ik分词器安装
https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.3.0
下载插件并安装(安装方式一)
1)在elasticsearch的bin目录下执行以下命令,es插件管理器会自动帮我们安装,然后等待安装完成:
/usr/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysisik/releases/download/v7.3.0/elasticsearch-analysis-ik-7.3.0.zip
2)下载完成后会提示 Continue with installation?输入
3)重启Elasticsearch 和Kibana
上传安装包安装 (安装方式二)
1)在elasticsearch安装目录的plugins目录下新建analysis-ik目录
#新建analysis-ik文件夹 mkdir analysis-ik#切换至 analysis-ik文件夹下cd analysis-ik#上传资料中的 elasticsearch-analysis-ik-7.3.0.zip#解压 unzip elasticsearch-analysis-ik-7.3.3.zip#解压完成后删除ziprm -rf elasticsearch-analysis-ik-7.3.0.zip
2)重启Elasticsearch 和Kibana
测试案例
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1)ik_max_word (常用)
会将文本做最细粒度的拆分
2)ik_smart
会做最粗粒度的拆分
我们先在Kibana测试一波输入下面的请求:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "南京市长江大桥"
}
POST _analyze
{
"analyzer": "ik_smart",
"text": "南京市长江大桥"
}
扩展词典使用
扩展词:就是不想让哪些词被分开,让他们分成一个词。比如上面的江大桥
自定义扩展词库
1)进入到 config/analysis-ik/(插件命令安装方式) 或 plugins/analysis-ik/config(安装包安装方式) 目录 下, 新增自定义词典
vim lagou_ext_dict.dic
输入 :江大桥
2)将我们自定义的扩展词典文件添加到IKAnalyzer.cfg.xml配置中
vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">lagou_ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">lagou_stop_dict.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">http://192.168.211.130:8080/tag.dic</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
停用词典使用
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、 an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行 索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的 速度,减少索引库文件的大小。
自定义停用词库
1)进入到 config/analysis-ik/(插件命令安装方式) 或 plugins/analysis-ik/config(安装包安装方式) 目录下, 新增自定义词典
vim lagou_stop_dict.dic
输入
的
了
啊
2)将我们自定义的停用词典文件添加到IKAnalyzer.cfg.xml配置中
3)重启Elasticsearch
同义词典使用
语言博大精深,有很多相同意思的词,我们称之为同义词,比如“番茄”和“西红柿”,“馒头”和“馍”等。在 搜索的时候,我们输入的可能是“番茄”,但是应该把含有“西红柿”的数据一起查询出来,这种情况叫做 同义词查询。 注意:扩展词和停用词是在索引的时候使用,而同义词是检索时候使用。
配置IK同义词
Elasticsearch 自带一个名为 synonym 的同义词 filter。为了能让 IK 和 synonym 同时工作,我们需要 定义新的 analyzer,用 IK 做 tokenizer,synonym 做 filter。听上去很复杂,实际上要做的只是加一段 配置。
1)创建/config/analysis-ik/synonym.txt 文件,输入一些同义词并存为 utf-8 格式。例如
lagou,拉勾
china,中国
1)创建索引时,使用同义词配置,示例模板如下
PUT /索引名称
{
"settings": {
"analysis": {
"filter": {
"word_sync": {
"type": "synonym",
"synonyms_path": "analysis-ik/synonym.txt"
}
},
"analyzer": {
"ik_sync_max_word": {
"filter": ["word_sync"],
"type": "custom",
"tokenizer": "ik_max_word"
},
"ik_sync_smart": {
"filter": ["word_sync"],
"type": "custom",
"tokenizer": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"字段名": {
"type": "字段类型",
"analyzer": "ik_sync_smart",
"search_analyzer": "ik_sync_smart"
}
}
}
}
以上配置定义了ik_sync_max_word和ik_sync_smart这两个新的 analyzer,对应 IK 的 ik_max_word 和 ik_smart 两种分词策略。ik_sync_max_word和 ik_sync_smart都会使用 synonym filter 实现同义词转
换
3)到此,索引创建模板中同义词配置完成,搜索时指定分词为ik_sync_max_word或ik_sync_smart。
4)案例
PUT /lagou-es-synonym
{
"settings": {
"analysis": {
"filter": {
"word_sync": {
"type": "synonym",
"synonyms_path": "analysis-ik/synonym.txt"
}
},
"analyzer": {
"ik_sync_max_word": {
"filter": ["word_sync"],
"type": "custom",
"tokenizer": "ik_max_word"
},
"ik_sync_smart": {
"filter": ["word_sync"],
"type": "custom",
"tokenizer": "ik_smart"
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_sync_max_word",
"search_analyzer": "ik_sync_max_word"
}
}
}
}
插入数据
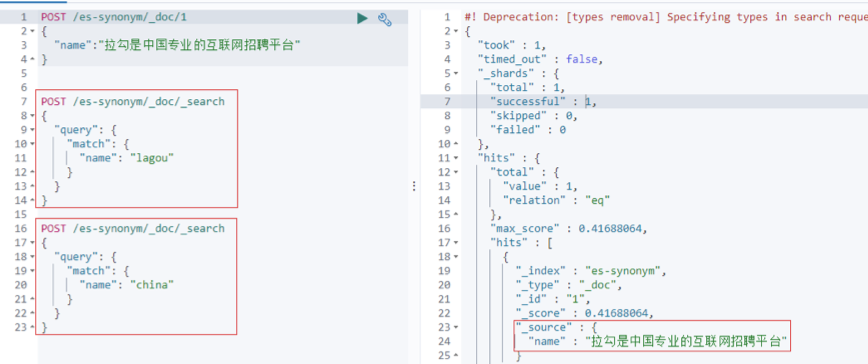
POST /lagou-es-synonym/_doc/1
{
"name":"拉勾是中国专业的互联网招聘平台"
}
使用同义词”lagou”或者“china”进行搜索
POST /lagou-es-synonym/_doc/_search
{
"query": {
"match": {
"name": "lagou"
}
}
}
热更新
elasticsearch开启加载外部词典功功能后,会每60s间隔进行刷新字典。
它有一个对应的核心配置文件名为:IKAnalyzer.cfg.xml,具体内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry>
</properties>
热更新 IK 分词使用方法,目前该插件支持热更新 IK 分词,通过上文在 IK 配置文件中提到的如下配置
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">location</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<entry key="remote_ext_stopwords">location</entry>
其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
- 该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
- 该 http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在 nginx 或其他简易 http server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
编写http服务, 连接mysql更新
@RestController
@RequestMapping("/keyWord")
@Slf4j
public class KeyWordDict {
private String lastModified = new Date().toString();
private String etag = String.valueOf(System.currentTimeMillis());
@RequestMapping(value = "/hot", method = {RequestMethod.GET,RequestMethod.HEAD}, produces="text/html;charset=UTF-8")
public String getHotWordByOracle(HttpServletResponse response,Integer type){
response.setHeader("Last-Modified",lastModified);
response.setHeader("ETag",etag);
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
String sql = "";
final ArrayList<String> list = new ArrayList<String>();
StringBuilder words = new StringBuilder();
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection(
"jdbc:oracle:thin:@192.168.114.13:1521:xe",
"test",
"test"
);
if(ObjectUtils.isEmpty(type)){
type = 99;
}
switch (type){
case 0:
sql = "select word from IK_HOT_WORD where type=0 and status=0";
break;
case 1:
sql = "select word from IK_HOT_WORD where type=1 and status=0";
break;
default:
sql = "select word from IK_HOT_WORD where type=99";
break;
}
stmt = conn.createStatement();
rs = stmt.executeQuery(sql);
while(rs.next()) {
String theWord = rs.getString("word");
System.out.println("hot word from mysql: " + theWord);
words.append(theWord);
words.append("\n");
}
return words.toString();
} catch (Exception e) {
e.printStackTrace();
} finally {
if(rs != null) {
try {
rs.close();
} catch (SQLException e) {
log.error("资源关闭异常:",e);
}
}
if(stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
log.error("资源关闭异常:",e);
}
}
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
log.error("资源关闭异常:",e);
}
}
}
return null;
}
@RequestMapping(value = "/update", method = RequestMethod.GET)
public void updateModified(){
lastModified = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date());
etag = String.valueOf(System.currentTimeMillis());
}
}
updateModified方法为单独更新lastModified与etag,用于判断ik是否需要重新加载远程词库,具体关联数据库操作代码时自行扩展
/data/elasticsearch-7.2.0/plugins/ik/config/IKAnalyzer.cfg.xml
ik配置文件修改
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.xx.xx:8080/keyWord/hot?type=0</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启es加载ik配置文件,会看到如下日志信息,说明远程的词典加载成功了。
使用建议
可以和pinyin分词结合起来
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
analyzer\search_analyzer分词类型选择:分词时我们分别插入文档时,将text类型的字段做最细的分词然后插入倒排索引,在查询时,先对要查询的text类型的输入做最粗分词,再去倒排索引搜索。举个例子:假如插入数据为”苹果手机”的时候我们尽可能多拆为”苹果”,”手机”,我们在搜索的”小米手机”时候,就不会查询出苹果手机这条数据了
长度限制
将搜索结果展示的粒度最小为词,而非字?
- 因为单字一般情况下载关联度比较低,可能会推荐很多不相关的数据,从而让用户感觉搜索体验不好。
- 举例:我搜索“南山区的“,我想搜索结果中,只展示命中“南山区”的数据,而不要展示命中“的”的数据
```java
curl -XPUT “localhost:9200/starry_sky-question-v1.0.2?pretty=true” -H ‘content-type: application/json’ —data ‘
{
“settings”: {
}, “mappings”: {"analysis": { "filter": { "len": { "type": "length", "min": 2 } }, "analyzer": { "ik_smart_filter_length_less_2": { "tokenizer": "ik_smart", "filter": [ "len" ] } } }, "number_of_shards": 3, "number_of_replicas": 1
} } ‘"properties": { "id": { "type": "keyword" }, "title": { "type": "completion", "analyzer": "ik_max_word", "search_analyzer": "ik_smart_filter_length_less_2" }, "content": { "type": "completion", "analyzer": "ik_max_word", "search_analyzer": "ik_smart_filter_length_less_2" }, "status": { "type": "keyword" } }
```

若有收获,就点个赞吧
0 人点赞
