简介
Bucket Aggregations,桶聚合, 常见的分为
- Terms: 根据某个字段进行分组,例如根据出版社进行分组。
- Range, Date Range: 根据用户指定的范围参数作为分组的依据来进行聚合操作。
Histogram, Date Histogram: 可以指定间隔区间来进行聚合操作。
Bucket 聚合不像metrics 那样基于某一个值去计算,每一个Bucket (桶)是按照我们定义的准则去判断数据是否会落入桶(bucket)中。
一个单独的响应中,bucket(桶)的最大个数默认是10000,我们可以通过**serarch.max_buckets**去进行调整
它执行的是对文档分组的操作(与sql中的group by类似),把满足相关特性的文档分到一个桶里,即桶分,输出结果往往是一个个包含多个文档的桶(一个桶就是一个group)
bucket:一个数据分组 , 第一个aggs
metric:对一个数据分组执行的统计, 第二个aggsTerms聚合
```shell POST /bank/_search { “size”: 0, “aggs”: { “ages”: {
"terms": { //关键词"field": "age", //指明term字段"size": 5 //指定返回数目}
} } }
GET /your_index/your_type/_search
{
“size”: 0,
使用聚合时,天然存在一个metric,就是当前bucket的count
“aggs”: { “group_by_xxx”: { # 自定义的名字
# 除了使用term还可以使用terms
# trems允许你指定多个字段
"terms": {
# 指定聚合的字段, 意思是 group by v1、v2、v3
"field": {"value1","value2","value3"}
}
}
} }
比如说我们要看各个年龄段的存款人数
```java
POST /bank/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
},
"aggs": {
"ages": {
"terms": {
"field": "age"
}
}
}
}
其中,ages是我们定义的聚合查询的名称,terms指定要分组的列,我们运行一下,看看结果,
{
"aggregations": {
"ages": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 463,
"buckets": [
{
"key": 31,
"doc_count": 61
}
,
{
"key": 32,
"doc_count": 52
}
,
{
"key": 34,
"doc_count": 49
}
]
}
}
我们可以看到在返回的结果中,每个年龄的数据都汇总出来了。假如我们要看每个年龄段的存款余额,该怎么办呢?这里就要用到子聚合查询了,在Bucket 聚合中,再加入子聚合查询了,我们看看怎么写,
POST /bank/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
}
}
},
"aggs": {
"ages": {
"terms": {
"field": "age"
},
"aggs": {
"sum_balance": {
"sum": {
"field": "balance"
}
}
}
}
}
}
我们在聚合类型terms的后面又加了子聚合查询,在子聚合查询中,又自定义了一个sum_balance的查询,它是一个metrics聚合查询,要对字段balance进行求和。我们运行一下,看看结果。
"aggregations": {
"ages": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 463,
"buckets": [
{
"key": 31,
"doc_count": 61,
"sum_balance": {
"value": 1727088
}
}
,
{
"key": 33,
"doc_count": 50,
"sum_balance": {
"value": 1254697
}
}
,
{
"key": 34,
"doc_count": 49,
"sum_balance": {
"value": 1313688
}
}
]
}
}
我们看到返回结果中,增加了我们定义的sum_balance字段,它是balance余额的汇总
filter过滤和聚合
前置条件的过滤:filter
在当前文档集上下文中定义与指定过滤器(Filter)匹配的所有文档的单个存储桶。通常,这将用于将当前聚合上下文缩小到一组特定的文档。
GET /test-agg-cars/_search
{
"size": 0,
"aggs": {
"make_by": {
"filter": { "term": { "type": "honda" } },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}
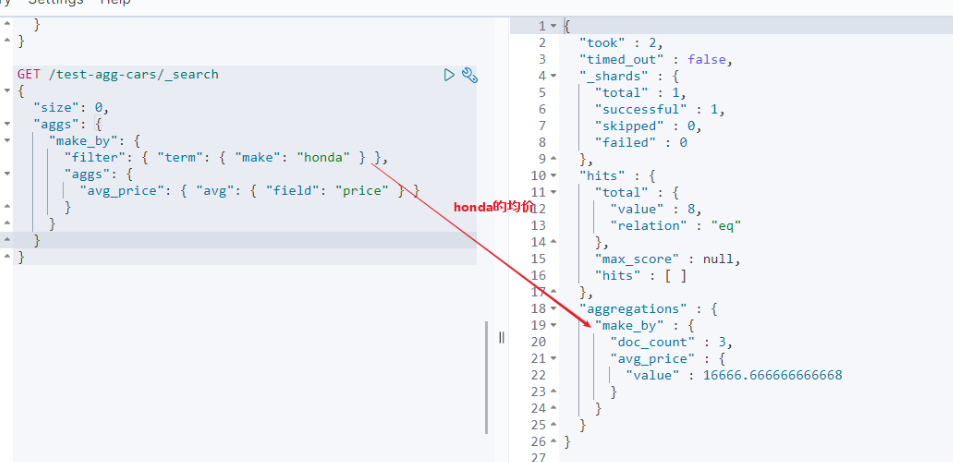
对filter进行分组聚合:filters
设计一个新的例子, 日志系统中,每条日志都是在文本中,包含warning/info等信息
PUT /test-agg-logs/_bulk?refresh
{ "index" : { "_id" : 1 } }
{ "body" : "warning: page could not be rendered" }
{ "index" : { "_id" : 2 } }
{ "body" : "authentication error" }
{ "index" : { "_id" : 3 } }
{ "body" : "warning: connection timed out" }
{ "index" : { "_id" : 4 } }
{ "body" : "info: hello pdai" }
我们需要对包含不同日志类型的日志进行分组,这就需要filters:
GET /test-agg-logs/_search
{
"size": 0,
"aggs" : {
"messages" : {
"filters" : {
"other_bucket_key": "other_messages",
"filters" : {
"infos" : { "match" : { "body" : "info" }},
"warnings" : { "match" : { "body" : "warning" }}
}
}
}
}
}
# 还有个其他的case
# bucket filter
POST /sales/_search
{
"aggs" : {
# T恤bucket的agg
"agg_t_shirts" : {
"filter" : {
"term": {
"type": "t-shirt"
}
},
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
},
# 毛衣bucket的agg
"agg_sweater" : {
"filter" : {
"term": {
"type": "sweater"
}
},
"aggs" : {
"avg_price" : { "avg" : { "field" : "price" } }
}
}
}
}

range范围聚合
# aggs代表聚合,
# group_by_price是自己起的名字, 范围分组(0-200)(200-400)(400-1000)这几个组
# 对上面分组之后, 再进行avg
POST /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0, // 这个也可以省略
"to": 200
},
{
"from": 200,
"to": 400
},
{
"from": 400,
"to": 1000
}
]
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
ranges": [
{
"key": "<200", //桶命名, 返回值里面会有这个名词
"to": 200
},
{
"key": "200-400",
"from": 200,
"to": 400
},
{
"key": "400-1000",
"from": 400,
"to": 1000
}
]
IP Range: ip类型聚合
GET /ip_addresses/_search
{
"size": 10,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "to": "10.0.0.5" },
{ "from": "10.0.0.5" }
]
}
}
}
}
- CIDR Mask分组
此外还可以用CIDR Mask分组
GET /ip_addresses/_search
{
"size": 0,
"aggs": {
"ip_ranges": {
"ip_range": {
"field": "ip",
"ranges": [
{ "mask": "10.0.0.0/25" },
{ "mask": "10.0.0.127/25" }
]
}
}
}
}
增加key显示
GET /ip_addresses/_search { "size": 0, "aggs": { "ip_ranges": { "ip_range": { "field": "ip", "ranges": [ { "to": "10.0.0.5" }, { "from": "10.0.0.5" } ], "keyed": true // here } } } }自定义key显示
GET /ip_addresses/_search { "size": 0, "aggs": { "ip_ranges": { "ip_range": { "field": "ip", "ranges": [ { "key": "infinity", "to": "10.0.0.5" }, { "key": "and-beyond", "from": "10.0.0.5" } ], "keyed": true } } } }Date Range日期范围聚合
请注意,此聚合包括from值,但不包括to每个范围的值。
其中to:now-10M/M表示,过去到10个月前
from:now-10M/M表示,从10个月前到现在{ "aggs":{ "range":{ "date_range":{ "field":"date", "format":"MM-yyy", "ranges":[ {"to":"now-10M/M"}, {"from":"now-10M/M"} ] } } } }还有种指定格式的
{ "aggs":{ "range":{ "date_range":{ "field":"date", "format":"yyyy", "ranges":[ { "from": "1980", "to": "1990" }, { "from": "1990", "to": "2000" }, { "from": "2000" } ] } } } }Historgram直方图
基本语法
创建直方图需要指定一个区间,如果我们要为售价创建一个直方图,可以将间隔设为 20,000。这样做将会在每个 $20,000 档创建一个新桶,然后文档会被分到对应的桶中。
对于仪表盘来说,我们希望知道每个售价区间内汽车的销量。我们还会想知道每个售价区间内汽车所带来的收入,可以通过对每个区间内已售汽车的售价求和得到。
可以用 histogram 和一个嵌套的 sum 度量得到我们想要的答案:GET /test-agg-cars/_search { "size" : 0, "aggs":{ "price":{ "histogram":{ "field": "price.keyword", "interval": 20000 }, "aggs":{ "revenue": { "sum": { "field" : "price" } } } } } }
- histogram 桶要求两个参数:一个数值字段以及一个定义桶大小间隔。
- sum 度量嵌套在每个售价区间内,用来显示每个区间内的总收入。
如我们所见,查询是围绕 price 聚合构建的,它包含一个 histogram 桶。它要求字段的类型必须是数值型的同时需要设定分组的间隔范围。 间隔设置为 20,000 意味着我们将会得到如 [0-19999, 20000-39999, …] 这样的区间。
接着,我们在直方图内定义嵌套的度量,这个 sum 度量,它会对落入某一具体售价区间的文档中 price 字段的值进行求和。 这可以为我们提供每个售价区间的收入,从而可以发现到底是普通家用车赚钱还是奢侈车赚钱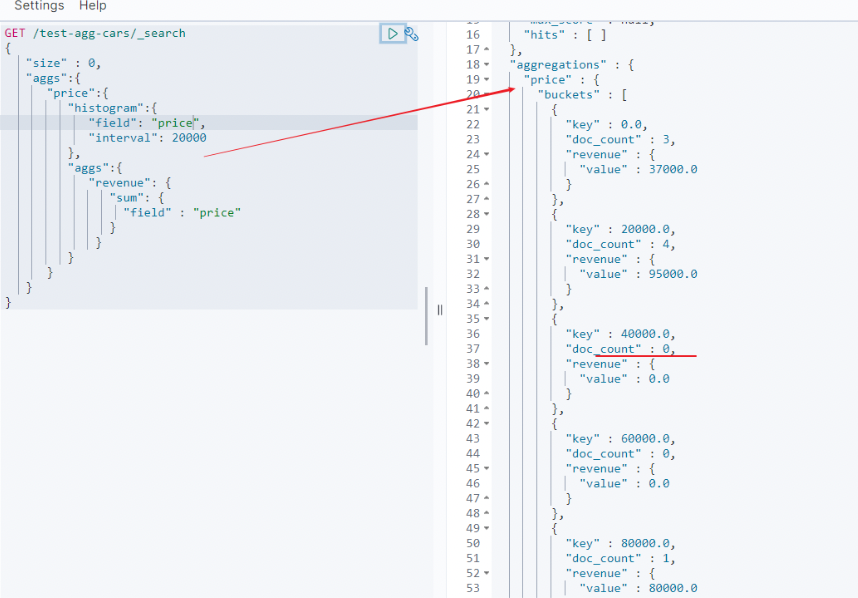
结果很容易理解,不过应该注意到直方图的键值是区间的下限。键 0 代表区间 0-19,999 ,键 20000 代表区间 20,000-39,999 ,等等。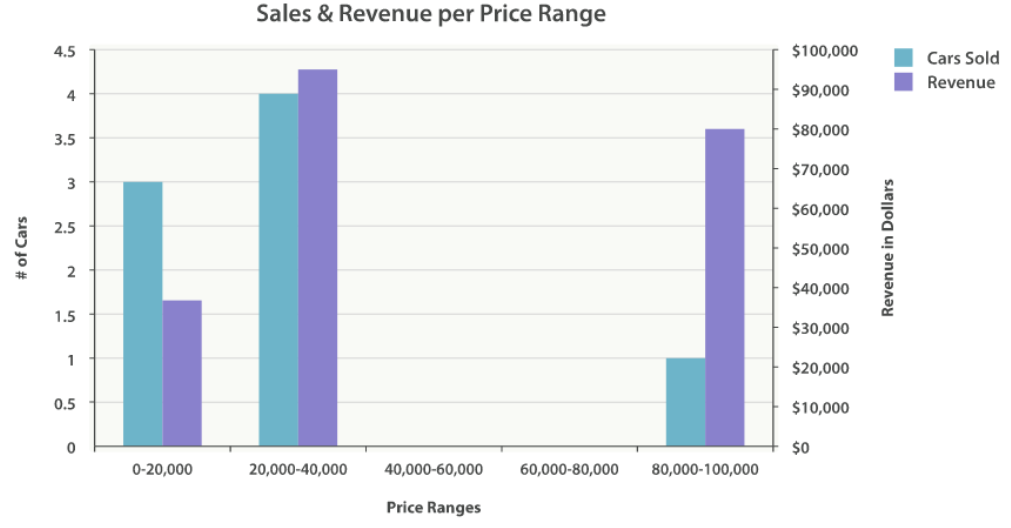
固定间隔的策略分割
有一个price字段,这个字段描述了商品的价格,现在想每隔50就创建一个桶,统计
{
"aggs" : {
"prices" : {
"histogram" : { //关键词
"field" : "price",
"interval" : 50, //指定间隔大小
"extended_bounds": { //指定数据范围, 可不写
"min": 0,
"max": 40000
}
}
}
}
}
min_doc_count限制最小返回的
比如100-150是没有文档的,但是却显示为0.如果不想要显示count为0的桶,可以通过min_doc_count来设置。
这样返回的数据,就不会出现为0的了。
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"min_doc_count" : 1
}
}
}
}
order排序
排序大同小异,可以按照_key的名字排序:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_key" : "desc" }
}
}
}
}
也可以按照文档的数目:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "_count" : "asc" }
}
}
}
}
或者指定排序的聚合:
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"order" : { "price_stats.min" : "asc" }
},
"aggs" : {
"price_stats" : { "stats" : {} }
}
}
}
}
keyed设置返回的方式
正常返回的数据如上面所示,是按照数组的方式返回。如果要按照名字返回,可以设置keyed为true
{
"aggs" : {
"prices" : {
"histogram" : {
"field" : "price",
"interval" : 50,
"keyed" : true
}
}
}
}
那么返回的数据就为:
{
"aggregations": {
"prices": {
"buckets": {
"0": {
"key": 0,
"doc_count": 2
},
"50": {
"key": 50,
"doc_count": 4
},
"150": {
"key": 150,
"doc_count": 3
}
}
}
}
}
缺省的值
缺省值通过MissingValue设置:
{
"aggs" : {
"quantity" : {
"histogram" : {
"field" : "quantity",
"interval": 10,
"missing": 0
}
}
}
}
Date Historgram时间直方图
可用表达式:
- year(1y)年
- quarter(1q)季度
- month(1M)月份
- week(1w)星期
- day(1d)天
- hour(1h)小时
- minute(1m)分钟
- second(1s)秒
例子
{
"aggs":{
"by_year":{
"date_historgram":{
"field":"birth",
"format":"yyyy",
"interval" : "year",
}
}
}
}
// 查询
"query": {
"bool": {
"must": [{
"range": {
"@timestamp": {
"gte": 1533556800000,
"lte": 1533806520000
}
}
}]
}
},
// 不显示具体的内容
"size": 0,
// 聚合
"aggs": {
// 自己取的聚合名字
"group_by_grabTime": {
// es提供的时间处理函数
"date_histogram": {
// 需要聚合分组的字段名称, 类型需要为date, 格式没有要求
"field": "@timestamp",
// 按什么时间段聚合, 这里是5分钟, 可用的interval在上面给出
"interval": "5m",
// 设置时区, 这样就相当于东八区的时间
"time_zone":"+08:00",
// 返回值格式化,HH大写,不然不能区分上午、下午
"format": "yyyy-MM-dd HH",
// 为空的话则填充0
"min_doc_count": 0,
// 需要填充0的范围
"extended_bounds": {
"min": 1533556800000,
"max": 1533806520000
}
},
// 聚合
"aggs": {
// 自己取的名称
"group_by_status": {
// es提供
"terms": {
// 聚合字段名
"field": "LowStatusOfPrice"
}
}
}
}
}
返回结果
{
"took": 960,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"_clusters": {
"total": 3,
"successful": 3,
"skipped": 0
},
"hits": {
"total": 13494821,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_grabTime": {
"buckets": [
{
"key_as_string": "2018-08-06 12",
"key": 1533556800000,
"doc_count": 25851,
"group_by_status": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ { "key": "2", "doc_count": 10804 }, { "key": "1", "doc_count": 7240 }, { "key": "4", "doc_count": 6716 }, { "key": "3", "doc_count": 1091 } ] }
},
{
"key_as_string": "2018-08-06 13",
"key": 1533562200000,
"doc_count": 25282,
"group_by_status": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [ { "key": "2", "doc_count": 10457 }, { "key": "1", "doc_count": 7185 }, { "key": "4", "doc_count": 6696 }, { "key": "3", "doc_count": 944 } ] }
},
.....
特别说明
"buckets": [
{
"key_as_string": "2018-08-06 12",
"key": 1533556800000,
- 关于统计的时间段
2018-08-06 12 统计的是12~13点之间的数据
以此类推
2018-08-06 00 统计的是00~01之间的数据
2018-08-06 23 统计的是23~次日00之间的数据
- 关于key 和 key_as_string
key_as_string 不一定完全可信, 即key按照用户当前时间格式化之后不一定等于key_as_string
这是由建立es索引时采用的时区决定的, 用之前最好验证一下, 比如说博主现在正在做的一个项目中, 由于es采用的是ISO8859-1的时间格式, 导致所有时区提前了8个小时, 所以在查询和统计时, 一定要记得补偿这8个小时的数据
可以通过设置时区来解决这个问题
[
](https://blog.csdn.net/qq_28988969/article/details/81565765)
值的个数统计
# 写在上面最后一个aggs里面
"count_price": {
"value_count": {
"field": "price"
}
}
having 效果
对组数据进行过滤
# having就是: buckets_path路径对什么路径, 对average_price进行having过滤, 脚本是 >=200
POST /book/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 200
},
{
"from": 200,
"to": 400
},
{
"from": 400,
"to": 1000
}
]
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
},
"having": {
"bucket_selector": {
"buckets_path": {
"avg_price": "average_price"
},
"script": {
"source": "params.avg_price >= 200 "
}
}
}
}
}
}
}
having里面也可以and的
对average_price进行过滤, 脚本里面的要对上外面的名字
"having": {
"bucket_selector": {
"buckets_path": {
"avg_price": "average_price"
},
"script": {
"source": "params.avg_price >= 200 && params.avg_price <= 500"
}
}
}
Bucket+Metric聚合分析
Bucket聚合分析允许通过添加子分析来进步进行分析,该子分析可以是 Bucket也可以是 Metric。
这也使得es的聚合分析能力变得异常强大
GET test_search/_search
{
"size": 0,
"aggs": {
"jobs": { //第一层聚合
"terms": {
"field": "job.keyword",
"size": 10
},
"aggs": {
"age_range": { //第二层聚合
"ranges": [
{"to": 20},
{"from": 20, "to": 30},
{"from": 30}
]
}
}
}
}
}
GET visited/_search
{
"size": 0,
"query": {
"bool": {
"must": [
{
"range": {
"createTime": {
"gte": "now-1d/d",
"lte": "now/d"
}
}
}
]
}
},
"aggs": {
"visit_per_day": {
"date_histogram": {
"field": "createTime",
"calendar_interval": "day"
},
"aggs": {
"times_per_user": {
"terms": {
"field": "salesmanAutoId"
}
}
}
}
}
}
我想知道我们公司每个年龄段,每个性别的平均账户余额。
GET /your_index/your_type/_search
{
"size":0,
# 先按照年龄分组,在按照性别分组,再按照平均工资聚合
# 最终的结果就得到了每个年龄段,每个性别的平均账户余额
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
}
]
},
"aggs": {
"group_by_gender": {
"term": {
"field": "gender.keyword"
},
# 在上一层根据gender聚合的基础上再基于avg balance聚合
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
嵌套聚合,并且使用内部聚合的结果集
GET /your_index/your_type/_search
{
"size":0,
# 嵌套聚合,并且使用内部聚合的结果集
"aggs": {
"group_by_state": {
"term": {
"field": "state.keyword",
"order": {
# average_balance是下面内部聚合的结果集合,在此基础上做desc
"average_balance": "desc"
}
},
# 如下的agg会产出多个bucket如:
# bucket1 => {state=1,acg=xxx、min=xxx、max=xxx、sum=xxx}
# bucket2 => {state=2,acg=xxx、min=xxx、max=xxx、sum=xxx}
"aggs": {
"average_balance": {
"avg": { # avg 求平均值 metric
"field": "balance"
}
},
"min_price": {
"min": { # metric 求最小值
"field": "price"
}
},
"max_price": {
"max": { # metric 求最大值
"field": "price"
}
},
"sum_price": {
"sum": { # metric 计算总和
"field": "price"
}
},
}
}
}
}

若有收获,就点个赞吧
0 人点赞
