- 一、教程指南
- 二、项目实践
- (四)爬虫逻辑
- Automatically created by: scrapy startproject
- For more information about the [deploy] section see:
- https://scrapyd.readthedocs.io/en/latest/deploy.html">https://scrapyd.readthedocs.io/en/latest/deploy.html
- http://localhost:6800/">url = http://localhost:6800/
- (五)运行项目
- (六)具体发生了什么?
- (七)递归爬取
- (八)调试抓取代码
- 三、Scrapy Shell教程
- 四、Shell实践
一、教程指南
注意这不一定是最新版本。
中文版:版本比较滞后。
https://www.osgeo.cn/scrapy/index.html#
英文版:
https://docs.scrapy.org/en/latest/
二、项目实践
(一)安装Scrapy
1、安装python,要3.4以上,3.7比较好。
2、设置python的Path
python\
python\Scripts
3、安装Scrapy:
pip install Scrapy
(二)项目架构
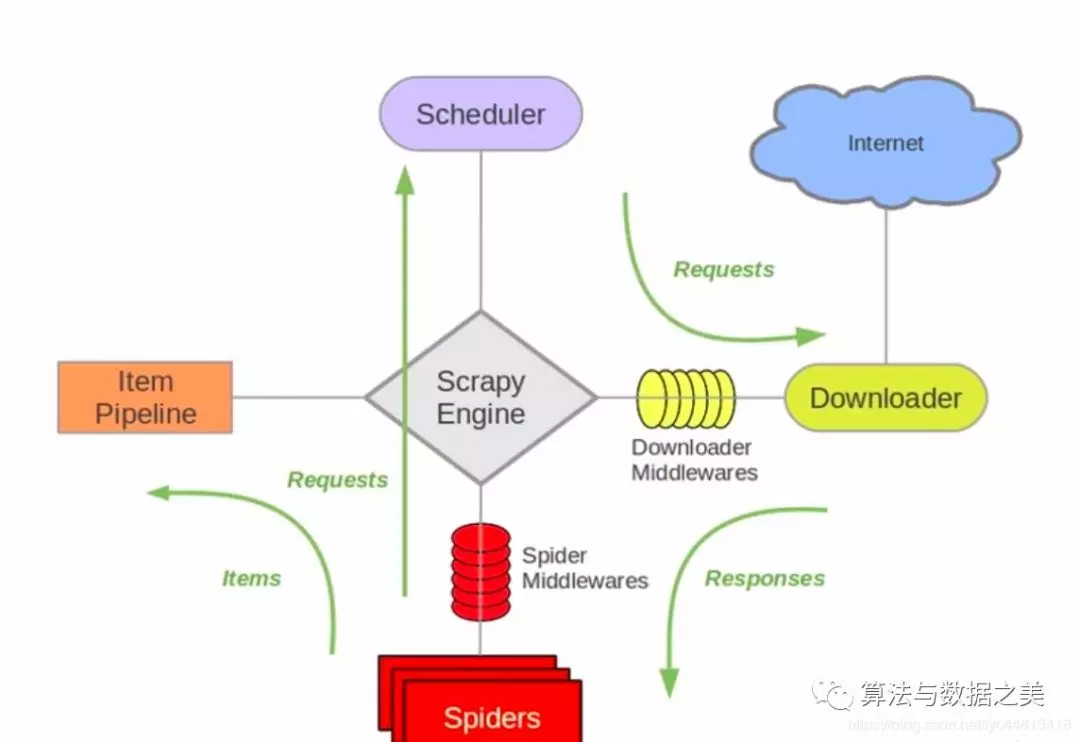
上面是Scrapy的架构图,下面简单介绍一下各个组件
- Scrapy Engine:引擎用来处理整个系统的数据流,触发各个事件,是整个系统的核心部分。
- Scheduler:调度器用来接受引擎发过来的Request请求, 压入队列中, 并在引擎再次请求的时候返回。
- Downloader:下载器用于引擎发过来的Request请求对应的网页内容, 并将获取到的Responses返回给Spider。
- Spiders:爬虫对Responses进行处理,从中获取所需的字段(即Item),也可以从Responses获取所需的链接,让Scrapy继续爬取。
- Item Pipeline:管道负责处理Spider中获取的实体,对数据进行清洗,保存所需的数据。
- Downloader Middlewares:下载器中间件主要用于处理Scrapy引擎与下载器之间的请求及响应。
Spider Middlewares:爬虫中间件主要用于处理Spider的Responses和Requests。
(三)创建项目
Scrapy.exe就在python\scripts下,所以可以全局执行scrapy命令。
Scrapy startproject tutorial
(四)爬虫逻辑
文件结构
项目名/
- scrapy.cfg — 部署文件
- 项目名/
- init.py
- settings.py — 配置文件
- items.py — 爬取数据模型
- piplines.py — 管道
- middlewares.py — 中间件
- spiders/
- init.py
- 项目名.py — 爬虫逻辑
scrapy.cfg
部署文件,所有的配置都要在这里部署,不然不会生效,这个文件强调的是部署(deploy) ```pythonAutomatically created by: scrapy startproject
#For more information about the [deploy] section see:
https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings] default = projectX.settings
[deploy]
url = http://localhost:6800/
project = projectX
<a name="WJzrQ"></a>### settings.py配置文件。配置项有很多,在文件头部有链接查看配置的完整说明。```python# -*- coding: utf-8 -*-# Scrapy settings for projectX project## For simplicity, this file contains only settings considered important or# commonly used. You can find more settings consulting the documentation:## https://docs.scrapy.org/en/latest/topics/settings.html# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlimport randomBOT_NAME = 'projectX'SPIDER_MODULES = ['projectX.spiders']NEWSPIDER_MODULE = 'projectX.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent#USER_AGENT = 'projectX (+http://www.yourdomain.com)'user_agent_list = ["Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50","Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0","Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko","Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)","Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)","Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)","Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1","Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1","Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11","Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"]USER_AGENT = random.choice(user_agent_list)# Obey robots.txt rulesROBOTSTXT_OBEY = True# Configure maximum concurrent requests performed by Scrapy (default: 16)#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docs#DOWNLOAD_DELAY = 3# The download delay setting will honor only one of:#CONCURRENT_REQUESTS_PER_DOMAIN = 16#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)#TELNETCONSOLE_ENABLED = False# Override the default request headers:# DEFAULT_REQUEST_HEADERS = {# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',# 'Accept-Language': 'en',# }# Enable or disable spider middlewares# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html# SPIDER_MIDDLEWARES = {# 'projectX.middlewares.ProjectxSpiderMiddleware': 543,# }# Enable or disable downloader middlewares# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html# DOWNLOADER_MIDDLEWARES = {# 'projectX.middlewares.ProjectxDownloaderMiddleware': 543,# }# Enable or disable extensions# See https://docs.scrapy.org/en/latest/topics/extensions.html# EXTENSIONS = {# 'scrapy.extensions.telnet.TelnetConsole': None,# }# Configure item pipelines# See https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = {'projectX.pipelines.ProjectxPipeline': 300,}# Enable and configure the AutoThrottle extension (disabled by default)# See https://docs.scrapy.org/en/latest/topics/autothrottle.html#AUTOTHROTTLE_ENABLED = True# The initial download delay#AUTOTHROTTLE_START_DELAY = 5# The maximum download delay to be set in case of high latencies#AUTOTHROTTLE_MAX_DELAY = 60# The average number of requests Scrapy should be sending in parallel to# each remote server#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0# Enable showing throttling stats for every response received:#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings#HTTPCACHE_ENABLED = True#HTTPCACHE_EXPIRATION_SECS = 0#HTTPCACHE_DIR = 'httpcache'#HTTPCACHE_IGNORE_HTTP_CODES = []#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
pipelines.py
提取非爬虫直接爬取数据时用到,就是复杂数据,比如获得下载链接还需要下载。
记得在settings中注册。
# -*- coding: utf-8 -*-# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlclass ProjectxPipeline:def process_item(self, item, spider):return item
middlewares.py
中间件,看上面架构图,理解其作用。
# -*- coding: utf-8 -*-# Define here the models for your spider middleware## See documentation in:# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlfrom scrapy import signalsclass ProjectxSpiderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the spider middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_spider_input(self, response, spider):# Called for each response that goes through the spider# middleware and into the spider.# Should return None or raise an exception.return Nonedef process_spider_output(self, response, result, spider):# Called with the results returned from the Spider, after# it has processed the response.# Must return an iterable of Request, dict or Item objects.for i in result:yield idef process_spider_exception(self, response, exception, spider):# Called when a spider or process_spider_input() method# (from other spider middleware) raises an exception.# Should return either None or an iterable of Request, dict# or Item objects.passdef process_start_requests(self, start_requests, spider):# Called with the start requests of the spider, and works# similarly to the process_spider_output() method, except# that it doesn’t have a response associated.# Must return only requests (not items).for r in start_requests:yield rdef spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)class ProjectxDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be calledreturn Nonedef process_response(self, request, response, spider):# Called with the response returned from the downloader.# Must either;# - return a Response object# - return a Request object# - or raise IgnoreRequestreturn responsedef process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpassdef spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
items.py
定义你爬取的数据的结构。
# -*- coding: utf-8 -*-# Define here the models for your scraped items## See documentation in:# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ProjectxItem(scrapy.Item):# define the fields for your item here like:name = scrapy.Field()# # 电影标题# title = scrapy.Field()# # 豆瓣评分# star = scrapy.Field()# # 主演信息# Staring = scrapy.Field()# # 豆瓣排名# rank = scrapy.Field()# # 描述# quote = scrapy.Field()# # 豆瓣详情页# url = scrapy.Field()
spiders/项目名.py
这个文件名是你创建时命名的。不一定是这个名字。
这是爬虫的爬取逻辑,包括如何起始url,提取页面逻辑等。
# -*- coding: utf-8 -*-import scrapyclass ExampleSpider(scrapy.Spider): # Scrapy.Spider类型爬虫# 标识蜘蛛。它在一个项目中必须是唯一的,也就是说,不能为不同的蜘蛛设置相同的名称。name = 'example'allowed_domains = ['example.com']# 启动请求方法的快捷方式# 数组形式# start_urls = ['http://example.com/']# 函數形式# 必须返回一个ITable of requests# (您可以返回一个请求列表或编写一个生成器函数),# 蜘蛛将从中开始爬行。随后的请求将从这些初始请求中依次生成。def start_requests(self):urls = ['http://quotes.toscrape.com/page/1/','http://quotes.toscrape.com/page/2/',]for url in urls:yield scrapy.Request(url=url, callback=self.parse)# 获取运行时命令行参数# url = 'http://quotes.toscrape.com/'# tag = getattr(self, 'tag', None)# if tag is not None:# url = url + 'tag/' +tag# yield scrapy.Request(url, self.parse)# 被调用时,每个初始URL完成下载后生成的 Response对象将会作为唯一的参数传递给该函数。# 该方法负责解析返回的数据(response data),# 提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。def parse(self, response):for quote in response.css('div.quote'):# 日志中输出yield {'text': quote.css('span.text::text').get(),'author': quote.xpath('span/small/text()').get(),}# 提取url方式一:发送Request# 最麻烦for next_page in response.css('li.next a::attr(href)'):# 可能是相对路径,所以要加这步next_page = response.urljoin(next_page)# 回调parse,递归爬取yield scrapy.Request(next_page, callback=self.parse)# 提取url方式二:response.follow(strHref)# for href in response.css('li.next a::attr(href)'):# yield response.follow(href, callback=self.parse)# 提取url方式三:response.follow(元素)# 最简洁# for a in response.css('li.next a'):# yield response.follow(a, callback=self.parse)
(五)运行项目
#运行quotes爬虫scrapy crawl quotes#存储爬取数据之json#当前目录下生成一个quotes.json文件,出于历史原因,scrapy会附加到给定的文件(append),而不是覆盖其内容。如果在第二次运行此命令两次之前不删除该文件,则最终会得到一个损坏的JSON文件。scrapy crawl quotes -o quotes.json#命令行传参:-a tag=fuck#它将传到爬虫逻辑的__init__方法中,变成爬虫的默认参数。scrapy crawl quotes -o quotes-humor.json -a tag=humor#存储爬取数据之JSON Lines#JSON Lines非常有用,类似于流,因为输出文件可以直接append而不会解析失败,另外每一条记录记录都是独立行方便处理大量数据。scrapy crawl quotes -o quotes.jl#上面可以应付直接存储直接爬取到的数据。#存储更复杂的数据比如图片视频就要用到Item Pipeline,#在pipelines.py中
(六)具体发生了什么?
Scrapy安排了 scrapy.Request 返回的对象 start_requests 蜘蛛的方法。在接收到每个响应时,它实例化 Response 对象并调用与请求关联的回调方法(在本例中,为 parse 方法)将响应作为参数传递。
(七)递归爬取
不能就爬取start_urls或者start_requests里面的几条链接,很可能是要爬取网站下所有。那就需要在爬取的网页中提取链接。
import scrapyclass QuotesSpider(scrapy.Spider):name = "quotes"start_urls = ['http://quotes.toscrape.com/page/1/',]def parse(self, response):for quote in response.css('div.quote'):yield {'text': quote.css('span.text::text').get(),'author': quote.css('small.author::text').get(),'tags': quote.css('div.tags a.tag::text').getall(),}#提取页面中的链接for a in response.css('li.next a'):yield response.follow(a, callback=self.parse)#response.follow,既可以接收string参数也可以接收元素类型。#注意,下面这样是错误的,因为css返回的是列表response.follow(response.css('li.next a'), callback=self.parse)#但是下面这样,也是可以的。response.follow(response.css('li.next a')[0], callback=self.parse)
(八)调试抓取代码
爬虫一运行就停不下来,肯定不能正常调试,Scrapy Shell就可以通过命令行方式执行一次抓取,这样让调试就变得非常简单了。
三、Scrapy Shell教程
可交互的shell,可以输入代码调试抓取代码,无需运行爬虫,即可调试抓取代码,非常有用。
(一)配置Shell
1、方法一
配置环境变量:SCRAPY_PYTHON_SHELL,路径
Python\Lib\site-packages\scrapyPython\Lib\site-packages\scrapy\commands#两个下面都有shell.py不知道是哪个
2、方法二
在scrapy.cfg中定义
[settings]shell = bpython
(二)抓取一次数据
#抓取网页链接#注意要带上引号,windows上要用双引号,unix系统要用单引号。scrapy shell 'http://quotes.toscrape.com/page/1/'#抓取本地文件,如果是本地文件时,注意shell先识别URL再识别路径。# UNIX-stylescrapy shell ./path/to/file.htmlscrapy shell ../other/path/to/file.htmlscrapy shell /absolute/path/to/file.html#File URIscrapy shell file:///absolute/path/to/file.htmlscrapy shell index.html#不能正常运行,因为index.html被认为是url,html是相当于com
结果如下:
[ ... Scrapy log here ... ]2016-09-19 12:09:27 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)[s] Available Scrapy objects:[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)[s] crawler <scrapy.crawler.Crawler object at 0x7fa91d888c90>[s] item {}[s] request <GET http://quotes.toscrape.com/page/1/>[s] response <200 http://quotes.toscrape.com/page/1/>[s] settings <scrapy.settings.Settings object at 0x7fa91d888c10>[s] spider <DefaultSpider 'default' at 0x7fa91c8af990>[s] Useful shortcuts:[s] shelp() Shell help (print this help)[s] fetch(req_or_url) Fetch request (or URL) and update local objects[s] view(response) View response in a browser>>>
(三)使用css抽取数据
#返回的是[]形式,是列表,可能有多个>>> response.css('title')[<Selector xpath='descendant-or-self::title' data='<title>Quotes to Scrape</title>'>]#提取title的文本,注意返回的是列表>>> response.css('title::text').getall()['Quotes to Scrape']#提取的是title整个元素,注意是列表>>> response.css('title').getall()['<title>Quotes to Scrape</title>']#提取列表第一个title的文本>>> response.css('title::text').get()'Quotes to Scrape'#同上,但是如果一个没有[0]就会报错,不建议>>> response.css('title::text')[0].get()'Quotes to Scrape'>>> response.css('title::text').get()'Quotes to Scrape'#正则表达是提取>>> response.css('title::text').re(r'Quotes.*')['Quotes to Scrape']#正则表达是提取>>> response.css('title::text').re(r'Q\w+')['Quotes']#正则表达是提取>>> response.css('title::text').re(r'(\w+) to (\w+)')['Quotes', 'Scrape']
(四)Selector Gadget 获取CSS
很好的工具,可以快速找到视觉上选中的元素的CSS选择器,它可以在许多浏览器中使用。
(五)除了CSS,也可以XPath
css底层其实就是转换成xpath,但是css明显要更流行。
>>> response.xpath('//title')[<Selector xpath='//title' data='<title>Quotes to Scrape</title>'>]>>> response.xpath('//title/text()').get()'Quotes to Scrape'
四、Shell实践
Http://quotes.toscrape.com的HTML结构如下:
<div class="quote"><span class="text">“The world as we have created it is a process of ourthinking. It cannot be changed without changing our thinking.”</span><span>by <small class="author">Albert Einstein</small><a href="/author/Albert-Einstein">(about)</a></span><div class="tags">Tags:<a class="tag" href="/tag/change/page/1/">change</a><a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a><a class="tag" href="/tag/thinking/page/1/">thinking</a><a class="tag" href="/tag/world/page/1/">world</a></div></div>
scrapy shell 'http://quotes.toscrape.com'>>> response.css("div.quote")>>> quote = response.css("div.quote")[0]>>> text = quote.css("span.text::text").get()>>> text'“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'>>> author = quote.css("small.author::text").get()>>> author'Albert Einstein'>>> tags = quote.css("div.tags a.tag::text").getall()>>> tags['change', 'deep-thoughts', 'thinking', 'world']>>> for quote in response.css("div.quote"):... text = quote.css("span.text::text").get()... author = quote.css("small.author::text").get()... tags = quote.css("div.tags a.tag::text").getall()... print(dict(text=text, author=author, tags=tags)){'tags': ['change', 'deep-thoughts', 'thinking', 'world'], 'author': 'Albert Einstein', 'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”'}{'tags': ['abilities', 'choices'], 'author': 'J.K. Rowling', 'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”'}... a few more of these, omitted for brevity>>>

若有收获,就点个赞吧
0 人点赞
