Field属性
Lucene存储对象是以Document为存储单元,对象中相关的属性值则存放到Field中。
每个Field包含3部分信息:域的名称,域的类型,域的值。域的值可以是String,Java.io.Reader,TokenStream,可以是byte[]字节数组,可以是数字等等,而域的类型则是有IndexableFieldType类表示的。
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field 的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
Field的三大属性:
是否分析:是否对域的内容进行分词处理。前提是我们要对域的内容进行查询。
是否索引:将Field分析后的词或整个Field值进行索引,只有索引方可搜索到。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储
Field常用类型
Field对应的类是 org.apache.lucene.document.Field,该类实现了org.apache.lucene.document.IndexableField 接口,代表用于indexing的一个字段。
Field类比较底层一些,所以Lucene实现了许多Field子类,用于不同的场景。
| Field类型 | 数据类型 | 分词 | 索引 | 存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName,FieldValue,Store.YES) | 字符 串 |
N | Y | Y/N | 字符串类型Field,不分词,作为一个整体进行索引(如:身份证号,订单编号),是否需要存储由Store.YES或Store.NO决定 |
| TextField(FieldName,FieldValue,Store.NO) | 文本类型 | Y | Y | Y/N | 文本类型Field,分词并且索引,是否需要存储由Store.YES或Store.NO决定 |
| LongField(FieldName,FieldValue,Store.YES)或LongPoint(Stringname,int…point)等 | 数值型代表 | Y | Y | Y/N | 在Lucene6.0中,LongField替换为LongPoint,IntField替换为IntPoint,FloatField替换为FloatPoint,DoubleField替换为DoublePoint。对数值型字段索引,索引不存储。要存储结合StoredField即可。 |
| StoredField(FieldName,FieldValue) | 支持 多种类型 |
N | N | Y | 构建不同类型的Field,不分词,不索引,要存储.(如:商品图片路径) |
Field应用代码
import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.*;import org.apache.lucene.index.*;import org.apache.lucene.search.*;import org.apache.lucene.search.similarities.ClassicSimilarity;import org.apache.lucene.search.Query;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.store.*;import org.junit.Test;import java.nio.file.Paths;import java.util.ArrayList;import java.util.List;@Testpublic void createIndex() throws Exception {// 1.采集数据Book booka = new Book();List<Book> bookList = new ArrayList<Book>();booka.setId(1);booka.setDesc("Lucene Core is a Java library providing powerful indexing and search features, as well as spellchecking, hit highlighting and advanced analysis/tokenization capabilities. The PyLucene sub project provides Python bindings for Lucene Core. ");booka.setName("Lucene");booka.setPrice(100.45f);bookList.add(booka);Book bookb = new Book();bookb.setId(11);bookb.setDesc("Solr is highly scalable, providing fully fault tolerant distributed indexing, search and analytics. It exposes Lucene's features through easy to use JSON/HTTP interfaces or native clients for Java and other languages. ");bookb.setName("Solr");bookb.setPrice(320.45f);bookList.add(bookb);Book bookc = new Book();bookc.setId(21);bookc.setDesc("The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.");bookc.setName("Hadoop");bookc.setPrice(620.45f);bookList.add(bookc);// 2.将采集到的数据封装到Document对象中List<Document> docList = new ArrayList<>();Document document;for (Book book : bookList) {document = new Document();// IntPoint 分词 索引 不存储 存储结合 StoredFieldField id = new IntPoint("id", book.getId());//看这个field是不是分词还有是不是存储System.out.println(id.fieldType().tokenized() + ":" + id.fieldType().stored());Field id_v = new StoredField("id", book.getId());// 分词、索引、存储 TextFieldField name = new TextField("name", book.getName(), Field.Store.YES);// 分词、索引、不存储 但是是数字类型,所以使用FloatPointField price = new FloatPoint("price", book.getPrice());// 分词、索引、不存储 TextFieldField desc = new TextField("desc", book.getDesc(), Field.Store.NO);// 将field域设置到Document对象中document.add(id);document.add(id_v);document.add(name);document.add(price);document.add(desc);docList.add(document);}//3.创建Analyzer 分词器 对文档进行分词Analyzer analyzer = new StandardAnalyzer();// 创建Directory 和 IndexWriterConfig 对象Directory directory = FSDirectory.open(Paths.get("/Users/xiajiandong/Desktop/luceneTest/index"));IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// 4.创建IndexWriter 写入对象IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);// 添加文档对象for (Document doc : docList) {indexWriter.addDocument(doc);}// 释放资源indexWriter.close();}
上面的desc虽然没有存储,但是可以搜索
不存储不代表没索引, 但是没有desc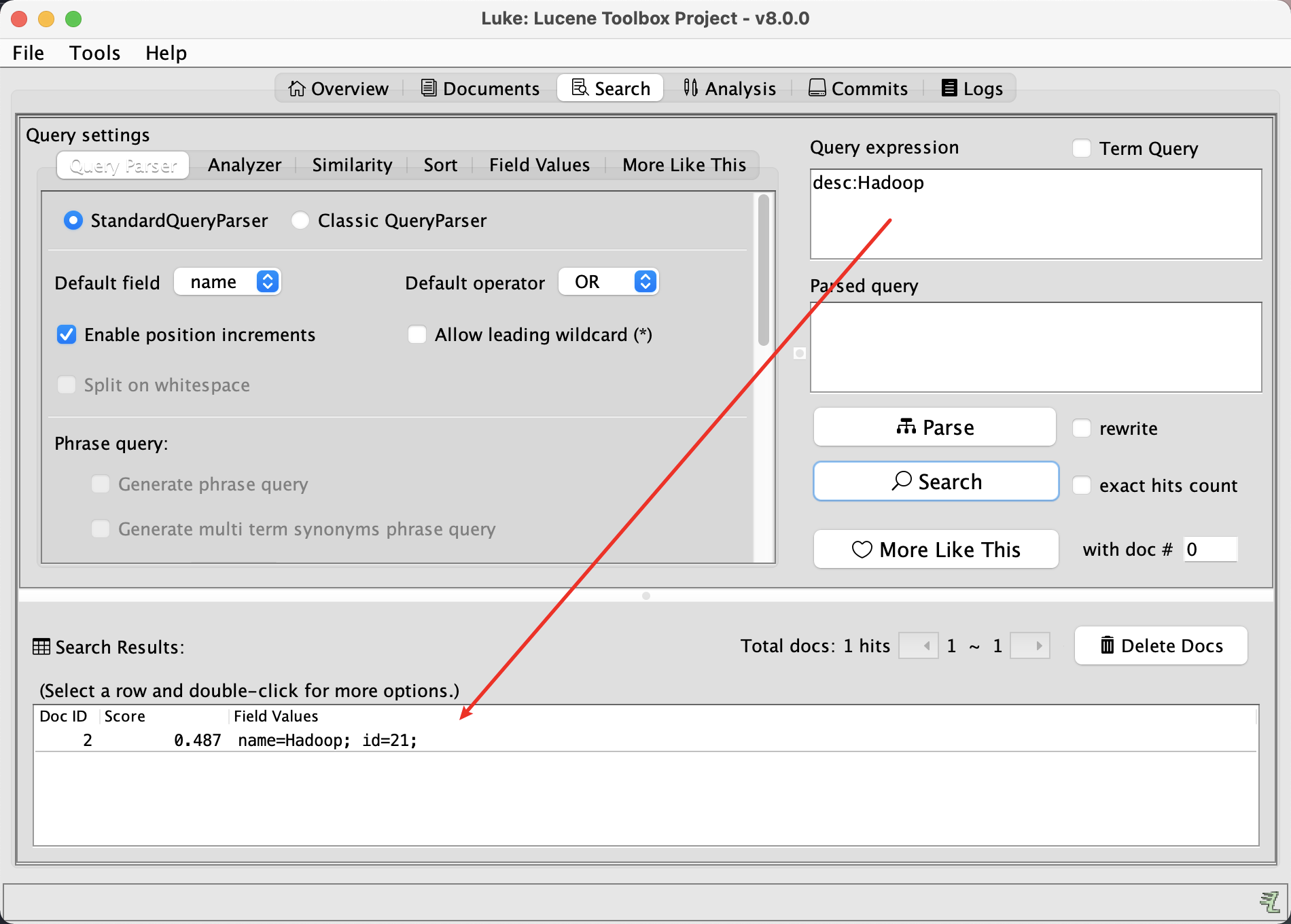

若有收获,就点个赞吧
0 人点赞
