分页
size:每页显示多少条
from:当前页起始索引, **int start = (pageNum - 1) * size**
from从哪里开始, size截取的数量
POST /book/_search{"query": {"match_all": {}},"size": 2,"from": 0}# 先排序, 再分页POST /book/_search{"query": {"match_all": {}},"sort": [{"price": {"order": "desc"}}],"size": 2,"from": 2}
分布式搜索流程
整体来说,ES 的搜索过程可以分为两个阶段:
- Query 阶段:查询阶段,主要获取文档的排序值和文档 ID 到协调节点。并且协调节点通过排序确定要获取的文档 ID 列表。
- Fetch 阶段:通过 multi get 的方式到对应的分片上获取文档数据。
因此,接下来我们就来详细剖析下这两个阶段,除此之外,还会讲解下由 Query 和 Fetch 这种方式带来的深度分页和相关性算法偏离的问题。
Query 阶段
Query 阶段会根据搜索条件遍历每个分片(主分片或者副分片中的其一)中的数据,返回符合条件的前 N 条数据的 ID 和排序值,然后在协调节点中对所有分片的数据进行排序,获取前 N 条数据的 ID。
Query 阶段的流程如上图,其中 1、2、3 步解析如下:
- 客户端发起 search 请求到 Node1;
- 协调节点 Node1 将查询请求转发到索引的每个主分片或者副分片中,每个分片执行本地查询并且将查询结果打分排序,然后将 from + size 个结果保存到 from + size 大小的有序队列中。
- 每个分片将查询结果返回到 Node1(协调节点)中,Node1 对所有结果进行排序,并且把排序后结果放到一个全局的排序列表中。
需要注意的是,在协调节点转发搜索请求的时候,如果有 N 个 Shard 位于同一个节点时,并不会合并这些请求,而是发生 N 次请求!
Fetch 阶段
在 Fetch 阶段,协调节点会从 Query 阶段产生的全局排序列表中确定需要取回的文档 ID 列表,然后通过路由算法计算出各个文档对应的分片,并且用 multi get 的方式到对应的分片上获取文档数据。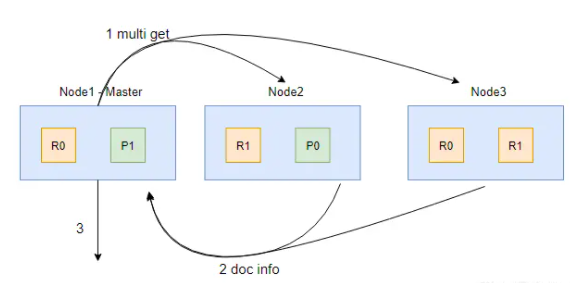
Fetch 阶段的流程如上图,其中 1、2、3 步解析如下:
- 协调节点(Node1)确定哪些文档需要获取,然后向相关节点发起 multi get 请求;
- 分片所在节点读取文档数据,并且进行 _source 字段过滤、处理高亮参数等,然后把处理后的文档数据返回给协调节点;
- 协调节点等待所有数据被取回后返回给客户端。
Query + Fetch 的方式看似很合理,但也会产生一些问题:
- 每个分片上都要取回 from + size 个文档(不是 from 到 size,而是 from + size);
- 协调节点需要处理 shard_amount * ( from + size ) 个文档。
不知道其他分片上, 能读取多少, 如果自己只返回from 到 size, 可能结果数据都不在里面.
然后这些数据都汇总到协调者节点中
深度分页的问题
ES 默认采用的分页方式是 from+ size 的形式,类似于mysql的分页limit。当请求数据量比较大时, Elasticsearch会对分页做出限制,因为此时性能消耗会很大。举个例子,一个索引 分10个 shards,然 后,一个搜索请求,from=990,size=10,这时候,会带来严重的性能问题:
CPU, 内存, IO, 网络带宽
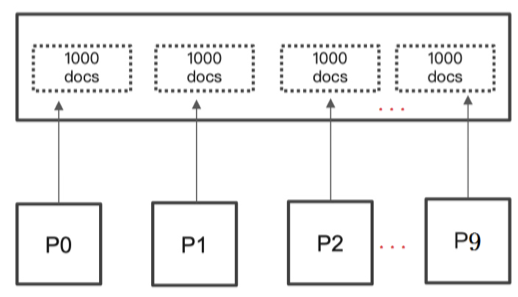
CPU、内存和IO消耗容易理解,网络带宽问题稍难理解一点。在 query 阶段,每个shard需要返回 1000条数据给 coordinating node,而 coordinating node 需要接收 10*1000 条数据,即使每条数据 只有 _doc _id 和 _score,这数据量也很大了,而且,这才一个查询请求,那如果再乘以100呢?
es中有个设置 index.max_result_window ,默认是10000条数据,如果分页的数据超过第1万条,就拒 绝返回结果了。如果你觉得自己的集群还算可以,可以适当的放大这个参数,比如100万。
我们意识到,有时这种深度分页的请求并不合理,因为我们是很少人为的看很后面的请求的,在很多的 业务场景中,都直接限制分页,比如只能看前100页。
不过,这种深度分页确实存在,比如有1千万粉丝的微信大V,要给所有粉丝群发消息,或者给某省粉丝 群发,这时候就需要取得所有符合条件的粉丝,而最容易想到的就是利用 from + size 来实现,但这是 不现实的,我们需要使用下面的解决方案。
分页条数限制
分页太多会报错
"error": {"root_cause": [{"type": "query_phase_execution_exception","reason": "Result window is too large, from + size must be less than or equal to: [1000000] but was [1000000099]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."}]
可以控制修改
PUT /index/_settings
{ "index.max_result_window" :"1000000"}
经过测试,在match_all的情况下,当from值>20w的时候查询的速度将会超过1s(1核2g)
解决深度分页
利用 scroll 遍历方式
scroll 分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照, 在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发
没有from参数
尽量不要使用复杂的sort条件,使用_doc最高效
初始化
POST /book/_search?scroll=1m&size=2
{
"query": { "match_all": {}}
}
初始化时需要像普通 search 一样,指明 index 和 type (当然,search 是可以不指明 index 和 type 的),然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的search请求一样。
scroll=1m表示该scroll快照的有效时间
初始化返回一个scroll_id,scroll_id用来下次取数据用。
遍历
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "步骤1中查询出来的值"
}
这里的 scroll_id 即 上一次遍历取回的 _scroll_id 或者是初始化返回的 _scroll_id,同样的,需要带 scroll 参数。 重复这一步骤,直到返回的数据为空,即遍历完成。注意,每次都要传参数 scroll,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type。设置scroll的时候,需要使搜索结果缓存到下 一次遍历完成,同时,也不能太长,毕竟空间有限
清理scroll
过多的调用scroll会产生大量的内存, 可以通过clear api删除过多的scroll快照
DELETE /_search/scroll
{
"scroll_id": [
"ASD8DHQN22..",
"JBW245GF9.."
]
}
DELETE /_search/scroll/_all
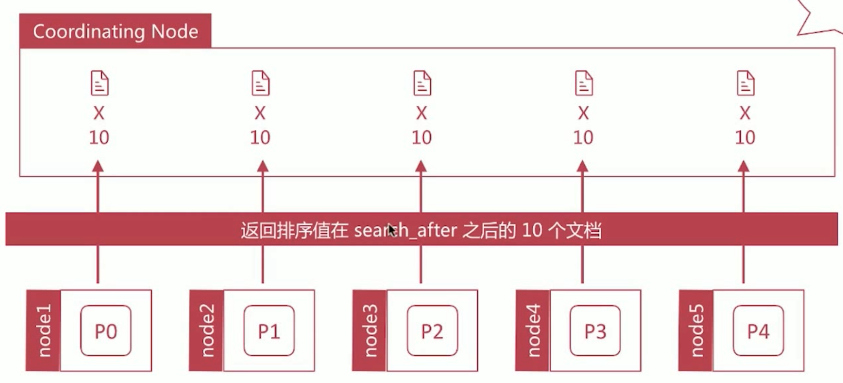
search after方式
满足实时获取下一页的文档信息,search_after 分页的方式是根据上一页的最后一条数据来确定下一页的
只能上一页, 下一页, 不能使用from参数, 不能指定页数
位置,同时在分页请求的过程中,如果有索引数据的增删改,这些变更也会实时的反映到游标上,这种 方式是在es-5.X之后才提供的。为了找到每一页最后一条数据,每个文档的排序字段必须有一个全局唯 一值 使用 _id 就可以了。
GET /book/_search
{
"query":{
"match_all": {}
},
"size":2,
"sort":[
{
"_id": "desc"
}
]
}
GET /book/_search
{
"query":{
"match_all": {}
},
"size":2,
"search_after":[3],
"sort":[
{
"_id": "desc"
}
]
}
下一页的数据依赖上一页的最后一条的信息 所以不能跳页。
Point In Time
Point In Time(PIT)是 ES 7.10 中引入的新特性,PIT 是一个轻量级的数据状态视图,用户可以利用这个视图反复查询某个索引,仿佛这个索引的数据集停留在某个时间点上。也就是说,在创建 PIT 之后更新的数据是无法被检索到的。
当我们想要获取、统计以当前时间节点为准的数据而不考虑后续数据更新的时候,PIT 就显得非常有用了。使用 PIT 前需要显式使用 _pit API 获取一个 PID ID:
# 使用 pit API 获取一个 PID ID
POST /books/_pit?keep_alive=20m
# 结果
{
"id": "46ToAwMDaWR5BXV1aWQy......=="
}
如上示例,使用 _pit 接口获取了一个 PIT ID,keep_alive 参数设置了这个视图的有效时长。有了这个 PIT ID 后续的查询就可以结合它来进行了。
PIT 可以结合 search after 进行查询,能有效保证数据的一致性。 PIT 结合 search after 的流程与前面介绍的 search after 差不多,主要区别是需要在请求 body 中带上 PIT ID,其示例如下:
# 第一次调用 search after,因为使用了 PIT,这个时候搜索不需要指定 index 了。
POST _search
{
"size": 2,
"query": { "match_all": {} },
"pit": {
"id": "46ToAwMDaWR5BXV1aWQy......==", # 添加 PIT id
"keep_alive": "5m" # 视图的有效时长
},
"sort": [
{ "price": "desc" } # 按价格倒序排序
]
}
# 结果
{
"pit_id" : "46ToAwMDaWR5BXV1aWQy......==",
"hits" : {
"hits" : [
{
"_id" : "6",
"_source" : {
"book_id" : "4ee82467",
"price" : 20.9
},
"sort" : [20.9, 8589934593]
},
{
"_id" : "1",
"_source" : {
"book_id" : "4ee82462"
"price" : 19.9
},
"sort" : [19.9, 8589934592]
}
]
}
}
如上示例,在 pit 字段中指定 PIT ID 和设置 keep_alive 来指定视图的有效时长。需要注意的是,使用了 PIT 后不再需要在 sort 中指定唯一的排序值了,也不需要在路径中指定索引名称了。
在其返回结果中,sort 数组中包含了两个元素,其中第一个是我们用作排序的 price 的值,第二个值是一个隐含的排序值。所有的 PIT 请求都会自动加入一个隐式的用于排序的字段称为:_shard_doc,当然这个排序值可以显式指定。这个隐含的字段官方也称它为:tiebreaker(决胜字段),其代表的是文档的唯一值,保证了分页不会丢失或者分页结果的数据不会重复,其作用就好像原 search after 的 sort 字段中要指定的唯一值一样。
在进行翻页的时候和原 search after 一样,需要把上次结果中最后一个文档的 sort 值带上:
# 第二次调用 search after,因为使用了 PIT,这个时候搜索不需要指定 index 了。
POST _search
{
"size": 2,
"query": {
"match_all": {}
},
"pit": {
"id": "46ToAwMDaWR5BXV1aWQy......==", # 添加 PIT id
"keep_alive": "5m" # 视图的有效时长
},
"search_after": [19.9, 8589934592], # 上次结果中最后一个文档的 sort 值
"sort": [
{ "price": "desc" }
]
}
search after + PIT 实现的功能似乎和 scroll API 类似,那它们间有啥区别呢?其实你会发现使用 scroll API 的时候,scroll 产生的上下文是与本次查询绑定的,很明显的一点就是,生成一个 scroll id 后,其他查询无法重用这个 id,scroll 的翻页也只能一直向下翻。而 PIT 可以允许用户在同一个固定数据集合上运行不同的查询,例如多个请求可以使用同一个 PIT 视图而互不影响。
应用场景
| 类型 | 场景 |
|---|---|
| From/Size | 需要实时获取顶部的部分文档, 需要自由翻页 |
| Scroll | 需要全部文档, 导出所有数据的功能 |
| Search_After | 需要全部文档, 不需要自由翻页 |

若有收获,就点个赞吧
0 人点赞
