简介
Filebeat的处理流程
- 输入Input
- 处理Filter
- 输出Output
Filebeat输入配置支持的输入类型有:
- Log
- Stdin
- Redis
- UDP
- Docker
- TCP
- Syslog
- ElasticSearch
- LogStash
- Kafka
- Redis
- File
- Console
-
工作原理
输入是个文件
harvester是收割机,收割了之后传递给spooler
spooler是卷轴传递给下游, 可以对接很多 harvester :
- 负责读取单个文件的内容。
- 如果文件在读取时被删除或重命名,Filebeat将继续读取文件。
- prospector
- prospector 负责管理harvester并找到所有要读取的文件来源。
- 如果输入类型为日志,则查找器将查找路径匹配的所有文件,并为每个文件启动一个harvester。
- Filebeat目前支持两种prospector类型:log和stdin。
- Filebeat如何保持文件的状态
- Filebeat 保存每个文件的状态并经常将状态刷新到磁盘上的注册文件中。
- 该状态用于记住harvester正在读取的最后偏移量,并确保发送所有日志行。
- 如果输出(例如Elasticsearch或Logstash)无法访问,Filebeat会跟踪最后发送的行,并在输出再次可用时继续读取文件。
- 在Filebeat运行时,每个prospector内存中也会保存的文件状态信息,当重新启动Filebeat时,将使用注册文件的数据来重建文件状态,Filebeat将每个harvester在从保存的最后偏移量继续读取。
- 文件状态记录在data/registry文件中。Filebeat 的 registry 文件存储 Filebeat 用于跟踪上次读取位置的状态和位置信息。
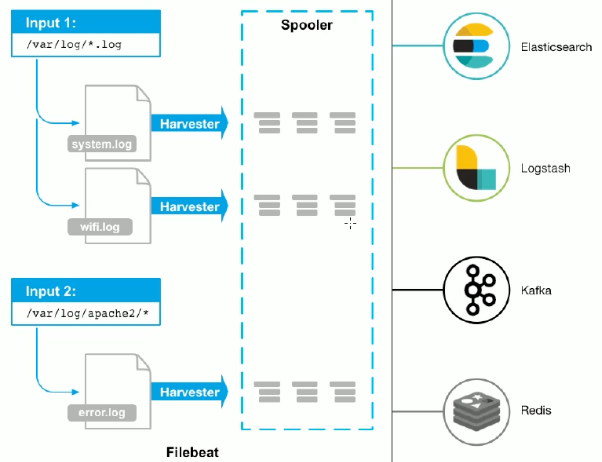
针对每个日志文件,filebeat都会启动一个harvester协程,即一个goroutine,在该goroutine中不停的读取日志文件,直到文件的EOF末尾.
不同的harvester goroutine采集到的日志数据都会发送至一个全局的队列queue中,queue的实现有两种:基于内存和基于磁盘的队列,目前基于磁盘的队列还是处于alpha阶段,filebeat默认启用的是基于内存的缓存队列。
每当队列中的数据缓存到一定的大小或者超过了定时的时间(默认1s),会被注册的client从队列中消费,发送至配置的后端。目前可以设置的client有kafka、elasticsearch、redis等。
从代码的实现角度来看,filebeat大概可以分以下几个模块:
- input: 找到配置的日志文件,启动harvester
- harvester: 读取文件,发送至spooler
- spooler: 缓存日志数据,直到可以发送至publisher
- publisher: 发送日志至后端,同时通知registrar
-
如何确保数据不丢
registry记录每个harvester最后读取到文件的offset,只要数据被发送成功时,才会记录。如果发送失败,则会一直重复发送
- 如果filebeat正在运行时,需要关闭。filebeat不会等待所有接收方确认完,而是立刻关闭。等再次启动时,这部分未确认的内容会重新发送(至少发送一次)。
- 可以通过
shutdown_timeout设置,收到关闭命令时,多久之后才关闭harvester。
- 当harvester不可用时,文件被删除
- 对于轮询文件,轮询速度的超过了处理的速度
- inode重新利用,新文件起始位置继续使用旧文件的开始记录位置导致
安装
创建my.yml ```java filebeat.inputs:wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.0-linux-x86_64.tar.gztar -zxvf filebeat-7.4.0-linux-x86_64.tar.gz
- type: stdin
enabled: true
output.console:
pretty: true
enable: true
参数说明
-e: 输出到标准输出, 默认输出到syslog和logs下 -c: 指定配置文件 -d: 输出debug信息
./filebeat -e -c my.yml ./filebeat -e -c my.yml -d “publish”
接下来在控制台输入就行, 会看到输出, 数据会在message里面```java{"@timestamp": "2021-11-21T13:38:09.155Z","@metadata": { # 元数据信息"beat": "filebeat","type": "_doc","version": "7.4.0"},"host": {"name": "box1"},"log": {"file": {"path": ""},"offset": 0},"message": "111", # 输入内容"input": { # 输入类型"type": "stdin"},"agent": { # beat主机信息"id": "b874f712-82d9-467b-a1d9-6e47cb135c55","version": "7.4.0","type": "filebeat","ephemeral_id": "120ebba5-2f21-46db-8f19-77ce6b917c8b","hostname": "box1"},"ecs": {"version": "1.1.0"}}
配置解析
exclude_lines:filebeat会删除与列表中正则表达式匹配的任何行,默认情况下,不会删除任何行。忽略空行
encoding:读取数据时使用的编码
filebeat.inputs:
- type: log
...
exclude_lines: ['^DBG']
encoding: GB2312
include_lines:filebeat只会导出与列表中正则表达式匹配的任何行,默认情况下,将导出所有行。忽略空行
filebeat.inputs:
- type: log
...
include_lines: ['^ERR', '^WARN']
只导出ERR/WARN开头的数据
注意:如果同时定义了 include_lines 和 exclude_lines,Filebeat 将首先执行 include_lines,然后再执行 exclude_lines。 定义两个选项的顺序无关紧要。 即使 exclude_lines 在配置文件中的 include_lines 之前出现,include_lines 选项也将始终在 exclude_lines 选项之前执行。
enabled:使用enabled去启用或禁用inputs,默认设置为true
tags:Filebeat在每个已发布事件的标记字段中包含的标记列表。标记使得在Kibana中选择特定事件或在Logstash中应用条件过滤变得很容易。这些标记将被附加到常规配置中指定的标记列表中。
filebeat.inputs:
- type: log
. . .
tags: ["json"]
fields:可选字段,您可以指定将附加信息添加到输出中。例如,可以添加可用于筛选日志数据的字段。字段可以是标量值、数组、字典或它们的任何嵌套组合。默认情况下,此处指定的字段将分组到输出文档的字段子字典下。如
filebeat.inputs:
- type: log
. . .
fields:
app_id: query_engine_12
fields_under_root: 将自定义字段显示为顶级字段
ignore_older: 忽略在指定时间跨度之前修改的所有文件
在 Filebeat 和 Logstash 之中,我们都可以发现一个叫做 ignore_older 的配置项。在默认的时候,它是没有被启动的。一旦它被启动了,表示它将忽略在指定时间跨度之前修改的所有文件。这个被修改的文件,我们通常可以使用如下的命令来进行获得:
$ ls -al test.log
-rw-r--r--@ 1 liuxg staff 194 Jul 23 2020 test.log
你可使用时间的字符串,比如 2h (2小时)及 5m (5 分钟)。我们可以在官方文档处找到详细的说明。
filebeat.inputs:
- type: log
paths:
- /var/log/*.log
ignore_older: 24h
...
在上面,它表示如果日志文件的 modified 时间超过 24 小时,那么, Filebeat 将不导入该文件,即使该文件出现在 path 里
processors:可以过滤和增强导出的数据。使用exclude_lines、include_lines可以达到过滤数据的作用,缺点是需要为每个配置文件配置所需的筛选条件。
每个处理器接收一个事件,对事件应用定义的操作,然后返回事件。如果定义处理器列表,则按照在Filebeat配置文件中定义的顺序执行这些处理器。
可以在配置中定义处理器,以便在事件被发送到配置的输出之前对其进行处理,libbeat类库提供的处理器可以处理以下内容:
- 减少导出字段的数量
- 使用其他元数据增强事件
- 执行附加处理和解码
如删除DBG开头的行
processors:
- drop_event:
when:
regexp:
message: "^DBG:"
如删除来自某个日志文件的所有日志消息
processors:
- drop_event:
when:
contains:
source: "test"
输出类型配置解析
Console输出
output.console:
pretty: true
pretty: 如果pretty设置为true,则写入stdout的事件将被格式化。默认值为false
codec:输出编解码器配置。如果缺少编解码器部分,事件将使用“pretty”选项进行json编码。
enabled: enabled config是用于启用或禁用输出的布尔设置。如果设置为false,则禁用输出
ElasticSearch输出:
output.elasticsearch:
hosts: ["https://localhost:9200"]
index: "filebeat-%{[beat.version]}-%{+yyyy.MM.dd}"
ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
ssl.certificate: "/etc/pki/client/cert.pem"
ssl.key: "/etc/pki/client/cert.key"
bulk_max_size: 1000
hosts:要连接到的ElasticSearch节点的列表。事件按循环顺序分发到这些就饿点。如果一个节点无法访问,则事件将自动返送到另一个节点。每个Elas节点都可以定义为URL或IP:PORT。若没有指定port,则默认是9200
index:索引名称。默认的格式是filebeat-%{[beat.version]}-%{+yyyy.MM.dd}(如filebeat-6.5.4-2020-09-23)。如果修改了这个配置,则必须同时配置setup.template.name和setup.template.pattern
LogStash输出
output.logstash:
hosts: ["127.0.0.1:5044"]
配置文件
filebeat.inputs: //设置日志输入源(可以配置多个)
- type: stdin //日志源类型,这里指定标准输入,也就是控制台
enabled: false //是否启用
- type: log //输入源是个日志文件
enabled: true
paths: //指定文件路径
- /logs/*.log
output.console: //日志收集,最后输出,这里指定输出到控制台
pretty: true //使用友好格式输出
enabled: true //是否启用
output.elasticsearch: //收集日志到es
hosts: ["http://10.0.16.15:9202"]
###################### Filebeat Configuration Example #########################
# This file is an example configuration file highlighting only the most common
# options. The filebeat.reference.yml file from the same directory contains all the
# supported options with more comments. You can use it as a reference.
#
# You can find the full configuration reference here:
# https://www.elastic.co/guide/en/beats/filebeat/index.html
# For more available modules and options, please see the filebeat.reference.yml sample
# configuration file.
#=========================== Filebeat inputs =============================
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
# 日志实际路径地址
- /data/learning/learning*.log
fields:
# 日志标签,区别不同日志,下面建立索引会用到
type: "learning"
fields_under_root: true
# 指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的
encoding: utf-8
# 多行日志开始的那一行匹配的pattern
multiline.pattern: ^{
# 是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。 【建议设置为true】
multiline.negate: true
# 匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
multiline.match: after
# 探矿者在指定的路径中检查新文件的频率
# 而不会导致Filebeat过于频繁地扫描。默认值:10s。
scan_frequency: 10s
# 定义每个采集器在获取文件时使用的缓冲区大小
harvester_buffer_size: 16384
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
# 日志实际路径地址
- /data/study/study*.log
fields:
type: "study"
fields_under_root: true
# 指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的
encoding: utf-8
# 多行日志开始的那一行匹配的pattern
multiline.pattern: ^\s*\d\d\d\d-\d\d-\d\d
# 是否需要对pattern条件转置使用,不翻转设为true,反转设置为false。 【建议设置为true】
multiline.negate: true
# 匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
multiline.match: after
#============================= Filebeat modules ===============================
#filebeat.config.modules:
# Glob pattern for configuration loading
# path: ${path.config}/modules.d/*.yml
# Set to true to enable config reloading
#reload.enabled: true
# Period on which files under path should be checked for changes
#reload.period: 10s
#==================== Elasticsearch template setting ==========================
setup.template.settings:
index.number_of_shards: 1
#index.codec: best_compression
#_source.enabled: false
# # 生成index模板的名称
#允许自动生成index模板
setup.template.enabled: true
# # 如果存在模块则覆盖
setup.template.overwrite: true
# # # 生成index模板时字段配置文件
setup.template.fields: fields.yml
setup.template.name: "logdata"
# # # 生成index模板匹配的index格式
setup.template.pattern: "logdata-*"
setup.ilm.enabled: auto
# 这里一定要注意 会在alias后面自动添加-*
setup.ilm.rollover_alias: "park-ssm"
setup.ilm.pattern: "{now/d}"
# # # 生成kibana中的index pattern,便于检索日志
# #setup.dashboards.index: myfilebeat-7.0.0-*
# #filebeat默认值为auto,创建的elasticsearch索引生命周期为50GB+30天。如果不改,可以不用设置
setup.ilm.enabled: false
#================================ General =====================================
#============================== Dashboards =====================================
#============================== Kibana =====================================
# Starting with Beats version 6.0.0, the dashboards are loaded via the Kibana API.
# This requires a Kibana endpoint configuration.
setup.kibana:
#kibanaIP地址
host: "localhost:5601"
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
#host: "localhost:5601"
# Kibana Space ID
# ID of the Kibana Space into which the dashboards should be loaded. By default,
# the Default Space will be used.
#space.id:
#============================= Elastic Cloud ==================================
#================================ Outputs =====================================
# Configure what output to use when sending the data collected by the beat.
setup.ilm.enabled: false
#-------------------------- Elasticsearch output ------------------------------
output.elasticsearch:
enabled: true
# Array of hosts to connect to
hosts: ["localhost:9200"]
# index: "logs-%{[beat.version]}-%{+yyyy.MM.dd}"
indices:
#索引名称,一般为 ‘服务名称+ip+ --%{+yyyy.MM.dd}’。
- index: "learning-%{+yyyy.MM.dd}"
when.contains:
#标签,对应日志和索引,和上面对应
type: "learning"
- index: "study-%{+yyyy.MM.dd}"
when.contains:
type: "study"
# Optional protocol and basic auth credentials.
#protocol: "https"
username: "#name"
password: "#pwd"
#----------------------------- Logstash output --------------------------------
#================================ Processors =====================================
# Configure processors to enhance or manipulate events generated by the beat.
processors:
- drop_fields:
# 去除多余字段
fields: ["agent.type","agent.name", "agent.version","log.file.path","log.offset","input.type","ecs.version","host.name","agent.ephemeral_id","agent.hostname","agent.id","_id","_index","_score","_suricata.eve.timestamp","agent.hostname","cloud. availability_zone","host.containerized","host.os.kernel","host.os.name","host.os.version"]
#================================ Logging =====================================
#============================== Xpack Monitoring ===============================
#================================= Migration ==================================
# This allows to enable 6.7 migration aliases
#migration.6_to_7.enabled: true
读取文件
文件有更新, filebeat会自动拉取的
filebeat.inputs:
- type: log
enabled: true
paths: /root/mylog/*.log
output.console:
pretty: true
enable: true
自定义tags还有fields
filebeat.inputs:
- type: log
enabled: true
paths: /root/mylog/*.log
tags: ["web"] # 添加自定义tag, 便于后续处理
fields: # 添加自定义字段
from: jdxia
fields_under_root: true # true为添加到根节点, false是添加到子节点 fields这个对象里面
output.console:
pretty: true
enable: true
输出
{
"@timestamp": "2021-11-21T13:44:47.335Z",
"@metadata": {
"beat": "filebeat",
"type": "_doc",
"version": "7.4.0"
},
"host": {
"name": "box1"
},
"agent": {
"version": "7.4.0",
"type": "filebeat",
"ephemeral_id": "8da66eb6-9c35-4dce-8804-b8b9ce4719d1",
"hostname": "box1",
"id": "b874f712-82d9-467b-a1d9-6e47cb135c55"
},
"log": {
"offset": 8,
"file": {
"path": "/root/mylog/abc.log"
}
},
"message": "12313",
"tags": [
"web"
],
"input": {
"type": "log"
},
"from": "jdxia",
"ecs": {
"version": "1.1.0"
}
}
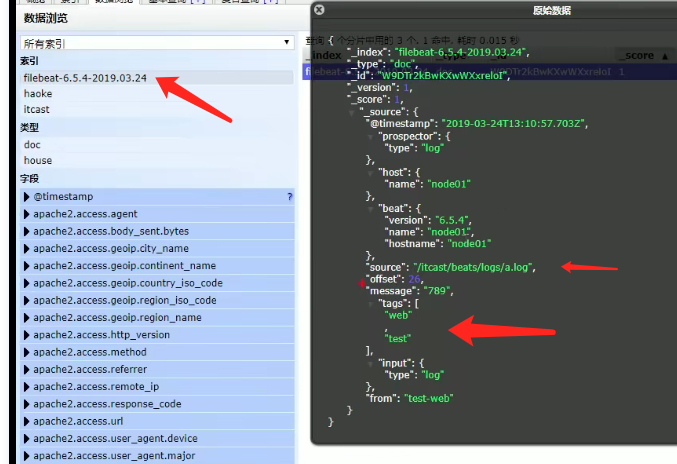
输出到es中
filebeat.inputs:
- type: log
enabled: true
paths: /root/mylog/*.log
tags: ["web", "test"] # 添加自定义tag, 便于后续处理
fields: # 添加自定义字段
from: test-web
fields_under_root: true # true为添加到根节点, false是添加到子节点
setup.template.settings:
index.number_of_shards: 3 # 指定索引分片数
output.elasticsearch:
hosts: ["192.168.33.120:9200", "192.168.33.121:9200"]
module
在Filebeat中,有大量的Module,可以简化我们的配置,直接就可以使用,如
./filebeat modules list
可以看到内置了很多module,但是都没有启用, 如果需要启用和禁用这样操作
# ./filebeat modules enable nginx
Enabled nginx
# ./filebeat modules disable nginx
Disabled nginx
cd modules.d
启用的话后面就没有.disable
我们看下nginx的日志
- module: nginx
# Access logs
access:
enabled: true
#需要填这个路径, *代表我这个是按天生成的
var.paths:["/path/access.log*"]
# Error logs
error:
enabled: true
#需要填这个路径, *代表我这个是按天生成的
var.paths:["/path/error.log*"]
配置filebeat
ilebeat.inputs:
setup.template.settings:
index.number_of_shards: 3 # 指定索引分片数
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.elasticsearch:
hosts: ["192.168.33.120:9200", "192.168.33.121:9200"]
启动前, 需要安装es的插件, 不然会提示你, 高版本好像自带了
sudo bin/elasticsearch-plugin install ingest-user-agent
sudo bin/elasticsearch-plugin install ingest-geoip
时间处理
logstash
在logstash的filter中增加如下代码,就可以把时间转换成北京所在时区时间。
ruby {
code => "event.timestamp.time.localtime"
}
数据去重
我们知道在es中,每个文档数据都有一个文档id,默认情况下这个文档id是es自动生成的,因此重复的文档数据可能产生多个文档。
由于文档 ID 通常是在 Elasticsearch 从 Beats 接收数据后由其设置的,因此重复事件被索引为新文档。
{ "id": "1", "user_name": "arthur","verified": false, "event": "logged_in"}
{ "id": "2", "user_name": "arthur", "verified": true, "event": "changed_state"}
add_id 处理器
如果你的数据没有自然键字段,并且你无法从现有字段派生唯一键,请使用 add_id 处理器。 本示例为每个事件生成一个唯一的 ID,并将其添加到 @metadata._id 字段中:
filebeat.inputs:
- type: log
enabled: true
paths:
- /Users/liuxg/data/processors/sample.json
processors:
- decode_json_fields:
fields: ['message']
target: ''
overwrite_keys: true
- drop_fields:
fields: ["message", "ecs", "agent", "log"]
- add_id: ~
setup.template.enabled: false
setup.ilm.enabled: false
output.elasticsearch:
hosts: ["localhost:9200"]
index: "logs_json"
bulk_max_size: 1000
在上面,我们通过 add_id 这个 processor 为我们的文档设定唯一的 id。最终在 Elasticsearch 中的文档 _id 是由 Filebeat 所生成的。如果我们再次删除 registry 并重新导入文档的话,那么在 Elasticsearch 中将会有重复的文档尽管我们可以通过这样的方式来设定最终文档的 _id。
fingerprint 处理器
filebeat.inputs:
- type: log
enabled: true
paths:
- /Users/liuxg/data/processors/sample.json
processors:
- decode_json_fields:
fields: ['message']
target: ''
overwrite_keys: true
- drop_fields:
fields: ["message", "ecs", "agent", "log"]
- fingerprint:
fields: ["id", "user_name"]
target_field: "@metadata._id"
setup.template.enabled: false
setup.ilm.enabled: false
output.elasticsearch:
hosts: ["localhost:9200"]
index: "logs_json"
bulk_max_size: 1000
encode_json_fields 处理器
解码包含自然键字段的 JSON 字符串时,请使用 encode_json_fields 处理器中的 document_id 设置。
针对我们的 sample.json 文件,我们假定 “id” 字段为唯一的值。 本示例从 JSON 字符串中获取 id 的值,并将其存储在 @metadata._id 字段中:
filebeat.inputs:
- type: log
enabled: true
paths:
- sample.json
processors:
- decode_json_fields:
fields: ['message']
target: ''
overwrite_keys: true
- drop_fields:
fields: ["message", "ecs", "agent", "log"]
- decode_json_fields:
document_id: "id"
fields: ["message"]
max_depth: 1
target: ""
setup.template.enabled: false
setup.ilm.enabled: false
output.elasticsearch:
hosts: ["localhost:9200"]
index: "logs_json"
bulk_max_size: 1000
JSON 输入设定
如果你要提取 JSON 格式的数据,并且该数据具有自然键字段,请使用 json.document_id 输入设置。
本示例从 JSON 文档中获取 id 的值,并将其存储在 @metadata._id字段中:
{"id": "1", "user_name": "arthur", "verified": false, "evt": "logged_in"}
{"id": "2", "user_name": "arthur", "verified": true, "evt": "changed_state"}
filebeat.inputs:
- type: log
enabled: true
tags: ["i", "love", "json"]
json.message_key: evt
json.keys_under_root: true
json.add_error_key: true
json.document_id: "id"
fields:
planet: liuxg
paths:
- sample.json
output.elasticsearch:
hosts: ["localhost:9200"]
index: "json_logs1"
setup.ilm.enabled: false
setup.template.name: json_logs1
setup.template.pattern: json_logs1

若有收获,就点个赞吧
0 人点赞
