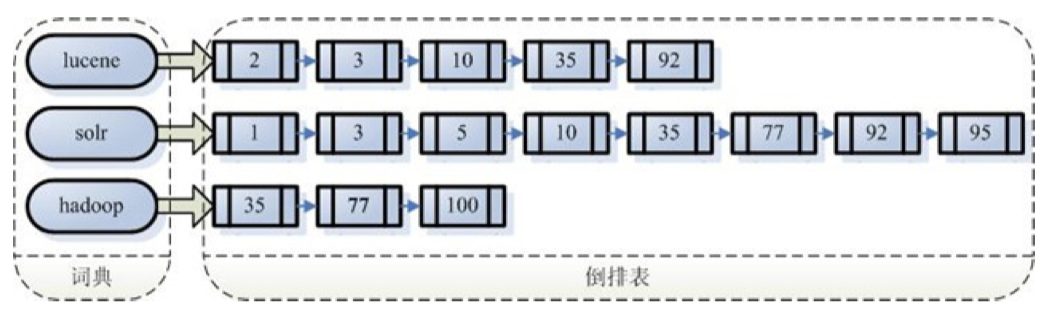
为何Lucene大数据量搜索快, 要分两部分来看:
一点是因为底层的倒排索引存储结构
另一点就是查询关键字的时候速度快 , 因为词典的索引结构
词典数据结构对比:
倒排索引中的词典位于内存,其结构尤为重要,有很多种词典结构,各有各的优缺点,最简单如排序数组,通过二分查找来检索数据,更快的有哈希表,磁盘查找有B树、B+树,但一个能支持TB级 数据的倒排索引结构需要在时间和空间上有个平衡,下图列了一些常见词典的优缺点:
很多数据结构均能完成字典功能,总结如下
| 数据结构 | 说明 |
|---|---|
| 排序列表Array/List | 使用二分法查找,不平衡 |
| HashMap/TreeMap | 性能高,内存消耗大,几乎是原始数据的三倍 |
| SkipList | 跳跃表,可快速查找词语,在lucene、redis、Hbase等均有实现。相对于TreeMap等结构,特别适合高并发场景 |
| Trie | 适合英文词典,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存 |
| DoubleArrayTrie | 适合做中文词典,内存占用小,很多分词工具均采用此种算法 |
| TernarySearchTree | 三叉树,每一个node有3个节点,兼具省空间和查询快的优点 |
| FiniteStateTransducers(FST) | 一种有限状态转移机,Lucene4有开源实现,并大量使用 |
FST的结构
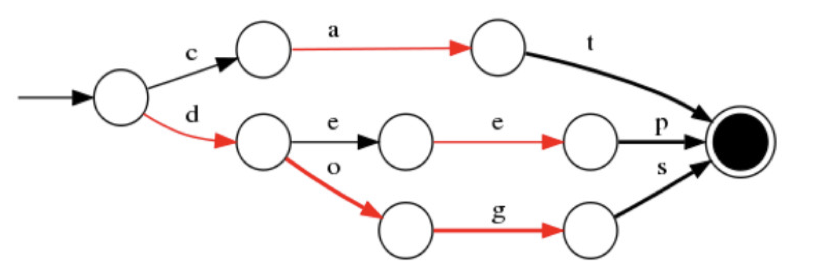
优点:内存占用率低,压缩率一般在3倍~20倍之间、模糊查询支持好、查询快
缺点:结构复杂、输入要求有序、更新不易

若有收获,就点个赞吧
0 人点赞
