java_home
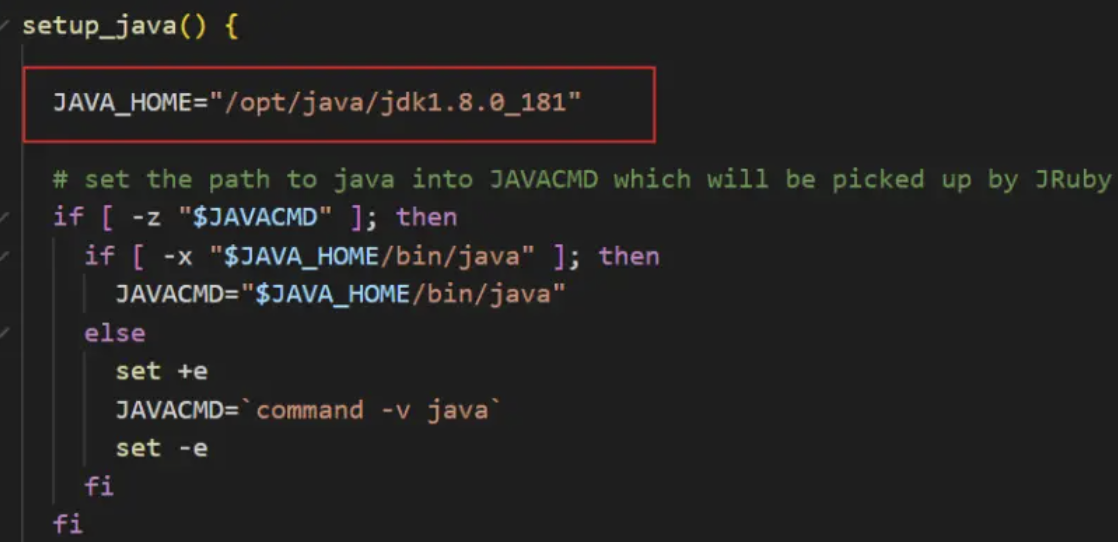
因在开机启动中,logstash 找不到 java 的运行环境,所以需要手动配置下 logstash
cd /home/software/logstash-7.6.2/bin/vim logstash.lib.sh
在 setup_java() 方法的第一行加入 JAVA_HOME 变量,JAVA_HOME 的路径需要根据自己的 java 安装目录来
JAVA_HOME="/opt/java/jdk1.8.0_181"
配置文件
- logstash.yml:包含Logstash配置标志。您可以在此文件中设置标志,而不是在命令行中传递标志。在命令行上设置的任何标志都会覆盖logstash中的相应设置
- pipelines.yml:包含在单个Logstash实例中运行多个管道的框架和指令。
- jvm.options:包含JVM配置标志。使用此文件设置总堆空间的初始值和最大值。您还可以使用此文件为Logsta设置语言环境
- log4j2.properties:包含log4j 2库的默认设置
- start.options (Linux):用于配置启动服务脚本
logstash.yml 设置项
node.name #默认主机名,该节点的描述名字path.data #LOGSTASH_HOME/data ,Logstash及其插件用于任何持久需求的目录pipeline.id #默认main,pipeline的idpipeline.java_execution #默认true,使用java执行引擎pipeline.workers #默认为主机cpu的个数,表示并行执行管道的过滤和输出阶段的worker的数量pipeline.batch.size #默认125 表示单个工作线程在尝试执行过滤器和输出之前从输入中收集的最大事件数pipeline.batch.delay #默认50 在创建管道事件时,在将一个小批分派给管道工作者之前,每个事件需要等待多长时间(毫秒)pipeline.unsafe_shutdown #默认false,当设置为true时,即使内存中仍有运行的事件,强制Logstash在关闭期间将会退出。默认情况下,Logstash将拒绝退出,直到所有接收到的事件都被推入输出。启用此选项可能导致关机期间数据丢失pipeline.ordered #默认auto,设置管道事件顺序。true将强制对管道进行排序,如果有多个worker,则阻止logstash启动。如果为false,将禁用维持秩序所需的处理。订单顺序不会得到保证,但可以节省维护订单的处理成本path.config #默认LOGSTASH_HOME/config 管道的Logstash配置的路径config.test_and_exit #默认false,设置为true时,检查配置是否有效,然后退出。请注意,使用此设置不会检查grok模式的正确性config.reload.automatic #默认false,当设置为true时,定期检查配置是否已更改,并在更改时重新加载配置。这也可以通过SIGHUP信号手动触发config.reload.interval #默认3s ,检查配置文件频率config.debug #默认false 当设置为true时,将完全编译的配置显示为调试日志消息queue.type #默认memory ,用于事件缓冲的内部排队模型。为基于内存中的遗留队列指定内存,或为基于磁盘的脱机队列(持久队列)指定持久内存path.queue #默认path.data/queue ,在启用持久队列时存储数据文件的目录路径queue.page_capacity #默认64mb ,启用持久队列时(队列),使用的页面数据文件的大小。队列数据由分隔为页面的仅追加数据文件组成queue.max_events #默认0,表示无限。启用持久队列时,队列中未读事件的最大数量queue.max_bytes #默认1024mb,队列的总容量,以字节为单位。确保磁盘驱动器的容量大于这里指定的值queue.checkpoint.acks #默认1024,当启用持久队列(队列)时,在强制执行检查点之前被隔离的事件的最大数量queue.checkpoint.writes #默认1024,当启用持久队列(队列)时,强制执行检查点之前的最大写入事件数queue.checkpoint.retry #默认false,启用后,对于任何失败的检查点写,Logstash将对每个尝试的检查点写重试一次。任何后续错误都不会重试。并且不推荐使用,除非是在那些特定的环境中queue.drain #默认false,启用后,Logstash将等待,直到持久队列耗尽,然后关闭path.dead_letter_queue#默认path.data/dead_letter_queue,存储dead-letter队列的目录http.host #默认"127.0.0.1" 表示endpoint REST端点的绑定地址。http.port #默认9600 表示endpoint REST端点的绑定端口。log.level #默认info,日志级别fatal,error,warn,info,debug,trace,log.format #默认plain 日志格式path.logs #默认LOGSTASH_HOME/logs 日志目录
keystore
keystore可以保护一些敏感的信息,使用变量的方式替代,比如使用ES_PWD代替elasticsearch的密码,可以通过${ES_PWD}来获取elasticsearch的密码,这样就是的密码不再是明文密码。./bin/logstash-keystore create #创建一个keyword ./bin/logstash-keystore add ES_PWD #创建一个elastic的passwd,然后通过${ES_PWD}使用该密码 ./bin/logstash-keystore list #查看已经设置好的键值对 ./bin/logstash-keystore remove ES_PWD #删除在keyword中的key
支持的value type
value types(logstash支持的数据类型)
array:数组可以是单个或者多个字符串值。
users => [ {id => 1, name => bob}, {id => 2, name => jane} ]
Lists:集合
path => [ "/var/log/messages", "/var/log/*.log" ]
uris => [ "http://elastic.co", "http://example.net" ]
Boolean:true 或者false
ssl_enable => true
Bytes:字节类型
my_bytes => "1113" # 1113 bytes
my_bytes => "10MiB" # 10485760 bytes
my_bytes => "100kib" # 102400 bytes
my_bytes => "180 mb" # 180000000 bytes
Codec:编码类型
codec => "json"
Hash:哈希(散列)
match => {
"field1" => "value1"
"field2" => "value2"
...
}
# or as a single line. No commas between entries:
match => { "field1" => "value1" "field2" => "value2" }
Number:数字类型
port => 33
Password:密码类型
my_password => "password"
URI:uri类型
my_uri => "http://foo:bar@example.net"
Path: 路径类型
my_path => "/tmp/logstash"
String:字符串类型,字符串必须是单个字符序列。注意,字符串值被括在双引号或单引号中
logstash的权限配置
配置账号,一个种是role,一种是user,配置方式有两种,一种是通过elasticsearch的API配置,一种是通过kibana配置:
elasticsearch的API配置
#添加一个logstash_writer的角色
POST _xpack/security/role/logstash_writer
{
"cluster": ["manage_index_templates", "monitor", "manage_ilm"],
"indices": [
{
"names": [ "logstash-*" ], #索引的模式匹配
"privileges": ["write","create","delete","create_index","manage","manage_ilm"] #权限内容
}
]
}
#添加一个有logstash_writer角色权限的用户:logstash_internal
POST _xpack/security/user/logstash_internal
{
"password" : "x-pack-test-password",
"roles" : [ "logstash_writer"], #分配角色
"full_name" : "Internal Logstash User"
}
#添加一个logstash_reader角色,只有read权限
POST _xpack/security/role/logstash_reader
{
"indices": [
{
"names": [ "logstash-*" ],
"privileges": ["read","view_index_metadata"]
}
]
}
#添加一个有logstash_reader角色权限的用户:logstash_user
POST _xpack/security/user/logstash_user
{
"password" : "x-pack-test-password",
"roles" : [ "logstash_reader", "logstash_admin"],
"full_name" : "Kibana User for Logstash"
}
kibana的界面配置
Management > Roles
Management > Users
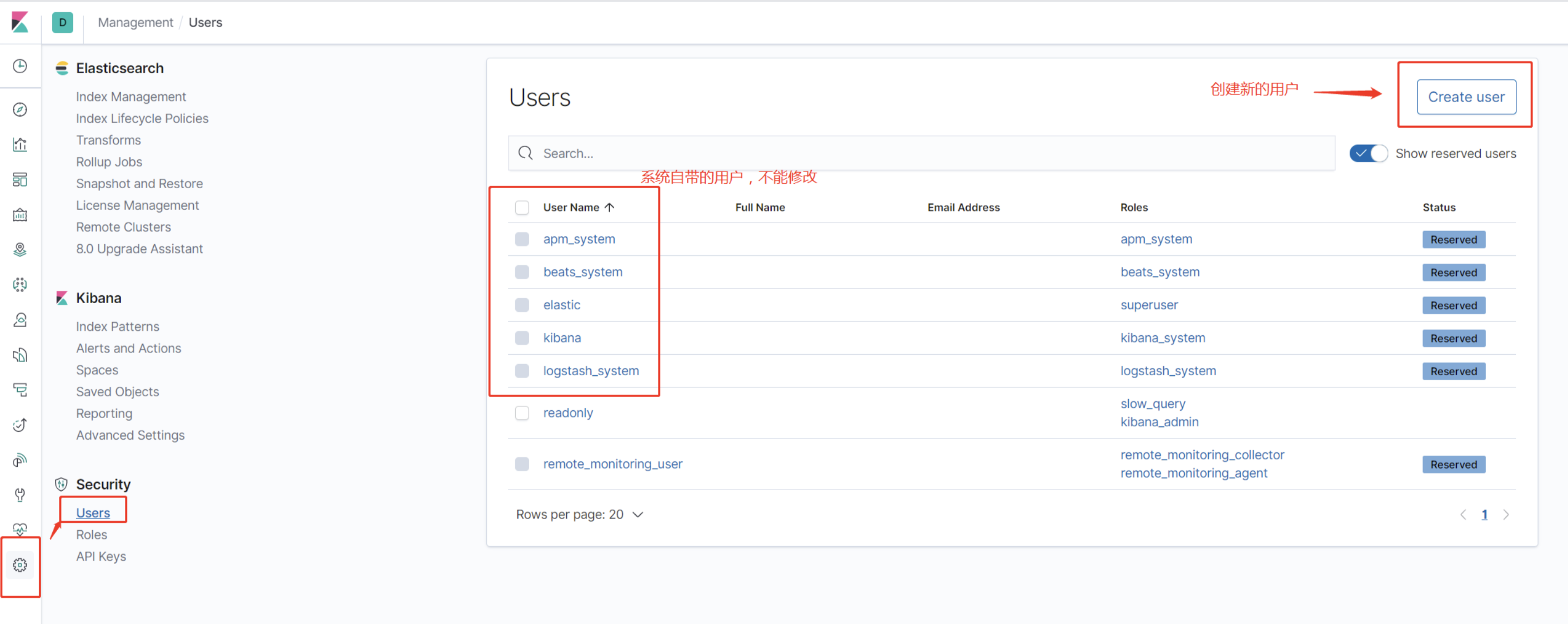
权限选择见elasticsearch官网:
https://www.elastic.co/guide/en/elasticsearch/reference/current/authorization.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/security-privileges.html
多管道配置
如果需要在同一个进程中运行多个管道,Logstash提供了一种通过名为pipelines.yml的配置文件来实现此目的的方法。
例如:
- pipeline.id: my-pipeline_1
path.config: "/etc/path/to/p1.config"
pipeline.workers: 3
- pipeline.id: my-other-pipeline
path.config: "/etc/different/path/p2.cfg"
queue.type: persisted
该文件在YAML文件格式中,并包含一个字典列表,其中每个字典描述一个管道,每个键/值对指定该管道的设置。该示例展示了通过id和配置路径描述的两个不同管道。对于第一个管道,为pipeline.workers的值设置为3,而在另一个中,持久队列特性被启用。未在pipelines.yml显式设置的值。yml文件将使用到logstash中指定的默认值。
当启动Logstash不带参数时,它将读取管道pipelines.yml。yml文件并实例化文件中指定的所有管道。另一方面,当使用-e或-f时,Logstash会忽略管道。
注意:
- 如果当前配置的事件流不共享相同的输入/过滤器和输出,并且使用标记和条件将它们彼此分离,这显得多个管道尤其重要
- 在单个实例中拥有多个管道还允许这些事件流具有不同的性能和持久性参数(例如,pipeline.workers和persistent queues的不同设置)。这种分离意味着一条管道中的阻塞输出不会对另一条管道产生反压力。
- 考虑管道之间的资源竞争是很重要的,因为默认值是针对单个管道调优的。因此,例如,考虑减少每个管道使用pipeline.worker的数量,因为每个管道在默认情况下每个CPU核使用一个worker。
- 每个管道都隔离持久队列和死信队列,它们的位置命名空间为pipeline.id的值
各管道之间的通信原理:https://www.elastic.co/guide/en/logstash/current/pipeline-to-pipeline.html
配置的重新加载
在我们运行logstash的过程,不想停掉logstash进程,但是又想修改配置,就可以使用到配置的重新加载了,有两种方式。
在启动的时候指定参数:
bin/logstash -f apache.config --config.reload.automatic
Logstash每3秒检查一次配置更改。要更改此间隔,请使用--config.reload.interval <interval>选项,其中interval指定Logstash检查配置文件更改的频率(以秒为单位),请注意,必须使用单位限定符(s)
强制加载配置文件
kill -SIGHUP pid #pid为logstash的pid
自动配置重新加载配置注意点:
- 当Logstash检测到配置文件中的更改时,它将通过停止所有输入来停止当前管道,并尝试创建使用更新后的配置的新管道。验证新配置的语法后,Logstash验证所有输入和输出都可以初始化(例如,所有必需的端口都已打开)。如果检查成功,则Logstash会将现有管道与新管道交换。如果检查失败,旧管道将继续运行,并且错误将传播到控制台。
- 在自动重新加载配置期间,不会重新启动JVM。管道的创建和交换都在同一过程中进行。
- 对grok模式文件的更改也将重新加载,但仅在配置文件中的更改触发重新加载(或重新启动管道)时。

若有收获,就点个赞吧
0 人点赞
