es通过下面两种方式处理关联关系
- Nested Object
- Parent/Child
Object
Objet类型:此时ES的文档组织会默认解析为扁平化的结构,此时对象数组的同一个字段会组织在一起。 ```java { “region”: “US”, “manager”: [{ “age”: 30, “name”: {
},{"first": "John1","last": "Smith1"
“age”: 18, “name”: { “first”: “John2”, “last”: “Smith2” } }
在内部,此文档被索引为一个简单,平坦的键值对列表,平坦化结构如下
```java
{
"region": "US",
"manager.age": [30,18],
"manager.name.first": ["John1","John2"],
"manager.name.last": ["Smith1","Smith2"]
}
嵌套类型Nested
nested 类型是一种对象类型的特殊版本,它允许索引对象数组,独立地索引每个对象
nested 类型是一种特别的 object 数据类型,其允许数组中的对象可以被单独索引,使它们可以被独立地检索。
嵌套类型与Object类型的区别
PUT /my_index/blogpost/1
{
"title": "Nest eggs",
"body": "Making your money work...",
"tags": [ "cash", "shares" ],
"comments": [
{
"name": "John Smith",
"comment": "Great article",
"age": 28,
"stars": 4,
"date": "2014-09-01"
},
{
"name": "Alice White",
"comment": "More like this please",
"age": 31,
"stars": 5,
"date": "2014-10-22"
}
]
}
如果我们使用动态映射,commets字段将会被自动创建成一个object对象类型的字段
由于所有的内容都在一个文档中,所以在查询的时候不需要对bolg posts和commets进行联合查询,搜索性能也会更好
但是有时候会出现如下的一个问题:
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "comments.name": "Alice" }},
{ "match": { "comments.age": 28 }}
]
}
}
}
可以看到JohnSimth和AliceWhite都被搜索了出来,因为John的age与搜索条件中的age为28匹配,Alice与搜索条件中name含有Alice匹配
造成这个的原因是在索引中结构化的JSON文档被扁平化成一个如下的键值对形式:
{
"title": [ eggs, nest ],
"body": [ making, money, work, your ],
"tags": [ cash, shares ],
"comments.name": [ alice, john, smith, white ],
"comments.comment": [ article, great, like, more, please, this ],
"comments.age": [ 28, 31 ],
"comments.stars": [ 4, 5 ],
"comments.date": [ 2014-09-01, 2014-10-22 ]
}
Alice和31、John和2014-09-01之间的相关性被丢失了,对象类型的字段在存储一个单个的对象时是非常有用的,但是对存储一系列对象数组时就变得没用了。
这个问题可以使用nested对象来解决。将comments映射为一个nested对象类型而不是一个普通的object类型,每个nested对象被索引为隐藏的单独文档,如下所示:
{ //1
"comments.name": [ john, smith ],
"comments.comment": [ article, great ],
"comments.age": [ 28 ],
"comments.stars": [ 4 ],
"comments.date": [ 2014-09-01 ]
}
{ //2
"comments.name": [ alice, white ],
"comments.comment": [ like, more, please, this ],
"comments.age": [ 31 ],
"comments.stars": [ 5 ],
"comments.date": [ 2014-10-22 ]
}
{//3
"title": [ eggs, nest ],
"body": [ making, money, work, your ],
"tags": [ cash, shares ]
}
- 是第一个nested对象
- 是第二个nested对象
- 是根(父)文档
通过分别对每个嵌套对象进行索引,对象中字段之间的关系可以被维持。我们可以执行一个查询,只有match发生在同一个nested对象时它才会匹配。
不仅如此,由于nested对象被索引的方式,在查询的时候联合nested文档到根文档的速度是非常快的,几乎与查询单个的的文档一样快。
另外,nested文档是隐藏的,我们不能直接访问它。当更新、添加或者删除一个nested对象,必须重新索引整个文档,需要注意的是,发送一个搜索请求时返回的是整个文档而不是只返回nested对象
复杂的映射
"comments": {
"type": "nested",
"properties": {
"username": {
"type": "keyword",
"ignore_above": 100
},
"date": {
"type": "date"
}
}
}
查询
需要用nested查询
- key 以 “nested” 开头
- path 就是嵌套对象数组的字段名
- 其他
- score_mode (可选的)匹配子对象的分数相关性分数。avg (默认,使用所有匹配子对象的平均相关性分数)
- ignore_unmapped (可选的)是否忽略 path 未映射,不返回任何文档而不是错误。默认为 false,如果 path 不对就报错
普通查询
GET my_index/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{ "match": { "user.first": "Alice" }},
{ "match": { "user.last": "White" }}
]
}
},
"inner_hits": {
"highlight": {
"fields": {
"user.first": {}
}
}
}
}
}
}
bool查询
GET /my_index/_search?pretty
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "users",
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "Alice"
}
},
{
"match": {
"users.age": 18
}
}
]
}
}
}
}
]
}
}
}
需要注意的是:
- 使用 nested 查询来搜索
- 使用 nested 和 reverse_nested 聚合来分析
- 使用 nested sorting 来排序
使用 nested inner hits 来检索和高亮
参数
参数:
(1)index.mapping.nested_fields.limit
一个索引最大支持的nested类型个数
(2)index.mapping.nested_objects.limit
一个nested类型支持的最大对象数
- 参数类型:动态参数
- 默认值:
(1)index.mapping.nested_fields.limit : 50
(2)index.mapping.nested_objects.limit : 10000
父子类型
简介
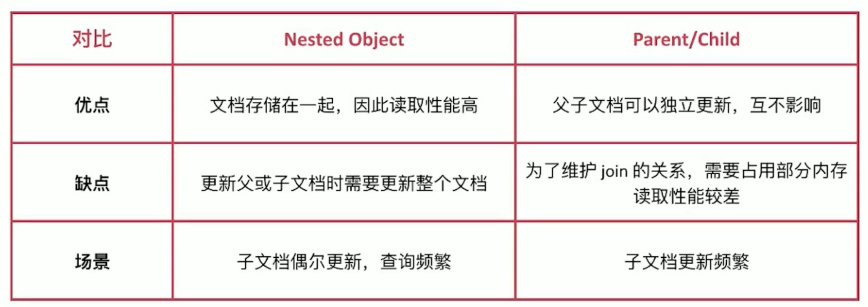
父-子关系文档 在实质上类似于 nested model :允许将一个对象实体和另外一个对象实体关联起来。 而这两种类型的主要区别是:在 nested objects 文档中,所有对象都是在同一个文档中,而在父-子关系文档中,父对象和子对象都是完全独立的文档。
父-子关系的主要作用是允许把一个 type 的文档和另外一个 type 的文档关联起来,构成一对多的关系:一个父文档可以对应多个子文档 。与 nested objects 相比,父-子关系的主要优势有:
更新父文档时,不会重新索引子文档。
最大优势! 创建,修改或删除子文档时,不会影响父文档或其他子文档。这一点在这种场景下尤其有用:子文档数量较多,并且子文档创建和修改的频率高时。
子文档可以作为搜索结果独立返回
需要注意的是,为了维护父子文档的关系需要占用额外的内存资源,并且读取性能相对较差。但由于父子文档是互相独立的,所以适合子文档更新频率高的场景。
注意
查询创建注意:查询父文档,Hits中,只会返回子文档,查询子文档,Hits中只会返回,父文档。
插入子文档注意:子文档必须和父文档在同一分片上,父文档,有路由存在时,插入子文档必须也填上和父文档相同的路由。
- 父子文档都可以独立返回,对于某些场景很适用,比如主表信息是一些基本不变的数据,而子表信息经常增删改,并且子表信息经常有查询场景,这样就很适合使用父子文档。
- 父子文档需要在同一分片上,当然,我们无需做特殊处理,默认就会为我放入同一个分片,其实原理是这样的,Elasticsearch会根据routing中的参数去看父文档所在分片在哪,然后将对应文档存储进去。
- 父子文档查询效率相对嵌套文档较低,官网说是5-10倍左右
映射
创建索引名和type均为blog的索引,从上面数据可以看出,其实父文档(博客内容)与子文档分别用不同的字段来存储对应的数据,不过在创建索引文档的时候需要指定父子文档的关系,即文章为parent,留言为child,创建索引语句如下:
PUT http://localhost:9200/blog/
{
"mappings": {
"blog": {
"properties": {
"date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"comment": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"age": {
"type": "long"
},
"body": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"relation": {
"type": "join", //指定类型
"relations": { //指定父子关系
// parent是父类型名称, child是子类型名称, 都可以自己定义
// "blog": "comment" 这样也行
"parent": "child"
}
}
}
}
}
}
插入数据
插入父文档数据,需要指定上文索引结构中的relation为parent,如下:
POST http://localhost:9200/blog/blog/1/
{
"title":"这是一篇文章",
"body":"这是一篇文章,从哪里说起呢? ... ...",
"relation":"parent" //创建父文档, 指定父类型
}

插入子文档,需要在请求地址上使用routing参数指定是谁的子文档,并且指定索引结构中的relation关系,如下:
//指定routing, 确保在一个分片上, 一般用父文档id
POST http://localhost:9200/blog/blog/2?routing=1
{
"name":"张三",
"comment":"写的不错",
"age":28,
"date":"2020-05-04",
"relation":{
"name":"child", //指定子类型
"parent":1 //指定父文档id
}
}
POST http://localhost:9200/blog/blog/3?routing=1
{
"name":"李四",
"comment":"写的很好",
"age":20,
"date":"2020-05-04",
"relation":{
"name":"child",
"parent":1
}
}
POST http://localhost:9200/blog/blog/4?routing=1
{
"name":"王五",
"comment":"这是一篇非常棒的文章",
"age":31,
"date":"2020-05-01",
"relation":{
"name":"child",
"parent":1
}
}
查询
普通查询这里不进行赘述,关系查询的话其实很好理解,大致分为两种特殊情况:
- 根据父文档查询子文档 has_child
- 根据子文档查询父文档 has_parent
- parent_id 返回某父文档的子文档
// 返回某父文档的子文档
{
"query": {
"parent_id": { //关键词
"type":"child", //指定子文档的类型
"id": "2" //指定父文档的id
}
}
}
接下来我们来看如何进行关系查询,首先看一下通过子文档查询父文档,比如这样的场景,查询名称是张三的人留言的文章,查询语句如下:
{
"query": {
"has_child": { //关键词
"type":"child", //子文档类型
"query": { //子文档查询条件
"match": {
"name": "张三"
}
}
}
}
}
使用has_child来根据子文档内容查询父文档,其实type就是创建文档时,子文档的标识。
在使用子查父的时候,可以添加一些筛选条件来增强匹配的结果,比如最大匹配max_children和最小匹配min_children,这里有点类似should查询的minimum_should_match,感兴趣的可以去官网了解更多的细节。
到这里,其实对Elasticsearch特性了解的读者就会知道如何根据父文档查询子文档了,只需要注意一点,父查子type需要修改成parent_type,其余都与自查父类似,比如查询标题为“这是一篇文章”的数据的留言内容,查询语句如下:
{
"query": {
"has_parent": { //关键词
"parent_type":"parent", //指定父文档类型
"query": { //指定父文档的查询条件
"match": {
"title": "这是一篇文章"
}
}
}
}
}
聚合查询与嵌套文档类似,比较简单,这里在说明另外一种场景:祖辈和孙辈可以创建吗?比如本文中的留言如果它也有子文档,那么可以根据文章查询孙辈吗?
答案是可以的,只需要在has_child里面在嵌套一层has_child查询即可。
区别
父子文档在理解上来说,可以理解为一个关联查询,有些类似MySQL中的JOIN查询,通过某个字段关系来关联。
父子文档与嵌套文档主要的区别在于,父子文档的父对象和子对象都是独立的文档,而嵌套文档中都在同一个文档中存储,如下图所示: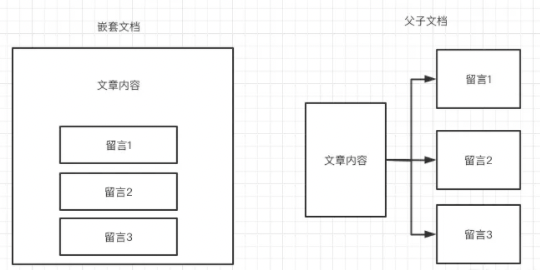
对比嵌套文档来说,父-子关系的主要优势有:
- 更新父文档时,不会重新索引子文档。
- 创建,修改或删除子文档时,不会影响父文档或其他子文档。这一点在这种场景下尤其有用:子文档数量较多,并且子文档创建和修改的频率高时。
- 子文档可以作为搜索结果独立返回。

若有收获,就点个赞吧
0 人点赞
