1. 数据采集模块
2. hadoop
2.1. 安装准备工作
安装工具包
sudo yum install -y epel-release #额外软件源sudo yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git wget #安装 psmisc工具包 nc工具包 net-tools工具包 rsync 远程同步 vim编辑器 lrzsz上传下载 ntp时间同步
修改静态ip
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE=ens33TYPE=EthernetONBOOT=yesBOOTPROTO=staticNAME="ens33"IPADDR=192.168.42.102PREFIX=24GATEWAY=192.168.42.2DNS1=192.168.42.2
service network restart
修改主机名
sudo vim /etc/hostname
修改host
sudo vim /etc/hosts
192.168.42.102 hadoop102192.168.42.103 hadoop103192.168.42.104 hadoop104
windows上也配置host
关闭防火墙
sudo systemctl stop firewalldsudo systemctl disable firewalld
创建用户 新版本hadoop无法使用root用户启动
sudo useradd atguigusudo passwd atguigu
修改atguigu权限
visudo
## Allow root to run any commands anywhereroot ALL=(ALL) ALLatguigu ALL=(ALL) ALL #在root下添加此行内容
创建opt下的存放目录
cd /optsudo mkdir modulesudo mkdir softwaresudo chown atguigu:atguigu /opt/module /opt/software
2.2. 安装java
先卸载
rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
解压
cd /opt/software/tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置环境变量
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME#yum 为/usr/lib/jvm/javaexport JAVA_HOME=/opt/module/jdk1.8.0_212export PATH=$PATH:$JAVA_HOME/bin
更新环境变量
source /etc/profilejava -version
2.3. 安装hadoop
解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
配置环境变量
sudo vim /etc/profile.d/my_env.sh
##HADOOP_HOMEexport HADOOP_HOME=/opt/module/hadoop-3.1.3export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin
更新
source /etc/profilehadoop version
2.4. xsync脚本
cd /home/atguiguvim xsync
#!/bin/bash#1. 判断参数个数if [ $# -lt 1 ]thenecho Not Enough Arguement!exit;fi#2. 遍历集群所有机器for host in hadoop102 hadoop103 hadoop104doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidonedone
chmod +x xsyncsudo mv xsync /bin/ #将脚本移动到/bin中,以便全局调用
2.5. ssh免密
生成ssh密钥
ssh-keygen -t rsa
分发ssh密钥
ssh-copy-id hadoop102ssh-copy-id hadoop103ssh-copy-id hadoop104
以上生成和分发 需要在每台机器上执行
2.6. 分发软件
cd /opt/module/xsync jdk1.8.0_212/xsync hadoop-3.1.3/
分发环境变量
sudo scp /etc/profile.d/my_env.sh root@hadoop103:/etc/profile.d/my_env.shsudo scp /etc/profile.d/my_env.sh root@hadoop104:/etc/profile.d/my_env.sh
2.7. 集群配置
集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | DataNode SecondaryNameNode |
| Yarn | NodeManager | Resourcemanager NodeManager | NodeManager |
进配置文件夹
cd /opt/module/hadoop-3.1.3/etc/hadoop
core-site.xml
vim core-site.xml
<property><name>fs.defaultFS</name><!-- 配置hdfs默认的地址 --><value>hdfs://hadoop102:8020</value></property><property><!-- 配置hadoop临时存放路径--><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><property><!-- 兼容性配置hive --><name>hadoop.proxyuser.atguigu.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.atguigu.groups</name><value>*</value></property><property><name>hadoop.http.staticuser.user</name><value>atguigu</value></property>
hdfs-site.xml
<property><!-- 2nn的地址 --><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
yarn-site.xml
<property><!--设置NodeManager上运行的附属服务,需配置成mapreduce_shuffle才可运行MapReduce程序--><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!--设定单个容器可以申领到的最小内存资源--><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!--设定物理节点有4G内存加入资源池--><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
mapred-site.xml
<!--Hadoop对MapReduce运行框架一共提供了3种实现,在mapred-site.xml中通过"mapreduce.framework.name"这个属性来设置为"classic"、"yarn"或者"local"--><property><name>mapreduce.framework.name</name><value>yarn</value></property>
workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
删除localhost 文件中添加的内容结尾不允许有空格,文件中不允许有空行。
hadoop102hadoop103hadoop104
同步
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
2.8. 格式化
格式化hdfs
hdfs namenode -format
启动dfs
start-dfs.sh
如果报java未找到 修改hadoop.env.sh文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
修改JAVA_HOME为 并同步
export JAVA_HOME=/opt/module/jdk1.8.0_212
启动yarn
start-yarn.sh #在103机器上启动
2.9. hdfs存储多目录
若HDFS存储空间紧张,需要对DataNode进行磁盘扩展。
- 在DataNode节点增加磁盘并进行挂载。

- 在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题。
<property><name>dfs.datanode.data.dir</name><value>file:///${hadoop.tmp.dir}/dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value></property>
- 增加磁盘后,保证每个目录数据均衡
bin/start-balancer.sh –threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令:
2.10. LZO压缩配置
2.10.1. 编译
hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译,编译步骤如下
下载、安装并编译LZO
sudo yum -y install gcc-c++ lzo-devel zlib-devel autoconf automake libtoolwget http://www.oberhumer.com/opensource/lzo/download/lzo-2.10.tar.gztar -zxvf lzo-2.10.tar.gzcd lzo-2.10./configure -prefix=/usr/local/hadoop/lzo/makesudo make install
编译hadoop-lzo源码
下载hadoop-lzo的源码,下载地址:https://github.com/twitter/hadoop-lzo/archive/master.zip
解压之后,修改pom.xml
<hadoop.current.version>2.7.2</hadoop.current.version>
声明两个临时环境变量
export C_INCLUDE_PATH=/usr/local/hadoop/lzo/includeexport LIBRARY_PATH=/usr/local/hadoop/lzo/lib
编译打包
mvn package -Dmaven.test.skip=true
进入target,hadoop-lzo-0.4.21-SNAPSHOT.jar 即编译成功的hadoop-lzo组件
2.10.2. 使用
将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
cd /opt/softwaremv hadoop-lzo-0.4.20.jar /opt/module/hadoop-3.1.3/share/hadoop/common/
同步分发
xsync /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar
core-site.xml增加配置支持LZO压缩
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
添加以下内容
<property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value></property><property><name>io.compression.codec.lzo.class</name><value>com.hadoop.compression.lzo.LzoCodec</value></property>
分发
xsync /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
重新启动集群
stop-all.shstart-dfs.sh #102start-yarn.sh #103
LZO创建索引
将bigtable.lzo(150M)上传到集群的/input目录
hadoop fs -mkdir /inputhadoop fs -put bigtable.lzo /input
执行wordcount程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output1
没有创建索引则LZO文件的切片只有一个

创建索引
# hadoop jar 编译好的lzo jar包 类引用路径 lzo数据文件hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo

重新执行wordcount
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2
2.11. 基准测试
2.11.1. 测试HDFS写性能
向HDFS写10个128M的文件
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB

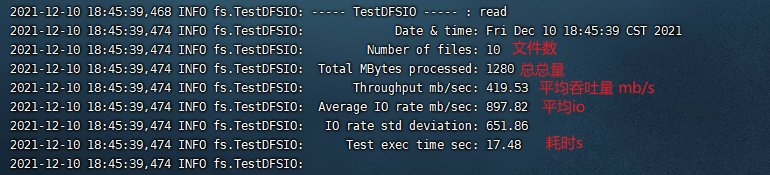
2.11.2. 测试HDFS读性能
读取HDFS集群10个128M的文件
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
2.11.3. 删除测试生成数据
测试数据默认存储在 /benchmarks/TestDFSIO上
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
2.11.4. 使用sort测试mapreduce
使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data
执行sort程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data
验证数据是否真正排好序了
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
2.12. hadoop参数调优
HDFS参数调优hdfs-site.xml
dfs.namenode.handler.count=20 * log2(Cluster Size)
如集群规模为8台时,此参数设置为60
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小YARN参数调优yarn-site.xml
- 情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
- 面临问题:数据统计主要用HiveSQL,没有数据倾斜(每个reduce数据没有偏大或偏小),小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
- 解决办法:内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
- yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。 - yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。 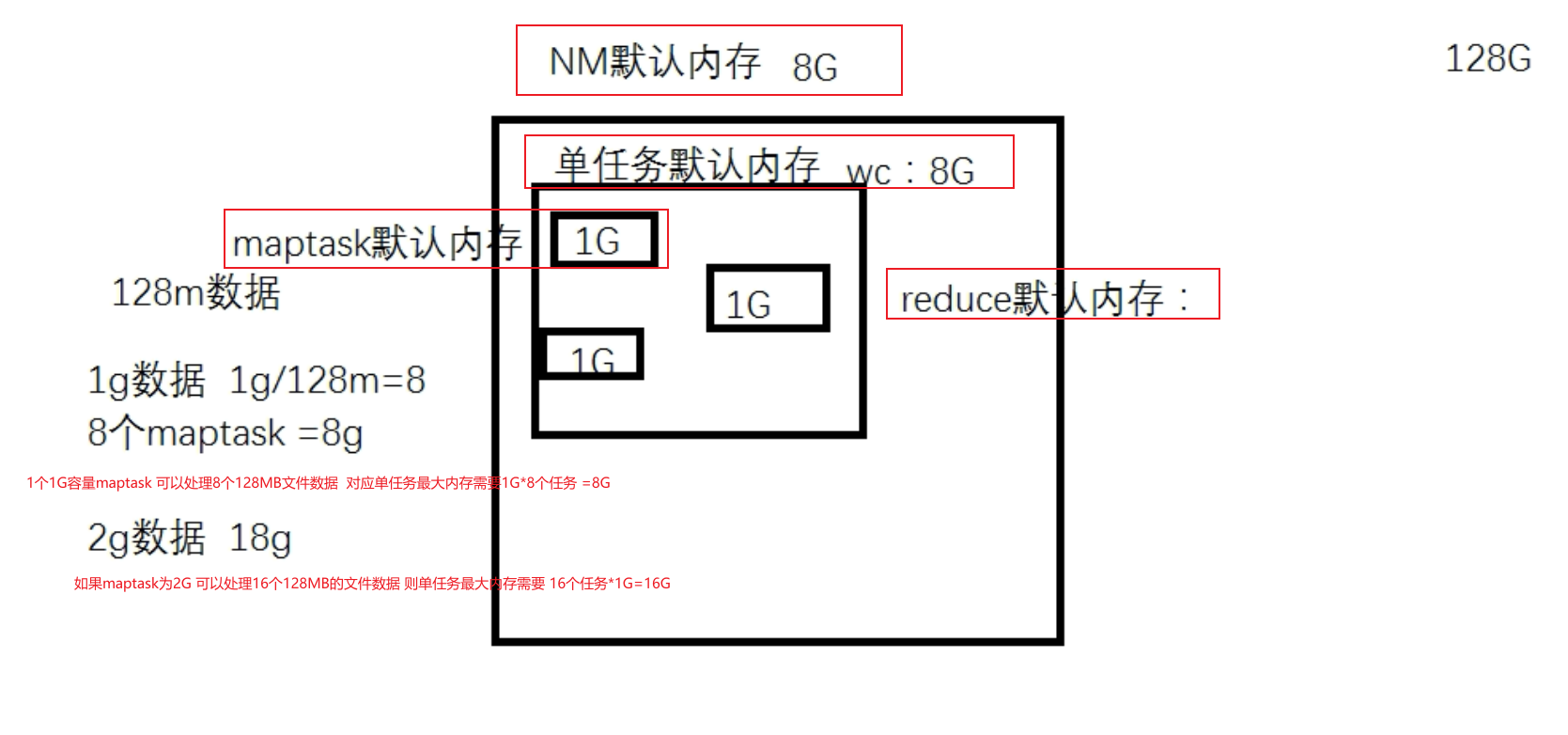
- yarn.nodemanager.resource.memory-mb
- Hadoop宕机
- 如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
- 如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
3. zookeeper
集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
tar -zxvf /opt/software/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/mv /opt/module/apache-zookeeper-3.5.7-bin/ /opt/module/zookeeper#环境变量sudo vim /etc/profile.d/my_env.sh#追加#ZOOKEEPER_HOMEexport ZOOKEEPER_HOME=/opt/module/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/bin#同步环境变量source /etc/profile.d/my_env.shsudo xsync /etc/profile.d/my_env.sh#将配置文件改名称为zoo.cfgcd /opt/module/zookeeper/conf/cp zoo_sample.cfg zoo.cfg#配置zookeeper文件vim zoo.cfg#追加下内容server.2=hadoop102:2888:3888server.3=hadoop103:2888:3888server.4=hadoop104:2888:3888#修改数据存储位置dataDir=/opt/module/zookeeper/zkDatacd /opt/module/zookeepermkdir zkData#创建myid用于zookeeper标记机器#编辑为102的2用于唯一标识 103为3 104为4echo 2 > /opt/module/zookeeper/zkData/myid#同步xsync /opt/module/zookeeper/#103echo 3 > /opt/module/zookeeper/zkData/myid#104echo 4 > /opt/module/zookeeper/zkData/myid
启动
#在三台机器上分别启动zkServer.sh start
3.1. 群起脚本
在hadoop102的/home/atguigu/bin目录下创建脚本
mkdir -p /home/atguigu/bincd /home/atguigu/binvim zk.sh
#!/bin/bashcase $1 in"start"){for i in hadoop102 hadoop103 hadoop104doecho "------------- $i -------------"ssh $i "/opt/module/zookeeper/bin/zkServer.sh start"done};;"stop"){for i in hadoop102 hadoop103 hadoop104doecho "------------- $i -------------"ssh $i "/opt/module/zookeeper/bin/zkServer.sh stop"done};;"status"){for i in hadoop102 hadoop103 hadoop104doecho "------------- $i -------------"ssh $i "/opt/module/zookeeper/bin/zkServer.sh status"done};;esac
增加权限
chmod 755 zk.shzk.sh start
4. 日志生成
将之前日志生成的带依赖jar上传到102上
4.1. 代码参数说明
// 参数一:控制发送每条的延时时间,默认是0Long delay = args.length > 0 ? Long.parseLong(args[0]) : 0L;// 参数二:循环遍历次数int loop_len = args.length > 1 ? Integer.parseInt(args[1]) : 1000;
4.2. 启动方式
启动方式有两种:
- 通过jar -classpath指定全类名启动
java -classpath log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain >/opt/module/test.log
- 通过jar -jar 启动 必须打包时指定启动类类引用否则无法启动
java -jar log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar >/opt/module/test.log
4.3. 日志收集
我们通过上面方式启动 java程序会收集控制台中的输出 但我们已经通过logback收集日志到指定路径文件了 我们无需保存控制台上的输出内容 可以通过将输出内容直接输出到/dev/null中
/dev/null代表linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
| 名称 | 代码 | 操作符 | Java中表示 | Linux 下文件描述符(Debian 为例) |
|---|---|---|---|---|
| 标准输入(stdin) | 0 | < 或 << | System.in | /dev/stdin -> /proc/self/fd/0 -> /dev/pts/0 |
| 标准输出(stdout) | 1 | >, >>, 1> 或 1>> | System.out | /dev/stdout -> /proc/self/fd/1 -> /dev/pts/0 |
| 标准错误输出(stderr) | 2 | 2> 或 2>> | System.err | /dev/stderr -> /proc/self/fd/2 -> /dev/pts/0 |
java -jar log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar 2>/dev/null 1>/dev/null
可以简写为
java -jar log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar >/dev/null 2>&1
在/tmp/logs路径下查看生成的日志文件
cd /tmp/logs/ls
4.4. 集群日志生成脚本
先同步日志jar到集群其他机器上
xsync /opt/module/log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar
在/home/atguigu/bin目录下创建脚本lg.sh
vim /home/atguigu/bin/lg.sh
#! /bin/bashfor i in hadoop102 hadoop103dossh $i "java -jar /opt/module/log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar $1 $2 >/dev/null 2>&1 &"done
chmod 755 /home/atguigu/bin/lg.sh/home/atguigu/bin/lg.sh
4.5. 集群时间同步修改脚本(非正规临时脚本)
在/home/atguigu/bin目录下创建脚本dt.sh
vim /home/atguigu/bin/dt.sh
#!/bin/bashfor i in hadoop102 hadoop103 hadoop104doecho "========== $i =========="ssh -t $i "sudo date -s $1"done
ssh -t 通常用于ssh远程执行sudo命令
chmod 755 /home/atguigu/bin/dt.sh/home/atguigu/bin/dt.sh 2020-03-10
4.6. 集群所有进程查看脚本
在/home/atguigu/bin目录下创建脚本xcall.sh
vim /home/atguigu/bin/xcall.sh
#! /bin/bashfor i in hadoop102 hadoop103 hadoop104doecho --------- $i ----------ssh $i "$*"done
chmod 755 /home/atguigu/bin/xcall.shxcall.sh jps
5. 采集日志Flume

集群规划:
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| Flume(采集日志) | Flume | Flume |
5.1. 安装
tar -zxvf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/cd /opt/module/mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume#将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3rm /opt/module/flume/lib/guava-11.0.2.jarsudo vim /etc/profile.d/my_env.sh#FLUME_HOMEexport FLUME_HOME=/opt/module/flumeexport PATH=$PATH:$FLUME_HOME/binsource /etc/profile.d/my_env.sh
同步
cd /opt/module/xsync flume/sudo xsync /etc/profile.d/my_env.sh
5.2. Flume组件选择
- Source
(1)Taildir Source相比Exec Source、Spooling Directory Source的优势
TailDir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
Exec Source可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
Spooling Directory Source监控目录,不支持断点续传。
(2)batchSize大小如何设置?
答:Event 1K左右时,500-1000合适(默认为100)
- Channel
采用Kafka Channel,省去了Sink,提高了效率。KafkaChannel数据存储在Kafka里面,所以数据是存储在磁盘中。
注意在Flume1.7以前,Kafka Channel很少有人使用,因为发现parseAsFlumeEvent这个配置起不了作用。也就是无论parseAsFlumeEvent配置为true还是false,都会转为Flume Event。这样的话,造成的结果是,会始终都把Flume的headers中的信息混合着内容一起写入Kafka的消息中,这显然不是我所需要的,我只是需要把内容写入即可。
5.3. Flume配置
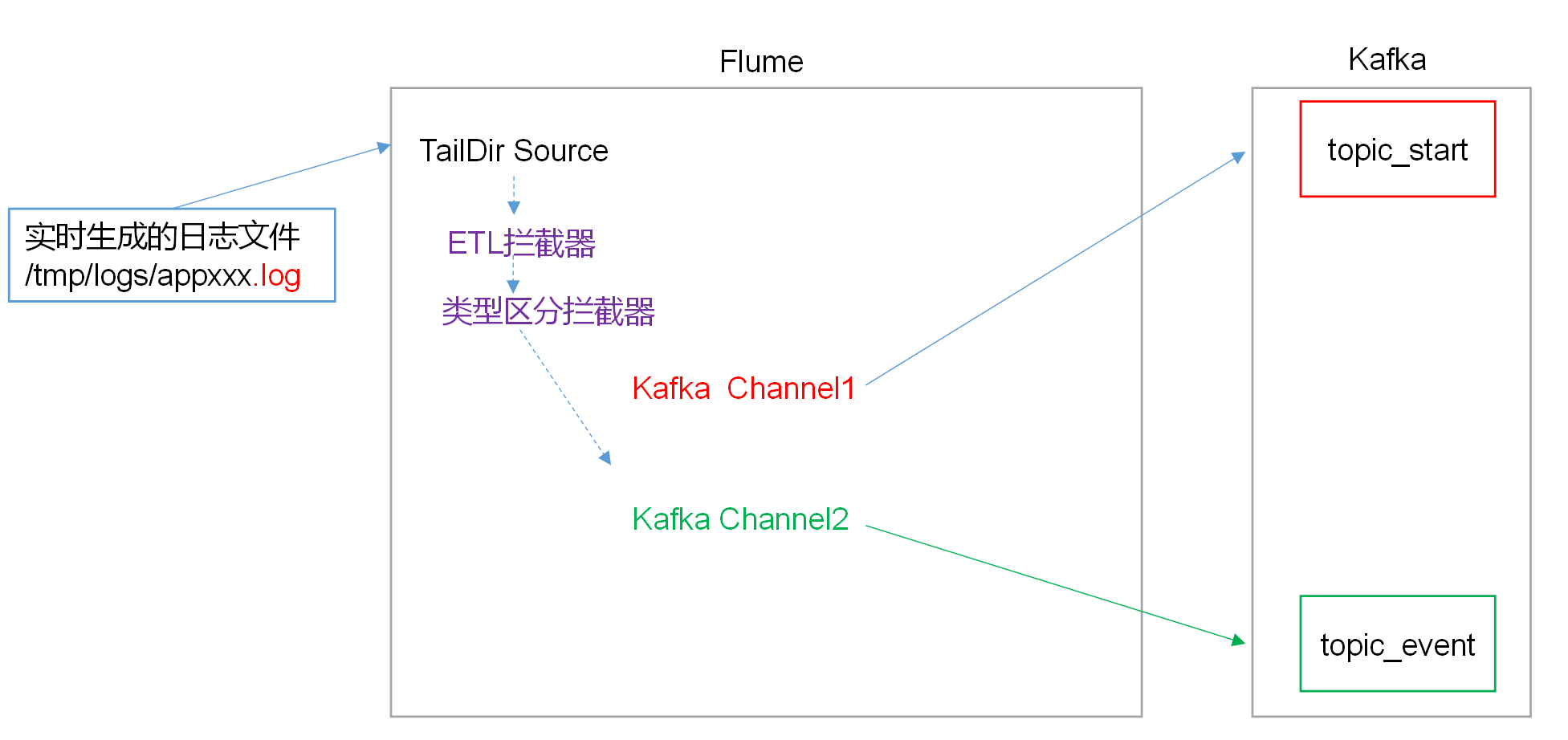
file-flume-kafka.conf文件
cd /opt/module/flume/confvim file-flume-kafka.conf
a1.sources=r1a1.channels=c1 c2# configure sourcea1.sources.r1.type = TAILDIRa1.sources.r1.positionFile = /opt/module/flume/test/log_position.jsona1.sources.r1.filegroups = f1a1.sources.r1.filegroups.f1 = /tmp/logs/app.+a1.sources.r1.fileHeader = truea1.sources.r1.channels = c1 c2#interceptora1.sources.r1.interceptors = i1 i2a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.LogETLInterceptor$Buildera1.sources.r1.interceptors.i2.type = com.atguigu.flume.interceptor.LogTypeInterceptor$Buildera1.sources.r1.selector.type = multiplexinga1.sources.r1.selector.header = topica1.sources.r1.selector.mapping.topic_start = c1a1.sources.r1.selector.mapping.topic_event = c2# configure channela1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.channels.c1.kafka.topic = topic_starta1.channels.c1.parseAsFlumeEvent = falsea1.channels.c1.kafka.consumer.group.id = flume-consumera1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.c2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.channels.c2.kafka.topic = topic_eventa1.channels.c2.parseAsFlumeEvent = falsea1.channels.c2.kafka.consumer.group.id = flume-consumer

5.4. ETL和分类型拦截器
本项目中自定义了两个拦截器,分别是:ETL拦截器、日志类型区分拦截器。
ETL拦截器主要用于,过滤时间戳不合法和Json数据不完整的日志
日志类型区分拦截器主要用于,将启动日志和事件日志区分开来,方便发往Kafka的不
在ide创建flume-interceptor工程 导入依赖
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
创建com.atguigu.flume.interceptor包 包下创建 LogETLInterceptor 类 并实现Interceptor接口
package com.atguigu.flume.interceptor;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.nio.charset.Charset;import java.nio.charset.StandardCharsets;import java.util.ArrayList;import java.util.List;public class LogETLInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {//将event转换为string 方便处理byte[] body = event.getBody();String log = new String(body, StandardCharsets.UTF_8);//判断日志是启动日志还是事件日志 并向header中添加标识if (log.contains("start")) {//清洗启动日志if (LogUtils.validateStart(log)) {return event;}} else {//清洗事件日志if (LogUtils.validateEvent(log)) {return event;}}return null;}@Overridepublic List<Event> intercept(List<Event> list) {ArrayList<Event> intercepts = new ArrayList<>();for (Event event : list) {Event intercept = intercept(event);if (intercept != null) {intercepts.add(intercept);}}return intercepts;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new LogETLInterceptor();}@Overridepublic void configure(Context context) {}}}
LogUtils 工具类
package com.atguigu.flume.interceptor;import org.apache.commons.lang.math.NumberUtils;public class LogUtils {public static boolean validateStart(String log) {if (log == null) {return false;}//开头不是以{或结尾不是以}结束的 不是json字符串if (!log.trim().startsWith("{") || log.trim().endsWith("}")) {return false;}return true;}public static boolean validateEvent(String log) {if (log == null) {return false;}//以 | 切割String[] logConents = log.split("\\|");//判断长度if (logConents.length != 2) {return false;}//判断服务器时间是否够13位 并且判断是否全为数字if (logConents[0].length() != 13 || !NumberUtils.isDigits(logConents[0])) {return false;}//判断json完整性if (!logConents[1].trim().startsWith("{") || !logConents[1].trim().endsWith("}")) {return false;}return true;}}
分类型拦截器 LogTypeInterceptor
package com.atguigu.flume.interceptor;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;import java.util.ArrayList;import java.util.List;import java.util.Map;public class LogTypeInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {//取出body数据byte[] body = event.getBody();String log = new String(body, StandardCharsets.UTF_8);//headerMap<String, String> headers = event.getHeaders();if (log.contains("start")) {headers.put("topic", "topic_start");} else {headers.put("topic", "topic_event");}return event;}@Overridepublic List<Event> intercept(List<Event> list) {ArrayList<Event> resultEvent = new ArrayList<>();for (Event event : list) {resultEvent.add(event);}return resultEvent;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder{@Overridepublic Interceptor build() {return new LogTypeInterceptor();}@Overridepublic void configure(Context context) {}}}
打包上传jar包到flume的lib中 选择不带依赖即可
同步分发
xsync /opt/module/flume/
5.5. flume启动脚本
在/home/atguigu/bin目录下创建脚本f1.sh
vim /home/atguigu/bin/f1.sh
#! /bin/bashcase $1 in"start"){for i in hadoop102 hadoop103doecho " --------启动 $i 采集flume-------"ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/test1 2>&1 &"done};;"stop"){for i in hadoop102 hadoop103doecho " --------停止 $i 采集flume-------"ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "done};;esac
说明1:nohup,该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup就是不挂起的意思,不挂断地运行命令。
说明2:awk 默认分隔符为空格
说明3:xargs 表示取出前面命令运行的结果,作为后面命令的输入参数。
cd /home/atguigu/bin/chmod 755 f1.shf1.sh start
6. Kafka
集群规划:
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| Kafka | Kafka | Kafka | Kafka |
要先启动zookeeper
tar -zxvf /opt/software/kafka_2.11-2.4.1.tgz -C /opt/module/cd /opt/module/mv kafka_2.11-2.4.1/ kafkacd kafkamkdir logs#环境变量sudo vim /etc/profile.d/my_env.sh#KAFKA_HOMEexport KAFKA_HOME=/opt/module/kafkaexport PATH=$PATH:$KAFKA_HOME/binsource /etc/profile.d/my_env.sh
配置kafka
vim /opt/module/kafka/config/server.properties
除了删除功能是新添加属性 其他都是修改
#broker的全局唯一编号,不能重复broker.id=0#添加删除功能#删除topic功能使能delete.topic.enable=true#kafka运行日志存放的路径log.dirs=/opt/module/kafka/logs#配置连接Zookeeper集群地址zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
同步
xsync /opt/module/kafkasudo xsync /etc/profile.d/my_env.sh
修改每个kafka中 broker.id
vim /opt/module/kafka/config/server.properties#102 为 0, 103为1 , 104为2
3.1. 群起脚本
在/home/atguigu/bin目录下创建脚本kf.sh
vim /home/atguigu/bin/kf.sh
#! /bin/bashcase $1 in"start"){for i in hadoop102 hadoop103 hadoop104doecho " --------启动 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done};;"stop"){for i in hadoop102 hadoop103 hadoop104doecho " --------停止 $i Kafka-------"ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh"done};;esac
cd /home/atguigu/bin/chmod 755 kf.shkf.sh start
6.2. 创建Kafka Topic
进入到/opt/module/kafka/目录下分别创建:启动日志主题、事件日志主题
kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --create --replication-factor 1 --partitions 1 --topic topic_startkafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --create --replication-factor 1 --partitions 1 --topic topic_event
查询topic列表
kafka-topics.sh --zookeeper hadoop102:2181/kafka --list
删除topic
kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --topic topic_startkafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka --topic topic_event
生产消息
kafka-console-producer.sh --broker-list hadoop102:9092 --topic topic_start
消费消息
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic topic_start
6.3. 压力测试
用Kafka官方自带的脚本,对Kafka进行压测。Kafka压测时,可以查看到哪个地方出现了瓶颈(CPU,内存,网络IO)。一般都是网络IO达到瓶颈。
6.3.1. 生产者
kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
record-size是一条信息有多大,单位是字节。
num-records是总共发送多少条信息。
throughput 是每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量。

本例中一共写入10w条消息,吞吐量为7.05 MB/sec,每次写入的平均延迟为408.12毫秒,最大的延迟为603.00毫秒。
6.3.2. 消费者
kafka-consumer-perf-test.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1
—zookeeper 指定zookeeper的链接信息
—topic 指定topic的名称
—fetch-size 指定每次fetch的数据的大小
—messages 总共要消费的消息个数

start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
开始测试时间,测试结束数据,共消费数据9.5367MB,吞吐量0.7875MB/s,共消费100000条,平均每秒消费**8257条。
6.4. kafka机器数量计算
Kafka机器数量(经验公式)=2(峰值生产速度副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量=2_(50_2/100)+ 1=3台
7. 消费kafka数据flume
此flume用于消费kafka中的数据 上传至hdfs上
集群规划
| 服务器hadoop102 | 服务器hadoop103 | 服务器hadoop104 | |
|---|---|---|---|
| Flume(消费Kafka) | Flume |

7.1. 日志消费flume配置
目前是启动日志和事件日志写在同一个config配置中 建议拆分为两个配置文件分开运行 解耦
在hadoop104的/opt/module/flume/conf目录下创建kafka-flume-hdfs.conf文件
vim /opt/module/flume/conf/kafka-flume-hdfs.conf
## 组件a1.sources=r1 r2a1.channels=c1 c2a1.sinks=k1 k2## source1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource#控制消费速度 每秒5000条a1.sources.r1.batchSize = 5000#延迟时间如果指定毫秒数没有到达指定消费速度 同样消费速度a1.sources.r1.batchDurationMillis = 2000a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.sources.r1.kafka.topics=topic_start## source2a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSourcea1.sources.r2.batchSize = 5000a1.sources.r2.batchDurationMillis = 2000a1.sources.r2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.sources.r2.kafka.topics=topic_event## channel1a1.channels.c1.type = filea1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/a1.channels.c1.maxFileSize = 2146435071a1.channels.c1.capacity = 1000000a1.channels.c1.keep-alive = 6## channel2a1.channels.c2.type = file#checkpointDir为存储日志 dataDirs为存储数据位置 两目录可以指定一个多目录路径提高读写性能a1.channels.c2.checkpointDir = /opt/module/flume/checkpoint/behavior2a1.channels.c2.dataDirs = /opt/module/flume/data/behavior2/#文件最大值a1.channels.c2.maxFileSize = 2146435071#数据容量a1.channels.c2.capacity = 1000000#等待时长 如果容量未达到指定大小,并且超过指定时间则提交到sinka1.channels.c2.keep-alive = 6## sink1a1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%da1.sinks.k1.hdfs.filePrefix = logstart-##sink2a1.sinks.k2.type = hdfsa1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%da1.sinks.k2.hdfs.filePrefix = logevent-## 不要产生大量小文件 以下3个配置属性满足任意一个则滚动到下一个文件#等待多少秒才滚动到下一个文件 默认为30s 建议为3600sa1.sinks.k1.hdfs.rollInterval = 10#多少字节滚动一次 默认为1024a1.sinks.k1.hdfs.rollSize = 134217728#event写入的个数滚动 默认为10 0则为禁用a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k2.hdfs.rollInterval = 10a1.sinks.k2.hdfs.rollSize = 134217728a1.sinks.k2.hdfs.rollCount = 0## 控制输出文件是否原生文件 此处设置为压缩流a1.sinks.k1.hdfs.fileType = CompressedStreama1.sinks.k2.hdfs.fileType = CompressedStream# 设置压缩格式a1.sinks.k1.hdfs.codeC = lzopa1.sinks.k2.hdfs.codeC = lzop## 拼装a1.sources.r1.channels = c1a1.sinks.k1.channel= c1a1.sources.r2.channels = c2a1.sinks.k2.channel= c2

5.2. Flume组件选择
- FileChannel和MemoryChannel区别
MemoryChannel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。
FileChannel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
企业选型:
- 金融类公司、对钱要求非常准确的公司通常会选择FileChannel
- 传输的是普通日志信息(京东内部一天丢100万-200万条,这是非常正常的),通常选择MemoryChannel。
- FileChannel优化
通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。
官方说明如下:
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据 - Sink:HDFS Sink
(1)HDFS存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。
(2)HDFS小文件处理
官方默认的这三个参数配置写入HDFS后会产生小文件,hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount
基于以上hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0几个参数综合作用,效果如下:
(1)文件在达到128M时会滚动生成新文件
(2)文件创建超3600秒时会滚动生成新文件
7.3. 日志消费Flume启动脚本
cd /home/atguigu/binvim f2.sh
#! /bin/bashcase $1 in"start"){for i in hadoop104doecho " --------启动 $i 消费flume-------"ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log.txt 2>&1 &"done};;"stop"){for i in hadoop104doecho " --------停止 $i 消费flume-------"ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs -n1 kill"done};;esac
chmod 755 f2.shf2.sh startf2.sh stop
7.4. Flume内存优化
如果启动消费Flume抛出如下异常则表示该机器最小内存不满足于Flume配置的最小启动内存
ERROR hdfs.HDFSEventSink: process failed java.lang.OutOfMemoryError: GC overhead limit exceeded
我们可以修改Flume的默认内存配置
vim /opt/module/flume/conf/flume-env.sh
#添加以下配置export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
分发配置文件
xsync flume-env.sh
Flume内存参数设置及优化
- JVM heap一般设置为4G或更高,部署在单独的服务器上(4核8线程16G内存)
- -Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
- -Xms表示JVM Heap(堆内存)最小尺寸,初始分配;-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发fullgc。
8. 采集通道启动/停止脚本
该脚本控制全部组件的启动和停止
cd /home/atguigu/binvim cluster.sh
注意要先启动zookeeper再起kafka 关闭时候先关kafka再关zookeeper
#! /bin/bashcase $1 in"start"){echo " -------- 启动 集群 -------"echo " -------- 启动 hadoop集群 -------"/opt/module/hadoop-3.1.3/sbin/start-dfs.shssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"#启动 Zookeeper集群zk.sh startsleep 4s;#启动 Flume采集集群f1.sh start#启动 Kafka采集集群kf.sh startsleep 6s;#启动 Flume消费集群f2.sh start};;"stop"){echo " -------- 停止 集群 -------"#停止 Flume消费集群f2.sh stop#停止 Kafka采集集群kf.sh stopsleep 6s;#停止 Flume采集集群f1.sh stop#停止 Zookeeper集群zk.sh stopecho " -------- 停止 hadoop集群 -------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh};;esac
chmod 755 cluster.shcluster.sh startcluster.sh stop
9. 采集模块总结
9.1. Linux&Shell相关总结
Linux常用高级命令
| 序号 | 命令 | 命令解释 |
|---|---|---|
| 1 | top | 查看内存 |
| 2 | df -h | 查看磁盘存储情况 |
| 3 | iotop | 查看磁盘IO读写(yum install iotop安装) |
| 4 | iotop -o | 直接查看比较高的磁盘读写程序 |
| 5 | netstat -tunlp | grep 端口号 | 查看端口占用情况 |
| 6 | uptime | 查看报告系统运行时长及平均负载 |
| 7 | ps aux | 查看进程 |
Shell常用工具
awk、sed、cut、sort
9.2. Hadoop相关总结
- Hadoop默认不支持LZO压缩,如果需要支持LZO压缩,需要添加jar包,并在hadoop的cores-site.xml文件中添加相关压缩配置。需要掌握让LZO文件支持切片。
- Hadoop常用端口号,50070,8088,19888,9000
- Hadoop配置文件以及简单的Hadoop集群搭建。8个配置文件
core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers(2.7为slaves) - 默认块大小
- 集群模式 128m
- 本地模式 32m
- hadoop1.x 64m
- 在业务开发中hdfs块大小通常设置为 128m或256m
- hive的文件块大小 256m
- 小文件问题
- 危害
- 占用namenode内存 一个文件块占用namenode 150字节
- 增加切片数 每个文件开启一个maptask(默认内存为1g)
- 解决办法
- har归档 自定义FileInputFormat
- combineInputformat 减少切片个数,进而减少的是maptask
- 开启JVM重用
- 危害
- MapReduce
- shuffle优化
- map方法之后 reduce方法之前 混洗过程
- Yarn
- 工作机制
- 调度器
- FIFO、容量、公平调度器 Apache默认调度器:容量 CDH默认调度器:公平调度器
- FIFO调度器特点:单队列,先进先出,在企业开发中没人使用
- 容量调度器:支持多队列,先进来的任务优先享有资源
- 公平调度器:支持多队列,每个任务公平享有资源 并发度最高。
- 对并发度要求比较高,同时机器性能比较好,选择公平; 大公司
如果并发度不高,机器性能比较差,选择容量: 中小公司 - 生产环境下队列怎么创建?
容量调度器默认只有一个default队列;
按照框架名称:hive、spark、flink
按照业务名称:登录、购物车、支付模块、部门1、部门2 (居多)
好处:解耦、降低风险、可以实现任务降级(部门1》部门2》购物车)
9.3. Flme相关总结
9.3.1. 组成
Flume组成,Put事务,Take事务
Taildir Source:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。File Channel:数据存储在磁盘,宕机数据可以保存。但是传输速率慢。适合对数据传输可靠性要求高的场景,比如,金融行业。Memory Channel:数据存储在内存中,宕机数据丢失。传输速率快。适合对数据传输可靠性要求不高的场景,比如,普通的日志数据。Kafka Channel:减少了Flume的Sink阶段,提高了传输效率。Source到Channel是Put事务Channel到Sink是Take事务
9.3.1.1. taildir source
- 断点续传、多目录
- 在Apache flume1.7之后产生的;如果是CDH,1.6之后;
- 自定义source实现断点续传的功能(只要能自定义,有很多想象空间了)
- taildir source挂了怎么办? 不会丢失、可能产生数据重复
- 对重复数据怎么处理? 不处理;
处理:(自身:自定义source实现事务,额外增加了运算量)- 在下一级处理:hive的数仓里面(dwd层,数据清洗ETL)
- spark Streaming里面处理 去重的手段:group by (id) 开窗(id),只取窗口第一条
- 是否支持递归读取文件? 不支持;自定义tail source(递归+读取) 消费kafka+上传hdfs
9.3.1.2. channel
- File Channel :基于磁盘、效率低、可靠性高
- memoryChannel:基于内存、效率高、可靠性低
- KafkaChannel:数据存储在Kafka里面,基于磁盘、效率高于memoryChannel+kafkasink,因为省了sink
flume1.6时 topic + 内容; 无论true还是false都不起作用; bug
flume1.7解决bug,被大家广泛使用; - 在生产环境:如果下一级是kafka的话,优先选择KafkaChannel;
如果不是kafka,如果更关心可靠性选择FileChannel;如果更关心性能,选择memoryChannel
9.3.1.3. HDFS sink
- 控制小文件:
时间(1-2小时)、大小(128m)、event个数(0禁止) - 压缩
开启压缩流;指定压缩编码方式(lzop/snappy)
9.3.2. 拦截器
- ETL(判断json的完整性 { }; 服务器时间(13 全数字)) 项目中自定义了:ETL拦截器和区分类型拦截器。 用两个拦截器的优缺点:优点,模块化开发和可移植性;缺点,性能会低一些
- 分类型(启动日志、事件日志) kafka(的topic要满足下一级所又消费者) 一张表一个topic
商品列表、商品详情、商品点击广告点赞、评论、收藏后台活跃、通知故障启动日志
- 自定义拦截器步骤
- 定义一个类 实现interceptor接口
- 重写4个方法:初始化、关闭、单event、多event()
- initialize 初始化
- public Event intercept(Event event) 处理单个Event
- public List
<Event>intercept(List<Event>events) 处理多个Event,在这个方法中调用Event intercept(Event event) - close 方法
- 创建一个静态内部类Builder
- 静态内部类,实现Interceptor.Builder
- 拦截器不要行不行? 看具体业务需求决定
9.3.3. 选择器
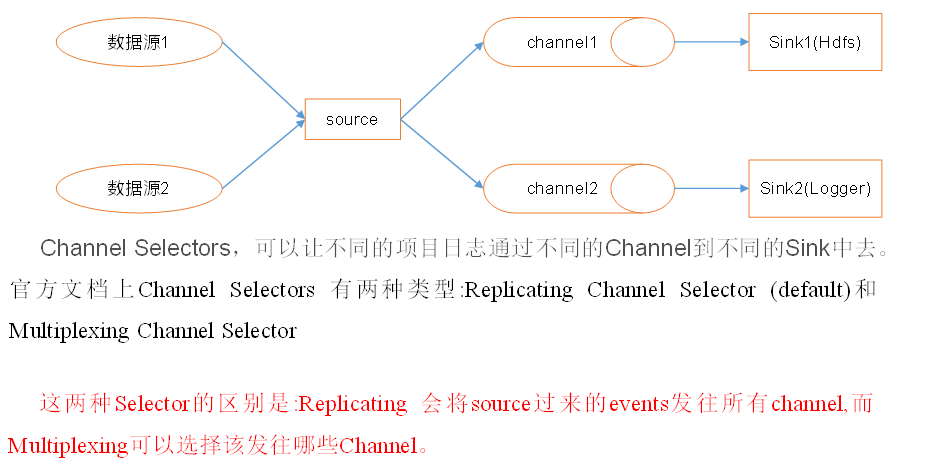
rep(默认) mul(选择性发往下一级通道)
9.3.4. 监控器
ganglia 发现尝试提交的次数 远远大于最终提交成功次数; 说明flume性能不行;
自身;提高自己的内存 4-6g flume_env.sh
外援:增加flume台数 服务器配置(16g/32g 8T)
9.3.5. Flume 内存
开发中在flume-env.sh中设置JVM heap为4G或更高,部署在单独的服务器上(4核8线程16G内存)
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
-Xms表示JVM Heap(堆内存)最小尺寸,初始分配;-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按需分配。如果不设置一致,容易在初始化时,由于内存不够,频繁触发fullgc。
9.3.6. 优化
- File Channel 能多目录就多目录(要求在不同的磁盘),提高吞吐量 checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据
- 控制小文件; 时间(1-2小时)、大小(128m)、event个数(0禁止)
- HDFS存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。
- HDFS小文件处理
官方默认的这三个参数配置写入HDFS后会产生小文件,hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount
基于以上hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0几个参数综合作用,效果如下:
(1)文件在达到128M时会滚动生成新文件
(2)文件创建超3600秒时会滚动生成新文件
- 监控器
9.3.7. Flume采集数据会丢失吗?
不会,Channel存储可以存储在File中,数据传输自身有事务。

若有收获,就点个赞吧
0 人点赞
