- 简介
- 索引生命周期管理的前提
- 核心概念:不同阶段(Phrase)的功能点(Acitons)
- ILM管理API
- 获取 ILM 状态
- 结果
- 停止 ILM 服务
- 启动 ILM 服务
- 查看索引 app_log 的生命周期状态
- 重新执行 your_index 索引的 Policy
- ILM例子
- my_node1 配置为 hot 节点
- my_node2 配置为 warm 节点
- my_node3 配置为 cold 节点
- my_node1 配置为 hot 节点
- my_node2 配置为 warm 节点
- my_node3 配置为 cold 节点
- 设置 Policy: log_policy
- 创建索引模版: log_index_template
- 创建索引:log_index-000001
- 小结
简介
在基于日志、指标、实时时间序列的大型系统中,集群的索引也具备类似上图中相通的属性,一个索引自创建之后,不可能无限期的存在下去, 从索引产生到索引“消亡”,也会经历:“生、老、病、死”的阶段
在elasticsearch6.6版本开始,elasticsearch把这两个组件进行了融合,搞出了个ILM(Index Lifecycle Management ,简称 ILM),所谓 Lifecycle(生命周期)是把索引定义了四个阶段:
Kibana 7.12.0 索引生命周期管理配置界面如下图所示: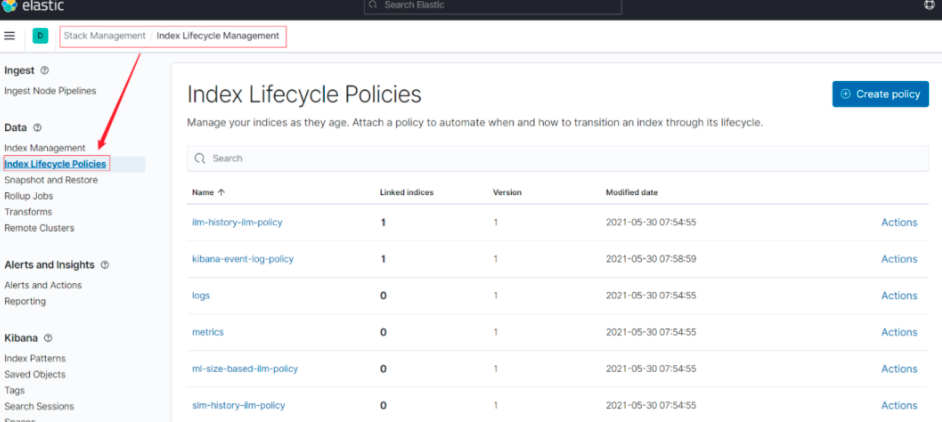
索引生命周期管理的前提
本文演示试用版本:Elasticesarch:7.12.0,Kibana:7.12.0
集群规模:3节点,属性(node_roles)设置分别如下:
- 节点 node-022:主节点+数据节点+热节点(Hot)
- 节点 node-023:主节点+数据节点+温节点(Warm)
- 节点 node-024:主节点+数据节点+冷节点(Cold)
冷热集群架构
冷热架构也叫热暖架构,是“Hot-Warm” Architecture的中文翻译。
冷热架构本质是给节点设置不同的属性,让每个节点具备了不同的属性。
为演示 ILM,需要首先配置冷热架构,三个节点在 elasticsearch.yml 分别设置的属性如下: ```java - node.attr.box_type: hot
- node.attr.box_type: warm
node.attr.box_type: cold ``` 拿舆情数据举例,通俗解读如下:
热节点(Hot):存放用户最关心的热数据。
比如:最近3天的数据——近期大火的“曹县牛皮666,我的宝贝”。
- 温节点(Warm):存放前一段时间沉淀的热数据,现在不再热了。
比如:3-7天的热点事件——“特斯拉车顶事件”。
- 冷节点(Cold):存放用户不太关心或者关心优先级低的冷数据,很久之前的热点事件。
比如:7天前或者很久前的热点事件——去年火热的“后浪视频“、”马老师不讲武德”等。
如果磁盘数量不足,冷数据是待删除优先级最高的。
如果硬件资源不足,热节点优先配置为 SSD 固态盘。
检索优先级最高的是热节点的数据,基于热节点检索数据自然比基于全量数据响应时间要快
核心概念:不同阶段(Phrase)的功能点(Acitons)

注意:仅在 Hot 阶段可以设置:Rollover 滚动。
ILM 里有三个最基本的概念:Phase、Action、Policy。ILM 里将索引的生命周期分为多个 Phase (阶段),Action 是指索引在不同阶段下可以执行的操作。而 Policy 可以将不同阶段的 Action 串联起来,是所有要执行的操作的蓝图。
Phase(阶段)
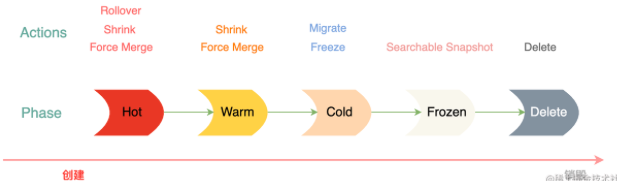
如上图,在 ILM 里 Phase 有 5 个,他们的含义分别如下:
- Hot,处理时序数据的写入和热点数据的查询。
- Warm,不再写入和更新数据,索引被设置为只读,主要承担查询操作。
- Cold,不能执行写操作,这个阶段的数据很少会被查询,而且查询速度很慢。
- Frozen,不能执行写操作,这个阶段的数据几乎不会再进行查询,其查询速度极慢。
- Delete,这个阶段的数据不再被系统业务需要了,可以安全地被删除了。
这些阶段都是见名识意,比较好理解。从图中可以得知,在每个阶段里都有支持的 Actions,那 ES 里可用的 Actions 有那些呢?请继续往下看!
Actions
ES 里可用的 Action 有多个:
- Set Priority,设置 Index 的处理优先级。在节点重启时,优先级越高的索引 recover 时优先被处理。
- Unfollow,在 CCR 架构中,将一个 CCR 跟随索引转换为普通索引,即取消 follow。
- Rollover,提供根据文档数量、索引大小、创建时间自动切换到新的索引。
- Read-Only,设置索引只读。
- Force Merge,强制合并索引,最大限度地使得索引占用更少的 Segment 文件。
- Searchable Snapshot,为索引生成快照,并且存储在指定的仓库和挂载这个快照。
- Shrink,这个我们之前介绍过了,用来缩小索引主分片 (Shard)的数量的。
- Allocate,提供更新索引设置的功能,可以重新分配索引分片的存储节点和更改分片的副本数量。
- Migrate,将索引迁移到对应阶段的数据层级节点上。
- Freeze,冻结索引以最大限度地减少其占用的存储空间。
- Wait For Snapshot,在删除索引前,等待指定的 SLM(快照生命周期管理) 协议执行完成,这样可以保证被删除索引的快照可用。
- Delete,永久地删除索引。
从上图中我们知道,ILM 的每个阶段(Phase)都可以对应多个 Action,下面是各个 Phase 和 Action 的关系:
| ILM Phase | 对应阶段可执行的 Actions |
|---|---|
| Hot | Set Priority、Unfollow、Rollover、Read-Only、Shrink、Force Merge、Searchable Snapshot |
| Warm | Set Priority、Unfollow、Read-Only、Allocate、Migrate、Shrink、Force Merge |
| Cold | Set Priority、Unfollow、Read-Only、Searchable Snapshot、Allocate、Migrate、Freeze |
| Frozen | Searchable Snapshot |
| Delete | Wait For Snapshot、Delete |
ES 支持的 Action 比较多,下面对几个重要的进行详细介绍。更多的 Action 信息和使用示例可以参考官方文档。
Rollover
假如我们想实现一个功能:当一个索引的 size 大于 20G 的时候自动创建一个新的索引来保存数据,这个时候 Rollover 就可以帮到我们了。
从字面上来理解,Rollover 就是滚动的意思。当 Rollover 因满足某些条件被触发的时候,系统会创建新的索引来存储新的数据,并且将索引别名指向新的索引来使得客户端写入无感知,所以 Rollover 需要和 Alias 结合使用。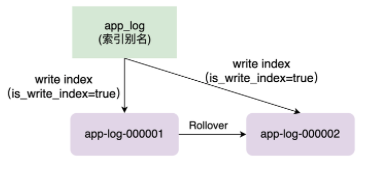
如上图,客户端向 app_log 的索引别名中写入业务数据,当没有触发 Rollover 条件的时候,app_log 别名将指向 app-log-000001,并且 app-log-000001 是一个 write index。而一旦触发 Rollover 条件的时候系统会自动创建 app-log-00002 索引,并且将 app_log 别名指向 app-log-00002,此时会设置 app-log-00001 只读(is_write_index = false)。
可以触发 Rollover 的条件有以下几个:
- 最大的创建时间。意思是经过多长时间后再次创建新的索引来存储数据。其 API 参数为 max_age。
- 最大文档数。当文档总数(主分片上的文档数量)达到指定值后触发 Rollover。其 API 选项为 max_docs。
- 索引大小。当索引所有主分片的 size 之和超过指定值后触发 Rollover。其 API 选项为 max_size。
- 主分片大小。当某个主分片的 size 超过指定值后触发 Rollover。其 API 选项为 max_primary_shard_size。
要设置 Rollover 条件可以使用如下示例:
# 创建一个索引,并且指定其别名为 app_logPUT app-log-000001{"aliases": {"app_log": { "is_write_index": true }}}# 指定 app_log 的 rollover 条件POST /app_log/_rollover{"conditions": {"max_age": "2d","max_docs": 1001,"max_size": "20gb","max_primary_shard_size": "5gb"}}
可以看到 Rollover 可以帮助我们根据条件管理索引,但不合理的配置可能会导致集群中产生过多的小索引,从而导致集群的总分片过多,增加集群的压力影、响查询性能。
更多关于 Rollover 的信息可以参考官方文档
Shrink
Shrink 提供了收缩索引主分片的功能,api可以百度下
Shrink 在底层的实现上是通过硬链接来实现的,但如果操作系统不支持硬链接或者使用了多路径的方式挂载了多个磁盘就会通过复制 Lucene 的分段来实现。
那为啥要用硬链接来实现呢?其实 Linux 文件系统用两部分组成:Inode 和 Block。其中 Inode 用来存储元数据,如文件的字节数、文件拥有者、文件的读写、执行权限、链接数(名指向这个 Inode 的文件数)等,而 Block 是实际存储的文件数据。所以系统可以通过 Inode 定位一个文件的数据。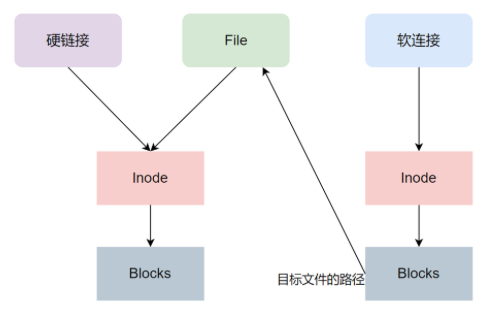
如上图,在 Linux 系统中链接分为软连接和硬链接。它们的特点是:
- 软连接:文件的 Inode 和 Block 都是独立的,但是 Block 的内容为目标文件的路径。
- 硬链接:文件拥有相同的 Inode 和 Block。
所以当源文件被删除的时候,软连接索引的数据会被删除,但是硬链接不会,在删除的时候硬链接只会减少 Inode 的链接数。使用硬链接的另外一个好处是可以不用复制文件,加快 Shrink 操作的速度。
下面看看 Shrink 操作时,硬链接建立的过程。我们将一个拥有 4 个主分片的源索引收缩为只有一个主分片的目标索引,其流程如下: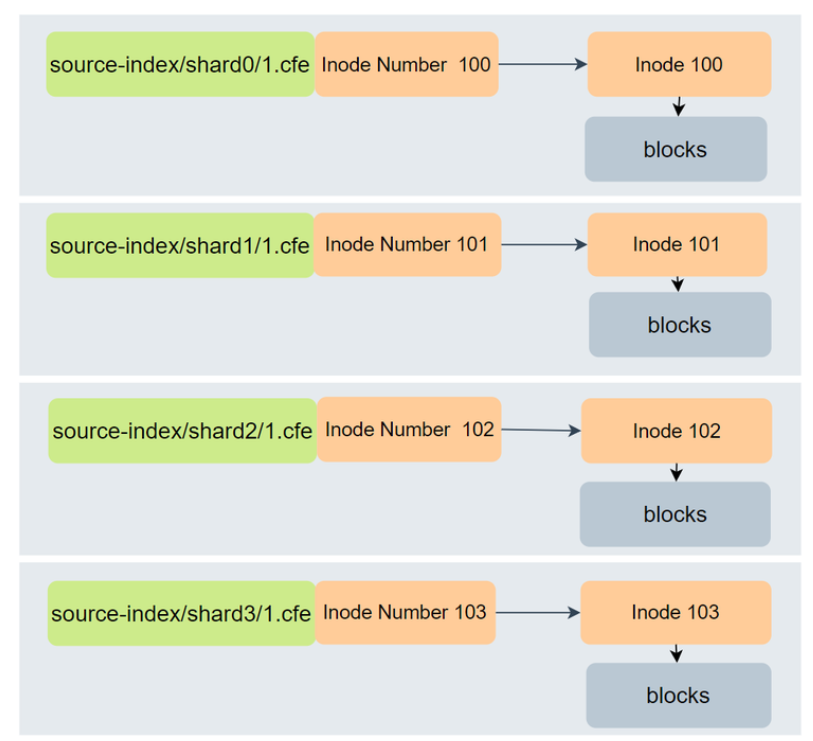
如上图,源索引有 4 个主分片,当进行 Shrink 操作前,需要将这些分片都汇聚到同一个节点,这些分片各占一个文件,它们都有对应的 Inode Number
如上图,链接过程会遍历所有的 shard,将所有的 Segment 文件(Segment 有多个类型文件,这里只列出 .cfe 类型)链接到目标索引,目标索引的 Segment 从 0 开始命名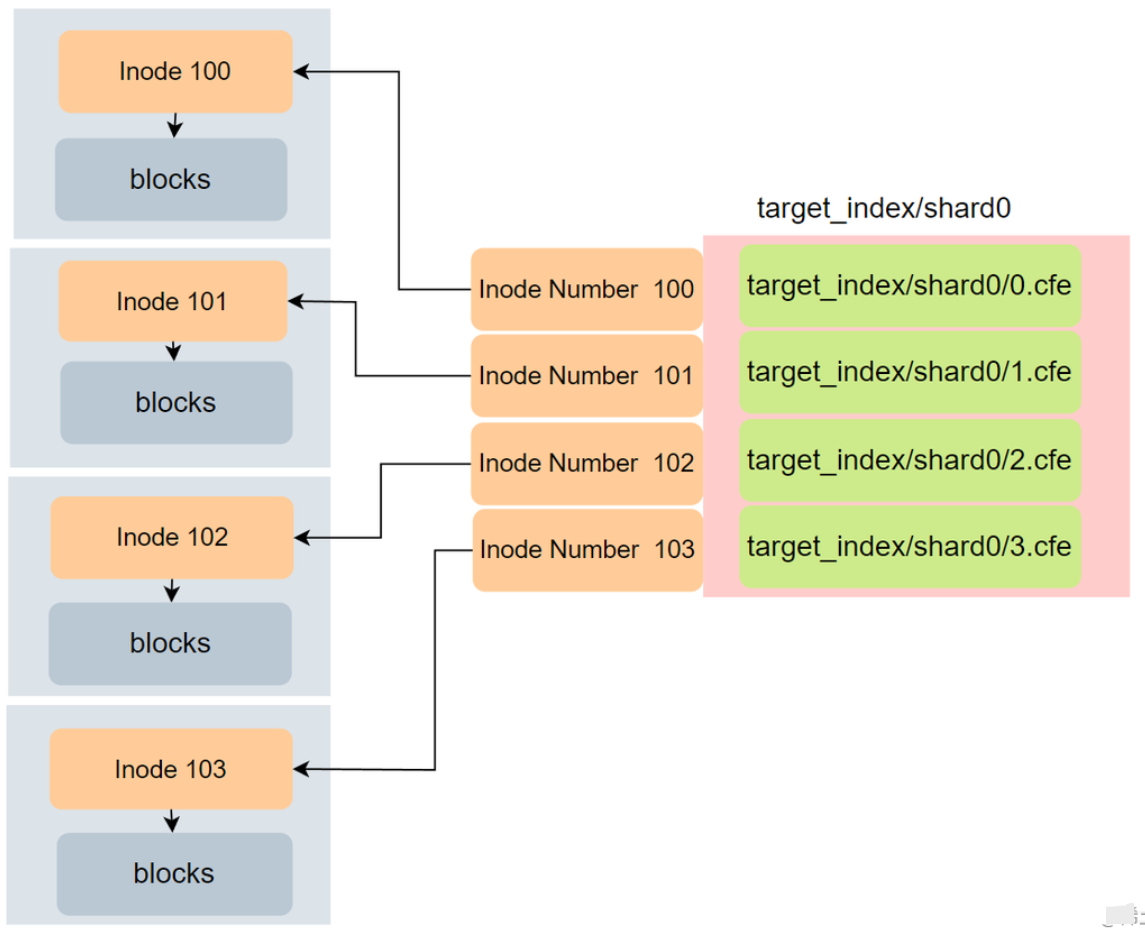
当硬链接创建好后,就可以把原来的索引删除了,在源索引删除后其最终的形式如上图。
其实你会发现,上图的表达并不完整,因为每个 shard 都是一个 Lucene 的索引,而每个 Lucene 索引包含了多个文件,如:.cef、.cfs、.si 等。所以最终 source-index/shard0/1.cef 和 source-index/shard1/1.cef 将映射到 target_index/shard0/0.cef 和 target_index/shard0/1.cef 。
更多更新 Shrink Action 的信息请参考官方文档
Allocate
Allocate action 可以应用在 warm 和 cold 阶段。通过 Allocate 可以更新索引的设置,从而更改索引分片可分配的宿主节点和更改副本数量。
Allocate 的可设置选项有以下四个:
- number_of_replicas,设置副本的数量。
- include,分配索引分片到至少拥有一个指定属性的节点上。
- exclude,分配索引分片到不包含任何一个指定属性的节点上。
- require,分配索引分片到拥有所有属性的节点上。
使用 Allocate 时,这四个选项必须最少指定一个,否则会报错
对于 number_of_replicas 其实很好理解,但是 include、exclude、require 并不好理解,下面举个例子来帮助你理解。假如要为一个节点 A 设置 box_type 属性,我们可以在 elasticsearch.yml 配置文件中设置 node.attr.box_type: hot,这个时候 节点 A 的属性中就有了 box_type,并且其值为 hot。我们可以设置一个 ILM 策略使得应用这个策略的索引在 warm 阶段可以把其分片分配到节点 A。
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": { # 在 warm 阶段 执行
"actions": { # 定义要执行的 action
"allocate" : { # 重新分配索引分片
"include" : {
# 将索引分片分配到带有 box_type 属性,且其值为 hot 或者 warm 的节点上。
"box_type": "hot,warm" # 指定属性列表
}
}
}
}
}
}
}
如上示例,allocate 使用了 include 选项,其效果是:将索引分片分配到带有 box_type 属性,且其值为 hot 或者 warm 的节点上。所以应用这个 ILM 策略的索引可以在 warn 阶段重新分配索引分片到节点 A 上。
同理,exclude、require 就很好理解了。exclude 就是节点属性 box_type 带有 hot 或者 warm 的节点都不分配,require 就是同时带有 hot 和 warm 才分配。
更多关于 Allocate 的信息请参考官方文档
Migrate
Migrate Action 只能用于 warm 和 cold 阶段。使用 Migrate 可以移动索引到与现在 phase 对应的数据层级节点上。
额,啥是数据层级呢?不知道你还记不记得,我们在介绍节点角色类型的时候介绍过,数据节点分为很多类型:data_hot、data_content、data_warm、data_cold、data_frozen。数据层级(data tiers)就是具有相同数据节点角色的节点集合,它们通常有着相同的硬件配置。
所以数据层级(data tiers)官方分为以下几种:
- Content tier, 一般用于保存产品数据的节点,可以索引和检索数据。例如在线书店中书本信息这类数据。
- Hot tier,主要索引最新的时序数据为主,例如日志。
- Warm tier,存储不怎么频繁访问、通常不会更新的时序数据。
- Cold tier,存储很少访问的时序数据,这些数据几乎不会更新。
- Frozen tier,存储几乎不会被访问、不会更新的时序数据。
通过设置 index.routing.allocation.include._tier_preference 索引设置项来指定数据层级,假如 index.routing.allocation.include._tier_preference 设置为 data_warm,data_hot,那么索引在分配的时候会先分配到 warm 层级的节点上,如果不存在 warm 层级节点,就会分配到 hot 层级的节点上。
下面是 Migrate 的使用示例:
# 迁移索引到 warm 节点上
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": {
"actions": {
"migrate" : {
},
"allocate": {
"number_of_replicas": 1
}
}
}
}
}
}
如上示例定义的 ILM 策略,其将会减少索引的副本分片到 1,然后迁移索引到 warm 节点上。需要注意的是,上述示例中 migrate 并没有指定任何操作,所以可以得出 ILM 中会自动执行索引迁移操作,除非你指定具体的分片分配操作或者禁用迁移操作。
禁用 migrate 的示例:
# 不进行 migrate action 的 ILM 策略
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"warm": {
"actions": {
"migrate" : {
"enabled": false
},
"allocate": {
"include" : {
"rack_id": "one,two"
}
}
}
}
}
}
}
如上示例,因为 migrate 被明确禁用了,所以这个 migrate action 不会执行。并且你会发现,allocate 指定了选项,其将会把索引分配到带有 rack_id 为 “one” 或者 “tow” 的节点上。需要注意的是,只要指定了 allocate 进行分配选项,migrate 操作就会被禁止,所以使用 allocate 分配索引分片的优先级是比 migrate 要高的。
Freeze
使用 Freeze Action 可以冻结一个索引从而可以最大限度地减少其占用的内存资源。
其实从占用资源的层面来看,索引有 3 中状态:
- Open,索引可读写,倒排索引等数据会加载到内存中缓存,所以状态下搜索性能高。
- Frozen,索引可读不可写,数据不缓存到内存,此时只占用磁盘空间,搜索性能低。
- Close,索引不可读写,不占用内存,只占用磁盘。
Frozen 状态非常适合存储时序数据的场景和在冷热分离的架构应用。因为 Frozen 的索引不占用内存空间,可以将不怎么访问的历史数据索引设置为 Frozen 来节省资源和保障集群稳定性。
冻结、解冻结、查询冻结的索引的使用示例如下:
# 冻结索引 test
POST /test/_freeze
# 解冻结索引 test
POST /test/_unfreeze
# 查询已经冻结的索引数据
POST /test/_search?ignore_throttled=false
{
"query": {"match_all": {}}
}
需要注意的是,冻结的索引默认是无法检索到数据的,需要查询时加上 ignore_throttled=false 参数。
ok,看完了 Action 后,我们来看看上面提到过的 ILM Policy策略
Policy(策略)
Policy 是 ILM 中的引擎,是所有要执行的操作的蓝图。Policy 会将不同阶段的 Action 串联起来,而索引只有绑定了 Policy 后才会按照 Policy 定义的 Action 执行。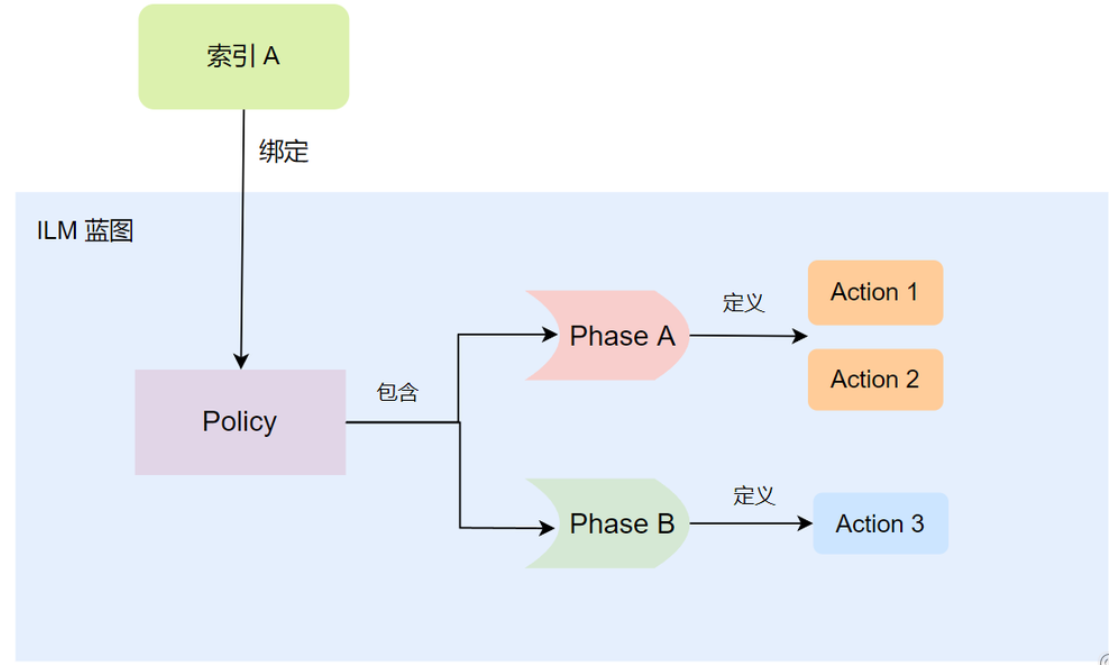
定义或者更新一个 Policy 的示例如下:
# 定义一个策略
# 索引以每 5 个文档做一次 Rollover
# 在 warm 阶段迁移索引到 warm 节点上,
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_docs": "5"
}
}
},
"warm": {
"actions": {
"migrate" : {
},
"allocate": {
"number_of_replicas": 1
}
}
}
}
}
}
如上示例,我们定义了一个策略,在 hot 阶段索引会以每 5 个文档做一次 Rollover,在 warm 阶段会先将索引副本数量设置为 1,然后将索引分片分配到 warm 节点上。
查看和删除 Policy 的示例如下:
# 删除 Policy
DELETE _ilm/policy/my_policy
# 获取 Policy 的信息
GET _ilm/policy/my_policy
索引绑定 Policy 的方式有两种:
- 在 setting 中指定 Policy
- 在索引模板中指定 Policy,只要新的索引应用了这个索引模板就可以绑定对应的 Policy。
在 setting 中指定 Policy
# 创建索引的时候指定
PUT test1
{
"mappings": {
"properties": { "test_name": { "type": "keyword"} }
},
"settings": {
"index.lifecycle.name":"my_policy"
}
}
# 如果索引 test1 已经存在,直接在 setting 中指定
PUT test1/_settings
{
"settings": {
"index.lifecycle.name":"my_policy"
}
}
如上示例,我们在创建 test1 的时候指定了 Policy 为 my_policy。而当 test1 索引已经存在的情况下,我们可以使用第二个示例进行设置索引的 Policy。
在索引模板中指定 Policy
# 定义一个索引模板
PUT _template/test_template
{
"order": 50,
"index_patterns": [ "test-*" ],
"settings": {
"index": {
"lifecycle": {
"name": "my_policy",
"rollover_alias": "test-log"
}
},
"number_of_shards": "3",
"number_of_replicas": "1"
}
}
# 创建 test-11 索引
PUT test-11
{
"mappings": {
"properties": { "test_name": { "type": "keyword"} }
}
}
# 查看 test-11 的设置
GET test-11/_settings
如上示例,我们定义了一个索引模板:test_template,新创建的以 “test-“ 开头的索引将应用这个索引模板。test_template 指定了在 ILM 中使用 my_policy 策略,并且 rollover 时使用 “test-log” 为索引别名。最后创建 test-11 时将会应用 test_template 模板,通过查看 test-11 的 setting 可以发现,其已经应用了 my_policy 策略。
需要注意的是,Policy 的名称确定后就无法修改,但是 Policy 中的 Phase 和 Actions 是可以修改的,一旦 Policy 修改成功,后续新创建的索引会应用最新的 Policy。而那些正在执行旧 Policy 的索引,会在当前 Phase 的 Actions 执行完成后进入下一个阶段的时才会使用更新后的 Policy。
各生命周期 Actions 设定
Hot 阶段
基于:max_age=3天、最大文档数为5、最大size为:50gb rollover 滚动索引
设置优先级为:100(值越大,优先级越高)。
Warm 阶段
关于触发滚动的条件:
- Hot 阶段的触发条件:手动创建第一个满足模板要求的索引
- 其余阶段触发条件:min_age,索引自创建后的时间。
时间类似:业务里面的 热节点保留 3 天,温节点保留 7 天,冷节点保留 30 天的概念。
DSL 实战索引生命周期管理
# step1: 前提:演示刷新需要
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
# step2:测试需要,值调的很小
PUT _ilm/policy/my_custom_policy_filter
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "3d",
"max_docs": 5,
"max_size": "50gb"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "15s",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"allocate": {
"require": {
"box_type": "warm"
},
"number_of_replicas": 0
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30s",
"actions": {
"allocate": {
"require": {
"box_type": "cold"
}
},
"freeze": {}
}
},
"delete": {
"min_age": "45s",
"actions": {
"delete": {}
}
}
}
}
}
# step3:创建模板,关联配置的ilm_policy
PUT _index_template/timeseries_template
{
"index_patterns": ["timeseries-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "my_custom_policy_filter",
"index.lifecycle.rollover_alias": "timeseries",
"index.routing.allocation.require.box_type": "hot"
}
}
}
# step4:创建起始索引(便于滚动)
PUT timeseries-000001
{
"aliases": {
"timeseries": {
"is_write_index": true
}
}
}
# step5:插入数据
PUT timeseries/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
# step6:临界值(会滚动)
PUT timeseries/_bulk
{"index":{"_id":5}}
{"title":"testing 05"}
# 下一个索引数据写入
PUT timeseries/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
核心步骤总结如下:
- 第一步:创建生周期 policy。
- 第二步:创建索引模板,模板中关联 policy 和别名。
- 第三步:创建符合模板的起始索引,并插入数据。
- 第四步: 索引基于配置的 ilm 滚动。
ILM管理API
下面来看看几个 ILM 管理的 API 使用示例,更多关于 ILM 管理 API 的使用示例请查看官方文档获取 ILM 运行状态
```获取 ILM 状态
GET _ilm/status
结果
{ “operation_mode” : “RUNNING” }
ILM 默认的情况下是启动了的,使用如上示例可以查看 IML 的状态。返回的 operation_mode 值有以下 3 个:
- **RUNNING**,正在运行。
- **STOPPING**,正在停止,还有部分 Action 还在处理,处理完成后将转到 STOPPED 状态。
- **STOPPED**,已经停止。
<a name="ZX1ve"></a>
### 停止和启动 ILM
停止 ILM 服务
POST _ilm/stop
启动 ILM 服务
POST _ilm/start
如上示例,你可以在 Kibana 中执行后使用状态查看的 API 查看 ILM 的状态。
<a name="wOLIc"></a>
### 使用 explain 查看 Policy 执行状态
查看索引 app_log 的生命周期状态
GET app_log/_ilm/explain
如上示例,使用 explain 可以查看一个或者多少索引的生命周期状态。
<a name="WT0dy"></a>
### 重新执行索引的 Policy
重新执行 your_index 索引的 Policy
POST your_index/_ilm/retry
如上示例,使用 retry API 可以重新索引的 Policy。需要注意的是,your_index 是你的索引名称,不能为索引的别名。
<a name="Y2KjQ"></a>
# Kibana 图形化界面实现索引生命周期管理
除了使用 API 的形式管理 Policy 外,我们还可以在 Kibana 中对其进行管理。在 Kiabna 中进入 Stack Management => Index Lifecycle Management 即可打开 Policy 管理界面:<br /><br />在管理界面中可以看到我们上面创建的 log_policy,点击绿色箭头处的 Actions 可以绑定 Policy 到索引,而点击右上角的 Create Policy 即可创建新的 Policy。直接点击策略名称如 log_policy 即可管理此 Policy 的各个阶段和对应的 Actions:
<a name="cJ8JA"></a>
## 步骤 1:配置 policy。
<br />如上图,其中 Hot phase 是必须的,点击 Advanced setting 可以设置其对应的 Actions,下图是我们设置 Hot Rollover Action 的界面:<br />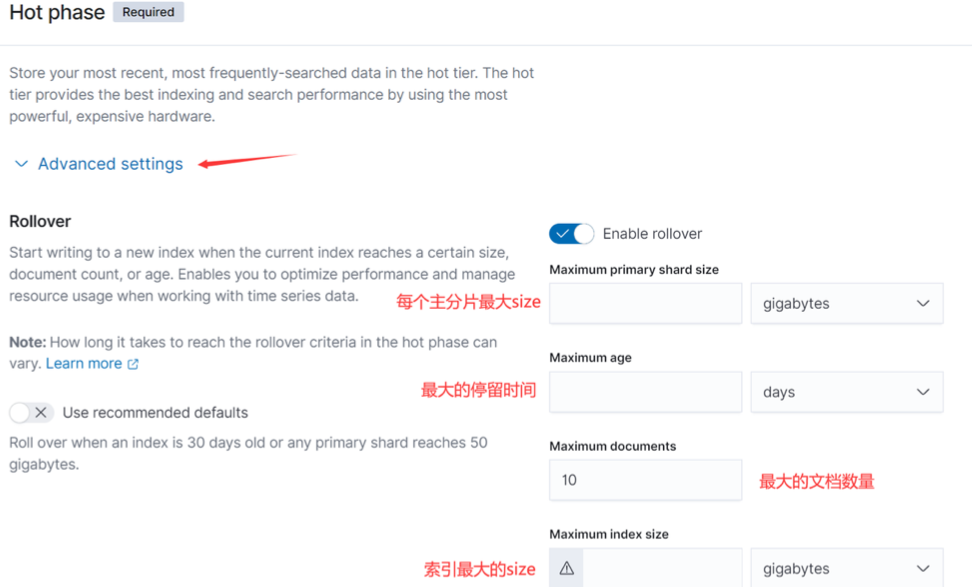
<a name="vsAoM"></a>
## 步骤 2:关联模板
<br />前提条件:
- 模板要自己 DSL 创建,以便关联。
```java
PUT _index_template/timebase_template
{ "index_patterns": ["time_base-*"] }
- 创建起始索引,指定别名和写入。
PUT time_base-000001 { "aliases": { "timebase_alias": { "is_write_index": true } } }
ILM例子
制定需求
在进行实践前,我们先制定我们的需求如下:
- 业务的日志数据写入到 hot 节点上,当索引的文档达到 10 条后执行 Rollover Action,新数据写入到新的索引中。
- 在 Rollover Action 完成 20 秒后,索引进入 warm 阶段,并且索引被分配到了 warm 节点上。
- 在 Rollover Action 完成 30 秒后,索引进入 cold 阶段,并且索引分配到 cold 节点上。
- 在 Rollover Action 完成 60 秒后,索引进入 delete 阶段,并且执行索引删除操作。
修改集群设置
1、设置节点的属性 在 elasticsearch.yml 配置文件中设置节点的属性,我们设置 node.attr.box_type 为 hot、warm、cold,分别代表 hot、warm、cold 节点。在我的环境中其配置如下: ```my_node1 配置为 hot 节点
node.attr.box_type: hot
my_node2 配置为 warm 节点
node.attr.box_type: warm
my_node3 配置为 cold 节点
node.attr.box_type: cold
如果你使用的是 docker-compose 启动的集群,可以这样配置:
my_node1 配置为 hot 节点
environment:
- node.name=my_node1
- node.attr.box_type=hot
my_node2 配置为 warm 节点
environment:
- node.name=my_node2
- node.attr.box_type=warm
my_node3 配置为 cold 节点
environment:
- node.name=my_node3
- node.attr.box_type=cold
完成重启后,集群节点如下:<br /><br />**2、修改策略轮询的时间**<br />默认的情况下 ILM Service 会在后台每 10 分钟轮询执行 Policy,因为我们只是测试,所以设置为 1 秒轮询一次,使用下面指令进行修改:
PUT _cluster/settings { “persistent”: { “indices.lifecycle.poll_interval”:”1s” } }
需要注意的是,在生产环境中不能把这个值设置得过小,避免过短的时间间隔给集群造成负载过大的情况。每个阶段是按顺序执行的,假如一个阶段的 Action 还没有执行完成,但又触发了到达某个阶段的 Condition 的时候,只会等待当前阶段的 Action 执行完成才会执行下一个阶段的 Action。
<a name="jFDpp"></a>
## 操作步骤
通过前面的内容我们可以知道,进行 ILM 实践的操作步骤主要有以下几个:
1. **创建 Policy**,Policy 是蓝图,我们第一步必须定义这个蓝图。
1. **创建索引模板**,将创建的索引模板与上面创建的 Policy 进行绑定。
1. **使用模板创建初始的索引,并且指定别名**,这样索引就绑定了上述的 Policy。
1. **通过别名写入日志数据**。
<a name="SQFWZ"></a>
### 创建 Policy
设置 Policy: log_policy
PUT /_ilm/policy/log_policy { “policy”: { “phases”: { “hot”: { “actions”: { “rollover”: { “max_docs”: 10 # 最大的文档数量为10 } } }, “warm”: { “min_age”: “20s”, # rollover 执行完成 20 秒后,进入 warm 阶段 “actions”: { “allocate”: { “include”: { “box_type”: “warm” } } } }, “cold”: { “min_age”: “30s”, # rollover 执行完成 30 秒后,进入 cold 阶段 “actions”: { “allocate”: { “include”: { “box_type”: “cold” } } } }, “delete”: { “min_age”: “60s”, # rollover 执行完成 60 秒后,进入 delete 阶段 “actions”: { “delete”: {} } } } } }
如上示例定义了一个 Policy:log_policy,这个 Policy 有 hot、warm、cold、delete 阶段。在 hot 阶段指定了 rollover 在超过 10 个文档后执行,产生新的索引来存储新写入的数据。在 rollover 执行完成 20 秒后,进入 warm 阶段,索引数据将分配到 box_type 属性为 warm 的节点上。在 rollover 执行完成 30 秒后,进入 cold 阶段,索引分片将分配在 box_type 属性为 cold 的节点上。最后在 rollover 执行完成 60 秒后,进入 delete 阶段,并且执行索引删除操作。<br />这里需要对 min_age 字段进行解析,min_age 是指数据从 Rollover 完成后开始计算的时间。如果 Policy 没有设置 rollover,则在索引创建后开始计算。
<a name="mi2nL"></a>
### 创建索引模板
创建索引模版: log_index_template
PUT /_template/log_index_template { “index_patterns” : [ “log_index-*” ], “settings” : { “index” : { “lifecycle” : { “name” : “log_policy”, “rollover_alias”: “app_log” }, “routing”: { “allocation” : { “include” : { “box_type” : “hot” } } } }, “number_of_shards” : “1”, “number_of_replicas” : “0”, “refresh_interval” : “1s” } }
如上示例,我们创建了 log_index_template 索引模板,其中指定了 lifecycle 策略为上面定义的 log_policy,并且指定了 rollover 时的索引别名为 app_log。在 routing 中,指定了新创建的索引它们的分片将分配在 box_type 属性为 hot 的节点上。<br />**在模板中一定要定义 routing 和 rollover_alias 的设置,不然 ILM 在 rollover 时自动创建的新索引将找不到这些设置而导致 ILM 失败,产生莫名奇妙的结果**。如果你感兴趣的话可以试一下(可以调整各个阶段的 min_age 值方便观察),这些现象我就不在这里展开了,自己去尝试和思考可以加深理解。
<a name="HArGs"></a>
### 使用模板创建初始的索引
创建索引:log_index-000001
PUT log_index-000001 { “aliases”: { “app_log”: { “is_write_index”: true } },
“mappings”: { “properties”: { “log_msg”: { “type”: “text”} } } }
如上示例使用了 log_index_template 模板创建了初始的索引:log_index-000001。需要注意的是,**Rollover 阶段对索引的名字是有要求的,其形式为:** **_^._-\d+$。***
<a name="vO7kc"></a>
### **通过别名写入日志数据**
POST app_log/_doc
{
“log_msg”: “service up ….”
}
```
如上示例,我们通过 app_log 向索引写入数据(这个 API 会自动分配文档 ID,执行多次可以写入多个文档),这个时候可以在 cerebro 中观察 log_policy 策略的执行过程了。
在我的测试环境中,我简单对执行流程截了几个图: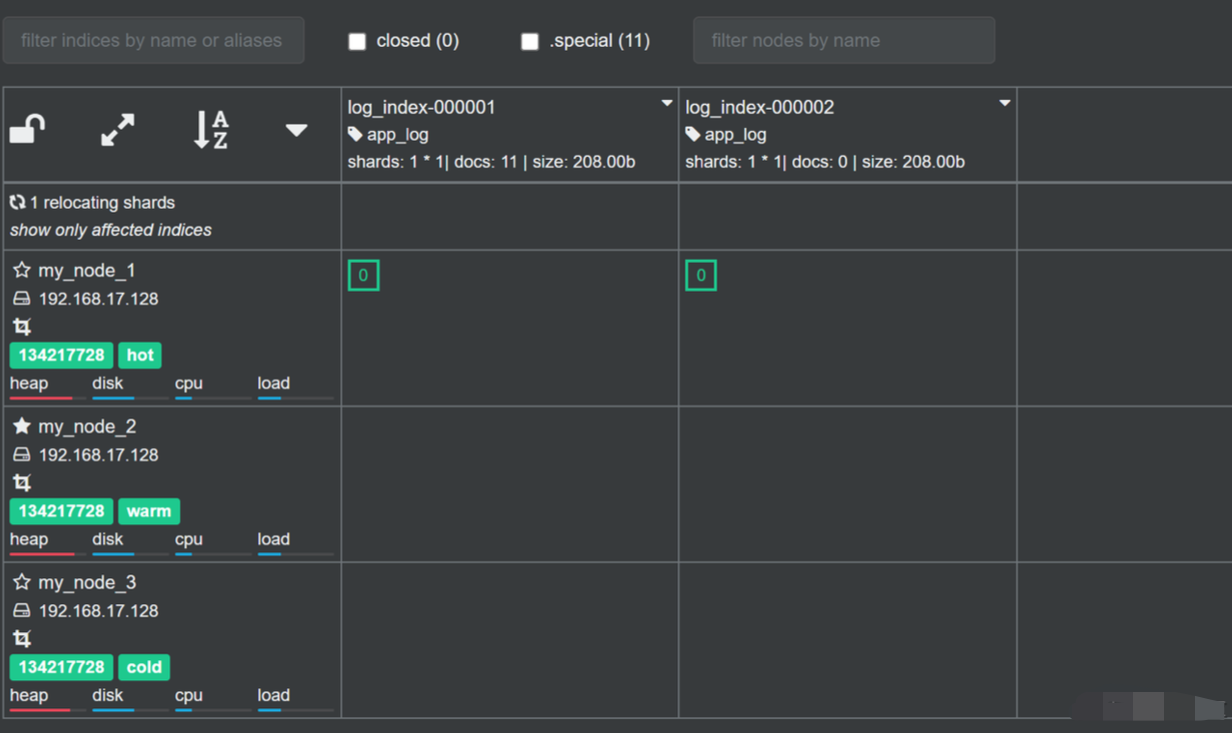
如上图,可以看到在 log_index-000001 的文档超过10 的时候,Rollover 自动执行了,并且创建了 log_index-000002 索引。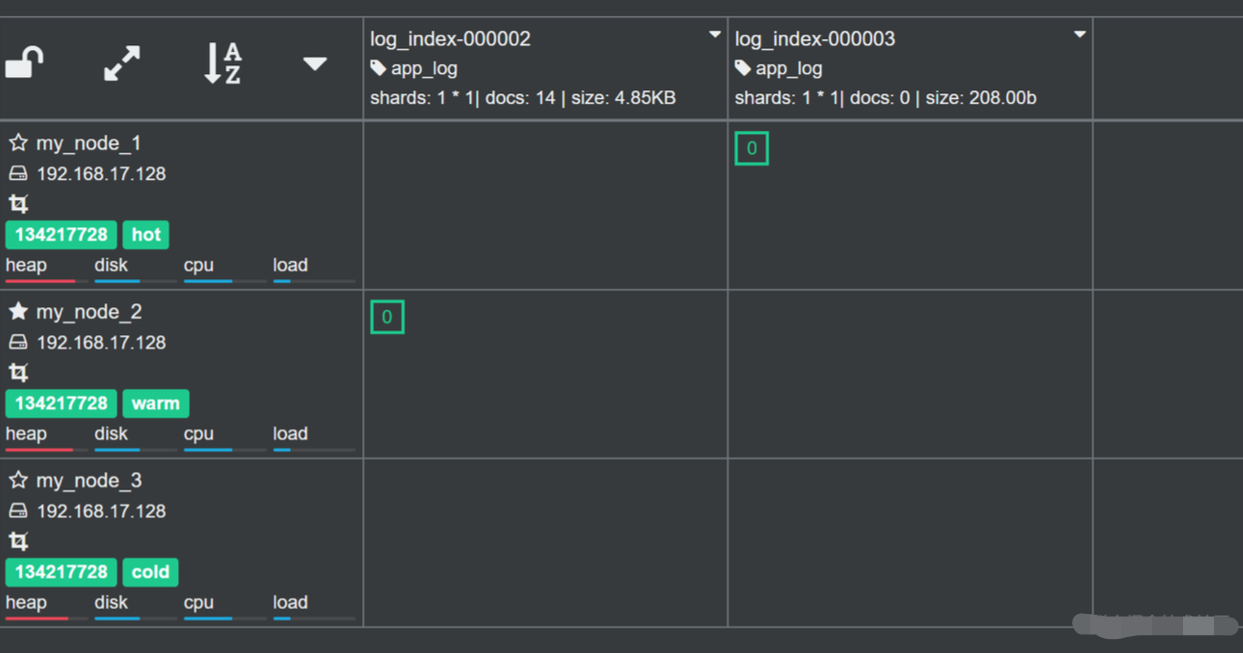
如上图,此时 log_index-000002 已经进入到 warm 阶段,并且分配到 warm 节点了,而 log_index-000001 已经被执行删除。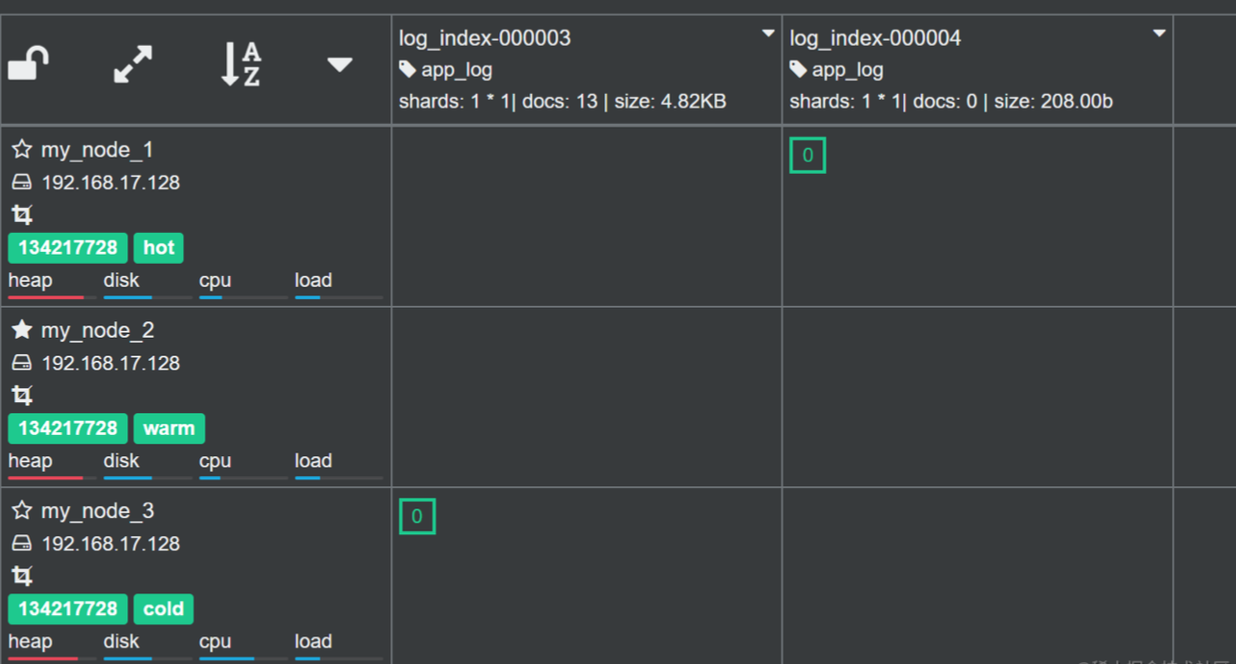
如上图,此时 log_index-000003 已经进入到 cold 阶段,并且索引分配到了 cold 节点,而此时 log_index-000002 已经被执行删除了。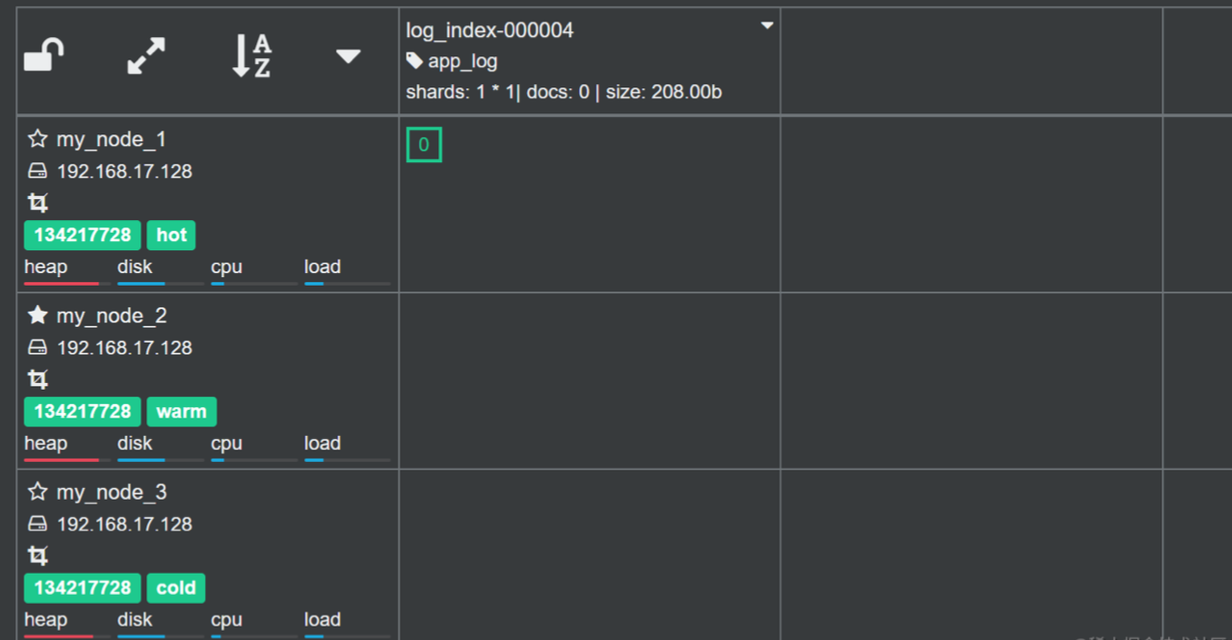
如上图,最终这些索引只剩下了 log_index-000004 在 hot 阶段,随着日志的写入,这个索引最终都会进入到 delete 阶段然后被删除。
更多关于 IML API 的使用示例可以参考官方文档。
小结
索引生命周期管理需要加强对三个概念的认知:
- 横向——Phrase 阶段:Hot、Warm、Cold、Delete 等对应索引的生、老、病、死。
- 纵向——Actions 阶段:各个阶段的动作。
- 横向纵向整合的Policy:实际是阶段和动作的综合体。
ILM 中有5个阶段(Phase)分别为 Hot、Warm、Cold、Frozen、Delete,每个阶段有其对应的 Actions。使用这些 Actions 我们可以在每个阶段执行不同的操作来满足索引管理的需求。Policy 是所有要执行的操作的蓝图,Policy 将不同阶段的 Actrion 串联起来,而索引只有绑定了 Policy 后才会按照 Policy 定义的 Action 执行。
ES 提供的 Actions 有多个,我们主要介绍了以下几个:
- Rollover,是滚动的意思,可以根据文档数量、索引大小、创建时间自动切换到新的索引。
- Shrink ,其可以提供索引收缩的功能,在 Linux 下可以通过硬链接来实现。
- Allocate,可以更新索引的设置,从而更改索引分片可分配的宿主节点和更改副本数量。
- Migrate,使用 Migrate 可以移动索引到与现在 phase 对应的数据层级节点上。
- Freeze,可以冻结一个索引从而可以最大限度地减少其占用的内存资源。
在我们要进行 ILM 的时候,一般需要通过以下步骤进行:
- 创建 Policy,Policy 是蓝图,我们第一步必须定义这个蓝图。
- 创建索引模板,将创建的索引模板与上面创建的 Policy 进行绑定。
- 使用模板创建初始的索引,并且指定别名,这样索引就绑定了上述的 Policy。
- 通过别名写入日志数据。
剩下就是各个阶段 Actions 的调整和优化了。
实战表明:用 DSL 实现ILM 比图形化界面更可控、更便于问题排查。

若有收获,就点个赞吧
0 人点赞
