Query 阶段
Query 阶段会根据搜索条件遍历每个分片(主分片或者副分片中的其一)中的数据,返回符合条件的前 N 条数据的 ID 和排序值,然后在协调节点中对所有分片的数据进行排序,获取前 N 条数据的 ID。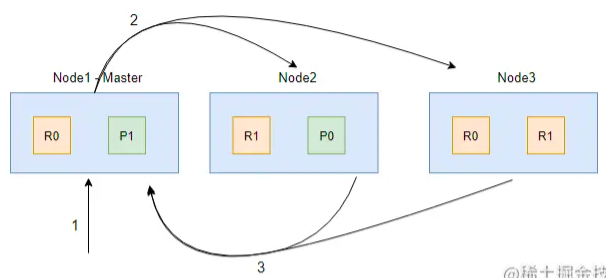
Query 阶段的流程如上图,其中 1、2、3 步解析如下:
- 客户端发起 search 请求到 Node1;
- 协调节点 Node1 将查询请求转发到索引的每个主分片或者副分片中,每个分片执行本地查询并且将查询结果打分排序,然后将 from + size 个结果保存到 from + size 大小的有序队列中。
- 每个分片将查询结果返回到 Node1(协调节点)中,Node1 对所有结果进行排序,并且把排序后结果放到一个全局的排序列表中。
需要注意的是,在协调节点转发搜索请求的时候,如果有 N 个 Shard 位于同一个节点时,并不会合并这些请求,而是发生 N 次请求!
Fetch 阶段
在 Fetch 阶段,协调节点会从 Query 阶段产生的全局排序列表中确定需要取回的文档 ID 列表,然后通过路由算法计算出各个文档对应的分片,并且用 multi get 的方式到对应的分片上获取文档数据。
Fetch 阶段的流程如上图,其中 1、2、3 步解析如下:
- 协调节点(Node1)确定哪些文档需要获取,然后向相关节点发起 multi get 请求;
- 分片所在节点读取文档数据,并且进行 _source 字段过滤、处理高亮参数等,然后把处理后的文档数据返回给协调节点;
- 协调节点等待所有数据被取回后返回给客户端。
深度分页的问题
Query + Fetch 的方式看似很合理,但也会产生一些问题:
- 每个分片上都要取回 from + size 个文档(不是 from 到 size,而是 from + size);
- 协调节点需要处理 shard_amount * ( from + size ) 个文档。
在 from + size 很大的情况下,协调节点需要处理的数据就会很多,这个就是深分页产生的原因,所以一般在产品上我们都是一页一页地翻,而不是跳到任意一页。
DFS
执行了一个预查询来计算整体文档的frequency。
- 预查询每个shard,询问Term和Document frequency;
- 发送查询到每隔shard;
- 找到所有匹配的文档,并使用全局的Term/Document Frequency信息进行打分;
- 对结果构建一个优先队列(排序,标页等);
- 返回关于结果的元数据到请求节点。注意,实际文档还没有发送,只是分数;
- 来自所有shard的分数合并起来,并在请求节点上进行排序,文档被按照查询要求进行选择
- 最终,实际文档从他们各自所在的独立的shard上检索出来
- 结果被返回给用户
Search Type的版本演进
- DFS_QUERY_AND_FETCH,QUERY_AND_FETCH两种类型在5.3版本之前的Search Request中会被用到。
- 5.3版本到6.X版本只支持DFS_QUERY_THEN_FETCH,QUERY_THEN_FETCH,DFS_QUERY_AND_FETCH被废弃,QUERY_AND_FETCH过期,其中默认的search type为QUERY_THEN_FETCH。
-
Search Type的详解
query and fetch
client向coordinator node发起search请求
- coordinator node查询本地的cluster state找到目标search所在的data node,向索引的所有分片(shard)都发出查询请求
- 各分片返回的时候把元素文档(document)和计算后的排名信息一起返回
- 在coordinator node进行总体排序后返回结果给client
这种搜索方式单次search是最快的。因为相比下面的几种搜索方式,这种查询方法只需要去shard查询一次。但是各个shard返回的结果的数量之和可能是用户要求的size的n倍。所以如果高并发高吞吐时,效率会受到很大的影响,shard越多影响越大。
query then fetch(默认的搜索方式)
如果你搜索时,没有指定搜索方式,就是使用的这种搜索方式。
- client向coordinator node发起search请求
- coordinator node查询本地的cluster state找到目标search所在的data node,向索引的所有分片(shard)都发出查询请求
- 各分片只返回”足够“(预估是排序、排名以及分值相关)的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档
- 去相关的shard取排序和计算后所需的最终document
- 在coordinator node汇集后直接返回结果给client
这种方式虽然需要查询两次data node,单次search查询速度不及query and fetch,但是返回的document与用户要求的size是相等的,可以尽量减少IO的浪费。所以如果高并发高吞吐时,这种IO的reduce效果很明显,shard越多效果越明显。
DFS query and fetch
这种方式比第一种方式多了一个initial scatter phrase步骤,有这一步,可以使distributed term frequencies for more accurate scoring达到更好的效果
DFS query then fetch
这种方式比第二种方式多了一个initial scatter phrase步骤
总结
存在即是合理,这说明在不同的场景下,不同的search type都会有自己发挥的空间,简单来说:
- 如果search命中的shard较少,那么QUERY_AND_FETCH的效率理论上应该会比较好;反之,如果search命中的shard较多,那么QUERY_THEN_FETCH的效率理论上应该会比较好,两者的差别就在IO的消耗以及多一次查询两者之间的差值。这个临界值需要根据实际的集群以及数据情况进行测试
- 按照当前新版本SearchType的演进来看,显而易见的是,elasticsearch在经过优化后,两次查询带来的消耗明显已经优于IO的消耗了,继而SearchType的默认值也就变成了QUERY_THEN_FETCH,而QUERY_AND_FETCH在新版本中已经被废弃了,这场效率之争在现在版本看来还是QUERY_THEN_FETCH取得了阶段性的胜利
- 对于DFS相关的方式,笔者建议除非是对全文匹配的精确度有着极高的要求,否则其他对全文匹配精确度要求不高甚至不care全文匹配的场景,直接使用DEFAULT即可

若有收获,就点个赞吧
0 人点赞
