input
Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
常用 input 插件
- file:从文件系统上的文件读取,就像UNIX命令 tail -0F 一样
- syslog:在众所周知的端口514上侦听系统日志消息,并根据RFC3164格式进行解析
- redis:从redis服务器读取,使用redis通道和redis列表。 Redis经常用作集中式Logstash安装中的“代理”,它将来自远程Logstash“托运人”的Logstash事件排队。
- beats:处理由Filebeat发送的事件。
更多详情请见:Input Plugins
filter
过滤器是Logstash管道中的中间处理设备。如果符合特定条件,您可以将条件过滤器组合在一起,对事件执行操作。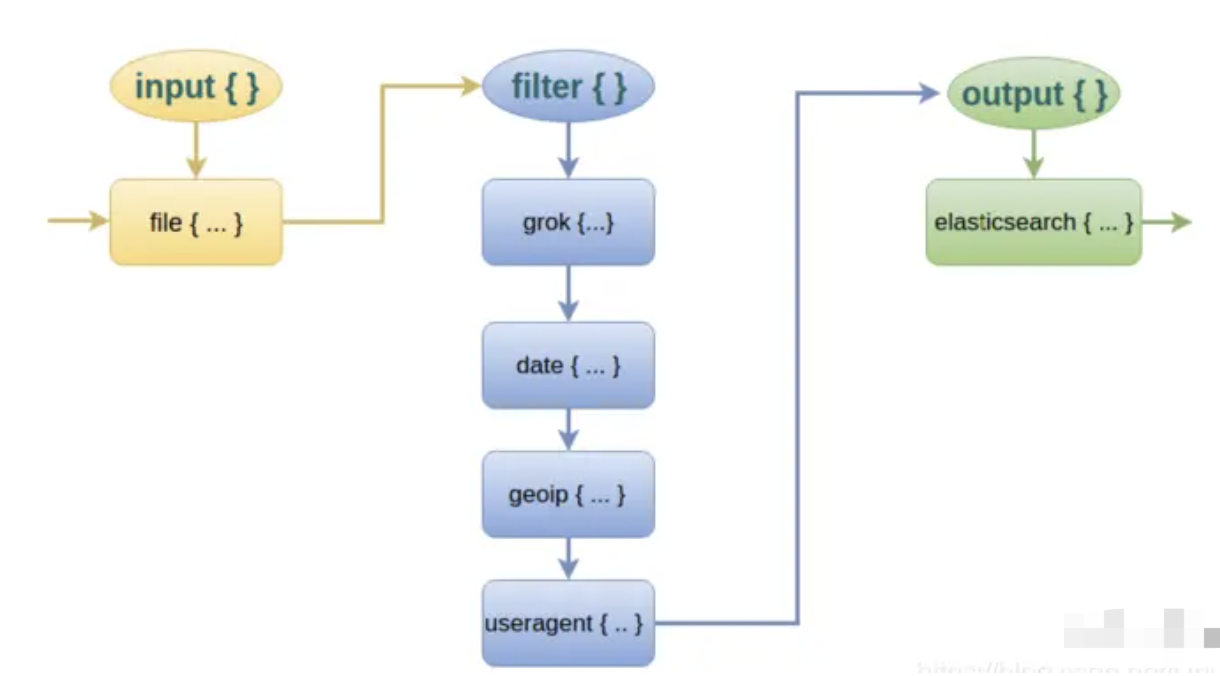
常用 filter 插件
- grok:解析和结构任意文本。 Grok目前是Logstash中将非结构化日志数据解析为结构化和可查询的最佳方法。
- mutate:对事件字段执行一般转换。您可以重命名,删除,替换和修改事件中的字段。
- drop:完全放弃一个事件,例如调试事件。
- clone:制作一个事件的副本,可能会添加或删除字段。
- geoip:添加有关IP地址的地理位置的信息(也可以在Kibana中显示惊人的图表!)
更多详情请见:Filter Plugins
解析日志
logback.xml 配置的日志格式如下:
<encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n</pattern></encoder>
日志格式解释如下:
- 记录日志时间:%d{yyyy-MM-dd HH:mm:ss.SSS}
- 记录是哪个线程打印的日志:[%thread]
- 记录日志等级:%-5level
- 打印日志的类:%logger
- 记录具体日志信息:%msg%n,这个 msg 的内容就是 log.info(“abc”) 中的 abc。
通过执行代码 log.info(“xxx”) 后,就会在本地的日志文件中追加一条日志。
2022-06-16 15:50:00.070 [XNIO-1 task-1] INFO com.passjava.config - 方法名为:MemberController-,请求参数:{省略}
那么 Logstash 如何针对上面的信息解析出对应的字段呢?比如如何解析出打印日志的时间、日志等级、日志信息?
grok 插件
这里就要用到 logstash 的 filter 中的 grok 插件。filebeat 发送给 logstash 的日志内容会放到 message 字段里面,logstash 匹配这个 message 字段就可以了。配置项如下所示:
filter {
grok {
match => [
"message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+[(?<thread>.*)]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"
]
}
}
大家发现没,上面的 匹配 message 的正则表达式还是挺复杂的,这个是我一点一点试出来的。Kibana 自带 grok 的正则匹配的工具,路径如下:
http://<your kibana IP>:5601/app/kibana#/dev_tools/grokdebugger
我们把日志和正则表达式分别粘贴到上面的输入框,点击 Simulate 就可以测试是否能正确匹配和解析出日志字段。如下图所示: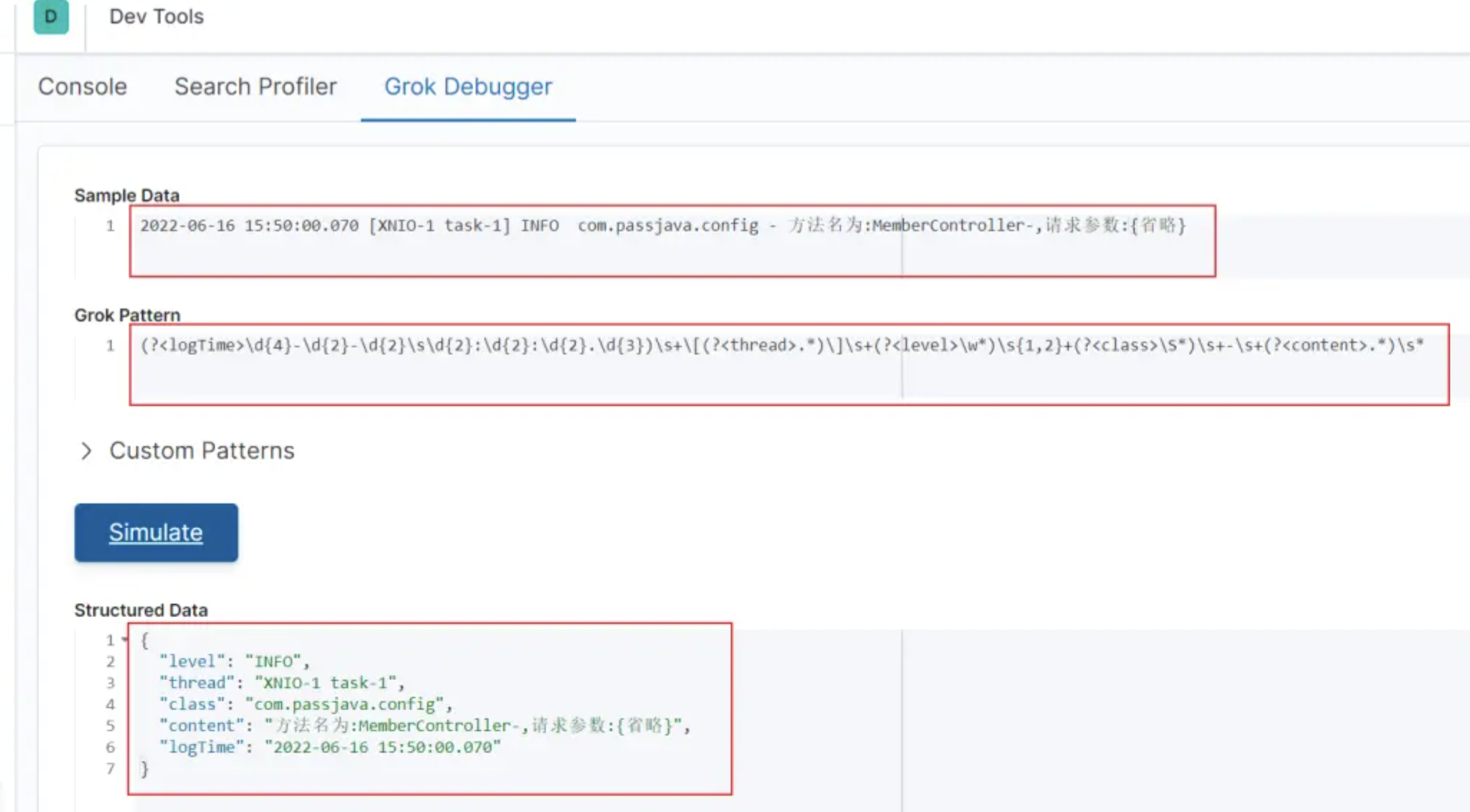
Grok Debugger 工具
有没有常用的正则表达式呢?有的,logstash 官方也给了一些常用的常量来表达那些正则表达式,可以到这个 Github 地址查看有哪些常用的常量。
https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patterns
比如可以用 IP 常量来代替正则表达式 IP (?:%{IPV6}|%{IPV4})
好了,经过正则表达式的匹配之后,grok 插件会将日志解析成多个字段,然后将多个字段存到了 ES 中,这样我们可以在 ES 通过字段来搜索,也可以在 kibana 的 Discover 界面添加列表展示的字段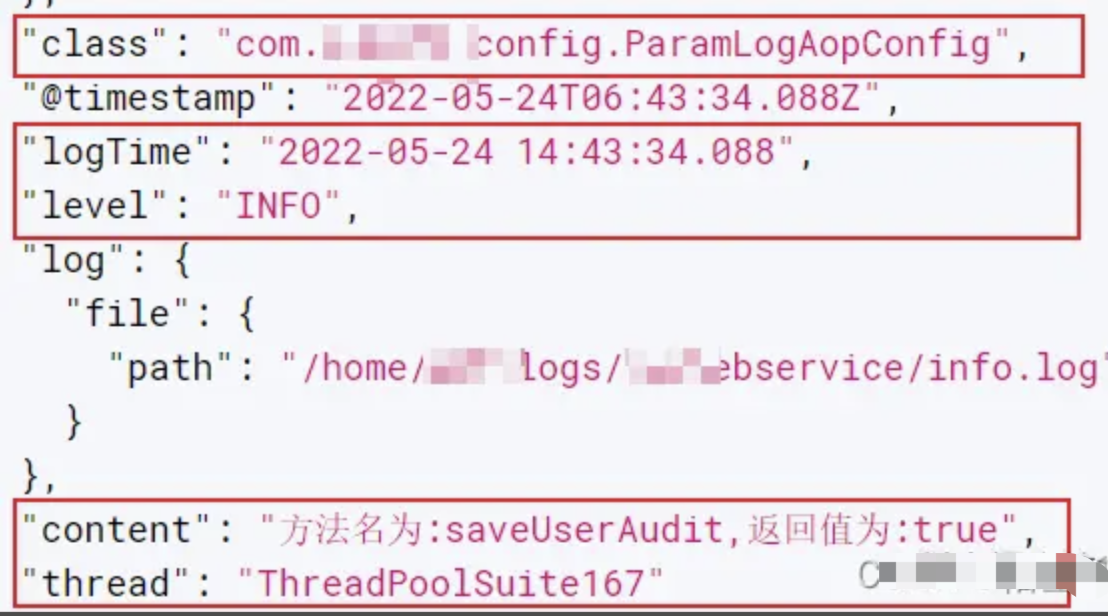
坑:我们后端项目的不同服务打印了两种不同格式的日志,那这种如何匹配?
再加一个 match 就可以了。
filter {
grok {
match => [
"message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+[(?<thread>.*)]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"
]
match => [
"message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?<level>\w*)\s{1,2}+.\s---+\s[(?<thread>.*)]+\s(?<class>\S*)\s*:+\s(?<content>.*)\s*"
]
}
}
当任意一个 message 匹配上了这个正则,则 grok 执行完毕。假如还有第三种格式的 message,那么虽然 grok 没有匹配上,但是 message 也会输出到 ES,只是这条日志在 ES 中不会展示 logTime、level 等字段。
multiline 插件
还有一个坑的地方是错误日志一般都是很多行的,会把堆栈信息打印出来,当经过 logstash 解析后,每一行都会当做一条记录存放到 ES,那这种情况肯定是需要处理的。这里就需要使用 multiline 插件,对属于同一个条日志的记录进行拼接。
multiline 不是 logstash 自带的,需要单独进行安装。我们的环境是没有外网的,所以需要进行离线安装。
介绍在线和离线安装 multiline 的方式:
- 在线安装插件。
在 logstash 根目录执行以下命令进行安装。
bin/logstash-plugin install logstash-filter-multiline
- 离线安装插件。
在有网的机器上在线安装插件,然后打包。
bin/logstash-plugin install logstash-filter-multiline
bin/logstash-plugin prepare-offline-pack logstash-filter-multiline
拷贝到服务器,执行安装命令
bin/logstash-plugin install file:///home/software/logstash-offline-plugins-7.6.2.zip
安装插件需要等待 5 分钟左右的时间,控制台界面会被 hang 住,当出现 Install successful 表示安装成功。
检查下插件是否安装成功,可以执行以下命令查看插件列表。当出现 multiline 插件时则表示安装成功。
bin/logstash-plugin list
如果要对同一条日志的多行进行合并,你的思路是怎么样的?比如下面这两条异常日志,如何把文件中的 8 行日志合并成两条日志?
多行日志示例
思路是这样的:
- 第一步:每一条日志的第一行开头都是一个时间,可以用时间的正则表达式匹配到第一行。
- 第二步:然后将后面每一行的日志与第一行合并。
- 第三步:当遇到某一行的开头是可以匹配正则表达式的时间的,就停止第一条日志的合并,开始合并第二条日志。
- 第四步:重复第二步和第三步
按照这个思路,multiline 的配置如下:
filter {
multiline {
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}"
negate => true
what => "previous"
}
}
时间的正则表达式就是这个 pattern 字段,大家可以根据自己项目中的日志的时间来定义正则表达式。
- pattern: 这个是用来匹配文本的表达式,也可以是grok表达式
- what: 如果pattern匹配成功的话,那么匹配行是归属于上一个事件,还是归属于下一个事件。previous: 归属于上一个事件,向上合并。next: 归属于下一个事件,向下合并
- negate: 是否对 pattern 的结果取反false: 不取反,是默认值。true: 取反。将多行事件扫描过程中的行匹配逻辑取反(如果 pattern 匹配失败,则认为当前行是多行事件的组成部分)
多行被拆分
坑:Java 堆栈日志太长了,有 100 多行,被拆分了两部分,一部分被合并到了原来的那一条日志中,另外一部分被合并到了不相关的日志中。
如下图所示,第二条日志有 100 多行,其中最后一行被错误地合并到了第三条日志中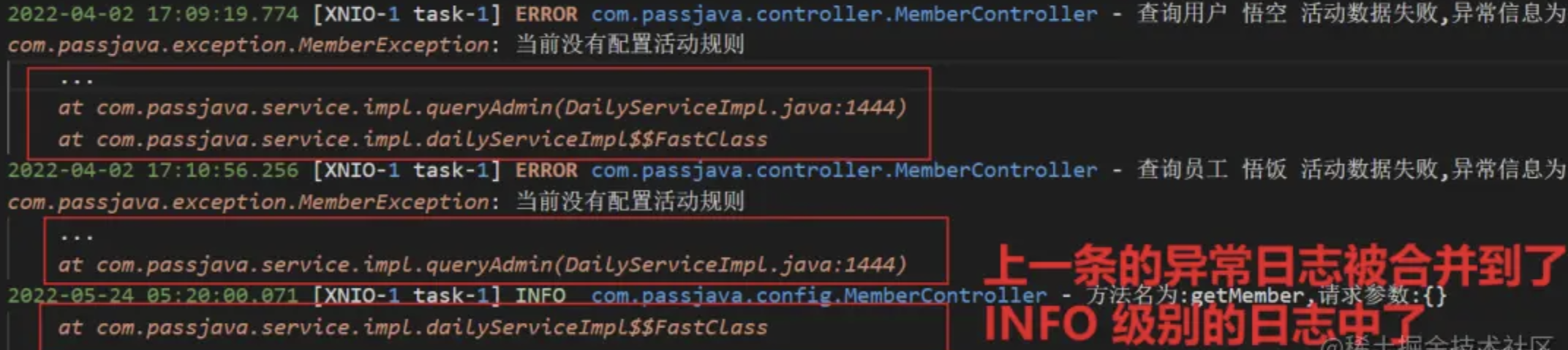
日志合并错乱
为了解决这个问题,我是通过配置 filebeat 的 multiline 插件来截断日志的。为什么不用 logstash 的 multiline 插件呢?因为在 filter 中使用 multiline 没有截断的配置项。filebeat 的 multiline 配置项如下: ```java multiline.type: patternmultiline.pattern: ‘^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}’multiline.negate: truemultiline.match: aftermultiline.max_lines: 50
配置项说明:
- multiline.pattern:希望匹配到的结果(正则表达式)
- multiline.negate:值为 true 或 false。使用 false 代表匹配到的行合并到上一行;使用 true 代表不匹配的行合并到上一行
- multiline.match:值为 after 或 before。after 代表合并到上一行的末尾;before 代表合并到下一行的开头
- multiline.max_lines:合并的最大行数,默认 500
- multiline.timeout:一次合并事件的超时时间,默认为 5s,防止合并消耗太多时间导致 filebeat 进程卡死
我们重点关注 max_lines 属性,表示最多保留多少行后执行截断,这里配置 50 行。<br />注意:filebeat 和 logstash 我都配置了 multiline,没有验证过只配置 filebeat 的情况
<a name="G9xaT"></a>
### mutate 插件
当我们将日志解析出来后,Logstash 自身会传一些不相关的字段到 ES 中,这些字段对我们排查线上问题帮助不大。可以直接剔除掉。<br />坑:输出到 ES 的日志包含很多无意义字段。<br />这里我们就要用到 mutate 插件了。它可以对字段进行转换,剔除等。<br />比如我的配置是这样的,对很多字段进行了剔除。
```java
mutate {
remove_field => [
"agent",
"message",
"@version",
"tags",
"ecs",
"input",
"[log][offset]"
]
}
注意:一定要把 log.offset 字段去掉,这个字段可能会包含很多无意义内容。
关于 Mutate 过滤器它有很多配置项可供选择,如下表格所示: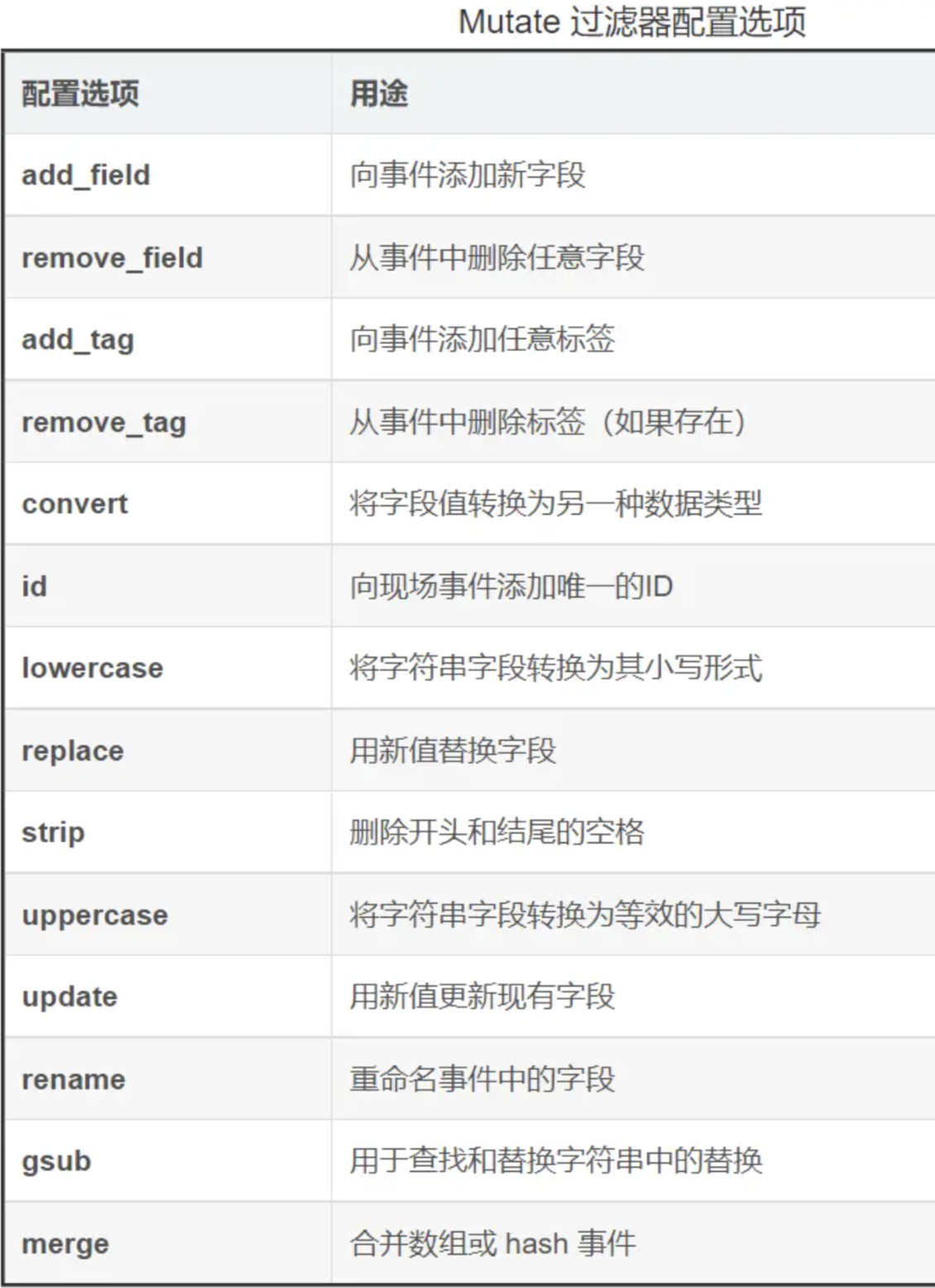
date 插件
到 kibana 查询日志时,发现排序和过滤字段 @timestamp 是 ES 插入日志的时间,而不是打印日志的时间。
这里我们就要用到 date 插件了。
上面的 grok 插件已经成功解析出了打印日志的时间,赋值到了 logTime 变量中,现在用 date 插件将 logTime 匹配下,如果能匹配,则会赋值到 @timestamp字段,写入到 ES 中的 @timestamp字段就会和日志时间一致了。配置如下所示:
date {
match => [
"logTime",
"MMM d HH:mm:ss",
"MMM dd HH:mm:ss",
"ISO8601"
]
}
但是经过测试写入到 ES 的 @timestamp 日志时间和打印的日志时间相差 8 小时。如下图所示: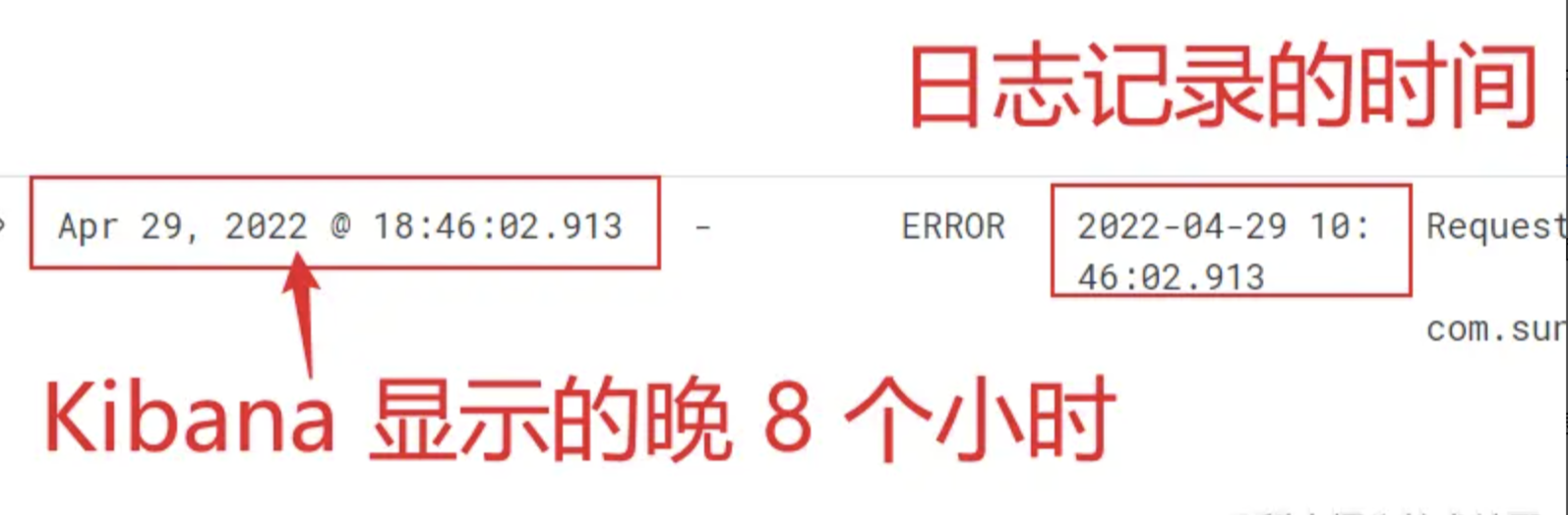
我们到 ES 中查询记录后,发现 @timestamp 字段时间多了一个字母 Z,代表 UTC 时间,也就是说 ES 中存的时间比日志记录的时间晚 8 个小时。
我们可以通过增加配置 timezone => “Asia/Shanghai” 来解决这个问题。修改后的配置如下所示:
date {
match => [
"logTime",
"MMM d HH:mm:ss",
"MMM dd HH:mm:ss",
"ISO8601"
]
timezone => "Asia/Shanghai"
}
调整后,再加一条日志后查看结果,Kibana 显示 @timestamp 字段和日志的记录时间一致了。
output
输出是Logstash管道的最后阶段。一个事件可以通过多个输出,但是一旦所有输出处理完成,事件就完成了执行。
常用 output 插件
- elasticsearch:将事件数据发送给 Elasticsearch(推荐模式)。
- file:将事件数据写入文件或磁盘。
- graphite:将事件数据发送给 graphite(一个流行的开源工具,存储和绘制指标。 http://graphite.readthedocs.io/en/latest/)。
- statsd:将事件数据发送到 statsd (这是一种侦听统计数据的服务,如计数器和定时器,通过UDP发送并将聚合发送到一个或多个可插入的后端服务)。
更多详情请见:Output Plugins
output {
stdout {}
elasticsearch {
hosts => [
"10.2.1.64:9200",
"10.2.1.65:9200",
"10.27.2.1:9200"
]
index => "qa_log"
}
}
注意这里的 index 名称 qa_log 必须是小写,不然写入 es 时会报错
codec
常用 codec 插件
- json:以JSON格式对数据进行编码或解码。
- multiline:将多行文本事件(如java异常和堆栈跟踪消息)合并为单个事件。
更多插件请见:Codec Plugins
例子
input {
beats {
port => 9900
}
}
filter {
multiline {
pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}"
negate => true
what => "previous"
}
grok {
match => [
"message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+[(?<thread>.*)]\s+(?<level>\w*)\s{1,2}+(?<class>\S*)\s+-\s+(?<content>.*)\s*"
]
match => [
"message", "(?<logTime>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?<level>\w*)\s{1,2}+.\s---+\s[(?<thread>.*)]+\s(?<class>\S*)\s*:+\s(?<content>.*)\s*"
]
match => [
"source", "/home/passjava/logs/(?<logName>\w+)/.*.log"
]
overwrite => [
"source"
]
break_on_match => false
}
mutate {
convert => {
"bytes" => "integer"
}
remove_field => [
"agent",
"message",
"@version",
"tags",
"ecs",
"_score",
"input",
"[log][offset]"
]
}
useragent {
source => "user_agent"
target => "useragent"
}
date {
match => [
"logTime",
"MMM d HH:mm:ss",
"MMM dd HH:mm:ss",
"ISO8601"
]
timezone => "Asia/Shanghai"
}
}
output {
stdout {}
elasticsearch {
hosts => [
"10.2.1.64:9200",
"10.2.1.65:9200",
"10.2.1.66:9200"
]
index => "qa_log"
}
}

若有收获,就点个赞吧
0 人点赞
