Elasticsearch默认脚本语言为Painless。其他lang插件使您可以运行以其他语言编写的脚本。
| 语言 | 沙盒 | 是否需要插件 | 备注 |
|---|---|---|---|
| painless | 是 | 内置的 | 默认脚本语言 |
| expression | 是 | 内置的 | 快速的自定义排名和排序 |
| mustache | 是 | 内置的 | 范本 |
基础语法
"script": {"lang": "...","source" | "id": "...","params": { ... }}
lang: 定义脚本使用的语言, 默认painless
source, id: 脚本的主体, source后面跟着内联的脚本代码, id后面跟着脚本的id,id存储脚本指定脚本本身, 具体代码存在于脚本id对应的代码中
params: 定义一些变量的值, 使用params可以减少脚本的编译次数. 因为如果变量的值硬编码到代码中, 每次进行变量值得更改都会对脚本进行重新编译. 使用params则不会重新编译脚本.
script.context.field.max_compilations_rate=75/5m 脚本的默认编译频率, 定义脚本的编译频率为5分钟75个, 当超过75个时会抛出circuit_breaking_exception异常.
es遇到一个新脚本时,将对其进行编译并将编译后的版本存储在缓存中。编译可能是一个繁重的过程。如果我们有相同逻辑的脚本只是参数不一样的时候,应以命名形式传递变量,而不是将值硬编码到脚本本身中。
简单脚本
当脚本中source只有很简单的内容,不涉及参数变化等复杂逻辑可以直接在script后使用字符串而不是对象。
下面两个脚本是等价的:
“ script” :“ ctx._source.likes ++”
"script": {"source": "ctx._source.likes++"}
脚本代码的存储
// 我们可以将脚本保存在集群中,然后使用它的时候只需要指定其ID。// POST _scripts/{id}POST _scripts/calculate-score{"script": {"lang": "painless","source": "Math.log(_score * 2) + params['my_modifier']"}}
查询脚本
查询脚本需要使用/_scripts/{id}的GET请求
GET _scripts/calculate-score
脚本使用
GET my-index-000001/_search{"query": {"script_score": {"query": {"match": {"message": "some message"}},"script": {"id": "calculate-score","params": {"my_modifier": 2}}}}}
删除脚本
DELETE _scripts/calculate-score
默认情况下,脚本没有基于时间的到期,但是可以通过script.cache.expire设置来更改此行为。也可以使用该script.cache.max_size设置来配置此缓存的大小。默认情况下,缓存大小为100。
脚本中访问文档字段和特殊变量
根据脚本使用的不同位置,它们可以访问的变量的文档字段是不同的。
更新操作中脚本访问数据
在update,update-by-query或reindex API中使用的脚本将有权访问显示以下内容的ctx变量
| 参数 | 作用 |
|---|---|
| ctx._source | 访问文档_source字段 |
| ctx.op | 应用于文档的操作:index或delete |
| ctx._index | 访问文档元字段,其中某些字段可能是只读的 |
在搜索和聚合中脚本访问数据
进行搜索和聚合操作中的脚本,除了会对命中的数据进行脚本字段操作之外,针对可能与查询或汇总匹配的文档都会执行一次。这使得搜索中脚本操作的文档量会根据实际拥有的文档数量,对于比较大的业务数据会非常庞大,所以要求脚本必须足够的效率。
官方建议使用doc-values或 stored fields段或_source field从脚本访问字段值 ,
官方提供的三种访问方式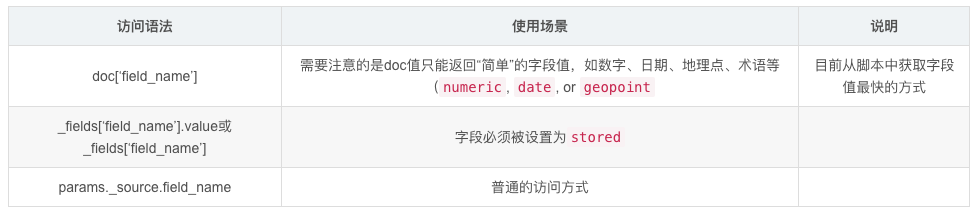
例子
现在创建一个测试用的索引
PUT test_index/_mapping{"properties": {"name": {"type": "text","store": true},"desc": {"type": "text"},"num": {"type":"long"}}}PUT test_index/_doc/2?refresh{"name":"测试","desc":"描述","num" : 100}
doc-values
目前从脚本中获取字段值最快的方式是使用
**doc['field_name']**格式,此方法会从doc值中检索字段数据,但是需要注意的是需要注意的是doc值只能返回“简单”的字段值,如数字、日期、地理点、术语等,如果字段是多值的,则只能返回这些值的数组。它不能返回JSON对象。
在对上面的索引执行脚本test的时候会成功完成, 但是执行脚本test2的时候会发生错误
GET test_index/_search{"script_fields": {"test": {"script": {"lang": "expression","source": "doc['num']"}}}}GET test_index/_search{"script_fields": {"test2": {"script": {"lang": "expression","source": "doc['name']"}}}}
执行脚本test2会发生错误
"reason": "Fielddata is disabled on text fields by default.Set fielddata=true on [name] in order to load fielddata in memory by uninverting the inverted index.Note that this can however use significant memory.Alternatively use a keyword field instead."
官方对此说明是
如果启用了fielddata, doc[‘field’]语法也可以用于分析的文本字段,但是要注意:在文本字段上启用fielddata需要将所有的术语加载到JVM堆中,这在内存和CPU方面都非常昂贵。从脚本访问文本字段很少有意义。
params._fields['field_name']
使用params._fields[‘field_name’]可以访问被设置为”store”: true的参数。但是对没有设置此参数的数据使用此方法时会抛出异常
GET test_index/_search{"script_fields": {"test": {"script": {"lang": "painless","source": "params._fields['desc']"}}}}
上面请求的desc没有被设置”store”: true此时会返回内容
"error": {"root_cause": [{"type": "illegal_argument_exception","reason": "cannot write xcontent for unknown value of type class org.elasticsearch.search.lookup.FieldLookup"}],"type": "illegal_argument_exception","reason": "cannot write xcontent for unknown value of type class org.elasticsearch.search.lookup.FieldLookup"}
params._source.field_name
三种访问方式对比
存储字段取值方式比doc取值慢得多。doc值针对访问许多文档中特定字段的值进行了优化,使用_source或存储字段取值它们针对每个结果返回多个字段进行了优化。对于需要获取结果中内容生成脚本字段时是有意义的。但是对于一些聚合或者排序操作的时候,doc取值会更好。
_source和存储字段取值。_source字段只是一个特殊的存储字段,因此其性能与其他存储字段类似。使用存储字段取值而不是_source字段取值可能的场景是在当在_source非常大的时候访问几个小的存储字段而不是整个_source的成本更低。
脚本安全性的配置
默认情况下,允许执行所有脚本类型。通过修改script.allowed_types我们可以指定允许执行的类型;
## 只允许执行内联脚本,而不允许执行存储脚本(或任何其他类型)。script.allowed_types: inline
相关配置选项:
- both 同时支持inline和stored
- inline 内联脚本
- stored 存储脚本
- none 都不支持
默认情况下,允许执行所有脚本上下文。通过修改script.allowed_contexts只允许一部分操作执行
若要指定不允许上下文,请将 script.allowe_contexts 设置为 none
## 这将只允许执行搜索和更新脚本,而不允许执行aggs或插件脚本(或任何其他上下文)script.allowed_contexts: search, update
脚本对文档进行更新
PUT my-index-000001/_doc/1{"counter" : 1,"tags" : ["red"]}// 将count加上4POST my-index-000001/_update/1{"script" : {"source": "ctx._source.counter += params.count","lang": "painless","params" : {"count" : 4}}}// 增加tags的元素POST my-index-000001/_update/1{"script": {"source": "ctx._source.tags.add(params['tag'])","lang": "painless","params": {"tag": "blue"}}}// If the list contains duplicates of the tag, this script just removes one occurrence.// 如果集合中有多个相同的值, 只删除第一个POST my-index-000001/_update/1{"script": {"source": "if (ctx._source.tags.contains(params['tag'])) { ctx._source.tags.remove(ctx._source.tags.indexOf(params['tag'])) }","lang": "painless","params": {"tag": "blue"}}}// 增加新的字段POST my-index-000001/_update/1{"script" : "ctx._source.new_field = 'value_of_new_field'"}// 删除字段POST my-index-000001/_update/1{"script" : "ctx._source.remove('new_field')"}// 如果tags字段中包含green, 则删除该文档, 否则不做操作POST my-index-000001/_update/1{"script": {"source": "if (ctx._source.tags.contains(params['tag'])) { ctx.op = 'delete' } else { ctx.op = 'none' }","lang": "painless","params": {"tag": "green"}}}// doc.containsKey('field')
脚本变量
ctx._source.field: add, contains, remove, indexOf, length
ctx.op: The operation that should be applied to the document: index or delete
ctx._index: Access to document metadata fields
_score 只在script_score中有效
doc[‘field’], doc[‘field’].value: add, contains, remove, indexOf, length
脚本缓存
- You can change this behavior by using the
script.cache.expiresetting. Use thescript.cache.max_sizesetting to configure the size of the cache.The size of scripts is limited to 65,535 bytes. Set the value ofscript.max_size_in_bytesto increase that soft limit. Cache sizing is important. Your script cache should be large enough to hold all of the scripts that users need to be accessed concurrently.
脚本优化
使用脚本缓存, 预先缓存可以节省第一次的查询时间
- 使用ingest pipeline进行预先计算
- 相比于_source.field_name使用doc[‘field_name’]语法速度更快, doc语法使用doc value , 列存储 ```json
// 根据分数相加结果进行排序 GET /my_test_scores/_search { “query”: { “term”: { “grad_year”: “2099” } }, “sort”: [ { “_script”: { “type”: “number”, “script”: { “source”: “doc[‘math_score’].value + doc[‘verbal_score’].value” }, “order”: “desc” } } ] }
// 在索引中新加一个字段存储计算结果 PUT /my_test_scores/_mapping { “properties”: { “total_score”: { “type”: “long” } } }
// 使用ingest pipeline先将计算结果作为值存储起来 PUT _ingest/pipeline/my_test_scores_pipeline { “description”: “Calculates the total test score”, “processors”: [ { “script”: { “source”: “ctx.total_score = (ctx.math_score + ctx.verbal_score)” } } ] }
// 重新索引时使用ingest pipeline POST /_reindex { “source”: { “index”: “my_test_scores” }, “dest”: { “index”: “my_test_scores_2”, “pipeline”: “my_test_scores_pipeline” } }
// 索引新文档时使用ingest pipeline POST /my_test_scores_2/_doc/?pipeline=my_test_scores_pipeline { “student”: “kimchy”, “grad_year”: “2099”, “math_score”: 1200, “verbal_score”: 800 }
// 查询 GET /my_test_scores_2/_search { “query”: { “term”: { “grad_year”: “2099” } }, “sort”: [ { “total_score”: { “order”: “desc” } } ] }
// stored field 用法 PUT my-index-000001 { “mappings”: { “properties”: { “full_name”: { “type”: “text”, “store”: true }, “title”: { “type”: “text”, “store”: true } } } }
PUT my-index-000001/_doc/1?refresh { “full_name”: “Alice Ball”, “title”: “Professor” }
GET my-index-000001/_search { “script_fields”: { “name_with_title”: { “script”: { “lang”: “painless”, “source”: “params._fields[‘title’].value + ‘ ‘ + params._fields[‘full_name’].value” } } } }
用到脚本的命令
- function_score
- script_score
- aggregation
- rescore

若有收获,就点个赞吧
0 人点赞
