1. 多线程高级
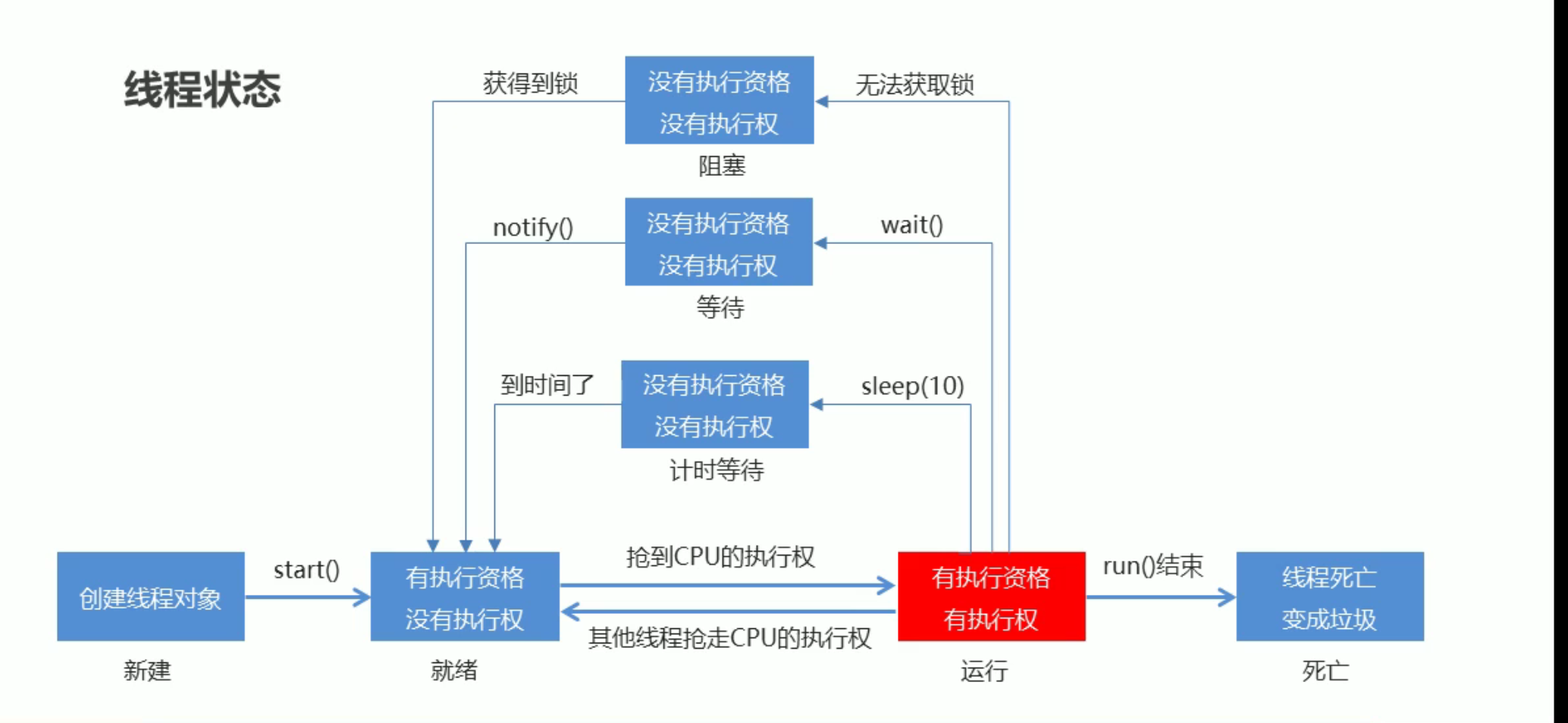
2. 线程状态
3. 线程池
3.1. 创建线程池
创建一关默认的线程池,默认为空,(空参构造方法)默认数量最多可以容纳int的最大值个线程
ExecutorService executorService = Executors.newCachedThreadPool(5);
带参构造为该线程池指定数量的线程池,并不是线程池创建就拥有指定数量的线程,而是该线程池可以拥有线程的上限
Executors类为创建线程池对象类
ExecutorService类为控制线程池类
3.2. 提交 submit
把线程提交给线程池处理
3.3. 销毁 shutdown
关闭线程池
executorService.shutdown();
4. ThreadPoolExecutor 自定义线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(2,5,2, TimeUnit.SECONDS,new ArrayBlockingQueue<>(10),Executors.defaultThreadFactory(),new ThreadPoolExecutor.AbortPolicy());
共有7个参数
- 核心线程数量 int 不能小于0
- 最大线程数 int 不能小于等于0.并且大于等于核心数
- 空闲线程最大存活时间 int 不能小于0
- 时间单位 Enum TimeUnit中的常量
- 任务队列 传递一个阻塞队列 不能为null 如果submit的线程过多则会缓存到队列中
- 创建线程工程 我们使用默认的线程池创建 Executors.defaultThreadFactory() 不能为null
任务的拒绝策略(即超出最大线程数如何处理) 我们使用new ThreadPoolExecutor.AbortPolicy()超出则拒绝 不能为null 当submit线程数量超出了最大线程数+任务队列边界时 触发 拒绝策略
- ThreadPoolExecutor.AbortPolicy: 丢弃任务并抛出RejectedExecutionException异常. 默认的cl
- ThreadPoolExecutor.DiscardPolicy: 丢弃任务 但不抛出异常 不太推荐使用
- ThreadPoolExecutor.DiscardOldestPolicy: 抛弃队列中等待最久的任务 然后把当前任务加入队列中
- ThreadPoolExecutor.CallerRunsPolicy: 调度任务的run()方法绕过线程池直接执行
5. Volatile
- 堆内存是唯一的,每一个线程都有自己的线程栈
- 每个线程在使用堆里面变量的时候,都会先拷贝一个变量的副本中.
- 在线程中,每一次使用都是从变量副本中获取
如果A线程 修改了堆中共享的变量值,其他线程不一定能及时的使用最新的值
使用Volatile关键字可以解决这个问题,强制线程每次使用时,都会先去看一下共享区域中最新值
只需要共享数据前面加上Volatile关键字
Volatile int count = 100;
5.1. 使用Synchronized同步代码块
使用Synchronized同步代码块,也可以解决此问题
- 线程获取锁
- 清空变量副本
- 拷贝共享变量中最新的值到副本中
- 执行代码
- 将修改后变量副本中的值赋值给共享数据
- 释放锁
6. 原子性
原子性指的是在一次或多次操作中,要么所有的操作全部执行并且不会受到任何因素而中断,要么所有的操作都不执行,多个操作是一个不可以分割的整体
我们可以使用Synchronized 锁 来强制协议统一共享数据的唯一性
而Volatile只是让线程在执行时检测在共享数据中检测最新的值并同步 副本中
6.1. 原子类 Atomic
JDK1.5提供了一个原子类 Atomic 该类下的的实现类都可以实现原子性,方便程序员在多线程环境下,无锁的进行原子操作。原子变量的底层使用了处理器提供的原子指令,但是不同的CPU架构可能提供的原子指令不一样,也有可能需要某种形式的内部锁,所以该方法不能绝对保证线程不被阻塞。
6.1.1. AtomicInteger
- AtomicInteger(): 空参构造方法 默认为0
- AtomicInteger(int initialValue): 带参构造方法 指定值原子型
- get(): 获取值
- getAndIncrement(): 以原子方式加+1 并且返回自增前的值
- incrementAndGet(): 以原子方式加+1 并且返回自增后的值
- addAndGet(int data): 以原子方式 与指定值相加 并返回结果
- getAndSet(int value): 以原子方式 设置原子型为指定值 并返回旧的值
原理:
自旋锁 + CAS 算法
CAS算法:有3个操作数(内存值V , 旧的预期值A , 要修改的值B )
当旧的预期A == 内存值 此时修改成功 将V改为B
当旧的预期A != 内存值 修改失败 不做任何操作
并重新获取现在的最新值(这个动作称为自旋)

6.2. Synchronized 与 CAS 的区别(乐观锁和悲观锁)
相同点: 在多线程区块下,都可以保证共享数据的安全性
不同点:
- Synchronized 总是从最坏的角度出发,认为每次获取数据的时候,别人都有可能修改.所以在每次操作共享数据之前,都会上锁.(悲观锁)
- CAS 是乐观的角度出发,假设每次获取数据别人都不会修改,所以不会上锁.只不过在修改共享数据的时候,会去检查一下,别人有没有修改过这个数据. (乐观锁) 如果别人修改过,那么再次获取最新的值 如果别人没有修改过,那么直接修改共享数据的值
7. Hashtable
在多线程下使用HashMap不是线程安全的,在多线程并发的环境下,可能会产生死锁等问题。
- Hashtable采用悲观锁 Synchronized 的形式保证数据的安全性
- 只有有线程访问,会将整张表全部锁起来,所以Hashtable效率低下
- 底层原理与hashmap一样也是数组+链表实现,其他无异
8. ConcurrentHashMap
如果map集合要使用多线程我们可以使用ConcurrentHashMap,它线程安全,效率较高
Hashtable已经被淘汰了
8.1. JDK1.7原理
- 创建一个默认长度为16,默认加载因 位0.75的数组 数组名为 Segmewnt 无法扩容
- 再创建一个长度为2的小数组(数组名为HashEntey) 把地址值赋值给Segmewnt数组中的索引0 (模板) 其他索引都为null
- 根据键的哈希值计算出 Segmewnt 数组索引
- 如果此索引为空 就会创建一个长度默认为2的数组 并把这个小数组的地址值 赋值给 该索引
- 再次利用键的哈希值计算出在 小数组 应存入的索引(二次哈希)
- 如果为空,则直接添加 如非空则equals比较 不同则存入 (链表形式挂载在新元素下面)
- 小数组的加载因 同样为0.75 当超过了20.75=1.5 强转为int=1 会*自动扩容2倍
- Segmewnt数组无法扩容(恒定为16) 因为只有HashEntey小数组在扩容
- ConcurrentHashMap 通过Segmewnt 索引 来加锁(悲观锁 Synchronized ) 所以在JDK1.7 默认情况下,最多允许 16个线程同时访问
8.2. JDK1.8原理
底层结构:哈希表(数组 链表 红黑树结合体)
结合CAS机制 + Synchronized 同步代码块形式来保证线程安全
- 如果使用空参构造方法创建ConcurrentHashMap,则什么事情都不做. 只有在第一次添加元素时候创建哈希表
- 计算出当前元素应存入的索引
- 如果该索引为为null,则利用CAS算法,将本结点添加到数组中
- 如果该索引不为null,则利用Volatile关键字获取当前位置最新的结点地址,挂载到它的下面,变成链表
- 当链表长度大于等于8时,自动转成红黑树
- 以链表或红黑树头结点为锁对象,配合悲观锁(Synchronized)保证多线程数据的安全性
9. CountDownLatch
让某一条线程等待其他线程执行完毕之后在执行.
- CountDownLatch(int count): 带参构造方法 传递线程数,表示等待线程数 定义一个计数器
- await(): 让线程等待 等待其他线程执行完毕后才执行 计数器为0执行
- countDown(): 当前线程执行完毕 将计数器-1
10. Semaphore
可以控制访问特定资源的线程数量 在线程类中创建并使用
- Semaphore(int permits): 带参构造方法 最多允许多少条线程同时执行
- acquire(): 获取通信证
- release(): 归还通信证

若有收获,就点个赞吧
0 人点赞
