压缩索引的本质:在索引只读等三个条件的前提下,减少索引的主分片数。
# 设置待压缩的索引,分片设置为5个。PUT kibana_sample_data_logs_ext{"settings": {"number_of_shards":5}}# 准备索引数据POST _reindex{"source":{"index":"kibana_sample_data_logs"},"dest":{"index":"kibana_sample_data_logs_ext"}}# shrink 压缩之前的三个必要条件PUT kibana_sample_data_logs_ext/_settings{"settings": {"index.number_of_replicas": 0,"index.routing.allocation.require._name": "node-024","index.blocks.write": true}}# 实施压缩POST kibana_sample_data_logs_ext/_shrink/kibana_sample_data_logs_shrink{"settings": {"index.number_of_replicas": 0,"index.number_of_shards": 1,"index.codec": "best_compression"},"aliases": {"kibana_sample_data_logs_alias": {}}}
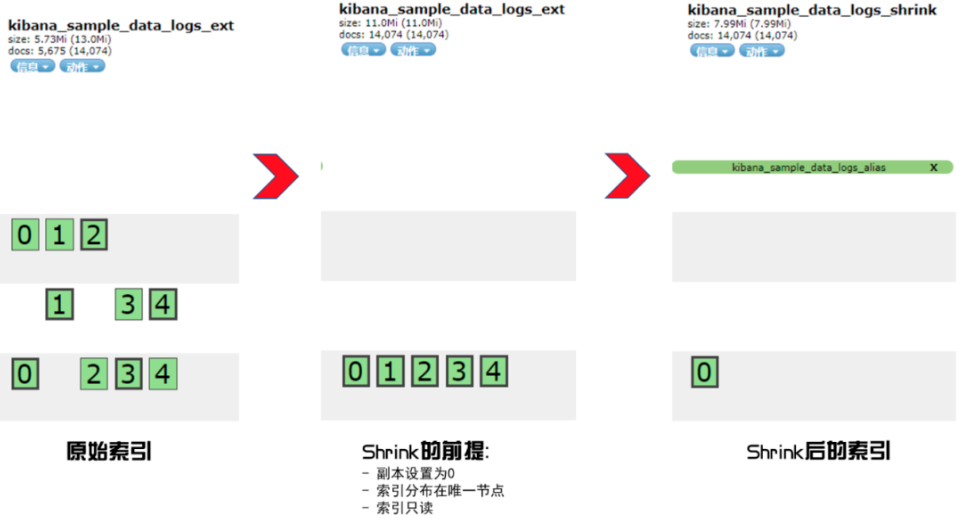
强调一下三个压缩前的条件,缺一不可:
- “index.number_of_replicas”: 0 副本设置为 0
- “index.routing.allocation.require._name”: “node-024” 分片数据要求都集中到一个独立的节点
- “index.blocks.write”: true 索引数据只读

若有收获,就点个赞吧
0 人点赞
