1. Azkaban实战
2. Command 单一job案例
在 windows 环境,创建job描述文件,编辑内容如下
#command.jobtype=commandcommand=mkdir /opt/module/test_azkaban
将此文件打包成zip 不能带中文

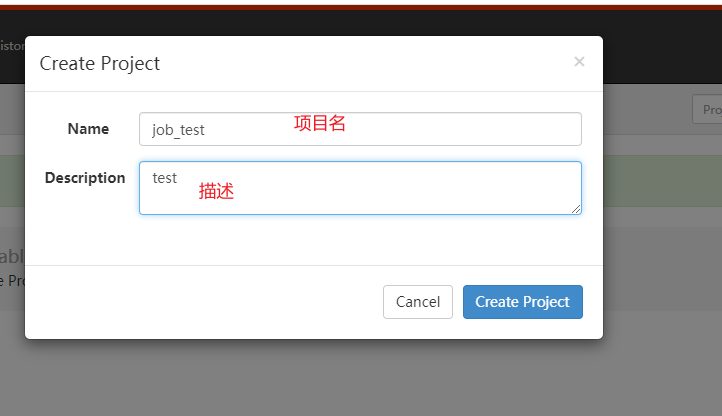
创建项目
上传zip包

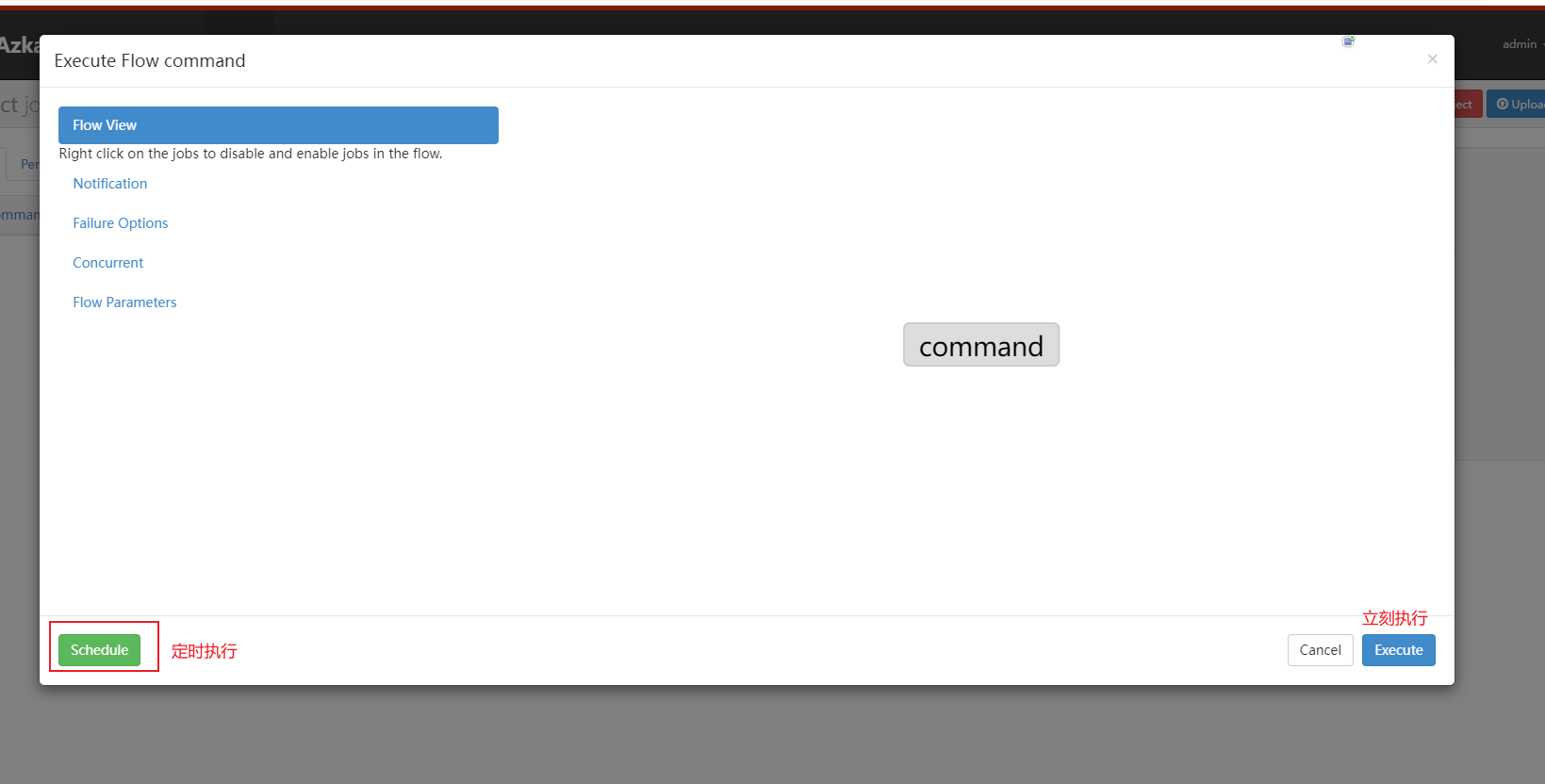
执行

3. 多job工作流
创建有依赖关系的多个job描述
第一个job: foo.job
#foo.jobtype=commandcommand=mkdir /opt/module/az
第二个job:bar.job
#bar.jobtype=commanddependencies=foocommand=touch /opt/module/az/test.txt
打包成zip包提交到azkaban中

4. MapReduce
#foo.jobtype=commandcommand=yarn jar hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
注意jar包也要打包进zip中 一般我们使用自定义的mapreduce
上传执行
5. hive
hive.sql
use default;drop table if exists aztest;drop table if exists azres;create external table aztest(id int,name string) row format delimited fields terminated by '\t'location '/student';load data inpath '/aztest/hiveinput' into table aztest;create table azres as select * from aztest;insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
hive.job
#hive.job
type=command
command=hive -f 'hive.sql'
打包上传并执行

若有收获,就点个赞吧
0 人点赞
