO模型
轻量级服务,占用比apache少
并发能力强,nginx处理请求是异步非阻塞的,能保持低资源,低消耗,高性能。
高度模块化的设计,编写模块相对简单。
社区活跃,各种高性能的模块产出迅速。
缺点:
动态处理上需要使用fastcgi连接php的fpm服务,相比apache不占优势。
Apache与nginx的选择
nginx适合做静态处理,简单,效率高
apache适合做动态处理,稳定,功能强
并发较高的情况下优先选择nginx,并发要求不高的情况下两者都可以,规模稍大的可以使用nginx作为反向代理,然后将动态请求负载均衡到后端apache上。
为什么Nginx并发能力强,资源消耗低
因为nginx是异步非阻塞模式。
同步异步区别:同步会去等,而异步不会。
阻塞非阻塞区别:apache中收到用户请求,会有一个线程一直等待用户请求完毕。nginx中则等待用户请求时还会能够去处理其他用户请求。
Nginx以异步非阻塞方法
◆客户端发送request,服务器分配work进程来处理
◆能立即处理完的,处理后work进程释放资源,进行下一个request的处理
◆不能立即处理完的work进程注册返回事件,然后接着去处理其他request
◆当之前的request?结果返回后,触发返回事件,由空闲work进程接着处理通过这种快速处理,快速释放请求的方式,达到同样的配置可以处理更大并发量的目的
写出几个nginx常用模块,并描述其功能
http_ssl_module
实现服务器加密传输的模块,部署完成后可使用https://协议进行数据传输,保证数据传输过程的安全。
http_image_filter_module
通过该模块可以实现图片裁剪,将过大的图片裁剪为指定大小的图片,生成缩略图。保证传输速率,该选项默认不开启,需要人为指定。
http_rewrite_module
Nginx的地址重写模块,功能和apache自带的一样。可以实现通过正则匹配来完成条件判断,然后进行域名或url的重写。
http_proxy_module
nginx的反向代理功能,由于nginx的高并发特性,很多时候我们都选择使用nginx作为网站的前置服务器,一般会和upstream模块一起使用,完成压力分摊工作。
反向代理需要安装模块才能使用,并且默认开启
http_upstream_module
Nginx的负载均衡模块,一般和http_proxy模块一起使用,用来对后台服务器的任务调度以及分配,分配原则可以通过算法进行控制。RR轮巡调度。常见模式为:nginx+tomcat,nginx+apache。
Nginx如何连接php进行页面解析
用户访问nginx——nginx将数据传输到fastcgi中——php-fpm中——mysql
用户访问tomcat——php——mysql
Nginx和Tomcat之间的数据传输过程
用户访问nginx——nginx将数据传输到tomcat——jdk/java——mysql
Mysql基础语法

1.查询姓李的同学的个数
select count(*) from student.report where Name like '李%';
2.查询表中数学成绩大于80的前2名同学的名字,并按照分数从大到小的顺序排列
select Result from report ORDER BY Result DESC limit 2;
SQL语句-增
创建用户
create user liao@’%’ identified by ‘123546’;
创建数据库
创建数据表
create table tst1(id int,name char(30));
插入数据
insert into test1(id,name,age) values (01,”liao”,29);
SQL语句-删
删除用户
删除数据库
删除表
删除数据
delete from a2 where id = 5;
delete from a2 where age between 23 to 25;
SQL语句-改
修改表中的数据
update a2 set age=21 where id = 3
修改数据表的名称
修改数据表的字段类型
describe a1; #查看表
alter table a1 modify name char(50); # 修改数据类型
alter table a1 change name username char(50) not null default ‘ ‘; # 修改数据类型
添加删除字段
alter table a1 add time datetime;
alter table a1 drop time;
SQL语句-查
查看所有数据库
查看指定库所有数据表
查看指定数据表的字段结构
查看所有Mysql用户密码以及登录方式
select User,Password,Host from mysql.user;
SQL语句-授权
授予用户全部权限
grant all on test1.a1 to liao@”%”;
创建用户并授权
grant all on test1.a1 to liao1@”%” identified by “123123”;
取消用户的表中的权限
revoke drop,delete on test.a1 from liao@”%”;
查看用户授权信息
show grants for liao@”%”;
SQL语句的启动关闭
启动
service mysqld start
/etc/init.d/mysqld start
mysqld_safe &
关闭
service mysqld stop
/etc/init.d/mysqld stop
mysqladmin -uroot -p123456 shutdown
Mysql集群
一主多从,主库宕机,如何合理切换到从库,其他从库如何处理。
主从服务器
主服务器接收用户的写入和查询,默认情况下从服务器只是用来备份数据。
主从服务器原理
技术点:bin-log日志
开启主服务器的bin-log日志记录功能,将主服务器的bin-log日志传到从服 务器,从服务器根据日志内容将数据还原到本地。
日志只会记录主服务器的增删改数据的操作,不会执行查和权限操作。所以本质就是模仿一遍操作,并不是把数据传输出去。
主从服务器:
从服务器主动把主服务器上的数据同步到本地。
主从故障切换
1.登录所有从库查看post信息,post最大的设置为主库。然后将从库提升为新的主库
2.登录新的主库,执行stop slave停止从库。修改my.cnf配置文件,开启log-bin并重新启动数据库服务,登录数据库执行restet master,show master statues\G。
3.查看主库信息,最后创建授权同步用户与权限和网站使用数据库的用户与权限,最后修改对应服务器的IP地址等信息。
4.登录其他从库,执行change master操作,查看同步状态。
单台Mysql达到性能瓶颈时,如何击碎性能瓶颈
可以进行纵向提升和横向提升,纵向提升就是提高硬件属性,比如网络带宽,内存等(少见)。
横向就是额外增加数据库,多台处理数据。
数据库代理工具:Amoeba
Amoeba致力于MySQL的分布式数据库前端代理层,它主要在应用层访问MySQL的时候充当SQL路由功能,专注于分布式数据库代理层(Database Proxy)开发。具有负载均衡、高可用性、SQL过滤、读写分离、可路由相关的到目标数据库、可并发请求多台数据库合并结果。通过Amoeba你能够完成多数据源的高可用、负载均衡、数据切片的功能。
Mysql索引
什么是索引
索引本质是数据结构,排好序的快速查找数据结构,可以提高查找效率数据分身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
主键索引
单值索引,一个索引只包含单个列,一个表可以有多个单列索引。如果字段会被经常用来检索就可以用单值索引
复合索引,一个索引包含多个列如电话簿上姓+名字。最好不超过5个字段
唯一索引,所有列的值必须唯一,但是允许有空值
普通索引和唯一索引可以称为辅助索引
索引的优劣势
优势:
提高效率,不需要再对数据进行排序操作。
将随机IO查询转变为顺序IO查询。
劣势:
虽然提高了查询速度,但是降低了更新表的速度。因为不仅要更新数据表,还要保存一下索引文件。
实际索引也是算法优化查询生成的一张表,该表保存了主键与索引字段,并指向了实体表记录,索引列也是占空间的。
如果数据较多,我们需要重复设置最高效的索引或优化查询。
什么时候需要创建索引
主键自动建立唯一索引
频繁作为查询条件的字段应该创建索引
查询中与其他表关联的字段,外键关系建立索引
where条件里用不到的字段不创建索引
单键/组合索引的选择问题,在高并发下倾向创建组合索引
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度。
查询中统计或者分组字段(group by).
什么时候不创建
表记录太少,比如几万条时。三百万+时可以创建。
频繁更新的字段不适合创建索引,因为每次更新不单单是更新了记录还会更新索引
误删数据库导致数据损坏,如何恢复
可以使用备份
手动切割binlog日志并记好切割好的binlog日志文件位置,这里假设为009,备份全部binlog日志
找到之前全备数据最后备份到的binlog文件位置并记好位置,这里假设为005用mysqladmin命令将005到008 binlog文件中的SQL语句分离出来,并找到drop库的语句将其删掉
将之前全备数据导入mysql服务器
将步骤3中分离出的SQL语句导入mysql服务器
将009 binlog文件删除,再次刷新binlog日志,到此数据库已恢复成功
Redis面试题
如何保证Redis能永久保存数据
Redis工作原理
Redis是一个key-value存储系统,它支持的value类型相对较多,包括string、list、set zset和hash,这些数据都支持push/pop/add/remove及交并补等操作,而且这些操作都是原子性的,在此基础上,redis支持各种不同方式的排序。为了保证效率,数据是缓存在内存中的,Redis会周期性的把数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave同步。
Redis持久化-RDB
在Redis运行时,RDB程序将当前内存中的数据库快照保存到磁盘中,当Redis需要重启时,RDB程序会通过重载RDB文件来还原数据库。
- 保存(rdbSave)
rdbSave负责将内存中的数据库数据以RDB格式保存到磁盘中,就是Snapshot快照,如果RDB文件已经存在将会替换已有的RDB文件。保存RDB文件期间会阻塞主进程,这段时间期间将不能处理新的客户端请求,直到保存完成为止。我们可以设置自动触发和手动触发(save/bgsave)。
- 读取(rdbLoad)
当Redis启动时,会根据配置的持久化模式,决定是否读取RDB文件,并将其中的对象加载到内存中。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
Redis持久化-AOF
以协议文本的方式,将所有对数据库进行写入命令记录到AOF文件,达到记录数据库状态的目的。AOF保存更完整。
可以理解为Redis中的bin_log存储方式。
AOF的保存
记录下来我们每次的操作,恢复时把操作再做一遍。因为是每秒同步一次数据,最多只会损失一秒左右的数据。
- 将客户端请求的命令转换为网络协议格式
- 将协议内容字符串追加到变量server.aof_buf中
- 当AOF系统达到设定的条件时,会调用aof_fsync将数据写入磁盘
AOF的读取
- AOF保存的是数据协议格式的数据。所以只要将AOF中的数据转换为命令,模拟客户端重新执行一遍操作,就可以还原
- 创建模拟的客户端
- 读取AOF保存的文本,还原数据为原命令和原参数。然后使用模拟的客户端发出这个命令请求。
- 继续执行第二步,直到读取完AOF文件,
AOF重写流程
- AOF重写完成会向主进程发送一个完成的信号
- 会将AOF重写缓存中的数据全部写入到文件中
- 用新的AOF文件,覆盖原有的AOF文件
- AOF重写会把多个sql命令合并为1个,以此来减少空间
如何利用Redis对Mysql进行性能优化
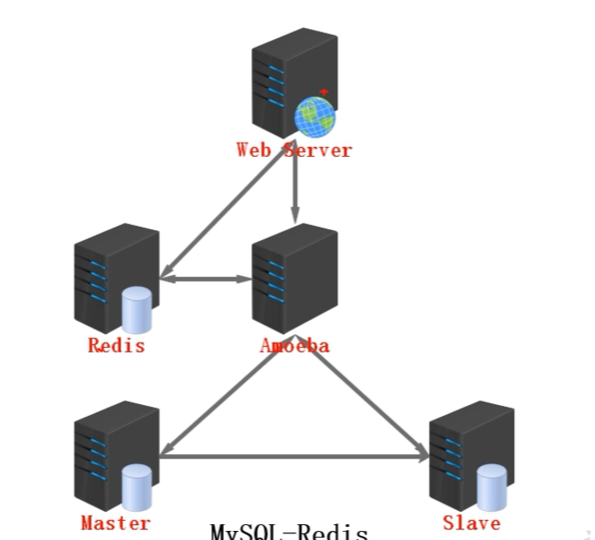
将Redis设置为缓存服务器,当用户访问完主从数据库,将数据返回给用户并再写入一个缓存到Redis中,如果用户访问一样,直接返回缓存即可。可以设置xx秒更新一次缓存。
Rredis乐观锁与悲观锁
悲观锁
- 很悲观,认为什么时候都会出问题,无论做什么都会加锁
- 每次拿数据的时候都认为别人会修改,所以每次拿数据都会先上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里面就用到了很多这种锁机制,比如行锁,表锁,读锁,写锁等。都是操作之前先上锁。
- 缺点:效率低,无法多人进行
乐观锁
- 很乐观,认为什么时候都不会出问题,所以不会上锁。更新数据的时候去判断一下,在此期间是否有人修改过数据。获取version,更新时比较version
- 每次拿数据都认为别人都不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间会判断别人有没有更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的
哨兵机制
当主机宕机,自动选举主机的模式
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
- 监控(Monitoring):哨兵进程会不断地检查Master和Slave是否运作正常。
- 提醒(Notification): 当被监控的某个节点出现问题时,哨兵进程可以通过API向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic Failover): 当一个Master不能正常工作时,哨兵进程会开始一次自动故障迁移操作,它会将失效Master的其中一个Slave升级为新的Master, 并让失效Master的其他Slave 改为复制新的Master.当客户端试图连接失效的Master时,Redis集群也会向客户端返回新Master的地址,使得Redis集群可以使用现在的Master替换失效Master。Redis Sentinel故障转移架构。
- 配置提供者:在哨兵模式下,客户端在初始化时连接的是哨兵节点集合,从中获取主节点的信息。
Tomcat面试题
Tomcat中使用虚拟主机来部署应用。
Tomcat默认端口是8080 8009 8005。
使用过哪些命令
查看文档使用 vi/vim/more/cat
解压缩使用 tar
查看日志 tail -f
查找日志/文件位置 find / -type d -iname
查看服务是否起来 ps -ef/netstat -ntlp
查看网络状态 ping
文档内容搜索 grep
自我介绍
1+2+1
您好面试官我是就读于郑州__的大三学生,我面试贵公司的运维工程师岗位。
面试前我仔细了解了该岗位的职责,12123语音平台的维护,监控与根据需求进行升级调整。因为我大二进行了专业的云计算培训,具有较好的Linux系统操作技术。在校期间成绩优异,并在河南省云计算赛项和信息安全评估拿到了一等奖。有较好的主动学习能力。个人也有写博客的习惯,并且愿意在互联网行业深耕。
我觉得我可以尝试这个岗位,听从领导和前辈的安排。希望在这个领域成长。十分希望能加入贵公司。
我们需要问的
1.请问我是否和本公司签约?我签约的合同是否是劳动合同?(研究所有可能会签劳务派遣合同)
2.请问公司是否是外包公司?(如果是外包公司,那么不推荐去)
3.请问公司中我的岗位具体做的是什么业务?
4.请问公司社保和公积金缴纳的基数是多少?
5.请问公司是否提供住宿或早午餐?基本工资是多少?如果是年薪制,每个月具体发多少?
6.请问这个岗位的工作日和周末休息日的加班情况如何?
你觉得你的缺点是什么?
回答:因为我是应届生的缘故,没有工作经验,这是我第一次进去工作,所以可能处理不好工作中的任务,不过我会努力学习的。(这里不推荐谈具体的一个缺点)
你觉得你的优点是什么?
回答:在学校中参加了很多项目和比赛,比起一般的同学更有优势。
如果是外地的,可能会问是否愿意留在这个身份工作?
回答:是的,因为我的大学是在这里读的,对这个地方比较熟悉,和家里人也商量过,我们一致决定愿意在这边工作两年试试

若有收获,就点个赞吧
0 人点赞
