1. 机器学习
2. 工作流程
- 获取数据
- 数据基本除了
- 特征工程
- 机器学习(模型训练)
- 模型评估
3. 特征工程
- 把数据转换为机器更容易识别的数据
- 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
- 特征提取 特征预处理 特征降维
4. 机器学习算法分类
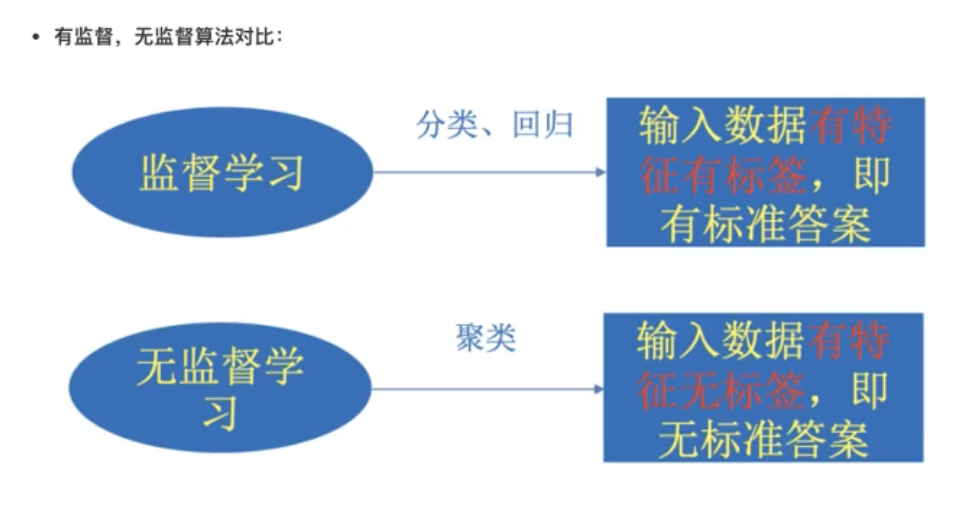
4.1. 监督学习
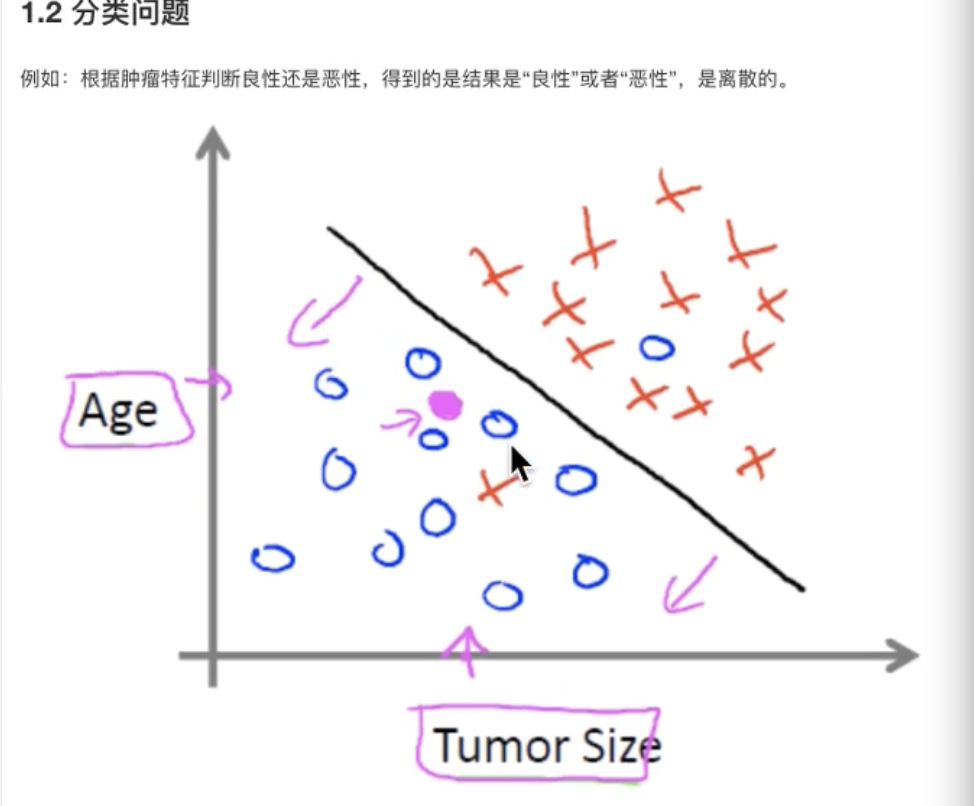
输入数据是由输入特征值和目标值所组成
函数的输出可以是一个连续的值(称为回归)
或是输出是有限个离散值(称为分类)

4.2. 无监督学习
输入数据是由输入特征值组成
输入数据没有被标记,也没有确定的结果. 样板数据类别未知,需要根据样本间的相似性对样本进行分类(聚类,clustering) 试图使类内差距最小化,类间差距最大化
4.3. 半监督学习
训练集同时包含有标记样板数据和未标记样板数据
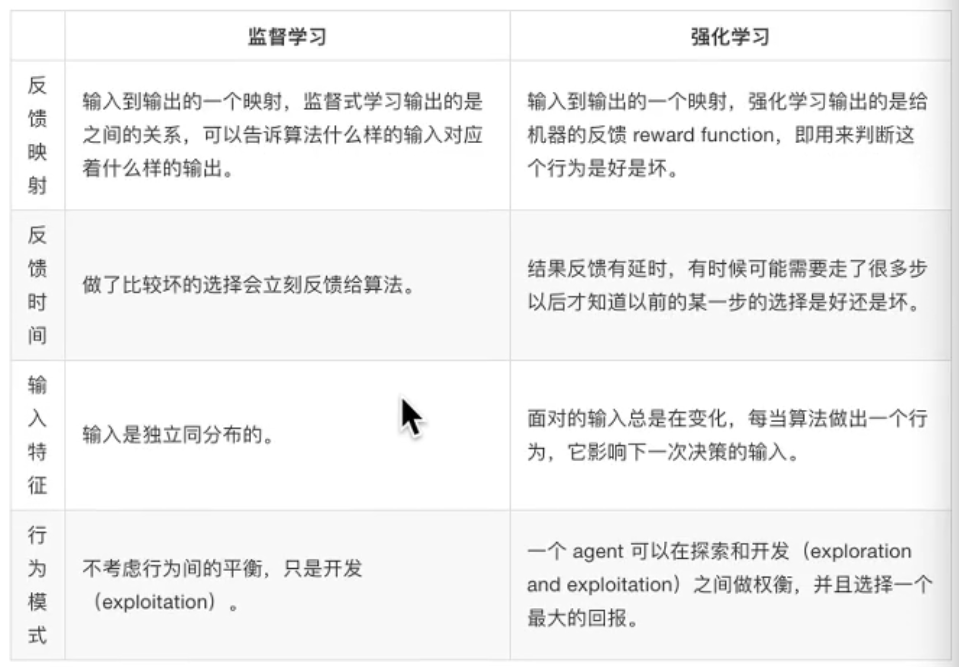
4.4. 强化学习
自动进行决策 并且可以做连续决策
动态过程,上一步数据的输出是下一步数据的输入
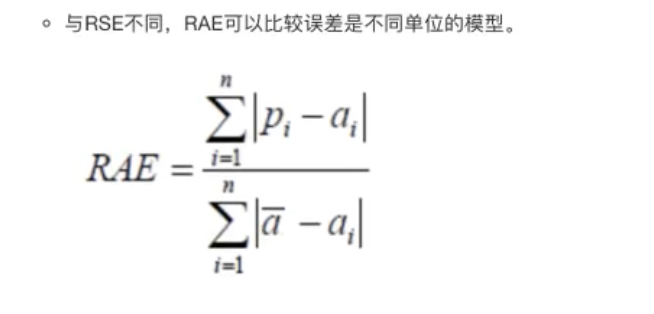
5. 分类模型评估
- 准确率
- 精确率
- 召回率
- F1-score
- AUC指标



https://archive.ics.uci.edu/ml/index.php
https://archive-beta.ics.uci.edu/
6. 安装库
requirements.txt
matplotlibnumpypandastablesjupyter
使用pip安装 在当前目录安装
#升级一下python -m pip install -U pippython -m pip install -U --force-reinstall pippip install -r requirements.txt
安装jupyter插件
pip install jupyter-contrib-nbextensions#执行jupyter contrib nbextension install --user --skip-running-check
安装自动整理
pip install autopep8
7. 快捷键
- 添加cell: a 或者 b
- 删除: x
- 修改cell的模式: m 或 y
- 执行: shift+enter
- 打开帮助文档 shift+tab

若有收获,就点个赞吧
0 人点赞
