- 1. Pandas
- 2. Series
- 3. DataFrame
- 导入np数据
- 根据行数生成行索引
- 修改行索引名称
- 生成时间序列
- date_range(start=None,end=None,periods=None,freq=”B”)
- start开始时间 end结束时间 periods时间天数 freq递进单位默认为一台 B为略过周末
- 添加列索引名称
- Column Non-Null Count Dtype
- 4. 列名修改
- 5. 单元格操作
- 替换值(多值)
- 7. 增加列和行
- 8. 删除列或行
- 9. 排序
- 10. 运算
- 11. 数据筛选
- 12. 自定义函数
- 15. set_option 选择设置
- 16. reset_option
- 17. style
- 18. 缺失值处理
- 查询每列Nan的数量
- 统计df中所有nan值
- 可以替换单列
- 更换指定列中的np.NaN为 Revenue (Millions)的中位值 inplace为是否替换原来数据 默认为false不替换原来数据
- 将评分列的缺失值,替换为上一个电影的评分
- 上下均值填充
- 匹配填充
- bfill:向前填充 ffill:向后填充 默认 axis=0(列方向) vs axis=1(行方向)
- 19. 数据离散化
- 21. 交叉表与透视表
- 22. 分组与聚合
- 自定义函数聚合
- 23. 时间处理
- 24. 去重
- 25. 热力图
- 26. 热力地图
- 27. 直方图
1. Pandas
Pandas 以Numpy为基础 和 matplotlib 开源的数据挖掘库 用于数据探索
2. Series
Series是一个类似于一维数组的数据结构,它能够保存任何类型的数据,比如整数、字符串、浮点数等,主要由一组数据和与之相关的索引两
部分构成

2.1. 创建
pd.Series(data=None, index=None, dtype=None)
- data:传入的数据,可以是ndarray、list等
- index:索引,必须是唯一的,且与数据的长度相等。如果没有传入索引参数,则默认会自动创建一个从0-N的整数索引。
- dtype:数据的类型
pd.Series(np.arange(10))
指定索引
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
- 通过字典创建
color_count = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
2.2. 属性
- color_count.index 返回行索引
- color_count.values 返回一个np数组 存放为列值
- color_count.tolist() 返回一个np数组 存放为列值
- color_count[n] 通过索引来获取值
3. DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象,既有行索引,又有列索引
- 行索引,表明不同行,横向索引,叫index,0轴,axis=0
- 列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
2.1. 创建
创建DataFrame 需要传递一个ndarray对象
- ```python
stock_change = np.random.normal(0, 1, (10, 5))
导入np数据
df = pd.DataFrame(stock_change)根据行数生成行索引
stock_code = [“股票{}”.format(i+1) for i in range(stock_rise.shape[0])]修改行索引名称
pd.DataFrame(stock_change,index=stock_code)生成时间序列
date_range(start=None,end=None,periods=None,freq=”B”)
start开始时间 end结束时间 periods时间天数 freq递进单位默认为一台 B为略过周末
date = pd.date_range(start=”20211020”,periods=stock_rise.shape[1],freq=”B”)
- ```python
stock_change = np.random.normal(0, 1, (10, 5))
添加列索引名称
stock_c = pd.DataFrame(stock_change,index=stock_code,columns=date)
-增加行、列索引-```python# 构造行索引序列subjects = ["语文", "数学", "英语", "政治", "体育"]# 构造列索引序列stu = ['同学' + str(i) for i in range(score_df.shape[0])]# 添加行索引data = pd.DataFrame(score, columns=subjects, index=stu)
3.2. 属性和查看
df.shape 查看几行几列
#查看几行几列stock_rise.shape#查看行stock_rise.shape[0]#查看列stock_rise.shape[1]
df.index 查询行索引列表
df.columns 查看当前df的列名列表
df.values 查询所有数据 返回为一个np数组
df.sample(n) 随机查看n条数据 默认为1条
df.sample(5)
df.head() 查看前5行 可传递指定行数
df.head(12)
df.tail() 后5行 可传递指定行数
df.info() 查看数据基本信息
- ```python df.info()
Column Non-Null Count Dtype
0 片名 262 non-null object
1 上映年份 262 non-null int64
2 评分 257 non-null float64
3 评价人数 259 non-null float64
4 导演 262 non-null object
5 编剧 262 non-null object
6 主演 262 non-null object
7 类型 262 non-null object
8 国家/地区 256 non-null object
9 语言 256 non-null object
10 时长(分钟) 256 non-null float64
dtypes: float64(3), int64(1), object(7)
memory usage: 22.6+ KB
-df.describe() 查看数据统计信息|整体-```pythondf.describe(include='all') #默认不包含 unique去重后数据量 top出现频率最高的 freq频率计数df.describe().round(2).T #保留2为小数 并进行行列互换 方便查看

df.dtypes 查看各列数据类型
df.corr() 相关系数矩阵,也就是每两列之间的相关性系数
df支持切片
df[0:]df[::2]
- df.T 行列互换
4. 列名修改
- df.columns=[“1”,”2”] 将全部列设置为指定列表
df.rename(columns={“a”:”A”,”b”:”B”},inplace=True) 替换指定列
- columns:列名 如传递一个数组则需要与csv文件中列名数保持一致 如果传递为map则将指定列名替换为值 {“positionId”:”ID”,”positionName”:”岗位名称”,”salary”:”薪资”}
- inplace: 是否替换原dataframe 默认为false
df.rename(columns={"positionId":"ID","positionName":"岗位名称","salary":"薪资"},inplace=True)
5. 单元格操作
5.1. 读取
df[“列名”][“行索引”] df中默认是先列后行 不支持切片 如果单列则支持索引
data['open']['2018-02-27'] #先列后行 不支持切片data['open'][1:2] #单列 支持切片
df.loc[“2018-02-27”:”2018-02-23”,”high”] 通过loc 索引名称 实现先行后列的查询 支持切片
df.iloc[行下标,列下标] 通过索引下标值 支持切片
stock_data.iloc[3,5]stock_data.iloc[:3,:5]
df.at[“行索引”,”列名”] at先行后列的查询
多列名读取
df[["positionId","companyId","industryField"]]
5.2. 赋值
指定列赋值
data['close'] = 1data.close = 1df["金牌大于30"] = np.where(df["金牌数"]>30,"是","否") #支持比较
指定单元格赋值
stock_data["open"]["2018-02-27"]=1df.at[5,"国家奥委会"] = "俄奥委会"df.iloc[4,0] = "俄奥委会"
5.3. 替换值
df.replace(“指定值”,”替换值”,inplace=True)
- ```python df.replace(0,”无”,inplace=True) #整个df替换 df[“金牌数”].replace(0,”无”,inplace=True)
替换值(多值)
df.replace(“无”,np.nan,inplace=True) df.replace(0,”None”,inplace=True)
<a name="aa47e26a"></a># 6. 索引重置和设置-修改索引 传递一个相同个数的列表 可以获取下标获取值但**不能单个修改**-```pythonstu = ["学生_" + str(i) for i in range(score_df.shape[0])]# 必须整体全部修改data.index = stu#索引可以通过下标获取 但无法直接进行修改#stu.index[3]
reset_index(drop=False) 重置索引 drop默认为Flase不删除原来索引
# 重置索引,drop=False 默认保留旧索引data.reset_index()# 重置索引,drop=Truedata.reset_index(drop=True)
set_index(keys,drop = True)以某列值设置为新的索引 keys列名或列索引 drop默认为true 删除原来的索引列
df.set_index("year") #以某列设置为新的索引df.set_index(keys=["year","month"]) #设置多个索引
df.rename_axis(keys,inplace=True) 更改当前索引列名
df.rename_axis("金牌排名",inplace=True)
df.set_index(“列名”,inplace=True) 将指定列设定为索引
df.set_index("排名",inplace=True)df.set_index(["排名","总分"],inplace=True) #支持多列行索引
df.reindex([“索引名1”,”索引名2”,…]) 将索引重置为指定索引列表
pd.concat([df1, df4], axis=1).reindex(df1.index)
7. 增加列和行
- 增加列 直接df引用未定的列名 自动创建
df["比赛地点"] = "东京"
在最后一行增加行 使用append
df1 = pd.DataFrame([[i for i in range(len(df.columns))]],columns=df.columns)df_new = df.append(df1)
在指定行中 增加行 使用concat
df1 = df.iloc[:1, :]df2 = df.iloc[1:, :]df3 = pd.DataFrame([[i for i in range(len(df.columns))]], columns=df.columns)df_new = pd.concat([df1, df3, df2], ignore_index=True)
8. 删除列或行
df.drop(columns,axis=0) 删除列或行 传递指定行索引名或者列名
df.drop(1) #删除索引名为1的行df.drop(df[df.金牌数<20].index) #条件删除df.drop(['ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20'],axis=1 ) #删除多个列df.drop(columns=["比赛地点"],inplace=True) #删除指定列df.drop(df.columns[[7,8,9,10]],axis=1,inplace=True) #按列号删除
9. 排序
3. DataFrame
df.sort_values(by=, ascending=) 按列的值排序 by: 列名 ascending: 默认为True升序 False降序
data.sort_values(by="open", ascending=True) #升序data.sort_values(by=['open', 'high'], ascending=False) #多个列降序
- df.sort_index() 根据索引进行排序 默认升序
2. Series
series.sort_values(ascending=True) 对series中的值进行排序 默认升序
data['p_change'].sort_values(ascending=True)
series.sort_index() 索引排序
data['p_change'].sort_index()
10. 运算
data.add 相加 data[‘open’].add(1)
逻辑运算
data[data["open"] > 23]data[(data["open"] > 23) & (data["open"] < 24)] # 支持逻辑运算符
data.query(expr) 逻辑运算函数
data.query("open<24 & open>23") # 只需要根据列名 + 条件就可以判断
data.isin(values) 判断值是否在指定范围
data[data["open"].isin([23.53, 23.85])]
data.agg() 进行聚合操作 支持自定义min max mead sum等操作
df.agg({"总分": ["min", "max", "median", "mean"],"高端人才得分": ["min", "max", "median", "mean"],"办学层次得分":["min", "max", "median", "mean"]})
data.max(0) 最大值 默认为列计算 axis=0 传递1为行计算
data.min() 最小值
data.std() 标准差
data.var() 方差
data.median() 中位数
data.quantile() 分位数 默认返回50%的分位数 即中位数
data.idxmax(axis=0) 最大值的索引名
data.idxmin(axis=0) 最小值的索引名
data.cumsum() 连续求和 累加到最后一个单元格
data.cummax() 计算最大值
data.cummin() 计算最小值
data.cumprod() 累乘
data.mode() 众数
data.nsmallest(n) 返回当前列最小的n个数
data.nlargest(n) 返回当前列最大的n个数
11. 数据筛选
11.1. 筛选列
df.iloc[:,[0,1,2,3]] #通过列号筛选df[['金牌数','银牌数','铜牌数']] #通过列名df.iloc[:,[i%2==0 for i in range(len(df.columns))]] #条件筛选df.loc[:, df.columns.str.endswith('数')] #提取全部列名中包含 数 的列df.iloc[9:20,-3:] #组合(行号+列名) 提取倒数后三列的10-20行
11.2. 筛选行
df.loc[9:9] # 通过行号df.iloc[9:,:] #切片df.loc[:50:3] # 步进df[df['金牌数'] > 30] # 判断df[df["金牌数"] == 10]df[df["金牌数"] != 10]df[[i%2 != 0 for i in range(len(df.index))]] # 条件df.loc[df['国家奥委会'].isin(['中国','美国','英国','日本','巴西'])] # 判断是否在列表中的值df.loc[((df['金牌数'] < 30) & df['国家奥委会'].isin(['中国', '美国', '英国', '日本', '巴西']))] #多条件 每个条件要用括号包起来df[df.国家奥委会.str.contains('国')] # 提取 国家奥委会 列中,所有包含 国的行
11.3. 组合
df.iloc[0:1,[1]] # 第 0 行第 2 列df.iloc[0:2,0:2] #筛选多行多列df.iloc[3,3] #行号+列号df.loc[4,"金牌数"] # 行号+列名df.loc[df['国家奥委会'] == '中国'].loc[1].at['金牌数'] # 条件df.query("金牌数 + 银牌数 > 15") # query 类sql筛选#query(引用变量)me = df["金牌数"].mean()df.query(f"金牌数 > {me}") #需要要{}引用变量 类sql语句
12. 自定义函数
df.apply(自定义函数名,axis=0) df会传递一个Series对象 通过自定义函数return一个结果 axis=0:默认是列,axis=1为行进行运算
- ```python def abc(ses): c_null = pd.isnull(ses) is_null = column[c_null] return len(is_null)
df.apply(abc) #会返回每一列null的个数
<a name="b68fa2d9"></a># 13. Pandas画图- df.plot (kind='line') 默认为line折线图- line 折线图- bar 柱状图- barh 横向直方图- hist 直方图- pie 饼图- scatter 散点图<a name="2eb0966b"></a># 14. 读取和保存-pd.read_csv(filepath_or_buffer, sep =',', usecols=[1,3,5],skiprows=[1,3,5],index_col=["列名"],names=[], keep_default_na=False,na_values=['[]'],na_filter= True,dtype={'positionId': str,'companyId':str})-filepath_or_buffer:文件路径-```pythonpd.read_csv("某招聘网站数据.csv")
sep :分隔符,默认用”,”隔开
pd.read_csv("某招聘网站数据.csv",sep=",")
usecols:指定读取的列名,列表形式 [1,3,5] 只读取2 4 6列 或指定列名 [‘positionId’,’positionName’,’salary’]
pd.read_csv("某招聘网站数据.csv",usecols = ['positionId','positionName','salary'])pd.read_csv("某招聘网站数据.csv",usecols = [1,3,5])
skiprows: 跳过指定行数 [1,3,5] 跳过 2 4 6 行
pd.read_csv("某招聘网站数据.csv",skiprows = [i for i in range(1,21)])
index_col: 将指定列设置为行索引
pd.read_csv("某招聘网站数据.csv",index_col="positionId")
names: 指定新的列名 [‘ID’,’岗位名称’,’薪资’] 不支持map
pd.read_csv('某招聘网站数据.csv', usecols=[0,1,17],header = 0,names=['ID','岗位名称','薪资'])
keep_default_na: 缺失值标记为NaN 默认为True
pd.read_csv('某招聘网站数据.csv', keep_default_na=False)
na_values: 将缺失值标记为指定字符串 如[‘[]’]
pd.read_csv('某招聘网站数据.csv',na_values=['[]'])
na_filter: 缺失值是否处理 默认为True 处理
pd.read_csv("某招聘网站数据.csv",na_filter=False)
dtype: 读取时指定列类型 传递map
pd.read_csv("某招聘网站数据.csv", dtype={'positionId': str,'companyId':str})
parse_dates: 将指定列转为datatime类型
pd.read_csv("某招聘网站数据.csv",parse_dates=['createTime'])
chunksize: 分块读取 返回一个可迭代对象,每次读取 n 行
data = pd.read_csv("某招聘网站数据.csv", chunksize= 10)for i in data:print(i)
df.to_csv(path_or_buf=None, sep=’, ’, columns=None, header=True, index=True, mode=’w’, encoding=None)
path_or_buf :文件路径
sep :分隔符,默认用”,”隔开
columns :选择需要的列索引
data.to_csv("234.csv",columns=["positionName","salary"])
header :boolean or list of string, default True,是否写进列索引值
index:是否写进行索引
data.to_csv("234.csv",index=False) #不写入索引
mode:’w’:重写, ‘a’ 追加
na_rep: 缺失值标记为指定字符
data.to_csv("234.csv",index=False,na_rep="数据缺失")
pd.read_hdf(path_or_buf,key =None)
- path_or_buffer:文件路径
- key:读取的键
- 需要先安装tables库 pip install tables
df.to_hdf(path_or_buf, key)
pd.read_json(“./data//test.json”,orient=”records”,lines=True) orient指定列 lines是否一行一个数据默认为false 一行一大串数据 推荐设置为true
df.to_json(“./data/test.json”,orient=”close”)
pd.read_clipboard() 从剪贴板读取数据
pd.read_sql(sql语句,conn连接对象)
from sqlite3 import connectconn = connect(':memory:')pd.read_sql("SELECT int_column, date_column FROM test_data",conn)
15. set_option 选择设置
option 选择设置为全局配置
display.max_columns 显示全部列
pd.set_option('display.max_columns', None) #显示全部列
display.max_columns 显示指定列
pd.set_option('display.max_columns', 10)
display.max_rows 显示指定行
pd.set_option('display.max_rows', 7)
display.max_colwidth 每列最多显示10个字符,多余的会变成… 设置指定长度字符
pd.set_option ('display.max_colwidth',10)
precision 修改默认显示精度为小数点后5位
pd.set_option('precision', 5)
mode.chained_assignment 取消pandas相关warning提示
pd.set_option("mode.chained_assignment", None)# 全局取消warning# import warnings# warnings.filterwarnings('ignore')
chop_threshold 数值显示条件 如果数值小于 20 则显示为0
pd.set_option('chop_threshold', 20)
display.html.use_mathjax 让dataframe中内容支持 Latex 显示(需要使用$$包住)
pd.set_option("display.html.use_mathjax",True)
plotting.backend 修改绘图引擎
#修改pandas默认绘图引擎为plotly(需要提前安装好plotly)pd.set_option("plotting.backend","plotly")
16. reset_option
根据key还原指定选择设置 去除display.
pd.reset_option("max_rows")pd.reset_option("max_columns")
还原全部显示设置 display
pd.reset_option("^display")
还原全部 option 设置
pd.reset_option("all")
17. style
基于 style 个性化设置同样不会修改数据,所有 data.style.xxxx 输出的数据均是一次性的(可以复用、导出),因此你应该在合适的时间选择使用该方法。
style.hide_index() 隐藏索引列
data.style.hide_index()
style.set_precision(n) 调整小数的精度
# 将带有小数点的列精度调整为小数点后2位data.style.set_precision(2)
style.set_na_rep(“指定字符”) 标记缺失值为指定字符
(data.style.set_na_rep("数据缺失"))
style.highlight_null(null_color=”red”) 高亮缺失值
null_color: 为高亮颜色 默认为红色
(data.style.set_na_rep("数据缺失").highlight_null(null_color='skyblue'))
style.highlight_max 高亮数值列最大值
(data.style.highlight_max)
style.highlight_min 高亮数值列最小值
(data.style.highlight_min)
同时高亮最大最小值
(data.style.highlight_max(color='#F77802').highlight_min(color='#26BE49'))
style.highlight_between 设置指定列 指定范围内高亮
(data.style.highlight_between(left=3000, right=10000, subset=['salary']))
style.background_gradient 渐变显示数值列
- ```python import seaborn as sns
cm = sns.light_palette(“green”, as_cmap=True)
(data .style .background_gradient(cmap=cm))
-style.set_properties 修改指定properties-```python# 修改字体颜色# 将 salary 列修改为红色字体(data.style.set_properties(subset=['salary'], **{'color': 'red'}))#修改背景颜色、对齐方式、字体大小#1.居中 2.背景色修改为 #F8F8FF 3.字体:13px(data.style.set_properties(**{'background-color': '#F8F8FF','text-align':'center', 'font-size': '13px'}))#链式多个设置进行结合(data.style.set_properties(**{'background-color': '#F8F8FF','text-align':'center', 'font-size': '13px'}).set_properties(subset=['salary'], **{'color': 'red'}))
带样式导出
(data.style.set_properties(**{'background-color': '#F8F8FF','text-align':'center', 'font-size': '13px'}).set_properties(subset=['salary'], **{'color': 'red'})).to_excel('带有样式导出.xlsx')
style.bar 将指定列以横向条形图形式进行可视化
(data.style.bar(subset=['salary'],color='skyblue'))
style.applymap 带条件样式 / 自定义样式
```python def my_style(val):
color = ‘red’ if val > 30000 else ‘black’ return ‘color: %s’ % color
data.style.applymap(my_style, subset=”salary”)
-style.format 格式化值-```python#将 createTime 列格式化输出为 xx年xx月xx日data.style.format({"createTime": lambda t: t.strftime("%Y年%m月%d日")})#1.在 salary 列后增加"元" 2.对 matchScore 列保留两位小数并增加"分"(data.style.format("{0:,.2f}分", subset="matchScore").format("{""}元", subset="salary"))
18.1. 判断缺失值
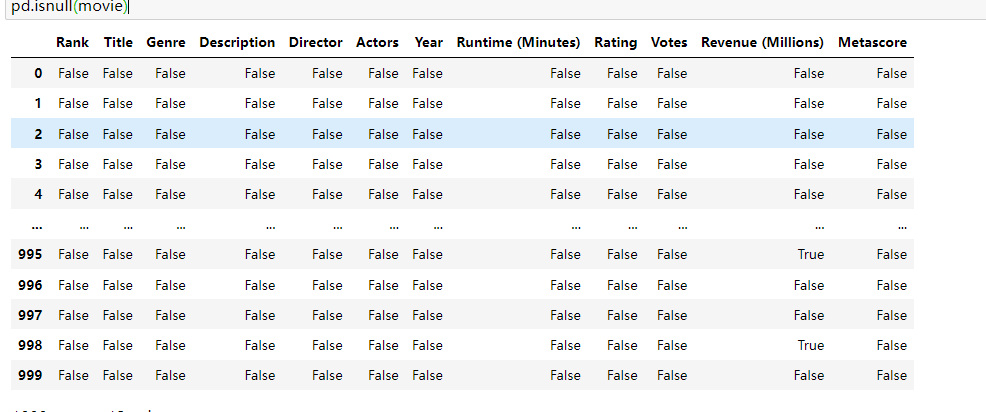
片名 0 上映年份 0 评分 5 评价人数 3 导演 0 编剧 0 主演 0 类型 0 国家/地区 6 语言 6 时长(分钟) 6 dtype: int64
统计df中所有nan值
df.isna().sum().sum()
-pd.notnull(df) 判断df 是否有Nan 如有则返回False-np.all(pd.notnull(movie)) 里面如果有一个缺失值 则为false 则返回false-np.any(pd.isnull(movie)) 通过np.any 只有里面有一个为null就返回true-高亮缺失值-```python(df[df.isnull().T.any() == True].style.highlight_null(null_color='skyblue'))
18.2. 替换和替换缺失值或标记值
df.dropna() 删除所有np.Nan 直接删除一行数据
df.dropna(axis=1) #按行删除df.dropna(axis=0,subset=["列名1","列名2"]) #删除指定列中的缺失值
df.fillna(value, inplace=False) 替换所有的缺失值为指定值
将评分列的缺失值,替换为上一个电影的评分
df[‘评分’] = df[‘评分’].fillna(axis=0,method=’ffill’)
上下均值填充
df[‘评价人数’] = df[‘评价人数’].fillna(df[‘评价人数’].interpolate())
匹配填充
df[‘语言’]=df.groupby(‘国家/地区’).语言.bfill()
bfill:向前填充 ffill:向后填充 默认 axis=0(列方向) vs axis=1(行方向)
-df.replace(to_replace=, value=)-```python#先把被标记的缺失值 也是? 替换成np.nanwis = wis.replace(to_replace='?',value=np.nan)#再进行缺失值处理wis = wis.dropna()wis.head(10)
18.3. 缺失值转换
不将缺失值标记为 NAN
data = pd.read_csv('某招聘网站数据.csv', keep_default_na=False)data
NaN会变成空字符
18.4. 缺失值标记
将指定的字符标记为NaN缺失值
data = pd.read_csv('某招聘网站数据.csv',na_values=['[]'])data
18.5. 缺失值忽略
忽略缺失值 变为空字符串
data = pd.read_csv("某招聘网站数据.csv",na_filter=False)data
19. 数据离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
pd.qcut(data, q) 对数据进行分组将数据分组,一般会与value_counts搭配使用,统计每组的个数 即将数据划分为指定个数的区间
# 自行分组qcut = pd.qcut(p_change, 10) #将此数据集 离散化平均分10个组# 计算分到每个组数据个数qcut.value_counts() #查看每个组共有多少个数据集
series.value_counts():统计分组次数
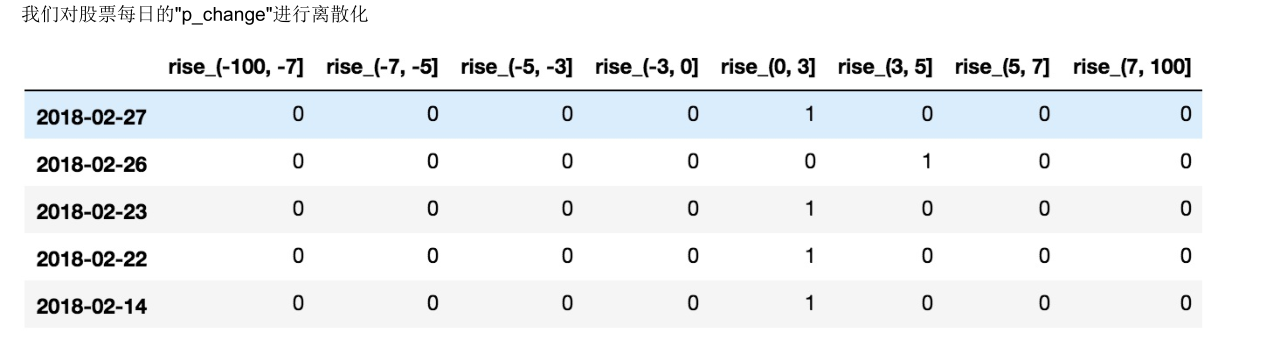
pd.cut(data, bins) 自定义区间分组
- ```python bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100] # 通过自定义区间范围来分组 cut_r = pd.cut(data_p, bins=bins) cut_r.value_counts()
(0, 3] 215 (-3, 0] 188 (3, 5] 57 (-5, -3] 51 (5, 7] 35 (7, 100] 35 (-100, -7] 34 (-7, -5] 28 Name: p_change, dtype: int64
<a name="92394646"></a>## 19.1. one-hot编码把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为独热编码。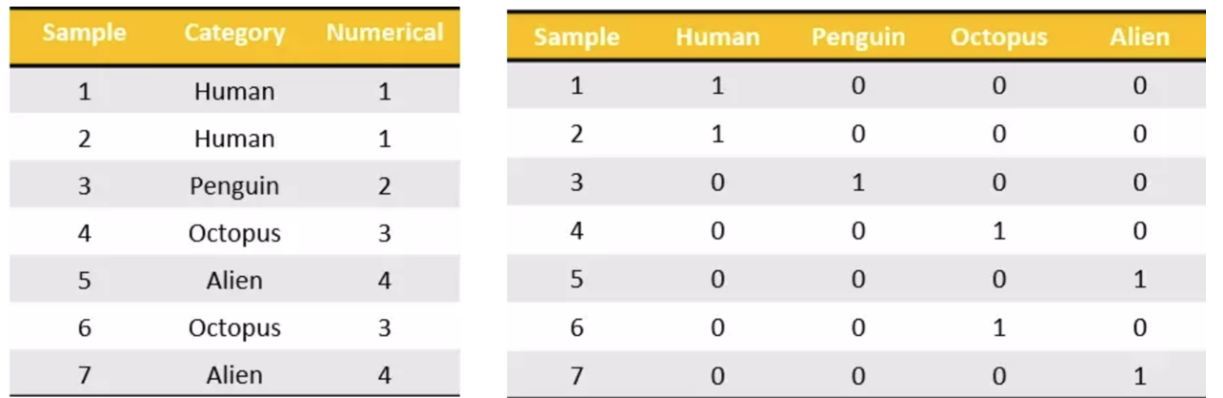- pd.get_dummies(data,prefix="区间前缀测试") 将据转为 one-hot编码 prefix为区间前缀方便阅读和理解<a name="4a8fc5cc"></a># 20. 数据合并<a name="998ee1d7"></a>## 20.1. concat-pd.concat([data1, data2], axis=1) 将两个df进行合并-按照行或列进行合并,axis=0为列索引,axis=1为行索引-```python#默认为行连接 通过指定axis=1为按列连接pd.concat([data,data_dummies],axis=1) #横向拼接pd.concat([df1,df2,df3]) #重置拼接
ignore_index: 重置索引 默认为flase
pd.concat([df1,df4],ignore_index=True)
join: 什么方式加入
inner:默认 内连接
pd.concat([df1,df4],axis=1,join='inner')
keys: 每个表拆分 来区分不同的表数据来源
- ```python pd.concat([df1, df2, df3], keys=[‘x’, ‘y’, ‘z’])
A B C D x 0 A0 B0 C0 D0 1 A1 B1 C1 D1 2 A2 B2 C2 D2 3 A3 B3 C3 D3 y 4 A4 B4 C4 D4 5 A5 B5 C5 D5 6 A6 B6 C6 D6 7 A7 B7 C7 D7 z 8 A8 B8 C8 D8 9 A9 B9 C9 D9 10 A10 B10 C10 D10 11 A11 B11 C11 D11
<a name="624e73bc"></a>## 20.2. merge-pd.merge(left, right, how='inner', on=None)-可以指定按照两组数据的共同键值对合并或者左右各自-left : DataFrame-right : 另一个DataFrame-on : 指定的共同键-```pythonpd.merge(left, right, on='key') #以名称为key的列为共同键连接pd.merge(left, right, on=['key1', 'key2']) # 多键
how:按照什么方式连接
left:左连接
pd.merge(left, right,how="left")
-
right:右连接
-
outer:全外连接
-
inner: 内连接
suffixes:将连接表除on键 以外的列 为前缀再区分数据
- ```python pd.merge(left, right, on=’k’, suffixes=[‘_l’, ‘_r’])
k v_l v_r 0 K0 1 4 1 K0 1 5
-```pythonpd.merge(left,right,on=["key1","key2"]) #默认为内连接pd.merge(left,right,on=["key1","key2"],how="inner") #通过how属性指定连接类型 默认inner为内连接pd.merge(left,right,on=["key1","key2"],how="outer") #outer 满外连接 没有的值会以NaN存在 需要注意pd.merge(left,right,on=["key1","key2"],how="left") # 左连接pd.merge(left,right,on=["key1","key2"],how="right") # 右连接
20.3. join 组合
df1.join(right,how=”outer”) 将两表进行组合 默认为内连接
left.join(right)
how: 连接方式
left.join(right,how="outer")
-
outer
-
left
-
right
-
inner
on: 共同键 按列名
left.join(right, on='v1')left.join(right, on=["key1","key2"]) #多个列
21. 交叉表与透视表
pd.crosstab(value1, value2) pd.crosstab(value1, value2) 交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
df.pivot_table([], ,values = [],index=[],aggfunc=”mean”) 透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数
```python data.pivot_table([“p_n”],index=”week”)
p_n week
0 0.496000 1 0.580153 2 0.537879 3 0.507812 4 0.535433
pd.pivot_table(df,values = [‘销售额’,’利润’,’数量’],index = ‘类别’,aggfunc = sum) #多列(指标) pd.pivot_table(df,values = [‘销售额’],index = [‘省/自治区’,’类别’],aggfunc = sum) # 多索引
-values :指标-```pythonpd.pivot_table(df,values = ['销售额'],index = '省/自治区')
index:索引名
columns: 列名
pd.pivot_table(df,values = ['销售额'],index = ['省/自治区'], columns='类别',aggfunc = sum) #多层
aggfunc: 透视图使用的方法 默认为mean平均值
pd.pivot_table(df,values = ['销售额'],index = '省/自治区',aggfunc = sum)pd.pivot_table(df,values = ['销售额'],index = '省/自治区',aggfunc = ['mean',sum]) #多个聚合方法
margins: string,默认为‘ALL’,当参数margins为True时,ALL行和列的名字
pd.pivot_table(df,values = ['销售额','数量'],index = ['省/自治区','类别'],aggfunc = ['mean',sum],margins=True)
df.melt() 逆透视
table = pd.pivot_table(df,values = ['销售额','利润','数量'],index = '类别',aggfunc = sum)table.melt(id_vars=['数量'],var_name='分类',value_name='金额')
22. 分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
df.groupby(key, as_index=False)
key:分组的列数据,可以多个
```python col.groupby([“color”])[“price1”].mean() #按照列索引color分组 再根据分组后的price1列求中位值 col[“price1”].groupby(col[“color”]).mean() #取出price1的值 再按color分组 再求中位值 col.groupby([“color”],as_index=False)[“price1”].mean() #为分组聚合后的数据给行索引 df[[‘district’,’salary’]].groupby(by=’district’).mean().sort_values(‘salary’,ascending=False).head(1) #分组并排序
pd.DataFrame(df.groupby(“district”)[‘companySize’].value_counts()).rename_axis([“行政区”, “公司规模”]) #分组后 修改索引名
-groupby().groups 以字典形式查看各分组内容-```pythondf.groupby(["district","salary"]).groups{('上城区', 22500): [81], ('上城区', 30000): [97], ('下沙', 30000): [31], ('余杭区', 7500): [84], ('余杭区', 20000): [52, 103], ('余杭区', 22500): [23, 51], ('余杭区', 25000): [62], ('余杭区', 27500): [24, 49], ('余杭区', 29000): [93], ('余杭区', 30000): [4, 10, 13, 18, 59, 61, 65, 68, 74, 76, 86, 92, 94], ('余杭区', 35000): [101], ('余杭区', 37500): [0, 32, 38, 39, 41], ('余杭区', 40000): [60, 87], ('余杭区', 45000): [25], ('余杭区', 50000): [5, 64, 90], ('余杭区', 60000): [8, 82], ('拱墅区', 24000): [72], ('拱墅区', 30000): [54, 89, 96], ('江干区', 3500): [2], ('江干区', 22500): [45], ('江干区', 30000): [73], ('江干区', 45000): [3], ('滨江区', 7500): [83], ('滨江区', 15000): [1], ('滨江区', 20000): [21, 40], ('滨江区', 22500): [37], ('滨江区', 30000): [22, 53, 55, 58, 67, 80, 102], ('滨江区', 32500): [26], ('滨江区', 37500): [17, 28, 57, 77], ('滨江区', 42500): [91], ('滨江区', 45000): [43, 47], ('滨江区', 50000): [44], ('萧山区', 25000): [100], ('萧山区', 30000): [6], ('萧山区', 45000): [66, 69], ('西湖区', 6500): [71], ('西湖区', 20000): [12], ('西湖区', 21500): [104], ('西湖区', 22500): [48, 70], ('西湖区', 24000): [42], ('西湖区', 25000): [56], ('西湖区', 26500): [78], ('西湖区', 27000): [75], ('西湖区', 27500): [15, 20, 50, 63], ('西湖区', 30000): [11, 27, 33, 34, 85, 88, 98], ('西湖区', 35000): [7], ('西湖区', 36500): [99], ('西湖区', 37500): [14, 16, 19, 30, 36, 79, 95], ('西湖区', 40000): [9, 35], ('西湖区', 45000): [29, 46]}
groupby().get_group 查看分组后指定值数据
df.groupby(["district", "salary"]).get_group(("西湖区", 30000))
groupby().transform(“聚合函数名”) 分组转换
df['该区平均工资'] = df[['district','salary']].groupby(by='district').transform('mean')df
groupby().filter() 分组过滤
df.groupby('district').filter(lambda x: x['salary'].mean() < 30000)
groupby().agg([“聚合函数名1”,”聚合函数名2”]) 将分组的数据 聚合统计
- ```python df.groupby(‘district’)[‘salary’].agg([min, max, np.mean])
df.groupby(‘positionName’).agg({‘salary’: np.median, ‘score’: np.mean}) #指定以指定聚合函数来获取值
df.groupby(‘district’).agg( {‘salary’: [np.mean, np.median, np.std], ‘score’: np.mean}) #多层聚合
自定义函数聚合
def myfunc(x):
return x.max()-x.mean()
df.groupby(‘district’).agg(最低工资=(‘salary’, ‘min’), 最高工资=( ‘salary’, ‘max’), 平均工资=(‘salary’, ‘mean’), 最大值与均值差值=(‘salary’, myfunc)).rename_axis([“行政区”])
-agg.rename_axis("列名") 修改列名-```pythondf.groupby('district').agg(最低工资=('salary', 'min'), 最高工资=('salary', 'max'), 平均工资=('salary', 'mean')).rename_axis(["行政区"])
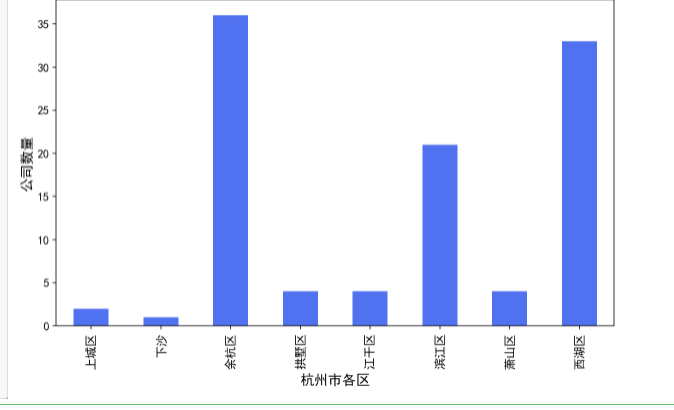
分组可视化
import matplotlib.pyplot as plt%config InlineBackend.figure_format = 'retina'plt.rcParams['font.sans-serif'] = ['Songti SC']df.groupby("district")['positionName'].count().plot(kind='bar', figsize=(10, 6), color='#5172F0', fontsize=12)plt.rcParams['font.sans-serif'] = 'SimHei'plt.rcParams['axes.unicode_minus'] = Falseplt.ylabel("公司数量", fontsize=14)plt.xlabel("杭州市各区", fontsize=14)plt.show()
23. 时间处理
从文件中读取的时间默认我object类型 需要转为pd时间才能进行运算
- pd.to_datetime(data) 将指定列转为时间序列 返回datatime对象
- datetime.weekday 星期几
- datetime.week 月中第几个星期
- datetime.day 几号
- datetime.year 年
- datetime.total_seconds() 将时间转为秒
t1 = datetime.datetime.strptime("2021-11-03 10:30:00", "%Y-%m-%d %H:%M:%S")t2 = datetime.datetime.strptime("2021-11-03 12:30:00", "%Y-%m-%d %H:%M:%S")time = (t2-t1).total_seconds() #获取时间差
24. 去重
df.drop_duplicates(subset=[‘列名’], keep=’first’) 去重 只保留第一个
keep: first为保留重复值中第一个 last为保留最后一个
df.drop_duplicates(keep="last")
- subset: 列名
df[“列名”].uniue()
查找行是否存在重复值
- ```py df[df.duplicated()]
2 True 3 True 4 True 5 True 6 True … 257 True 258 True 259 True 260 True 261 True Length: 260, dtype: bool
-查询指定列中的重复值-```pythondf[df.duplicated(['片名'])]
25. 热力图
df.corr().style.background_gradient(cmap='coolwarm').set_precision(2)## 25.1. 方法二 ####借助 `matplotlib` 和 `seaborn`# 其中中文设置可以参考我的这篇文章 https://mp.weixin.qq.com/s/WKOGvQP-6QUAP00ZXjhwegimport seaborn as snsimport matplotlib.pyplot as pltplt.figure(figsize = (9,6),dpi=100)sns.set(font='Songti SC')sns.heatmap(df.corr().round(2),annot=True,cmap='RdBu')plt.show()

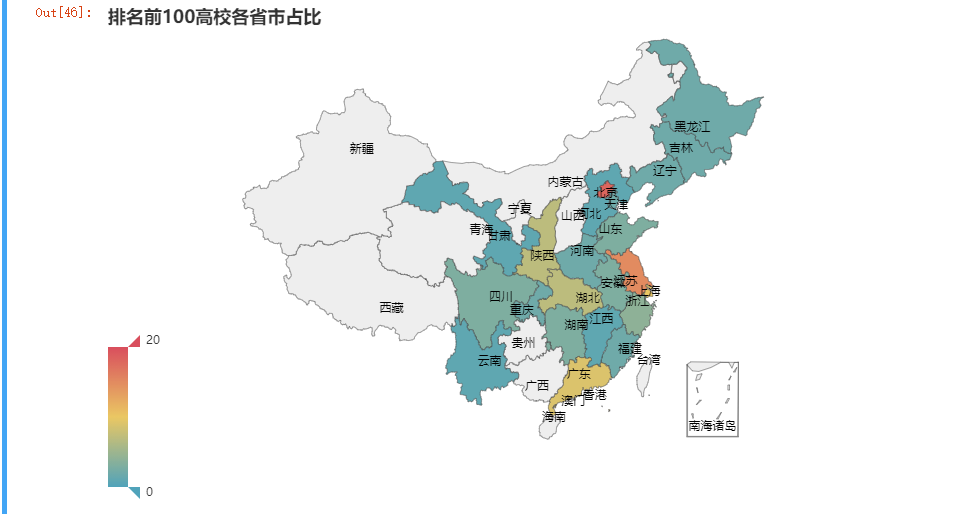
26. 热力地图
结合 pyecharts 进行地图可视化
from pyecharts import options as optsfrom pyecharts.charts import Maplist1 = list(pd.DataFrame(df.省市.value_counts()).index)list2 = list(pd.DataFrame(df.省市.value_counts()).省市)c = (Map().add('', [list(z) for z in zip(list1,list2)], "china",is_map_symbol_show=False).set_global_opts(title_opts=opts.TitleOpts(title="排名前100高校各省市占比"),visualmap_opts=opts.VisualMapOpts(max_=20),))c.render_notebook()
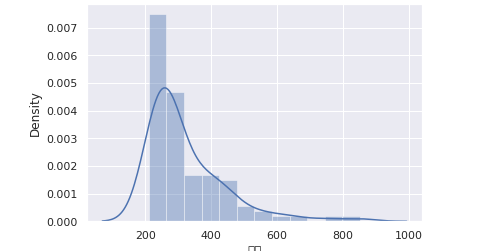
27. 直方图
import seaborn as snssns.set(font='Songti SC')sns.distplot(df['总分'])

若有收获,就点个赞吧
0 人点赞
