简介
SearchRequest
- 首先创建搜索请求对象:
SearchRequest searchRequest = new SearchRequest();
SearchRequest支持的部分参数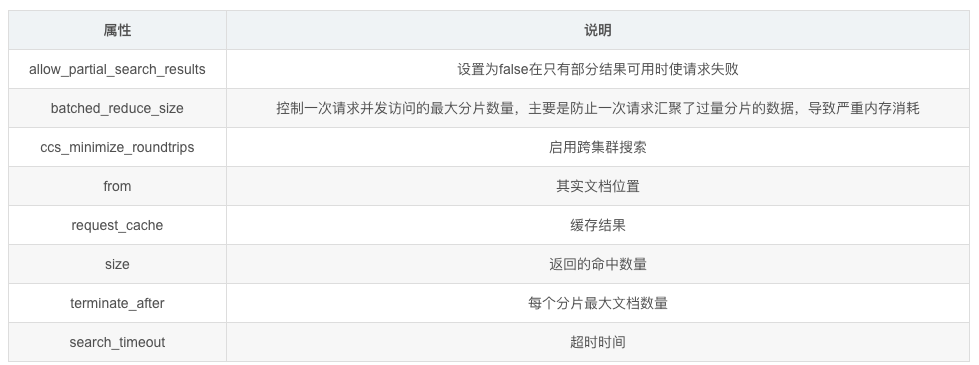
- 对搜索请求进行基本参数设置
设置查询指定的某个文档库:
SearchRequest searchRequest = new SearchRequest(“posts”); searchRequest.types(“doc”);
查询多个文档库,其中多个文档库名之间用逗号隔开
SearchRequest searchRequest = new SearchRequest(“posts2”,”posts”, “posts2”, “posts1”);
或者这样设置:
SearchRequest searchRequest = new SearchRequest(); // 指定只能在哪些文档库中查询:可以添加多个且没有限制,中间用逗号隔开searchRequest.indices(“posts2”,”posts”, “posts2”, “posts1”);
默认是去所有文档库中进行查询
- 指定查询的文档库中的文档类型:
searchRequest.types(“doc1”);
或多种类型,同样是文档类型之间用逗号隔开:
searchRequest.types(“doc1”, “doc1”, “doc2”);
- 设置指定查询的路由分片
searchRequest.routing(“routing”);
- 设置路由参数
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
用preference方法去指定优先去某个分片上去查询(默认的是随机先去某个分片)
searchRequest.preference(“_local”);
- 向主搜索请求中可以添加搜索内容的特征参数
创建 搜索内容参数设置对象:SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
将SearchSourceBuilder对象添加到搜索请求中:
searchRequest.source(searchSourceBuilder);
SearchSourceBuilder(通过这个添加查询条件)
为搜索的文档内容对象SearchSourceBuilder设置参数:
大多控制搜索内容的行为参数都可以在SearchSourceBuilder上进行设置,SearchSourceBuilder包含与Rest API的搜索请求主体中类似的参数选项。 以下是一些常见选项的几个示例:
1)查询包含指定的内容:
a.查询所有的内容
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
b.查询包含关键词字段的文档:如下,表示查询出来所有包含user字段且user字段包含kimchy值的文档
sourceBuilder.query(QueryBuilders.termQuery(“user”, “kimchy”));
c.上面是基于QueryBuilders查询选项的,另外还可以使用MatchQueryBuilder配置查询参数
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("user", "kimchy");// 启动模糊查询matchQueryBuilder.fuzziness(Fuzziness.AUTO);// 在匹配查询上设置前缀长度选项matchQueryBuilder.prefixLength(3);// 设置最大扩展选项以控制查询的模糊过程matchQueryBuilder.maxExpansions(10);
d.也可以使用QueryBuilders实用程序类创建QueryBuilder对象。此类提供了可用于使用流畅的编程样式创建QueryBuilder对象的辅助方法:
QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy").fuzziness(Fuzziness.AUTO).prefixLength(3).maxExpansions(10);
注:无论用于创建它的方法是什么,都必须将QueryBuilder对象添加到SearchSourceBuilder
searchSourceBuilder.query(matchQueryBuilder);
- 设置查询的起始索引位置和数量:如下表示从第1条开始,共返回5条文档数据
sourceBuilder.from(0); sourceBuilder.size(5);
- 设置查询请求的超时时间:如下表示60秒没得到返回结果时就认为请求已超时
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
10 . 添加排序
在SearchSourceBuilder允许添加一个或多个SortBuilder实例。有四个特殊的实现(Field-,Score-,GeoDistance-和ScriptSortBuilder)
//根据打分降序排列(默认)sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC));//也按_id字段升序排序sourceBuilder.sort(new FieldSortBuilder("id").order(SortOrder.ASC));
- 默认情况下,搜索请求会返回文档_source的内容,但与Rest API中的内容一样,您可以覆盖此行为。例如,您可以完全关闭_source检索:
sourceBuilder.fetchSource(false);
该方法还接受一个或多个通配符模式的数组,以控制以更精细的方式包含或排除哪些字段
String[] includeFields = new String[] {"title", "user", "innerObject.*"};String[] excludeFields = new String[] {"_type"};sourceBuilder.fetchSource(includeFields, excludeFields);
高亮显示
突出显示搜索结果可以通过设置来实现HighlightBuilder的 SearchSourceBuilder。通过向中添加一个或多个HighlightBuilder.Field实例,可以为每个字段定义不同的突出显示行为HighlightBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();HighlightBuilder highlightBuilder = new HighlightBuilder();//添加高亮显示的字段HighlightBuilder.Field highlightTitle =new HighlightBuilder.Field("title");//指定高亮的类型highlightTitle.highlighterType("unified");//将高亮的相关配置告诉BuilderhighlightBuilder.field(highlightTitle);//新加一个高亮显示的字段HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user");highlightBuilder.field(highlightUser);//将高亮的相关配置告诉上级BuildersearchSourceBuilder.highlighter(highlightBuilder);
聚合
可以通过先创建适当的集合AggregationBuilder,然后将其设置在上,将聚合添加到搜索中SearchSourceBuilder。在以下示例中,我们terms在公司名称上创建一个汇总,并在公司中员工的平均年龄上进行子汇总:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company").field("company.keyword");aggregation.subAggregation(AggregationBuilders.avg("average_age").field("age"));searchSourceBuilder.aggregation(aggregation);
- Requesting Suggestions
要将“Suggestions”添加到搜索请求中,请使用SuggestionBuilder可从SuggestBuilders工厂类轻松访问的实现之一。建议使用者需要添加到顶层SuggestBuilder,它本身可以在上设置 SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//TermSuggestionBuilder为user字段和文本创建一个新的kmichy
SuggestionBuilder termSuggestionBuilder =
SuggestBuilders.termSuggestion("user").text("kmichy");
SuggestBuilder suggestBuilder = new SuggestBuilder();
//添加建议生成器并命名 suggest_user
suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder);
searchSourceBuilder.suggest(suggestBuilder);
想要使用 聚合(aggregations),就必须指定下边的为true
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.profile(true);
- 返回结果同步
当SearchRequest以以下方式执行时,客户端将等待SearchResponse返回,然后继续执行代码:
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
IOException如果无法在 high-level REST client 中解析REST响应,请求超时或类似的情况(如果服务器没有响应返回),则同步调用可能会引发错误。
在服务器返回4xx或5xx错误代码的情况下,高级客户端尝试改为解析响应正文错误详细信息,然后引发泛型ElasticsearchException并将原始的ResponseException作为抑制的异常添加到它。
[
](https://blog.csdn.net/star1210644725/article/details/106014809)
返回结果异步
执行 SearchRequest也可以异步方式完成,以便客户端可以直接返回。用户需要通过将请求和侦听器传递给异步搜索方法来指定如何处理响应或潜在的失败的SearchRequest执行和ActionListener对执行完毕时使用:
client.searchAsync(searchRequest, RequestOptions.DEFAULT, listener);异步方法不会阻塞并立即返回。完成ActionListener后,onResponse如果执行成功完成,则使用onFailure方法进行调用;如果执行失败,则使用方法进行调用。故障情况和预期的异常与同步执行情况相同。
典型的侦听器search如下所示:ActionListener<SearchResponse> listener = new ActionListener<SearchResponse>() { @Override public void onResponse(SearchResponse searchResponse) { //成功后执行的内容 } @Override public void onFailure(Exception e) { //失败后执行的内容 } };在此之后,SearchSourceBuilder只需要将添加到 SearchRequest:
SearchRequest searchRequest = new SearchRequest(); searchRequest.indices("posts"); searchRequest.source(sourceBuilder);SearchResponse
在SearchResponse由执行搜索返回提供有关搜索执行本身以及访问返回文档的详细信息。首先,有关于请求执行本身的有用信息,例如HTTP状态代码,执行时间或请求是提前终止还是超时:
RestStatus status = searchResponse.status(); TimeValue took = searchResponse.getTook(); Boolean terminatedEarly = searchResponse.isTerminatedEarly(); boolean timedOut = searchResponse.isTimedOut();其次,响应还提供有关受搜索影响的分片总数以及成功与不成功分片的统计信息,从而提供有关分片级别执行的信息。可能的失败也可以通过遍历数组进行处理, ShardSearchFailures如以下示例所示:
int totalShards = searchResponse.getTotalShards(); int successfulShards = searchResponse.getSuccessfulShards(); int failedShards = searchResponse.getFailedShards(); for (ShardSearchFailure failure : searchResponse.getShardFailures()) { // failures should be handled here }检索SearchHits(返回结果的内容)
要访问返回的文档,我们需要首先获取SearchHits 响应中包含的内容:
SearchHits hits = searchResponse.getHits();将SearchHits提供所有点击全局信息,比如命中总数或最大比分:
TotalHits totalHits = hits.getTotalHits(); // the total number of hits, must be interpreted in the context of totalHits.relation long numHits = totalHits.value; // whether the number of hits is accurate (EQUAL_TO) or a lower bound of the total (GREATER_THAN_OR_EQUAL_TO) TotalHits.Relation relation = totalHits.relation; float maxScore = hits.getMaxScore();嵌套在中的SearchHits是可以迭代的各个搜索结果:
SearchHit[] searchHits = hits.getHits(); for (SearchHit hit : searchHits) { // do something with the SearchHit }的SearchHit可访问索引一样,文档ID和每个搜索命中的得分基本信息:
String index = hit.getIndex(); String id = hit.getId(); float score = hit.getScore();此外,它使您可以以简单的JSON-String或键/值对的映射的形式获取文档源。在此映射中,常规字段由字段名称键入并包含字段值。多值字段以对象列表的形式返回,嵌套对象以另一个键/值映射的形式返回。这些情况需要相应地强制转换:
String sourceAsString = hit.getSourceAsString(); Map<String, Object> sourceAsMap = hit.getSourceAsMap(); String documentTitle = (String) sourceAsMap.get("title"); List<Object> users = (List<Object>) sourceAsMap.get("user"); Map<String, Object> innerObject = (Map<String, Object>) sourceAsMap.get("innerObject");高亮显示
如果需要,可以从SearchHit结果中的每个检索出突出显示的文本片段。命中对象提供对HighlightField实例的字段名称映射的访问,每个实例包含一个或多个突出显示的文本片段:
SearchHits hits = searchResponse.getHits(); for (SearchHit hit : hits.getHits()) { Map<String, HighlightField> highlightFields = hit.getHighlightFields(); HighlightField highlight = highlightFields.get("title"); Text[] fragments = highlight.fragments(); String fragmentString = fragments[0].string(); }检索聚合
可以从检索聚合,方法是SearchResponse先获取聚合树的根,Aggregations对象,然后按名称获取聚合。
Aggregations aggregations = searchResponse.getAggregations(); //获取by_company条款汇总 Terms byCompanyAggregation = aggregations.get("by_company"); //获取带有密钥的存储桶 Elastic Bucket elasticBucket = byCompanyAggregation.getBucketByKey("Elastic"); //average_age从该存储桶中获取子聚合 Avg averageAge = elasticBucket.getAggregations().get("average_age"); double avg = averageAge.getValue();请注意,如果按名称访问聚合,则需要根据请求的聚合类型指定聚合接口,否则ClassCastException将抛出:
Range range = aggregations.get("by_company");这将引发异常,因为“ by_company”是一个terms聚合,但是我们尝试将其作为range聚合进行检索
也可以将所有聚合作为以聚合名称作为关键字的映射来访问。在这种情况下,必须明确地强制转换为正确的聚合接口:Map<String, Aggregation> aggregationMap = aggregations.getAsMap(); Terms companyAggregation = (Terms) aggregationMap.get("by_company");还有一些getter会将所有顶级聚合返回为列表:
List<Aggregation> aggregationList = aggregations.asList();您可以遍历所有聚合,然后例如根据其类型决定如何进一步处理它们:
for (Aggregation agg : aggregations) { String type = agg.getType(); if (type.equals(TermsAggregationBuilder.NAME)) { Bucket elasticBucket = ((Terms) agg).getBucketByKey("Elastic"); long numberOfDocs = elasticBucket.getDocCount(); } }聚合结果
要从中获取建议SearchResponse,请使用Suggest对象作为入口点,然后检索嵌套的建议对象:
Suggest suggest = searchResponse.getSuggest(); TermSuggestion termSuggestion = suggest.getSuggestion("suggest_user"); for (TermSuggestion.Entry entry : termSuggestion.getEntries()) { for (TermSuggestion.Entry.Option option : entry) { String suggestText = option.getText().string(); } }检索分析结果
SearchResponse使用getProfileResults()方法从中检索分析结果。该方法为执行中涉及的每个分片返回一个Map包含一个ProfileShardResult对象的对象 SearchRequest。使用唯一地标识配置文件结果所对应的分片的密钥ProfileShardResult存储在其中Map。
//检索Map的ProfileShardResult从SearchResponse Map<String, ProfileShardResult> profilingResults = searchResponse.getProfileResults(); for (Map.Entry<String, ProfileShardResult> profilingResult : profilingResults.entrySet()) { String key = profilingResult.getKey(); ProfileShardResult profileShardResult = profilingResult.getValue(); }所述ProfileShardResult对象本身包含一个或多个查询简档的结果,一个用于抵靠底层Lucene索引执行的每个查询: ```java List
queryProfileShardResults = profileShardResult.getQueryProfileResults();for (QueryProfileShardResult queryProfileResult : queryProfileShardResults) {
}
每个都QueryProfileShardResult可以访问详细的查询树执行,以ProfileResult对象列表的形式返回:<br />遍历概要文件结果<br />检索Lucene查询的名称<br />检索执行Lucene查询的毫秒数<br />检索子查询的概要文件结果(如果有)
```java
for (ProfileResult profileResult : queryProfileResult.getQueryResults()) {
String queryName = profileResult.getQueryName();
long queryTimeInMillis = profileResult.getTime();
List<ProfileResult> profiledChildren = profileResult.getProfiledChildren();
}
该QueryProfileShardResult还可以访问了Lucene的分析信息:
检索Lucene收集器的分析结果
检索Lucene收集器的名称
检索执行Lucene收集器所花费的毫秒数
检索子收集器的概要文件结果(如果有)
CollectorResult collectorResult = queryProfileResult.getCollectorResult();
String collectorName = collectorResult.getName();
Long collectorTimeInMillis = collectorResult.getTime();
List<CollectorResult> profiledChildren = collectorResult.getProfiledChildren();
通过与查询树执行非常类似的方式,这些QueryProfileShardResult对象可以访问详细的聚合树执行
检索 AggregationProfileShardResult
遍历聚合配置文件结果
检索聚合的类型(与用于执行聚合的Java类相对应)
检索执行Lucene收集器所花费的毫秒数
检索子聚合的概要文件结果(如果有)
AggregationProfileShardResult aggsProfileResults =
profileShardResult.getAggregationProfileResults();
for (ProfileResult profileResult : aggsProfileResults.getProfileResults()) {
String aggName = profileResult.getQueryName();
long aggTimeInMillis = profileResult.getTime();
List<ProfileResult> profiledChildren = profileResult.getProfiledChildren();
}

若有收获,就点个赞吧
0 人点赞
