1. 函数
2. 系统内置函数
show functions; -- 查看系统自带的函数show functions like "*date*"; -- 模糊查询函数名desc function upper; -- 显示自带的函数的用法desc function extended upper; -- 详细显示自带的函数的用法
3. 空字段赋值
NVL( value,default_value) 如果value为null 则替换为 default_value
select comm,nvl(comm, -1) from emp; -- 替换为指定值
select comm, nvl(comm,mgr) from emp; -- 如果值为列名 则替换为当前行列的值
4. CASE WHEN
类似于switch
select
dept_id,
sum(case sex when '男' then 1 else 0 end) male_count,
sum(case sex when '女' then 1 else 0 end) female_count
from
emp_sex
group by
dept_id;
-- 根据 dept_id 分组 条件判断值 再累加列个数
5. 行转列
将多个值 / 列的值 聚合为一个值

select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;
- CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
- CONCAT_WS(separator, str1, str2,…): 它是一个特殊形式的 CONCAT()。第一个参数剩余参数间的分隔符。 将array或者string 以分隔符分割 返回 string
- COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
- COLLECT_LIST(col):产生array类型字段, 包含重复元素 .
6. 列转行
EXPLODE(col):将hive一列中复杂的array拆分一列多行 map结构拆分成两列多行 k v。
split(str,regex): 将指定字符串以 指定的分割 进行拆分 返回数组
LATERAL VIEW: 虚拟表 在此基础上可以对拆分后的数据进行聚合。
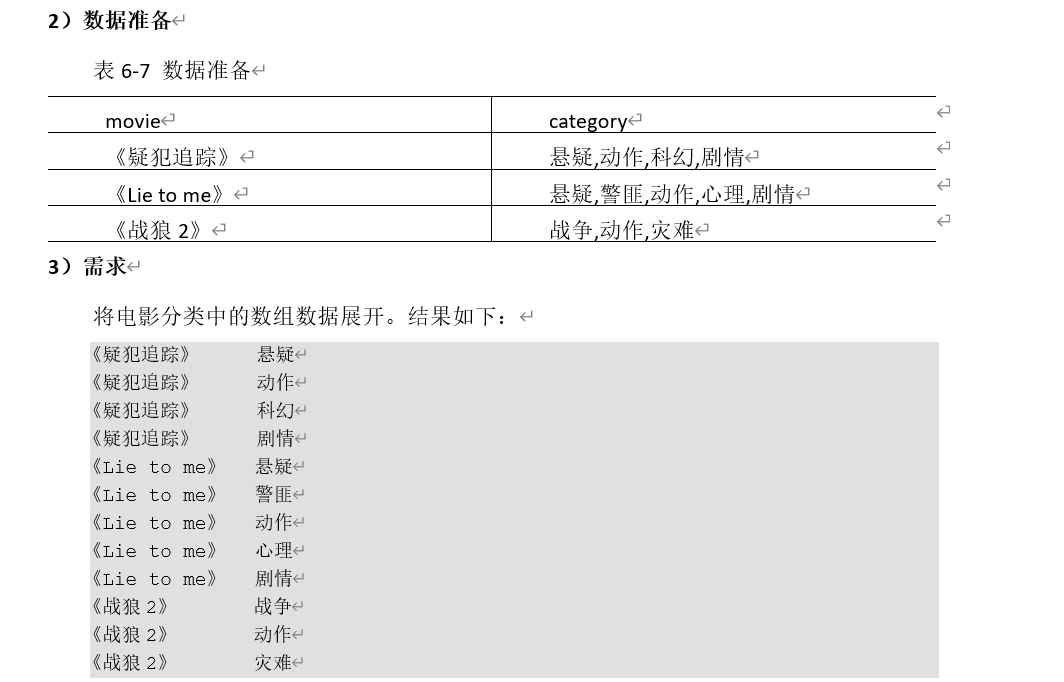
vi movie.txt
《疑犯追踪》 悬疑,动作,科幻,剧情
《Lie to me》 悬疑,警匪,动作,心理,剧情
《战狼2》 战争,动作,灾难
create table movie_info(
movie string,
category string)
row format delimited fields terminated by "\t";
load data local inpath "/opt/module/datas/movie.txt" into table movie_info;
转换
select
m.movie,
tbl.cate
from
movie_info m
lateral view
explode(split(category, ",")) tbl as cate;
现在根据电影名来进行分组聚合 请实现使用类分组 查看每个类别下的电影名
select
cate,
collect_list(movie)
from
(select
m.movie,
tbl,cate
from
movie_info m
lateral view
explode(split(category, ",")) tbl as cate;) t1
group by
cate;
#两sql语句一致
select
tbl.cate,
collect_list(m.movie)
from
movie_info m
lateral view
explode(split(category, ",")) tbl as cate
group by
cate;
7. 窗口函数(开窗函数)
数据准备:name,orderdate,cost
vim /opt/module/datas/business.txt
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
创建表
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath "/opt/module/datas/business.txt" into table business;
7.1. 窗口函数聚合
查询在2017年4月份购买过的顾客及总人数
统计所有2017-04的时间 根据用户名去重 count()默认是一列 而我们的name是多列 如果直接拼接则会报错,我们通过窗口函数 over()进行回写
select
distinct name,count(distinct name) over() -- distinct去重
from business
where
substring(orderdate,1,7) = "2017-04";
查询顾客的购买明细及月购买总额
使用窗口函数 根据时间列 分区 统计每区的sum 进行回写到对应的分区 每一个单元格中
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
上述的场景, 将每个顾客的cost按照日期进行累加
select name,orderdate,cost,
sum(cost) over() as sample1,-- 所有行相加
sum(cost) over(partition by name) as sample2,-- 按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate) as sample3,-- 按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,-- 和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, -- 当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,-- 当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 -- 当前行及后面所有行
from business;
#将上述操作整合到一个窗口函数中
select name,orderdate,cost,
sum(cost) over(partition by month(orderdate)) mc,
sum(cost) over(partition by name order by orderdate asc rows between unbounded PRECEDING and current row) lc, -- 每人购买金额的累加
sum(cost) over(partition by name,substring(orderdate,1,7)) -- 每人每月的购买金额
from business;
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
- CURRENT ROW 当前行
- n PRECEDING 往前N行数据
- n FOLLOWING 往后N行数据
- UNBOUNDED 起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
- rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量
7.2. 其他函数
LAG(col,n,default_val):往前第n行数据
col 列名
n 显示当前行的前几行
default_val 如果前几行中没有数据则以此值为默认值
查看顾客上次的购买时间
select name,orderdate,cost, lag(orderdate,1,'1970-01-01') over(partition by name order by orderdate ) as time1, lag(orderdate,2) over (partition by name order by orderdate) as time2 from business;
LEAD(col,n, default_val):往后第n行数据
- col 列名
- n 显示当前行的后几行
- default_val 如果前几行中没有数据则以此值为默认值
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
查询前20%时间的订单信息
select * from ( select name,orderdate,cost, ntile(5) over(order by orderdate) sorted -- 将结果分成5组数据 from business ) t where sorted = 1; -- 因为平均分为5组了 所有第一组为前百分之20
PERCENT_RANK() 求出当前行在结果集中位置的百分百 为double类型 每次计算后面都会有误差
select name,orderdate,cost, PERCENT_RANK() over(order by orderdate) pr -- 返回一个0.00-1.00 的值 为当前行所在结果集中占据位置的百分比 from business
8. Rank
原始数据
| name | subject | score |
|---|---|---|
| 孙悟空 | 语文 | 87 |
| 孙悟空 | 数学 | 95 |
| 孙悟空 | 英语 | 68 |
| 大海 | 语文 | 94 |
| 大海 | 数学 | 56 |
| 大海 | 英语 | 84 |
| 宋宋 | 语文 | 64 |
| 宋宋 | 数学 | 86 |
| 宋宋 | 英语 | 84 |
| 婷婷 | 语文 | 65 |
| 婷婷 | 数学 | 85 |
| 婷婷 | 英语 | 78 |
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
load data local inpath '/opt/module/datas/score.txt' into table score;
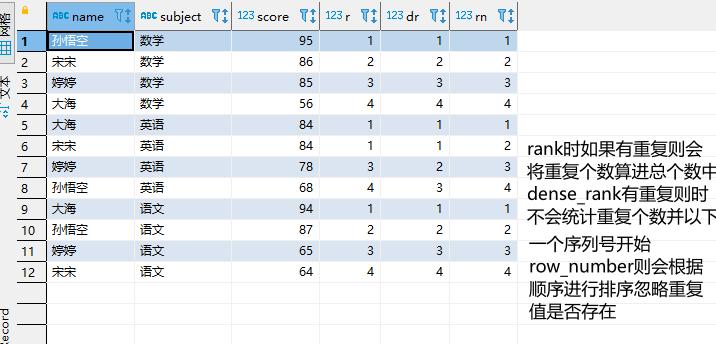
计算每门学科成绩排名
SELECT
*,
RANK() OVER(PARTITION by subject ORDER BY score desc) r,
DENSE_RANK() OVER(PARTITION by subject ORDER BY score desc) dr,
ROW_NUMBER() OVER(PARTITION by subject ORDER BY score desc) rn
FROM
score;
- RANK() 排序相同时会重复,总数不会变
- DENSE_RANK() 排序相同时会重复,总数会减少
- ROW_NUMBER() 会根据顺序计算
9. 日期函数
current_date返回当前日期
select current_date();
date_add 日期的加
-- 今天开始90天以后的日期 select date_add(current_date(), 90);
date_sub 日期的减
-- 今天开始90天以前的日期 select date_sub(current_date(), 90);
两个日期之间的日期差
-- 今天和1990年6月4日的天数差 SELECT datediff(CURRENT_DATE(), "1990-06-04"); -- 返回的为天数
判断哪个顾客连续两天光顾过
SELECT name, count(*) c from ( SELECT *, date_sub(orderdate, rn) temp -- 原始时间减去当前name区时间对应的序号 from ( SELECT *, ROW_NUMBER() over(PARTITION by name ORDER by orderdate) as rn FROM business ) t1)t2 group by name, temp HAVING c >= 2 ;

若有收获,就点个赞吧
0 人点赞
