字段和倒排索引的关系
首先,在es中,我们可以把一个doc(文档)理解为数据库中的一行数据,每个doc对应多个field(字段),例如:
PUT /employee/group/1{"age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]}PUT /employee/group/2{"age" : 32,"about" : "I like to collect rock albums","interests": [ "music" ]}
es中,会在_source中将数据存一份,然后,写入数据的同时,自动生成mapping信息,根据mapping信息,生成字段对应的倒排索引文件。
自动生成的mapping如下:
{"employee": {"mappings": {"group": {"properties": {"about": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"age": {"type": "long"},"interests": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}}}
按照字段,分别生成倒排索引文件,然后检索字段的时候,搜索字段对应的倒排索引文件即可,如下:
age字段:
age字段因为是long类型,整个字段无需分词(term,token),直接按字段值做倒排索引。
age-1-倒排索引文件
| term词条 | docID |
|---|---|
| 25 | 1 |
| 32 | 2 |
about字段本身为text类型,支持分词,about.keyword多域字段为keyword类型,按整词作为term词条,所以产生about,about.keyword两个字段的倒排索引文件。
about-1-倒排索引文件
| term词条 | docID |
|---|---|
| i | 1,2 |
| love | 1 |
| to | 1,2 |
| go | 1 |
| rock | 1,2 |
| climbing | 1 |
| like | 2 |
| collect | 2 |
| albums | 2 |
about.keyword-1-倒排索引文件
| term词条 | docID |
|---|---|
| I love to go rock climbing | 1 |
| I like to collect rock albums | 2 |
ES检索过程:
- 根据检索字段,如果是text类型的,按照写入索引时的分词机制,进行查询关键字分词,
- 查询字段对应的倒排索引文件,查询term分词,得到对应的docID
- 根据docID,获得doc,显示查询结果。
提问:
- keyword数据类型和text数据类型的区别?
对上面的about字段,keyword数据类型只支持精确搜索,因为keyword建立的索引文件的term,是全词建立索引,没有分词,"about":"I love to go rock climbing"
所以,对于检索 about:”i”,如果格式为keyword将返回null,无搜索结果。
如果格式为text,则分词后建立索引,搜索 about:”i”,有结果,因为有I 的term,
由此可见,分词机制对搜索影响很大,因为term只能完全匹配,才会得到term对应的文档。
倒排索引
倒排索引表以字或词为关键字进行索引,表中关键字所对应的记录项记录了出现这个字或词的所有文档,每个字段记录该文档的ID和关键字在该文档中出现的位置情况。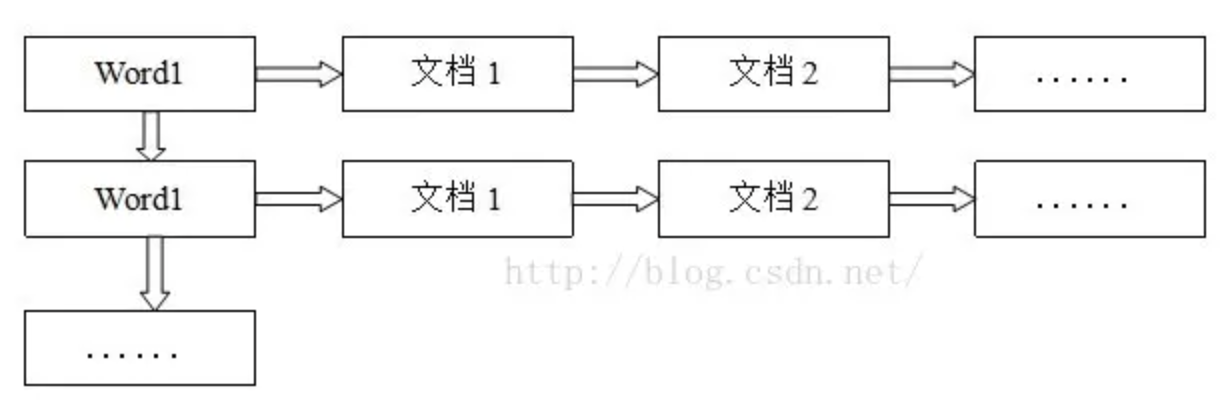
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是一旦完成创建,在查询的时候由于可以一次得到查询关键字所对应的所有文档
倒排索引的不足
- 倒排索引,按分词建立,建立后不可修改。
ES针对修改倒排索引,使用的是再合并策略:对修改的数据建立新的,小的索引文件,记录时间,新的索引文件和旧的索引文件合并,修改的部分,按时间最新覆盖。
- 倒排索引可以很快的通过分词,得到包含分词的文档。但是,如果我们已知文档,想得到文档拥有哪些分词,需要遍历整个倒排索引文件,影响效率。
解决办法是引入doc_values,doc_values是文档对应的分词形成的索引文件。
- 倒排索引十分依赖分词机制,分词机制不好,则搜索结果不理想
ES提供很多分词机制,也支持自定义分词机制。当然,如果不需要分词,只需要精准匹配,直接建立keyword类型数据即可。
- 聚合操作
不过针对某些功能(比如聚合),这种倒排索引架构就不是最佳选择。这类功能通常需要操作文档而不是词项,因此Lucene需要把索引翻转过来构成正排索引,然后才能进行这些功能所需要的计算。基于这些考虑,Lucene引入了doc values和额外的数据结构来进行排序和聚合。doc values是存储字段的正排索引,Lucene和Elasticsearch都允许通过配置来指定doc values的具体存储方式。可选的存储方式包括基于内存的、基于硬盘的以及二者的混合。从Elasticsearch 2.x开始doc values就已经默认提供了
doc_values 文档值
doc_values是什么
doc_values是elasticsearch中,对于倒排索引的部分缺点进行部分补充的功能。
倒排索引很方便单项查看 分词对应的文档,但是不利于反向查看,文档所有的分词。doc_values可以理解为反向的倒排索引,doc_values存放的是文档对应的分词.
正排索引的表结构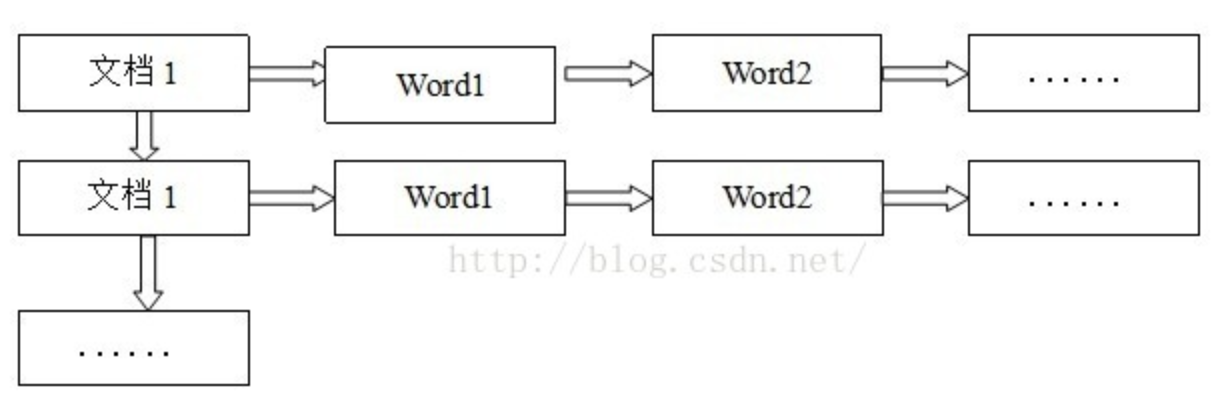
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护,当对ID查询的时候检索效率会很高。
doc_values的应用场景
上面说doc_values 是为了满足反向查询倒排索引而建立的。那么,什么样的情况我们需要用到doc_values呢。大致说来,聚合,排序,都会用到doc_values,
首先,我们进行一次聚合。
//增加一条记录PUT /employee/group/3{"age" : 32,"about" : "I like to read book","interests": [ "music","books" ]}//查询abount中有i的,按age聚合,统计文档数GET /employee/_search{"query" : {"match" : {"about" : "i"}},"aggs" : {"res": {"terms" : {"field" : "age"}}}}
这条语句主要是为了分析,每个数据出现的次数,例如,music有多少人喜欢,sports有多少人喜欢。结果如下:
{"aggregations": {"res": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": 32, //age=32的有两个文档"doc_count": 2},{"key": 25, //age=25的有一个文档"doc_count": 1}]}}}
将上面的查询聚合过程分解:
- 执行query,查询about中包含i这个term的doc。得到文档1,2,3
- 得到文档1,2,3后,我们分析1,2,3的age字段,判断每个age的有多少人。
在第2步中,如果我们只有倒排索引文件,我们需要遍历整个倒排索引,去获取,1,2,3文档的age索引文件,按照age索引文件的term(age是数值类型,整词形成倒排索引,不进行分词),即age的值,然后合并统计文档数。
但是如果我们有doc_values之后,就很方便统计了。
doc_values是和倒排索引同时建立的。同样按索引/类型/字段区分索引文件,doc_value生成数据为
age-1-doc_values索引文件
| 文档ID | 包含的term(不分词的term,即字段对应的值) |
|---|---|
| 1 | 25 |
| 2 | 32 |
| 3 | 32 |
有了doc_values的查询聚合过程如下:
- 执行query,查询about中包含i这个term的doc。得到文档1,2,3
- 得到文档1,2,3后,查询age对应的doc_values索引文件,将age合并,计数,得到25->1,32->2,返回结果。
搜索和聚合是相互紧密缠绕的。搜索使用倒排索引查找文档,聚合操作收集和聚合 doc values 里的数据。
弹性存储
Doc Values的存储是弹性的。因为Doc Values会被序列化到磁盘,所以我们可以利用操作系统的文件系统缓存来保持快速访问而不是直接用JVM堆内存:
当工作集所需内存小于该节点的可用内存时,操作系统自然将所有Doc Values存于内存中(堆外内存),这样就可以有超快的访问速度,和在堆上的表现一样;
反之,如果工作集比可用内存大得多的时候,操作系统会按需把Doc Values从操作系统页缓存中加载或弹出,从而避免发生内存溢出的异常。虽然说这种模式会比完全加载到内存的模式慢,但这样有个好处就是能利用超过服务器内存容量的空间。如果你把所有的这些数据放在java堆里面,那么会直接因为内存不足而崩溃(除非你自己实现一个类似操作系统的页缓存策略)。
所以,当我们大量使用Doc Values时,可以把更少的内存分配给ES,而把更多的内存留给操作系统
DocValues支持禁用
此值默认是启动状态,如果没有必要使用可以设置 doc_values: false来禁用。
Doc Values默认对除了analyzed String外的所有字段启用(因为分词后会生成很多token使得Doc Values效率降低)。但是当你知道某些字段永远不会进行排序、聚合以及脚本操作的时候可以禁用Doc Values以节约磁盘空间提升索引速度,示例如下:
PUT my_index{"mappings": {"my_type": {"properties": {"session_id": {"type": "string","index": "not_analyzed","doc_values": false}}}}}
以上配置以后,session_id字段就只能被搜索,不能被用于排序、聚合以及脚本操作了。
还可以通过设定doc_values为true,index为no来让字段不能被搜索但可以用于排序、聚合以及脚本操作:
PUT my_index{"mappings": {"my_type": {"properties": {"customer_token": {"type": "string","index": "not_analyzed","doc_values": true,"index": "no"}}}}}
注意:
doc_values对不分词的字段默认开启,包括about.keyword这类多域字段,对分词字段默认关闭,即about字段
分词字段. 从数据类型来看,text默认进行分词,keyword,long,int,double,复杂数据类型等默认不进行分词
刚才的描述中,经常强调doc_values存放的是 文档对应的分词数,这句话是容易引起歧义的,但是又是正确的,如果,该字段不允许分词,则该字段的值,就是该文档在这个索引文件的唯一分词(即term),对于能分词的字段,doc_values是默认关闭,但是可以手动开启,这个时候,doc_values存放的是文档对应的分词数 ,这句话就是正确的。
所以,对于docvalues的用途,ES官网的说法是:
Doc values 不仅可以用于聚合。 任何需要查找某个文档包含的值的操作都必须使用它。 除了聚合,还包括排序,访问字段值的脚本,父子关系处理_
为什么对分词字段关闭 没找到官方解释 、个人看法:对分词字段,开启doc_values,产生的索引文件占用磁盘过大,处理的时候,消耗cpu资源
doc_values的优缺点
- doc_values 提高了聚合,排序,所有针对字段值的操作的效率,
- doc_values加大了磁盘空间,但是ES提供了doc_values的压缩算法,对doc_values进行了大量压缩。而且,用不到可以禁用,节省空间。
fielddata
排序的过程本质是对字段原始内容排序的过程, 这个过程中倒排索引无法发挥作用,需要用到正排索引, 也就是通过文档id和字段可以快速得到字段原始内容
因为doc_values不针对分词字段,那么,如果一定要对分词字段的term分词进行聚合,该怎么办呢?
在es中,对分词的field,直接执行聚合操作,会报错
{"type": "illegal_argument_exception","reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [about] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."}
大概意思是说,你必须要打开fielddata,然后将正排索引数据加载到内存中,才可以对分词的field执行聚合操作,而且会消耗很大的内存
fielddata就是满足该需求的,但是,因为过于消耗资源,所以默认关闭。
fielddata结构和doc_values相同,区别是.fielddata运算时在内存中生成,纯内存计算,doc_values放在磁盘中即可
有需求时,在mapping中打开fielddata开关。默认false关闭。
注意内存使用
一些特性:
- Fielddata 是延迟加载的。如果你从来没有聚合一个分析字符串,就不会加载 fielddata 到内存中,是在查询时候构建的。
- fielddata 是基于字段加载的, 只有很活跃地使用字段才会增加fielddata 的负担。
- fielddata 会加载索引中(针对该特定字段的) 所有的文档,而不管查询是否命中。逻辑是这样:如果查询会访问文档 X、Y 和 Z,那很有可能会在下一个查询中访问其他文档。
- 如果空间不足,使用最久未使用(LRU)算法移除fielddata。
所以,fielddata应该在JVM中合理利用,否则会影响es性能。
我们可以使用indices.fielddata.cache.size限制fielddata内存使用,可以是具体大小(如2G),也可以是占用内存的百分比(如20%)。
也可以使用如下命令进行监控。
GET /_stats/fielddata
最后,如果一次性加载字段直接超过内存值会发生什么?挂掉?所以es为了防止这种情况,采用了circuit breaker(熔断机制)。
它通过内部检查(字段的类型、基数、大小等等)来估算一个查询需要的内存。它然后检查要求加载的 fielddata 是否会导致 fielddata 的总量超过堆的配置比例。如果估算查询大小超出限制,就会触发熔断,查询会被中止并返回异常。
indices.breaker.fielddata.limit fielddata级别限制,默认为堆的60%indices.breaker.request.limit request级别请求限制,默认为堆的40%indices.breaker.total.limit 保证上面两者组合起来的限制,默认堆的70%
Fielddata过滤
通过设置可以只加载部分fielddata来节省内存。
“frequency”: {“min”: 0.01,“min_segment_size”: 500}只加载那些至少在本段文档中出现 1% 的项。忽略任何文档个数小于 500 的段。
Fielddata预加载
加载fielddata默认是延迟加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
对于小索引段来说,这个过程的需要的时间可以忽略。但如果索引很大几个GB,这个过程可能会要数秒。对于 已经习惯亚秒响应的用户很难会接受停顿数秒卡顿。
有三种方式可以解决这个延时高峰: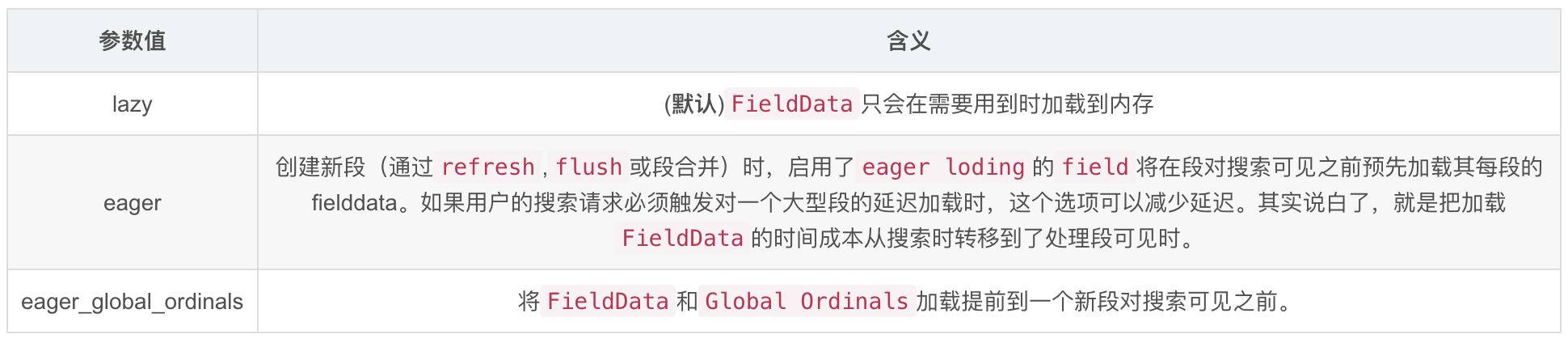
让tags字段的FieldData提前加载的示例:
PUT /music/_mapping/_song{“tags”: {“type”: “string”,“fielddata”: {“loading” : “eager”}}}
FieldData.format可以配置FieldData是否开启,它默认是开启的。可以接受的参数是disabled和paged_bytes(就是启用)
PUT my_index{"mappings": {"my_type": {"properties": {"text": {"type": "string","fielddata": {"format": "disabled"}}}}}}
fielddata和docvalues对比
| 维度 | doc_values | fielddata |
|---|---|---|
| 创建时间 | index时创建 | 使用时动态创建 |
| 创建位置 | 磁盘 | 内存(jvm heap) |
| 优点 | 不占用内存空间 | 不占用磁盘空间 |
| 缺点 | 索引速度稍低 | 文档很多时,动态创建开销比较大,而且占内存 |
查看doc_values和fieldData存储的内容
准备数据
PUT my_index{"mappings": {"properties": {"my_field": {"type": "text","fields": {"keyword": {"type": "keyword"}}}}}}PUT my_index/_mapping{"properties": {"my_field": {"type": "text","fielddata": true}}}POST /my_index/_doc/3{"my_field": "333"}
查看
GET /book/_search
{
"docvalue_fields": [
"name",
"nanme.keyword",
"price"
]
}
返回, fields里面就是fieldData和doc_values的内容
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"my_field" : "1111"
},
"fields" : {
"my_field" : [
"1111"
],
"my_field.keyword" : [
"1111"
]
}
},
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"my_field" : "2222"
},
"fields" : {
"my_field" : [
"2222"
],
"my_field.keyword" : [
"2222"
]
}
},
store存储
字段独立于_source,单独存储,注:_source中依然会存储该字段
优点: ES中,所有数据统一存在_source中,如果只是查询一个小字段,却要把_source中的整条数据显示后,再从_source中取出对应的字段,浪费资源。
缺点: 加大磁盘使用。
应用场景: 如果_source很大,频繁使用的字段很小,则应该store该字段,这样不需要每次都将_source加载完后,在查找该字段。
[
](https://blog.csdn.net/u013501457/article/details/86009050)
[
](https://blog.csdn.net/u013501457/article/details/86009050)

若有收获,就点个赞吧
0 人点赞
