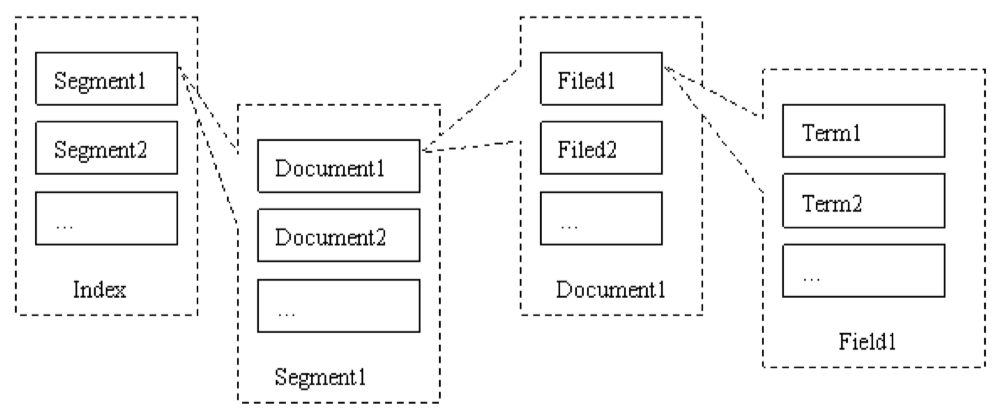
Lucene的索引结构是有层次结构的,主要分以下几个层次:
索引(Index):
一个目录一个索引,**在Lucene中一个索引是放在一个文件夹中的**。 <br /> 同一文件夹中的所有的文件构成一个Lucene索引。 <br />
段(Segment):
一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。
在建立索引的时候对性能影响最大的地方就是在向索引写入文档的时候, 所以在具体应用的时候就需要对此加以控制,段(Segment) 就是实现这种控制的 。
Lucene默认情况是每加入10份文档(Document)就从内存往index文件写入并生成一个段 (Segment) , 然后每10个段(Segment)就合并成一个段(Segment).
这些控制的变量如下:
IndexWriter属性 默认值 描述<br /> MergeFactory 10 控制segment合并的频率和大小<br /> MaxMergeDocs Int32.MaxValue 限制每个segment中包含的文档数<br /> MinMergeDocs 10 当内存中的文档达到多少时候再写入segment<br />
文档(Document):
文档是我们建索引的基本单位,**不同的文档是保存在不同的段中的,一个段可以包含多篇文档。 **<br />** 新添加的文档是单独保存在一个新生成的段中,随着段的合并,不同的文档合并到同一个段中。** <br />域(Field):
一篇文档包含不同类型的信息,可以分开索引,比如标题,内存,作者等,都可以保存在不同的域里。 <br /> **不同域的索引方式可以不同。** <br />词(Term):
词是索引的最小单位,是经过词法分析和语言处理后的字符串。
Lucene的索引结构中,即保存了正向信息,也保存了反向信息。
所谓正向信息:
按层次保存了从索引一直到词的包含关系:
:::info
索引(Index) –> 段(segment) –> 文档(Document) –> 域(Field) –> 词(Term)
:::
也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。
既然是层次结构,则每个层次都保存了本层次的信息以及下一层次的元信息,也即属性信息,比如一 本介绍中国地理的书,应该首先介绍中国地理的概况,以及中国包含多少个省,每个省介绍本省的基本概况 及包含多少个市,每个市介绍本市的基本概况及包含多少个县,每个县具体介绍每个县的具体情况。
所谓反向信息: 保存了词典到倒排表的映射:词(Term) –> 文档(Document)

若有收获,就点个赞吧
0 人点赞
