简介
索引创建之后,等于有了关系型数据库中的database。
Elasticsearch7.x取消了索引type类型的设置, 不允许指定类型,默认为_doc,但字段仍然是有的,
我们需要设置字段的约束信息,叫做字段映射 (mapping)
字段的约束包括但不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
- 分词器
Mapping 属性
https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-params.html
如何建立mapping映射
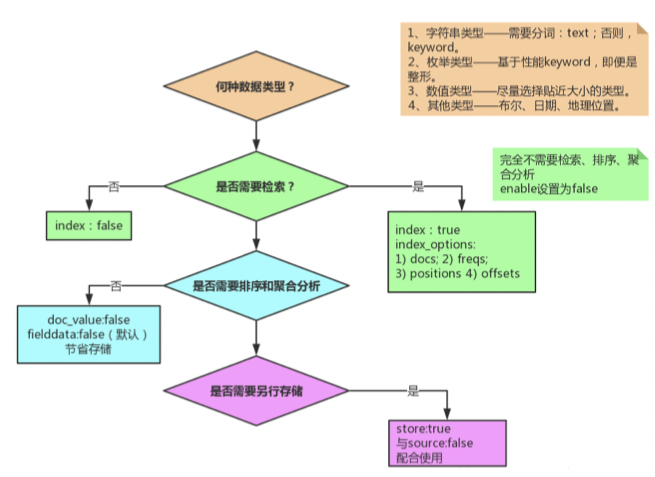
这个索引 Mapping中,_source设置为false,同时各个字段的store根据需求设置了true和false。 url的 doc_values设置为false,该字段url不用于聚合和排序操作。
建 mapping 时,可以为字符串(专指 keyword) 指定 ignore_above,用来限定字符长度。超过
ignore_above的字符会被存储,但不会被索引。
ES5.X版本以后,keyword支持的最大长度为32766个UTF-8字节数,text对字符长度没有限制.
但是分词对长度有限制, 如果长度很长, 需要存储, 就要设置不分词
"index": "not_analyzed",
注意,是字符长度,一个英文字母是一个字符,一个汉字也是一个字符。
在动态生成的 mapping 中,keyword类型会被设置ignore_above: 256。
text没有限制
"abstract": {
"type": "text",
"index": false
}
ignore_above可以在创建 mapping 时指定。
PUT blog_index
{
"mappings": {
"doc": {
"_source": {
"enabled": false
},
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 100
}
},
"store": true
},
"publish_date": {
"type": "date",
"store": true
},
"author": {
"type": "keyword",
"ignore_above": 100,
"store": true
},
"abstract": {
"type": "text",
"store": true
},
"content": {
"type": "text",
"store": true
},
"url": {
"type": "keyword",
"doc_values": false,
"norms": false,
"ignore_above": 100,
"store": true
}
}
}
}
}
查看字段的详情
ES没有提供_stat统计字段API,下面介绍字段能力API,可以返回多个索引的字段信息:
GET /_field_caps?fields=<fields>
POST /_field_caps?fields=<fields>
GET /<target>/_field_caps?fields=<fields>
POST /<target>/_field_caps?fields=<fields>
GET hockey/_field_caps?fields=last
输出
{
"indices" : [
"hockey"
],
"fields" : {
"last" : {
"text" : {
"type" : "text",
"metadata_field" : false,
"searchable" : true,
"aggregatable" : false
}
}
}
}
查询某个索引的字段信息,同时包括未映射的字段:
GET /index_name/_field_caps?fields=*&include_unmapped

若有收获,就点个赞吧
0 人点赞
