下载
https://opendistro.github.io/for-elasticsearch-docs/docs/install/plugins/#sql
注意:OpenDistro for Elasticsearch SQL 插件的版本必须和ES的版本保持一致,否则在使用的时候,会报版本不一致的错误。
下载下来后,直接在ES的安装目录下执行如下命令安装插件:
elasticsearch-plugin install file:///data/pack/opendistro_sql-x.x.x.zip
执行完后,便成功安装上插件了,是不是很简单,同时对应的Kibana也便支持_opendistro/sql命令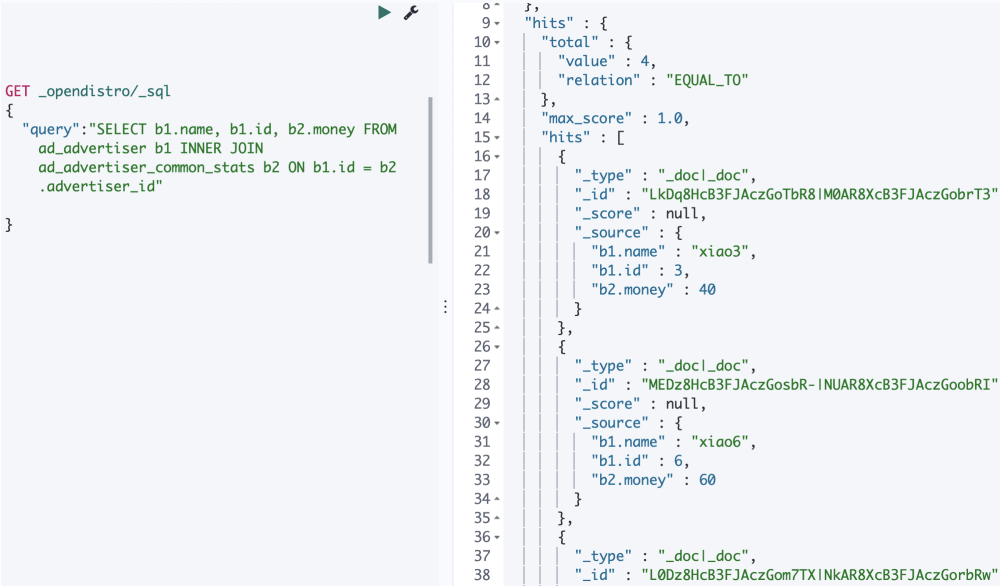
哈哈,关联语句都可以查,是不是很香。当前OpenDistro for Elasticsearch SQL 已经支持的基础SQL语句如下:
SQL SelectSQL DeleteSQL WhereSQL Order BySQL Group BySQL HavingSQL Inner JoinSQL Left JoinSQL ShowSQL DescribeSQL AND & ORSQL LikeSQL COUNT distinctSQL InSQL BetweenSQL AliasesSQL Not NullSQL(ES) DateSQL avg()SQL count()SQL max()SQL min()SQL sum()SQL NullsSQL isnull()SQL floorSQL trimSQL logSQL log10SQL substringSQL roundSQL sqrtSQL concat_wsSQL union and minus
光是安了插件肯定还是不够的,我们怎么在代码中直接使用SQL来操作ES的数据?
那就需要OpenDistro for Elasticsearch SQL-JDBC登场啦~
https://github.com/opendistro-for-elasticsearch/sql-jdbc
<dependency><groupId>com.amazon.opendistroforelasticsearch.client</groupId><artifactId>opendistro-sql-jdbc</artifactId><version>1.13.0.0</version></dependency>
opendistro-sql-jdbc的版本试过,可以和ES版本不一致。
public static void main(String[] args) throws Exception{String url = "jdbc:elasticsearch://http://localhost:9200";Connection con = DriverManager.getConnection(url);Statement stmt = con.createStatement();String sql = "SELECT COUNT(*) m, sum(time_create) as t FROM ad GROUP BY level HAVING m >= 3 ORDER BY time_create DESC";// 执行查询ResultSet rs = stmt.executeQuery(sql);while (rs.next()){System.out.println(rs.getString("t"));}con.close();}
代码中:url=”jdbc:elasticsearch:……”为固定写法,JDBC以此识别出需要使用opendistro-sql-jdbc连接数据源。上述执行结果如下:
既然JDBC可以的话,那么结合Spring-Data,使用jdbcTemplate操作ES当然一样可以,代码如下:
@Autowiredprivate JdbcTemplate jdbcTemplate;@GetMapping("/query")public List<Map<String, Object>> queryAll() {String sql = "select * from ad";//执行sql语句List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);return maps;}

若有收获,就点个赞吧
0 人点赞
