简介
正排索引是指文档ID为key,表中记录每个关键词出现的次数 位置等,查找时扫描表中的每个文档中字 的信息,直到找到所有包含查询关键字的文档。
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。 “文档2”的ID > 此文档出现的关键词列表。
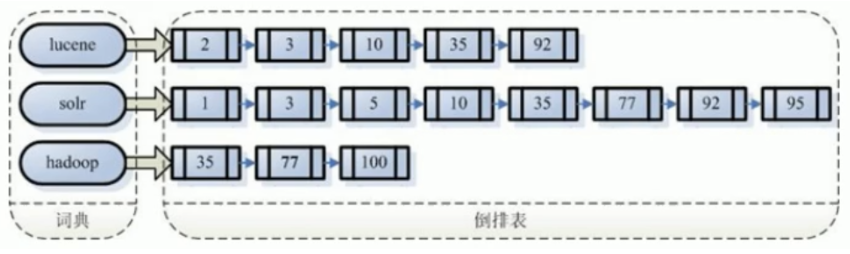
倒排索引
“关键词1”:“文档1”的ID 出现次数 出现的位置,“文档2”的ID 出现次数 出现的位置,…………。 “关键词2”:带有此关键词的文档ID列表。
倒排索引主要由两个部分组成:“单词词典”和“倒排文件
索引和搜索流程图
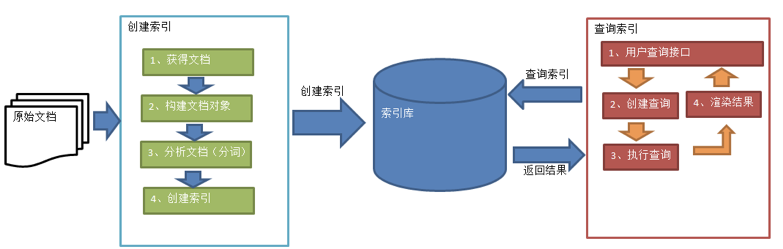
- 绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容->采集文档->创建文档->分析文档->索引文档
- 红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面->创建查询->执行搜索,从索引库搜索->渲染搜索结果
创建文档对象
获取原始内容的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档中包括一个一个的域(Field),域中存储内容。
这里我们可以将磁盘上的一个文件当成一个document,Document中包括一些Field(file_name文件名称、file_path文件路径、file_size文件大小、file_content文件内容)
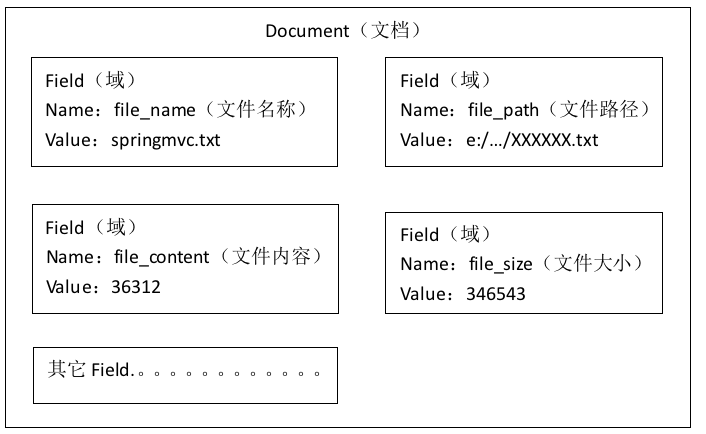
注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field(域名和域值都相同)
分析文档
就是分词的过程
- 根据空格进行字符串拆分,得到一个单词列表
- 把单词统一转换成小写
- 去除标点符号
- 去除停用词(无意义的词)
- 每个单词都封装一个Term对象.
Term对象包含两个部分:关键词所在的域,关键词本身.
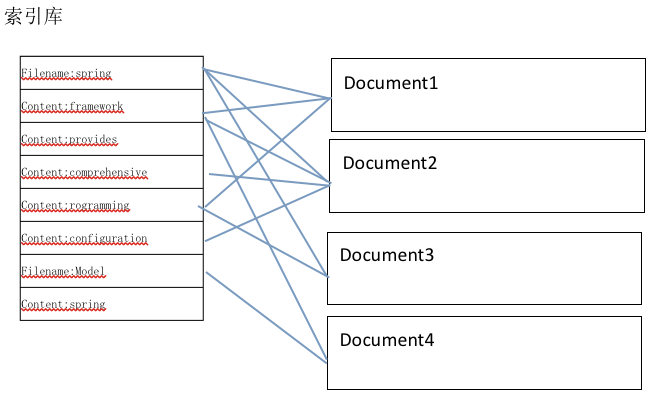
创建索引
基于关键词列表创建一个索引.保存到索引库中.
索引库中: 索引,document对象,关键词和文档的对应关系
通过词语找文档,这种索引的结构叫倒排索引结构
创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法,
例如:
语法 “fileName:lucene”表示要搜索Field域的内容为“lucene”的文档
lucene模块构成
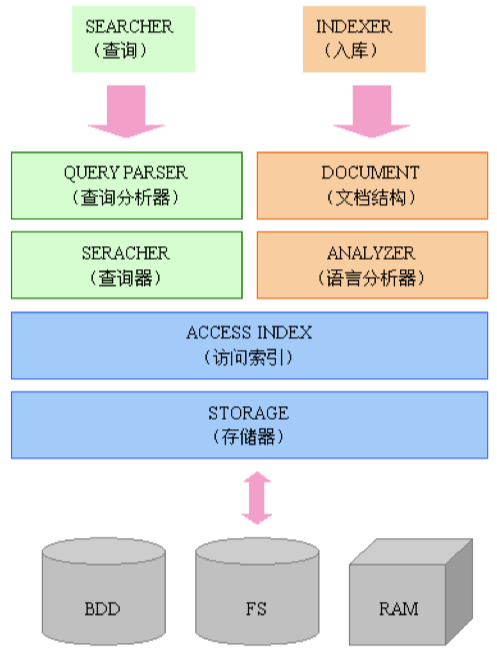
Lucene 的index模块主要负责索引的创建,里面有IndexWriter。
Lucene 的search模块主要负责对索引的搜索。 Lucene 的QueryParser主要负责语法分析。
Lucene 的Document相当于一个要进行索引的单元,任何可以想要被索引的文件都必须转化为Document 对象才能进行索引。代表一个虚拟文档与字段,其中字段是可包含在物理文档的内容,元数据等对象。
Lucene 的analysis 模块主要负责词法分析及语言处理而形成Term。 Lucene 的store模块主要负责索引的读写。
索引创建和搜索流程

pom
<dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>7.7.3</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>7.7.3</version></dependency><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId><version>7.7.3</version></dependency><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.5</version></dependency><dependency><groupId>com.github.magese</groupId><artifactId>ik-analyzer</artifactId><version>7.7.1</version></dependency>

若有收获,就点个赞吧
0 人点赞
