1. MapReduce
MapReduce是一个分布式运算程序的编程框架 将用户编写的业务逻辑代码和自带默认组件整合一贯完整的分布式运算程序 并发运行在一个Haoop集群上
优点:它简单的实现一些接口,就可以完成一个分布式程序
缺点:每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
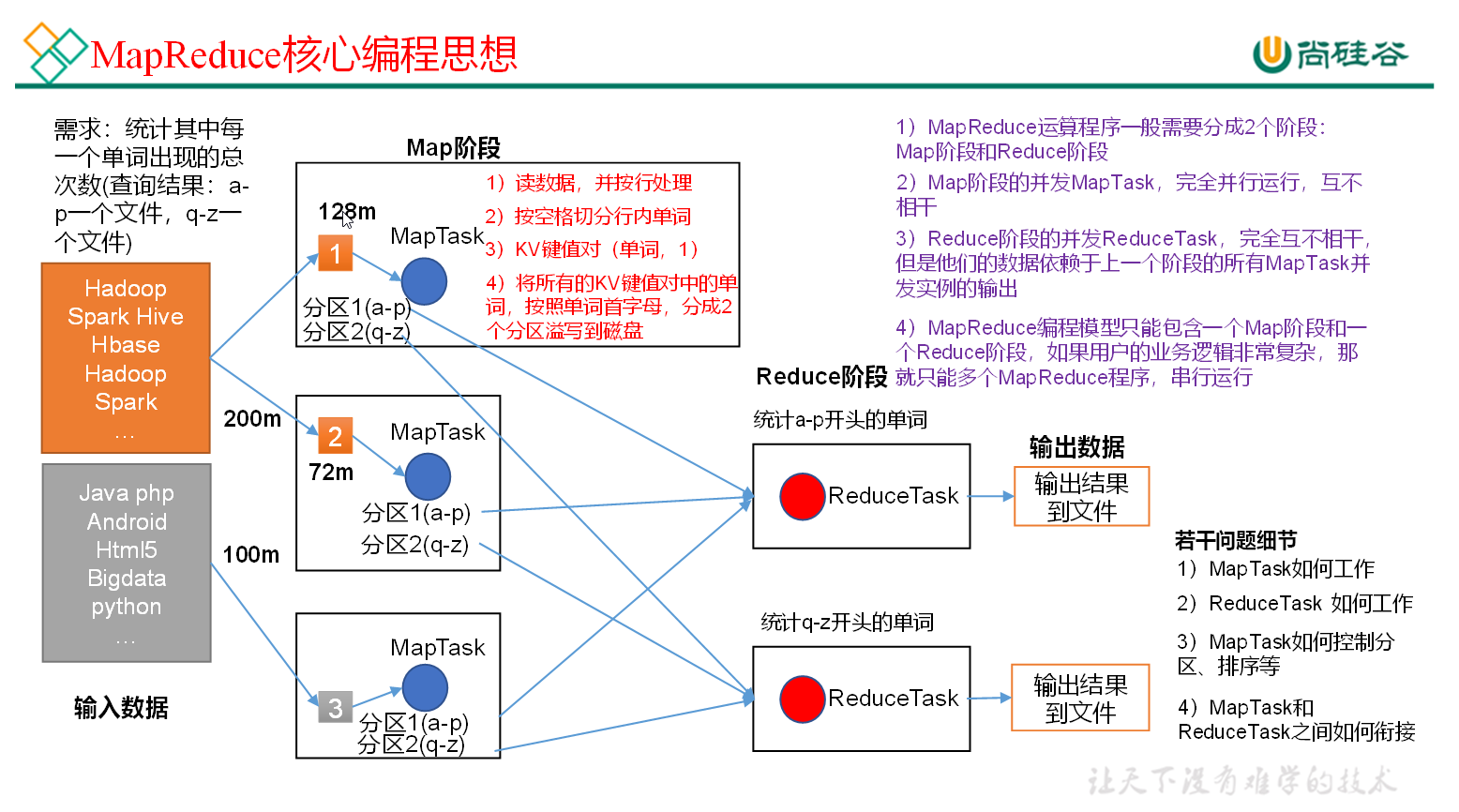
2. Hadoop原生MapReduce
存储在/opt/module/hadoop-3.1.3/share/hadoop/mapreduce
- yarn jar MapReduce路径 wordcount 输入hdfs文件路径 输出hdfs文件保存路径还是在hdfs上(必须是不存在的文件夹否则报错)
cd /opt/module/hadoop-3.1.3yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /fiddler.md /output
打开hdfs中output中的part-r-xxxx 里面会统计出每个字词出现的次数
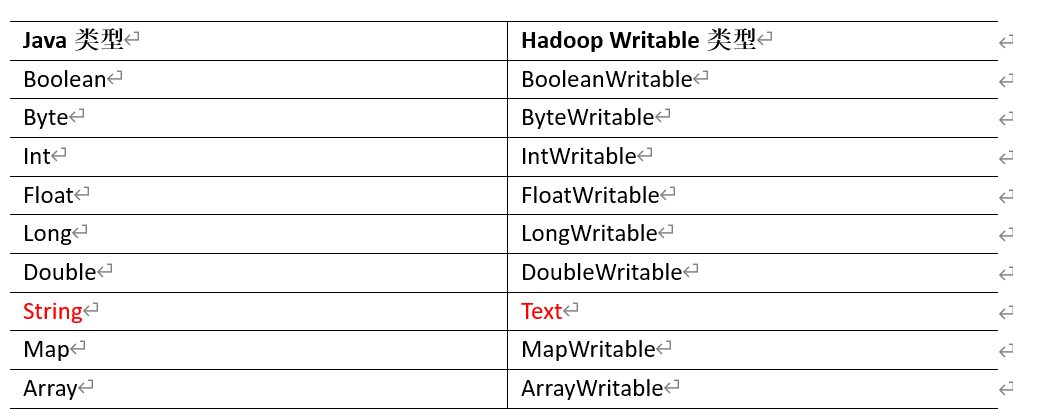
3. 常用数据序列化类型
4. WordCount编写
使用IDEA中创建hadoop项目 创建maven项目
WcDriver类
package com.mywordcount;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WcDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {//1.获取Job实例Job job = Job.getInstance(new Configuration());//2.设置jar包job.setJarByClass(WcDriver.class);//设置Mapper和Reducerjob.setMapOutputKeyClass(WcDriver.class);job.setReducerClass(WcReducer.class);//设置Map和Reduce的输出类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//设置输入输出文件FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));//提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}}
WcMapper
package com.mywordcount;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class WcMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private IntWritable one = new IntWritable(1);private Text word = new Text();/*** 框架将数据拆成一行一行输入进来 把数据变成(单词,1)的形式** @param key 行号* @param value 行内容* @param context 任务本身* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {//行数据String line = value.toString();//拆分成若干个单词String[] words = line.split(" ");//将(单词,1)写回框架for (String word : words) {this.word.set(word);context.write(this.word, this.one);}}}
WcReducer
package com.mywordcount;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WcReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();/*** 框架把单词分好组给我们, 我们将同一个单词的次数进行增加** @param key 单词* @param values 此时为1 数量* @param context 任务本身* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {//累加int sum = 0;for (IntWritable value : values) {sum += value.get();}result.set(sum);context.write(key, result);}}

打包项目 把maprduce1-1.0上传到集群中 打包前注意java版本 请用1.8打包
https://zhuanlan.zhihu.com/p/348660719 还有pom.xml版本要设置

- yarn jar mapreduce1-1.0-SNAPSHOT.jar 全类名引用路径 /fiddler.md /output2
yarn jar mapreduce1-1.0-SNAPSHOT.jar com.mywordcount.WcDriver /fiddler.md /output2
5. HaDoop序列化
序列号就是把内存中的对象,转换为二进制序列 以便持久化
JAVA序列化是一个重量级序列化框架 会附带额外的信息(校验信息 header 继承体系等)
但Hadoop不需要这么多信息,所以Hadoop拥有自己的一套序列化体系(Writable)
5.1. 统计流量案例
- FlowBean类 ```java package com.flow;
import org.apache.hadoop.io.Writable;
import java.io.DataInput; import java.io.DataOutput; import java.io.IOException;
public class FlowBean implements Writable { private long upFlow; private long downFlow; private long sumFlow;
@Overridepublic String toString() {return "FlowBean{" +"upFlow=" + upFlow +", downFlow=" + downFlow +", sumFlow=" + sumFlow +'}';}public void set(long upFlow, long downFlow) {this.downFlow = downFlow;this.upFlow = upFlow;this.sumFlow = upFlow + downFlow;}public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}/*** 将对象数据写出到框架指定地方 序列化** @param dataOutput 数据的容器* @throws IOException*/@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(upFlow);dataOutput.writeLong(downFlow);dataOutput.writeLong(sumFlow);}/*** 从框架指定地方读取数据填充对象 反序列化** @param dataInput* @throws IOException*/@Overridepublic void readFields(DataInput dataInput) throws IOException {//读写顺序要一致this.upFlow = dataInput.readLong();this.downFlow = dataInput.readLong();this.sumFlow = dataInput.readLong();}
}
2.FlowMapper类```javapackage com.flow;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {private Text phone = new Text();private FlowBean flow = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context) throws IOException, InterruptedException {//拿到一行数据String line = value.toString();//切分String[] split = line.split("\t");//封装phone.set(split[1]);flow.set(Long.parseLong(split[split.length - 3]),//upFlowLong.parseLong(split[split.length - 2]) //downFlow);context.write(phone, flow);}}
- FlowReducer类 ```java package com.flow;
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer
private FlowBean flow = new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException {//累加流量long sumUpFlow = 0;long sumDownFlow = 0;for (FlowBean value : values) {sumUpFlow += value.getUpFlow();sumDownFlow += value.getDownFlow();}//封装为flow对象flow.set(sumUpFlow, sumDownFlow);context.write(key, flow);}
}
4.FlowDriver类```javapackage com.flow;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Job job = Job.getInstance(new Configuration());job.setJarByClass(FlowDriver.class);job.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));boolean completion = job.waitForCompletion(true);System.exit(completion ? 0 : 1);}}
- 打包成jar文件上传到hadoop中
#创建目录hadoop fs -mkdir /inputhadoop fs -put /home/atguigu/phone_data.txt /inputyarn jar mapreduce1-1.0-SNAPSHOT.jar com.flow.FlowDriver /input /output3

若有收获,就点个赞吧
0 人点赞
