目录
| 文件夹 | 作用 |
|---|---|
| /bin | 运行elasticsearch实例和管理插件的一些脚本 |
| /config | 配置文件路径,包含elasticsearch.yml |
| /data | 在节点上每个索引/碎片的数据文件的位置.可以有多个目录 |
| /lib | ElasticSearch使用的库 |
| /logs | 日志的文件夹 |
| /plugins | 已经安装的插件的存放位置 |
启动成功会生成个data和logs文件夹
//mac es7brew tap elastic/tapbrew install elastic/tap/elasticsearch-full// 监控用的brew install elastic/tap/metricbeat-full
es配置
配置文件位于config目录中
jvm.options文件
里面有个
elasticsearch.yml关键配置
| 配置项 | 作用 |
|---|---|
| cluster.name | 集群名称,相同名称为一个集群 |
| node.name | 节点名称,集群模式下每个节点名称唯一 |
| node.master | 当前节点是否可以被选举为master节点,是:true、否:false |
| node.data | 当前节点是否用于存储数据,是:true、否:false |
| path.data | 索引数据存放的位置 |
| path.logs | 日志文件存放的位置 |
| bootstrap.memory_lock | 需求锁住物理内存,是:true、否:false |
| network.host | 监听地址,用于访问该es |
| http.port | es对外提供的http端口,默认9200 |
| transport.port | 节点选举的通信端口默认是9300 |
| discovery.seed_hosts | es7.x之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 |
| cluster.initial_master_nodes | es7.x之后新增的配置,初始化一个新的集群时需要此配置来选举master |
| http.cors.enabled | 是否支持跨域,是:true,在使用head插件时需要此配置 |
| http.cors.allow-origin”*” | 表示支持所有域名 |
cluster.name: my-es #集群名称 --
node.name: node-1 # 节点名称
node.master: true #当前节点是否可以被选举为master节点,是:true、否:false
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300 # --
#初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#写入候选主节点的设备地址 --
discovery.seed_hosts: ["127.0.0.1:9300", "127.0.0.1:9301","127.0.0.1:9302"]
http.cors.enabled: true
http.cors.allow-origin: "*"
修改完配置文件之后,一定要把之前的data目录下node数据删除再重新服务即可。
第二节点配置
拷贝原来的ES节点elasticsearch 并命名为elasticsearch1,并授权 cp elasticsearch/ elasticsearch1 -rfchown -R estest elasticsearch1
进入elasticsearch1目录config文件夹,修改elasticsearch.yml配置文件并保存。
# 修改node.name 和 http.port transport.port
node.name: node-2
http.port: 9201
transport.port: 9301
如果装了插件不能成功连接到es,添加下面的2个命令
# header插件
# 是否支持跨域
http.cors.enabled: true
# *表示支持所有域名
http.cors.allow-origin: "*"
elasticsearch配置说明
- Development与Production模式说明
以transport的地址是否绑定在localhost为判断标准network.host,只要绑定的不是localhost他就认为你在线上模式
bin/elasticsearch -E配置名称=配置值
bin/elasticsearch -Ehttp.port=19200
es7需要jdk11
进入bin文件下:cd binvi elasticsearch
#配置自己的jdk11
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk-11.0.5.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
#添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/Library/Java/JavaVirtualMachines/jdk-11.0.5.jdk/Contents/Home/bin/java"
else
JAVA=`which java`
fi
上面路径换成自己的
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
这是提醒你 cms 垃圾收集器在 jdk9 就开始被标注为 @deprecated -XX:+UseConcMarkSweepGC 改为 -XX:+UseG1GC
kibana配置
打开 config/kibana.yml这个配置文件,告诉kibana他elasticsearch.url在什么地方localhost:9200localhost:5601就可以看到了
汉化https://github.com/anbai-inc/Kibana_Hanization
7.x配置文件
i18n.locale: "zh-CN"
配置文件位于config文件夹中
kibana.yml关键配置说明
- server.host/server.port 访问kibana用的地址和端口,如果你想让外网访问你的kibana就要修改这个
- elasticsearch.url待访问elasticsearch的地址
常用功能
- Discover 数据搜索查看
- Visualize 图标制作
- Dashboard 仪表盘制作
- Timelion 时序数据的高级可视化分析
- DevTools 开发者工具
- Management 配置
启动es集群
本地启动集群的方式
./bin/elasticsearch./bin/elasticsearch -Ehttp.port=8200 -Epath.data=node2./bin/elasticsearch -Ehttp.port=7200 -Epath.data=node3
然后我们启动完就可以用http://localhost:9200/_cat/nodeshttp://localhost:9200/_cat/nodes?v
master 中* 表示那个是主节点
地址栏输入http://localhost:9200/_cluster/stats
简单的集群管理
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
- green:每个索引的primary shard和replica shard都是active状态的
- yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
- red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
节点角色
下面先通过kibana看下不同版本的elasticsearch集群上节点的角色:
使用如下命令: ```java GET _cat/nodes?v
es6<br /><br />es7<br /><br />由于elasticsearch版本迭代速度比较快,加上X-PACK的影响,所以elasticsearch在6和7版本的node的角色变化很大
---
lasticsearch的节点有下面几种角色:
- master
- data
- ingest
- ml
- remote_cluster_client
- transform
根据版本不同,这几种节点是否存在需要根据具体版本的elasticsearch来确定。上面的例子中,mdi,即master、data以及ingest三种角色,这要是elasticsearch自从6.X以来最基础的三种角色;而7.9的dilmrt就是对应着上面的六种全部的角色。而额外的三种角色是ml以及transform是因为X-pack插件的引入而带来的,remote_cluster_client则是跨集群连接时需要用到的client节点。X-pack从6.3版本开始逐步的开源和免费部分功能,所以lrt三个特性在不同版本的elasticsearch中可能有所不同,建议大家根据elasticsearch的版本自行确认
<a name="CrBHF"></a>
## Master
其实这个是master准确的来说是具有成为master节点资格的节点,即master-eligible node,具体哪个节点会成为master node则由master选举算法选举出来的,其中6版本的es使用的是Bully算法进行选举;7版本的es使用的定制版本的Raft算法进行选举,具体两者的实现机制和差异改天换篇文章单独说。<br />主节点负责集群范围内的元数据(即Cluster State)相关的操作,例如创建或删除索引,跟踪哪些节点是集群的一部分以及确定将哪些 shard 分配给哪些节点。 拥有稳定的主节点对于群集健康非常重要。<br />对于大规模的elasticsearch集群配置专用的master节点的必要且有效的,能够提升系统的稳定性,配置方法如下:<br />6.X:
```java
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false
7.X:
node.roles: [ master ]
在高版本的elasticsearch中master节点可以配置为voting_only角色,此类节点是具有master的选举权,但是不具备master的被选举权,即单纯的选民,大多数场景下此种配置不太必要,建议可以不配置。另外该角色只能是具有master角色的节点才可以配置,配置方式如下:
node.roles: [ master, voting_only ]
负责集群相关的操作,例如创建或删除索引,跟踪哪些节点是集群的一部分,以及决定将哪些分片分配给哪些节点。
注意:
1、由于索引和搜索数据都是CPU、内存、IO密集型的,可能会对数据节点的资源造成较大压力。 因此,在较大规模的集群里,最好要设置单独的仅主节点角色。(这点PB级集群调优时重点关注 )
2、不要将主节点同时充当协调节点的角色,因为:对于稳定的集群来说,主节点的角色功能越单一越好。
DataNode
node.data: true 默认是数据节点
保存包含索引文档的分片数据,执行CRUD、搜索、聚合相关的操作。属于:内存、CPU、IO密集型,对硬件资源要求高。
在通用部署的场景下,data节点仅有一个角色data,所有的数据存储和操作都在这个统一的角色下进行。另外为了保证系统的稳定性以及高可用性,配置单独的data节点是必须的,尤其对于大型的elasticsearch集群而言,专用的data节点可以有效的降低节点压力,提升数据处理的稳定性和实时性。配置方式如下:
6.x
node.master: false
node.data: true
node.ingest: false
search.remote.connect: false
7.X:
node.roles: [ data ]
多层部署
在高版本的elasticsearch中,elasticsearch的data节点可以采用多层部署。在这种部署模式下,data节点被细分成data_content,data_hot,data_warm 或 data_cold四类角色,用来存储和处理不同的数据,常常配置elasticsearch的ilm(索引生命周期管理)来共同管理数据。
Content data node
Content data 节点容纳用户创建的内容。 它们启用 CRUD,搜索和聚合之类的操作。此节点的存在对应着通用部署中的data角色,笔者理解是用来存储在多层部署结构中不需要进行冷热数据分离的索引数据,可以理解为通用数据处理角色。按照官网上“一个节点可以属于多个层,但是具有专用数据角色之一的节点不能具有通用数据角色。”这句话的理解,当你按照多层部署时,应该就不可以配置data这种数据角色,而data_content就是data角色在多层部署中的“别名”。
要创建专用的 content 节点,请设置:
node.roles: [ data_content ]
Hot data node
Hot data 数据节点在处理某些种类的ElasticSearch数据,如时序数据这种明显具有时间属性的数据时可以将新数据写入到Hot Data节点中。 Hot Data必须能够快速进行读写操作,并且需要更多的硬件资源(例如 SSD 驱动器)。
要创建专用的 hot 节点,请设置:
node.roles: [ data_hot ]
Warm data node
Warm data 节点存储的索引不再定期更新,但仍在查询中。 查询量通常比索引处于热层时的频率低。 性能较低的硬件通常可用于此层中的节点。
要创建专用的 Warm 节点,请设置:
node.roles: [ data_warm ]
Cold data node
Cold data 节点存储只读索引,该索引的访问频率较低。 该层使用性能较低的硬件,并且可能会利用可搜索的快照索引来最大程度地减少所需的资源。
要创建专用的 cold 节点,请设置:
node.roles: [ data_cold ]
Coordinate
node 协调节点,一个节点只作为接收请求、转发请求到其他节点、汇总各个节点返回数据等功能的节点,就叫协调节点,如果仅担任协调节点,将上两个配置设为false。 说明:一个节点可以充当一个或多个角色,默认三个角色都有
搜索请求在两个阶段中执行(query 和 fetch),这两个阶段由接收客户端请求的节点 - 协调节点协调。
- 在请求阶段,协调节点将请求转发到保存数据的数据节点。 每个数据节点在本地执行请求并将其结果返回给协调节点。
- 在收集fetch阶段,协调节点将每个数据节点的结果汇集为单个全局结果集。
如果一个节点不担任 master 节点的职责,不保存数据,也不预处理文档,那么这个节点将拥有一个仅可路由请求,处理搜索缩减阶段并分配批量索引的协调节点。 本质上,仅协调节点可充当智能负载平衡器。默认elasticsearch的所有节点都可以作为协调节点去路由和分发请求。
对于大型elasticsearch集群,配置单独的协调节点可以使elasticsearch集群通过从 data 和 master-eligible 节点上分担大量的路由和协调的工作量和资源而提升整个系统效率与稳定性。 他们加入群集并像其他所有节点一样接收完整的群集状态,并且使用群集状态将请求直接路由到适当的位置。
但是也不能过分夸大协调节点的作用,在集群中添加过多的仅协调节点会增加整个集群的负担,因为主节点每次发布新的Cluster State必须等待每个节点的集群状态更新确认! 仅协调节点的好处不应被夸大,因为数据节点可以很好地达到相同的目的,而且在某些情况下,协调节点的不合理设置会成为整个集群的性能瓶颈。
要创建专用的协调节点,请设置:
6.x
node.master: false
node.data: false
node.ingest: false
search.remote.connect: false
7.x
node.roles: [ ]
ingest 节点
摄取节点可以执行由一个或多个ingest processor组成的预处理pipeline。用于对写入或者查询的数据进行预处理,即可以将部分client需要预处理的工作放到了server端,如常见的格式转换,空值处理以及时间处理。可以通过
GET _ingest/pipeline
来查看所有的ingest processor,并在查询或者写入数据时配置相关的processor来进行数据预处理。
要创建专用的 ingest 节点,请设置:
6.x
node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
7.x
node.roles: [ ingest ]
Remote-eligible node
默认情况下,集群中的任何节点都可以充当跨集群客户端并连接到其他集群。 连接后,你可以使用跨集群搜索来搜索远程集群。 你还可以使用跨集群复制在集群之间同步数据。这些操作实现的基础就是远程连接节点。
要创建专用的 ingest 节点,请设置:
6.x
node.master: false
node.data: false
node.ingest: false
search.remote.connect: true
7.x
node.roles: [ remote_cluster_client ]
Coordinating only node
可以看作是数据前置处理转换的节点,支持 pipeline管道 设置,可以使用 ingest 对数据进行过滤、转换等操作,类似于 logstash 中 filter 的作用,功能相当强大。
我把Ingest节点的功能抽象为:大数据处理环节的“ETL”——抽取、转换、加载。
思考问题1:线上写入数据改字段需求
如何在数据写入阶段修改字段名(不是修改字段值)?
思考问题2:线上业务数据添加特定字段需求
如何在批量写入数据的时候,每条document插入实时时间戳?
这时,脑海里开始对已有的知识点进行搜索。 针对思考问题1:字段值的修改无非:update,updatebyquery?但是字段名呢?貌似没有相关接口或实现。
针对思考问题2:插入的时候,业务层面处理,读取当前时间并写入貌似可以,有没有不动业务层面的字段的方法呢?
答案是有的,这就是Ingest节点的妙处
Machine learning node(X-pack专用角色)
X-pack笔者用的不多,这里就直接从官网翻译完拿过来直接用了,感兴趣的小伙伴可以自己研究下。
机器学习节点提供了机器学习功能,该节点运行作业并处理机器学习 API 请求。 如果 xpack.ml.enabled 设置为 true,并且该节点不具有 ml 角色,则该节点可以处理 API 请求,但不能运行作业。
如果要在群集中使用机器学习功能,则必须在所有master-eligible的节点上启用机器学习(将 xpack.ml.enabled 设置为true)。 如果要在客户端(包括 Kibana)中使用机器学习功能,则还必须在所有协调节点上启用它。 如果你只有 OSS 发行版,请不要使用这些设置。
要在默认发布中创建专用的机器学习节点,请设置:
node.roles: [ ml ]
xpack.ml.enabled: true
Transform node(X-pack专用角色)
转换节点运行转换并处理转换 API 请求。 如果你只有 OSS 发行版,请不要使用这些设置。
要在默认分发中创建专用的变换节点,请设置:
node.roles: [ transform ]
总结
- 对于大型集群来说,专用的master-eligible节点是必要的,建议初始分配三个节点作为master-eligible节点,后续如果有需求进行扩展,对于6.X版本的elasticsearch,注意需要同步修改discovery.zen.ping.unicast.hosts以及discovery.zen.minimum_master_nodes属性;对于7.X版本的elasticsearch,注意需要修改discovery.seed_hosts相关的属性,建议将discovery.seed_providers配置为外部文件的方式,这样可以做到配置热更新的方式,也方便管理。
- 如果有时序数据以及冷热数据分离的需求,建议data节点使用多层部署的方式,配合elasticsearch的ilm进行数据管理;否则使用通用部署方式即可。
- 协调节点是把双刃剑,用好了可以分担压力负载均衡,用不好可能就会成为性能瓶颈,所以建议非大型或者并发特别大的集群可以不配置专门的协调节点,在这种场景下数据节点也可以很好的处理好协调的问题;对于使用了专属协调节点的集群,建议对协调节点做好监控,当整体集群的性能陷入瓶颈的时候,协调节点的负载和状态也是需要排查的一个方向
最重要的,一定要根据自己的elasticsearch版本来确认哪些节点角色以及如何配置,不能一概而论
配置
不同角色的节点
Master eligible /Data/Ingest/Coordinating /Machine Learning
在开发环境中,一个节点可承担多种角色
在生产环境中,
根据数据量,写入和查询的吞吐量,选择合适的部署方式
建议设置单一角色的节点( dedicated node)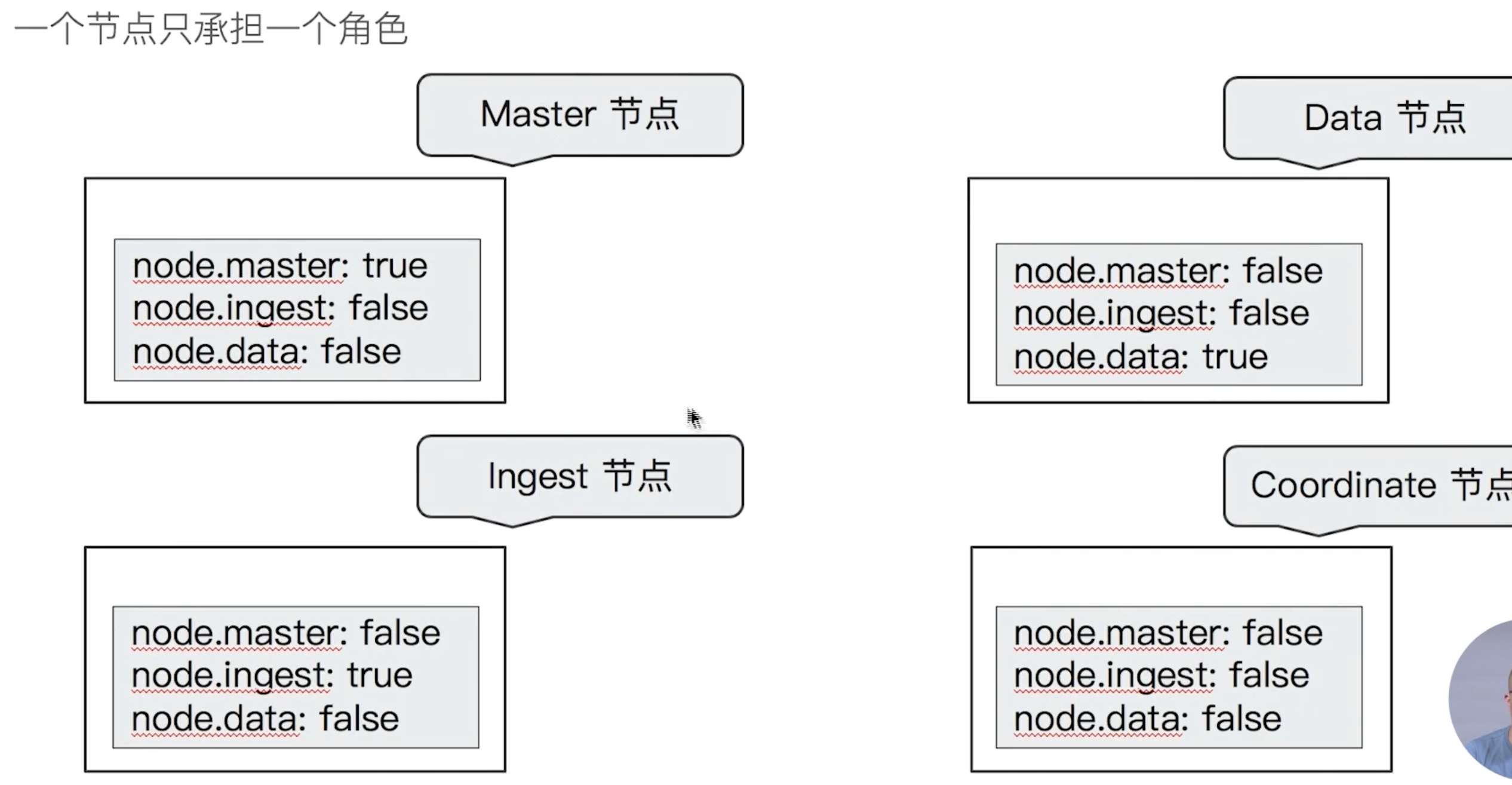
Dedicated master eligible nodes:负责集群状态( cluster state)的管理
使用低配置的CP∪,RAM和磁盘
- Dedicated data nodes:负责数据存储及处理客户端请求
使用高配置的CPU,RAM和磁盘
- Dedicated ingest nodes:负责数据处理
使用高配置CP∪;中等配置的RAM;低配置的磁盘

若有收获,就点个赞吧
0 人点赞
