简介
es在对文档进行倒排索引的需要用分析器(Analyzer)对文档进行分析、建立索引。从文档中提取词元(Token)的算法称为分词器(Tokenizer),在分词前预处理的算法称为字符过滤器(Character Filter),进一步处理词元的算法称为词元过滤器(Token Filter),最后得到词(Term)。这整个分析算法称为分析器(Analyzer)。
# 测试分词效果, ik_smart, ik_max_word, pinyinPOST /_analyze{"analyzer": "ik_smart","text":"四月份的尾巴你是狮子座"}# 输出, type类型是CN_WORD是一组词, type类型是char的是单个字符{"tokens":[{"token":"四月份","start_offset":0,"end_offset":3,"type":"CN_WORD","position":0},{"token":"的","start_offset":3,"end_offset":4,"type":"CN_CHAR","position":1},{"token":"尾巴","start_offset":4,"end_offset":6,"type":"CN_WORD","position":2},{"token":"你","start_offset":6,"end_offset":7,"type":"CN_CHAR","position":3},{"token":"是","start_offset":7,"end_offset":8,"type":"CN_CHAR","position":4},{"token":"狮子座","start_offset":8,"end_offset":11,"type":"CN_WORD","position":5}]}
其工作流程:
- 先会使用字符过滤器CharacterFilters对文档中的不需要的字符过滤(例如html语言的
<br/>等等) - 用Tokenizer分词器大段的文本分成词(Tokens)(例如可以空格基准对一句话进行分词)
- 最后用TokenFilter在对分完词的Tokens进行过滤、处理(比如除去英文常用的量词:a,the,或者把去掉英文复数等)

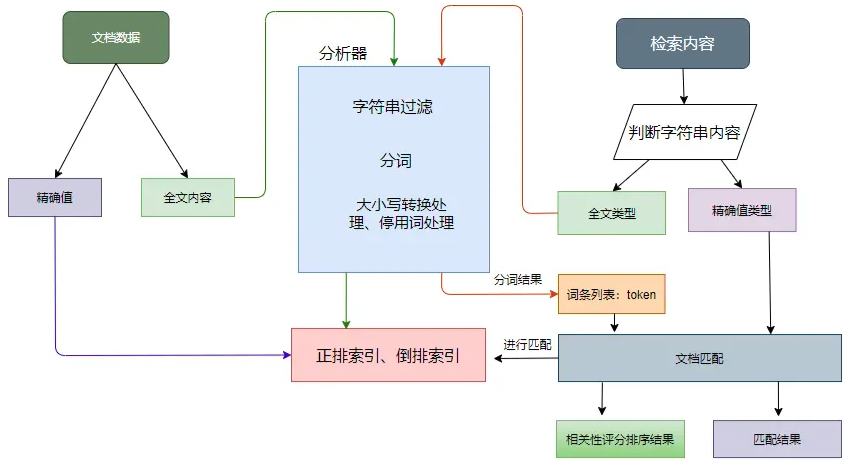
如上图,对全文本数据来说,数据索引时会对文本内容进行分析处理,分析器的处理流程如下:
- 先对字符串进行过滤,把一些 HTML、& 等字符处理掉;
- 分词器会将字符串按某些规律(空格、句号等)切分成单词,输出的这些单词为词条(token);
- 词条过滤器对切分后的词条进行过滤,例如过滤停用词(and、is 等),或者同义词转换等;
- 对过滤后的词条作进一步的处理,如小写转换、词根转换。
在搜索的时候如果是全文数据,会先生成词条列表,然后根据语法规则生成语法树进行查询,最后返回匹配度最高的文档列表。
我们可以使用_analyze来看es的分词是不是符合我们的预期目标
查看分析器效果
GET /blog/_analyze{"text": "Her(5) a Black-cats"}GET /blog/_analyze{"text": "Her(5) a Black-cats" ,"analyzer": "english"}
当然es的强大之处在于除了内置的分词器之外,我们可以自定义分析器,通过组装CharacterFilters、Tokenizer、TokenFilter三个不同组件来自定义分析器或者可以使用别人完成的分析器,最出名的就是ik中文分词插件。
除此之外我们也可以CharacterFilters、Tokenizer、TokenFilter进行自定义。
自定义分析器
作为示范,让我们一起来创建一个自定义分析器吧,这个分析器可以做到下面的这些事:
- 使用 html清除 字符过滤器移除HTML部分。
- 使用一个自定义的 映射 字符过滤器把 & 替换为 “ and “ :
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [ "&=> and "]
}
}
- 使用 标准 分词器分词。
- 小写词条,使用 小写 词过滤器处理。
- 使用自定义 停止 词过滤器移除自定义的停止词列表中包含的词:
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [ "the", "a" ]
}
}
我们的分析器定义用我们之前已经设置好的自定义过滤器组合了已经定义好的分词器和过滤器:
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [ "html_strip", "&_to_and" ],
"tokenizer": "standard",
"filter": [ "lowercase", "my_stopwords" ]
}
}
汇总起来,完整的 创建索引 请求 看起来应该像这样:
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [ "&=> and "]
}},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [ "the", "a" ]
}},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [ "html_strip", "&_to_and" ],
"tokenizer": "standard",
"filter": [ "lowercase", "my_stopwords" ]
}}
}}}
索引被创建以后,使用 analyze API 来 测试这个新的分析器:
GET /my_index1/_analyze
{
"analyzer":"my_analyzer",
"text": "The quick & brown fox"
}
拷贝为 CURL在 SENSE 中查看
下面的缩略结果展示出我们的分析器正在正确地运行:
token分词结果, start_offset 起始偏移, end_offset结束偏移, position分词位置
{
"tokens": [
{
"token": "quick",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "and",
"start_offset": 10,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "fox",
"start_offset": 18,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 4
}
]
}
逗号分割分词
注意, 这个分词器会大小写转换的,
比如 USER,GOODS这样, 你用 term输入USER查, 是查不到的, 因为分词结果是user,goods
PUT /danly
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "1"
},
"analysis": {
"analyzer": {
"ids_analyzer": {
"type": "pattern",
"pattern":[",", " ", ";"]
}
}
}
},
"mappings": {
"properties": {
"ids": {
"type": "text",
"analyzer": "ids_analyzer"
}
}
}
}
搜索时这样搜索
POST /danly/_doc
{
"ids": "2,1,3,4"
}
GET /danly/_analyze
{
"text": "3,1",
"analyzer": "ids_analyzer"
}
GET /danly/_search
{
"query": {
"match": {
"ids": "3,1"
}
}
}
GET /danly/_search
{
"query": {
"terms": {
"ids": [3, 1]
}
}
}
ik和pinyin组合
对于某个中文field进行ik分词,并对ik分词后的结果进行pinyin分词,这样我通过中文和英文都可以对此field进行搜索。
ik_smart切的比较粗, 出的结果比较少
比如说“道路挖掘”,分词结果是道路 和 挖掘,其拼音应该是daolu和wajue,那么我通过daolu或道路应该都能搜索到这条记录。
定义一个自定义分词器ik_pinyin_analyzer
运行流程看上面工作流程
PUT /test_index
{
"settings": {
"analysis": {
"analyzer": {
"ik_smart_pinyin": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["my_pinyin", "word_delimiter"]
},
"ik_max_word_pinyin": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["my_pinyin", "word_delimiter"]
}
},
"filter": {
"my_pinyin": {
"type" : "pinyin",
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"keep_original" : true,
"limit_first_letter_length" : 16,
"lowercase" : true,
"remove_duplicated_term" : true
}
}
}
}
}
测试
POST test_index/_analyze
{
"analyzer": "ik_smart_pinyin",
"text":"道路挖掘"
}
mapping可以是这样的
{
"properties": {
"lawbasis":{
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"fields": {
"my_smart_pinyin":{
"type":"text",
"analyzer": "ik_smart_pinyin",
"search_analyzer": "ik_pinyin_analyzer"
}
}
}
}
}

若有收获,就点个赞吧
0 人点赞
