1、概念
节点叫顶点vertex,顶点之间的连线叫边edge。
树、线性表是形式受限的图。
图是数据结构的最通用的形式。
G = ( V, E ),V是顶点集合,E是边集合。
|V|,|E|:顶点数、边数。
|E|:0 ~ O( |V| )。
包含所有可能的边,叫完全图。
有向图、无向图、标号图、带权图。
路径path,路径长度length = 边数。
简单路径:路径顶点各不相同。
回路:路径首尾是同一个节点,路径长度>=3。
密集图:边数较多的图。
稀疏图:边数较少的图。
简单回路:简单路径的回路。全部概念如下图: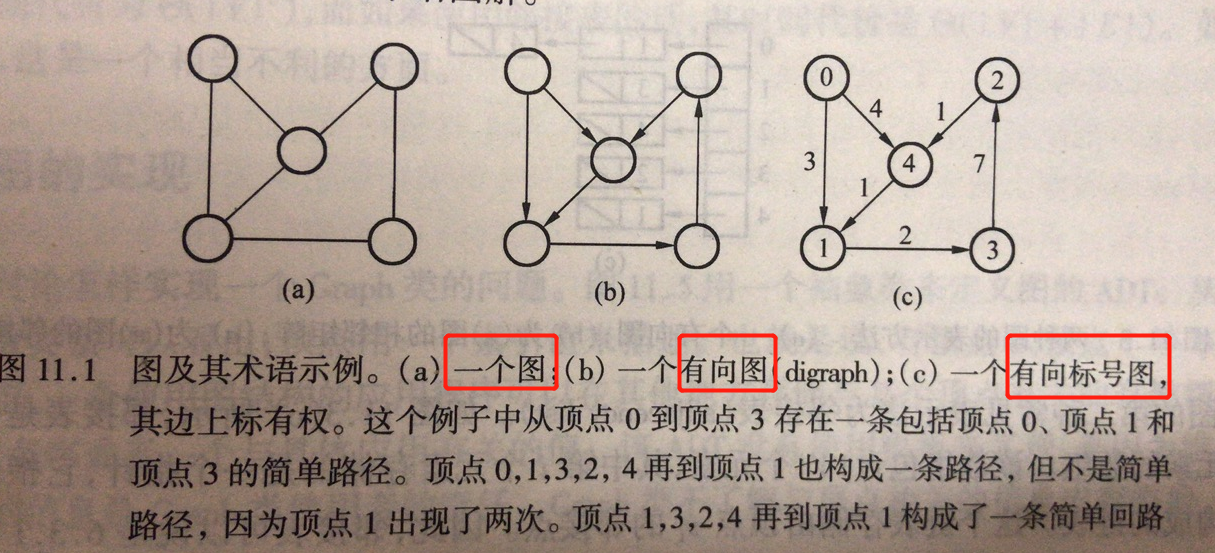
连通的无向图:每个顶点到任意其他顶点都有路径。
连通分量:无向图的最大连通子图。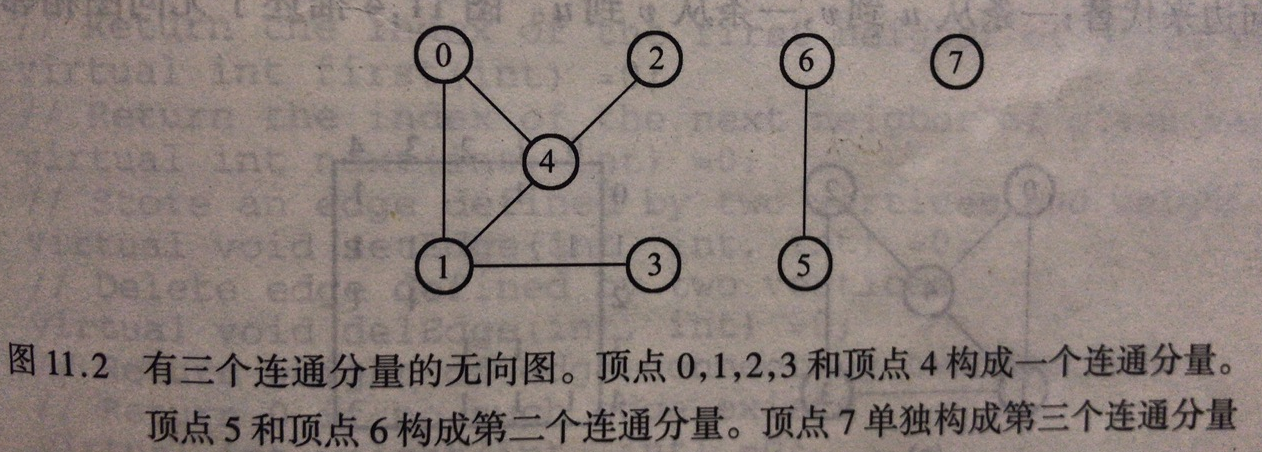
(有向)无环图:不带回路的(有向)图。
自由树:不带简单回路的连通无向图。连通且有|V| - 1条边的图。
2、图的表示方法
相邻矩阵:两个顶点边的权值,没有边返回0,所以!0表示顶点间有边相连。
领接表:链表存储边(Edge),边存储指向下一个的顶点和边权值。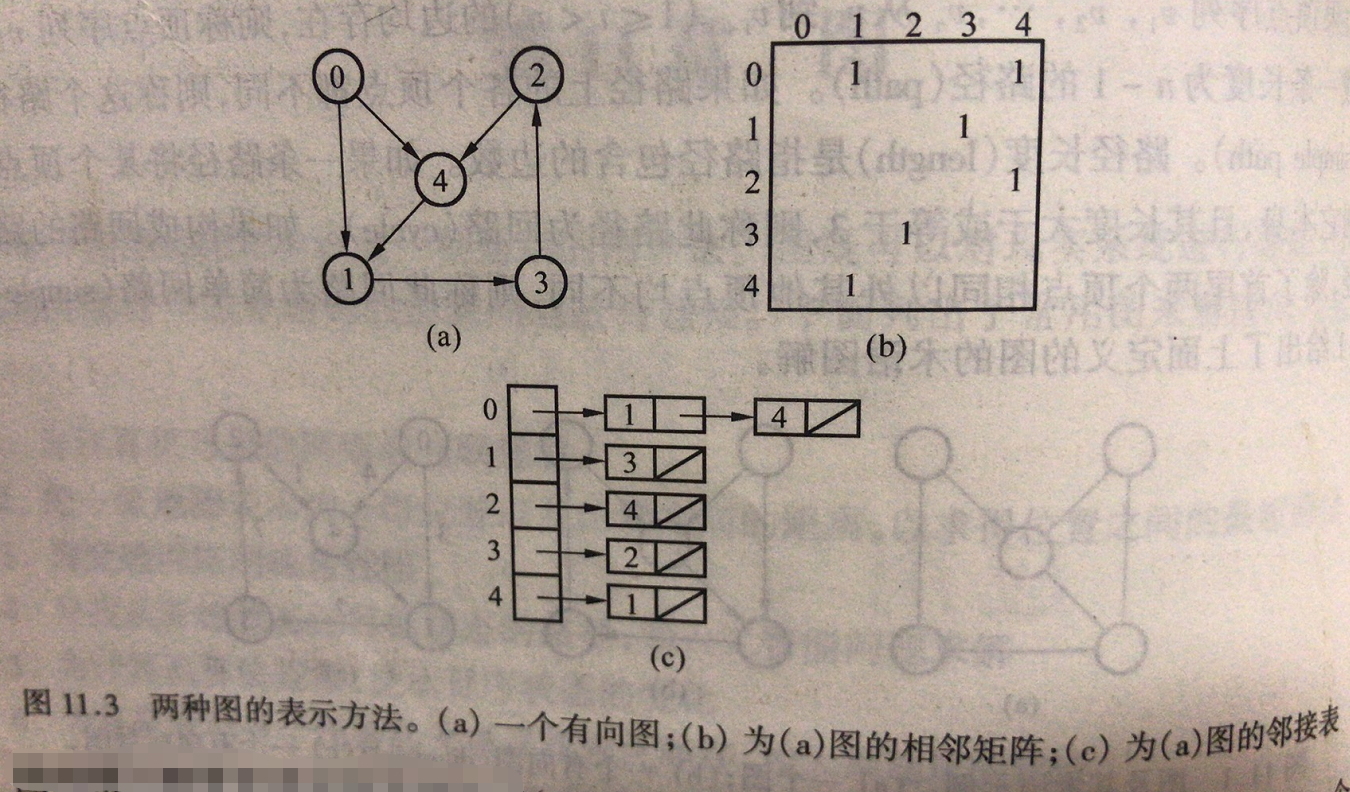
3、图ADT(抽象基类)
class Graph{public:virtual int n() = 0; //顶点数virtual int e() = 0; //边数virtual int first(int v) = 0; //顶点v相邻第一个邻居顶点virtual int next(int v, int v_n) = 0; //返回顶点v的下一相连顶点//比如0-1-2-3-4-5:顶点都相连//next(0, 3) = 4;//next(0, 5) = 6;即到达尾部,返回顶点数。virtual void setEdge(int v1, int v2, int weight) = 0; //存储边(顶点v1、v2,权重weight)//可以以此创建图virtual void delEdge(int v1, int v2) = 0; //删除边(v1, v2)virtual int weight(int v1, int v2) = 0; //边(v1, v2)的权重,如果不存在返回0virtual int getMark(int v1) = 0; //返回v1的标号值virtual void setMark(int v1, int value) = 0; //设置顶点v1的标号值}
图的实现(矩阵)
//边edge的类//为什么只存储了一点顶点和权重?//因为这些信息已经足够遍历图了。想象一下,初始提供一个顶点。class Edge{public://vertex:表示指向的顶点。//weight:表示与vertex相连边的权重int vertex, weight;Edge(){ vertex = -1; weight = -1; }Edge(int v, int w){ vertex = v; weight = w; }}class GraphMatrix : public Graph{private:int numVertex, numEdge; //顶点数,边数int** matrix; //矩阵数组:下标值为顶点索引,值为权重int* mark; //顶点标记,是否访问过//函数接口声明public:GraphMatrix(int numVert);~GraphMatrix();int n();int e();int first(int v);int next(int v1, int v2);void setEdge(int v1, int v2, int wgt);void delEdge(int v1, int v2);int weight(int v1, int v2);int getMark(int v);void setMark(int v, int val);//函数定义public:GraphMatrix(int numVert){int i, j;numVertex = numVert;numEdge = 0;mark = new int[numVert];for(i = 0; i < numVertex; i++) mark[i] = UNVISITED;maxtrix = (int**)new int*[numVertex];for(i = 0; i < numVertex; i++) *(maxtrix+i) = new int[numVert];for(i = 0;i < numVertex; i++)for(int j = 0;j < numVertex;j++)matrix[i][j] = 0;}~GraphMatrix(){delete[] mark;for(int i = 0;i < numVertex; i++) delete[] matrix[i];delete[] maxtrix;}int n(){ return numVertex; }int e(){ return numEdge; }int first(int v){int i;for(i = 0;i < numVertex; i++) if(matrixp[v][i] != 0) return i;return i;}int next(int v1, int v2){int i;for(i = v2 + 1;i < numVertex; i++) if(matrix[v1][i] != 0) return i;return i;}void setEdge(int v1, int v2, int wgt){Assert(wgt > 0, "Illegal weight value.");if(matrix[v1][v2] == 0) numEdge++;matrix[v1][v2] = wgt;}void delEdge(int v1, int v2){if(matrix[v1][v2] != 0) numEdge--;matrix[v1][v2] = 0;}int weight(int v1, int v2){ return matrix[v1][v2]; }int getMark(int v){ return mark[v]; }void setMark(int v, int val){ mark[v] = val; }}
图的实现(邻接表)
class GraphLink : public Graph{private:int numVertex, numEdge;List<Edge>** vertex; //注意,下标是顶点索引,链表项是与它相连的边。int *mark; //顶点标记,是否访问过public:GraphLink(int numVert){int i, j;numVertex = numVert;numEdge = 0;mark = new int[numVert];for(i = 0; i < numVertex; i++) mark[i] = UNVISITED;vertex = (List<Edge>**) new List<Edge>*[numVertex];for(i = 0; i < numVertex; i++)vertex[i] = new LList<Edge>();}~GraphLink(){delete[] mark;for(int i = 0;i < numVertex; i++) delete[] vertex[i];delete[] vertex;}int n(){ return numVertex; }int e(){ return numEdge; }int first(int v){ //也就是第一条边指向的顶点Edge it;vertext[v]->setStart();if(vertext[v]->getValue(it)) return it.vertex;else return numVertex;}int next(int v1, int v2){Edge it;vertex[v1]->getValue(it);if(it.vertex == v2) vertex[v1]->next();else{//循环直到找到v2顶点vertex[v1]->setStart();while(vertext[v1]->getValue(it) && (it.vertex <= v2))vertex[v1]->next();}if(vertex[v1]->getValue(it)) return it.vertex;else return numVertex;}void setEdge(int v1, int v2, int wgt){Assert(wgt > 0, "Illegal weight value.");Edge it(v2, wgt);Edge curr;vertex[v1]->getValue(curr);if(curr.vertex != v2){//循环直到找到顶点v2for(vertex[v1]->setStart(); vertex[v1]->getValue(curr);vertex[v1]->next())if(curr.vertex >= v2) break;}if(curr.vertex == v2) vertex[v1]->remove(curr);else numEdge++;vertex[v1]->insert(it);}void delEdge(int v1, int v2){Edge curr;vertex[v1]->getValue(curr);if(curr.vertex != v2)//循环直到找到顶点v2for(vertex[v1]->setStart();vertex[v1]->getValue(curr);vertex[v1]->next())if(curr.vertex >= v2) break;if(curr.vertex == v2){vertex[v1]->remove(curr);numEdge--;}}int weight(int v1, int v2){Edge curr;vertex[v1]->getValue(curr);if(curr.vertex != v2)//循环直到找到顶点v2for(vertex[v1]->setStart();vertex[v1]->getValue(curr);vertex[v1]->next())if(curr.vertex >= v2) break;if(curr.vertex == v2) return curr.weight;else return 0;}int getMark(int v){ return mark[v]; }void setMark(int v, int val){ mark[v] = val; }}
4、图的周游(遍历)
一次遍历可能无法全部遍历到,一个数组保存所有节点访问状态,遍历过的就标记。
每个节点vertex执行一次遍历算法:
vertex已被访问,则无需执行,
vertex已被访问,则执行遍历。
void graphTraverse(const Graph* G){for(v = 0;v < G->n(); v++)G->setMark(v, UNVISITED);for(v = 0;v < G->n();v++)if(G->getMark(v) != UNVISITED)doTraverse(G, v); //从图G的v顶点开始遍历。}//深度优先遍历//递归调用先天特性 就符合 深度优先的特点void DFS(Graph* G, int v){// PreVisit(G, v); // 访问节点前做点啥G->setMark(v, UNVISITED);for(int w = G->first(v); w < G->n(); w = G->next(v, w))if(G->getMark(w) == UNVISITED) DFS(G, w);// PostVisit(G, v); // 访问节点后做点啥}//广度优先遍历:先访问直接相连的点。//需要用一个队列来实现。void BFS(Graph* G, int start, Queue<int>* Q){int v, w;q->enqueue(start);G->setMakr(start, VISITED);while(Q->lengt()!=0)Q->dequeue(v);// PreVisit(G, v); //访问节点前做点啥for(int w = G->first(v); w < G->n(); w = G->next(v, w))if(G->getMark(w) == UNVISITED) BFS(G, w);// PostVisit(G, v); //访问节点后做点啥}
5、拓扑排序
优先访问顶点的“所有前顶点”规则的遍历。
有向图DAG才有拓扑排序。
比如工作任务必须先执行全部的先决任务(即“入边”或者是前顶点)。
//拓扑排序算法(PostVisit版深度优先)//注意最终输出的是“逆”拓扑排序!!还要再把结果序列颠倒一下。//所以以下不是完整的拓扑排序!!!!void topsort(Graph* G){int i;for(i = 0;i < G->n(); i++) G->setMark(i, UNVISITED);for(i = 0;i < G->n(); i++) //可能存在孤立的顶点,所以每个都要进行一次拓扑。if(G->getMark(i) == UNVISITED)tophelp(G, i);}void tophelp(Graph* G, int v){G->setMark(v, VISITED);//printout(v); //注意!不是在previsit打印,//如果是在这里打印,倒序之后就不符合拓扑排序。for(int w = G->first(v); w < G->n(); w = G->next(v, w))if(G->getMark(w) == UNVISITED)tophelp(G, w);printout(v); //必须在postvisit打印。}//基于队列的拓扑排序算法//算法原理:// 1、保存每个顶点的“前”顶点数包括:// 直接“前”顶点// “间接前”顶点,如a->b->c>d,ab是d的间接前顶点。// 其实就是所有先决条件(任务)// 2、没“前”顶点的顶点才能入队。// 3、出队时,后续所有相连顶点的顶点数-1:// 相当于执行当前任务,// 也算是为其他相关顶点减了个先决“任务”void topsort(Graph* G, Queue<int>* Q){int Count[G->n()];int v, w;for(v = 0; v < G->n(); v++) Count[v] = 0;for(v = 0; v < G->n(); v++)for(w = G->first(v); w < G->n(); w = G->next(v, w))Count[w]++; //上面注释第1步:记录“前”顶点数for(v = 0; v < G->n(); v++)if(Count[v] == 0)Q->enqueue(v); //上面注释第2步:while(Q->length() != 0){Q->dequeue(v); //上面注释第3步:printout(v);for(w = G->first(v); w < G->n(); w = G->next(v, w)){Count[w]--; //上面注释第3步if(Count[w] == 0) Q->enqueue(w); //上面注释第2步}}}
6、(单源)最短路径原则
给定一个顶点,找出到所有其他顶点的最短路径。
如下图,求A到D的最短路径。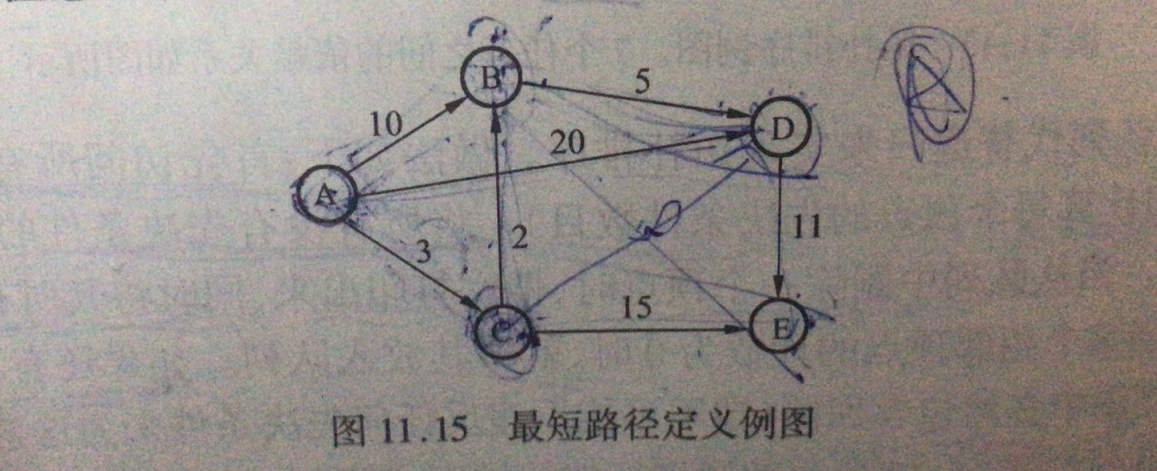
Dijkstra算法
算法思想:
下面是伪数学表达式,不是严格成立,但符合大脑思考方式。
d(s, vn+j) = d(s, v) + d(v, v)
v图中非s顶点。
d**(s, v):顶点 v 距离 顶点 s 的“目前”最短距离。
d(v, v):顶点v到直接相连的顶点v的距离(边权)。
从实际实现上,d只能算是目前掌握到的“目前最短距离”,我们必须顶点遍历完才是“真正最短距离”**。所以遍历的过程,最短距离不断接近准确值。
这里也反应了一个问题,就是求顶点v到顶点s的最短路径,其实是求所有顶点到s的最短路径。
算法复杂度:O( **|V|2 )**
//寻找顶点s到所有其他顶点的最短距离//D:保存每个顶点到s顶点的“目前”最短距离//s:目标顶点s//初始状态,D[s] = 0,其他都 = INFINITY。void Dijkstra(Graph* G, int* D, int s){int i;int v; //在D中,s的最近顶点int w; //w是v能next到的顶点for(i = 0; i < G->n(); i++){v = minVertex(G, D); //找出离s“最近”顶点v。//顶点v与s是“目前”不相连的,//就是目前还没有距离信息,还没遍历到。if(D[v] == INFINITY) return;G->setMark(v, VISITED); //避免重复访问//算法核心:根据目前的D(目前最短距离)for(w = G->first(v); w < G->n(); w = G->next(v, w))//s到v的目前最短距离 + v与顶点w相连的权边 < s到w的目前最短距离。if(D[w] > (D[v] + G->weight(v, w)))//更新s到w的最短距离为:s到v最短距离 + v到w的权边D[w] = D[v] + G->weight(v, w);}}//找出D中的最小值,而且是未访问的节点。int minVertex(Graph* G, int* D){int i, v;for(i = 0; i < G->n(); i++)if(G->getMark(i) == UNVISITED){v = i;break;}for(i++; i < G->n();i++)if((G->getMark(i) == UNVISITED) && (D[i] < D[v]))v = i;return v;}
Dijkstra算法(优先队列)
核心思想相同,但是用了最小值堆来找最短距离顶点。
算法复杂度:O( (|V| + |E|) * log |E| )
密集图时,复杂度接近:O( |V|**2* log |E| )
//保存每个顶点的索引和class DijkElem{public:int vertex, distance;DijkElem(){ vertex = -1; distance = -1; }DijkElem(int v, int d){ vertex = v; distance = d; }}//返回void Dijkstra( Graph* G, int* D, int s ){int i, v, w;DijkElem temp(s, 0);DijkElem E[G->e()];E[0] = temp;minheap<DijkElem, DDComp> H(E, 1, G->e()); //堆目前有1个元素,堆总空间G->e()//保存未被访问的顶点,各节点就是目前到s//最短距离的顶点for(i = 0; i < G->n(); i++){do{if(!H.removemin(temp)) //取出根节点,也就是最短值节点return; //堆没有节点了v = temp.vertex;}while(G->getMark(v) == VISITED);G->setMark(v, VISITED);if(D[v] == INFINITY) return;for(w = G->first(); w < G->n(); w = G->next(v, w))if(D[w] > (D[v] + G->weight(v, w))){D[w] = D[v] + G->weight(v, w);temp.distance = D[w];temp.vertex = w;H.insert(temp);}}}
算法分析
核心思想相同,但查找目前最短距离顶点的上各做了“取舍”。
minvertex是扫描数组,找的更慢点但找的稳定,不怕多,
minheap是最小值堆,是找的更快点但找的不稳定,多了代价就大。
minvertex:算法复杂度:O( **|V|2 )
minheap: 算法复杂度:O( (|V| + |E|) log |E| )*
边数过多时(密集图):
minvertex:算法复杂度:O( **|V|2 )
minheap: 算法复杂度:O( |V|2 * log |E| )
7、双源最短路径
找每对顶点的最短长度路径。
复杂度:O(**|V|**)**
密集图最好选择,较容易实现。
void Floyd(Graph* G){int D[G->n()][G->n()];for(int i = 0; i < G->n(); i++)for(int j = 0; j < G->n(); j++)D[i][j] = G->weight(i, j) //初始化为任意两点之间的权重。for(int k = 0; k < G->n(); k++)for(int i = 0; i < G->n(); i++)for(int j = 0; j < G->n(); j++)if(D[i][j] > (D[i][k] + D[k][j]))D[i][j] = D[i][k] + D[k][j];}
8、最小支撑树MST
minimum-cost spanning tree。
数学定义:G是连通无向图,MST是下图中的一个:包含所有顶点和部分边的连通图。所有边之和是所有这些图中最小的。
加深理解:把所有城市连在一起的,路长度最小的路线。
没有回路,所以是|V| - 1条边的树结构。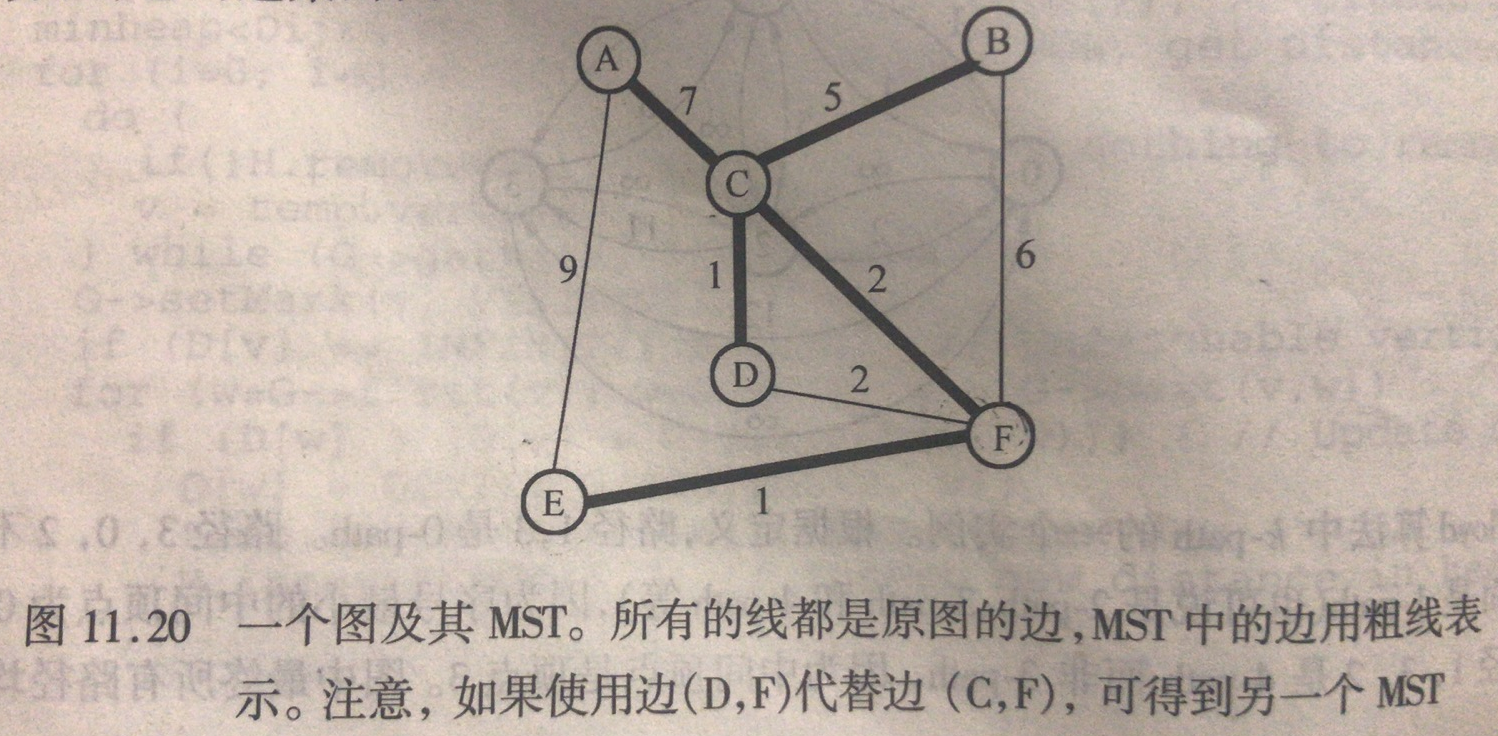
求最小支撑树:Prim算法
0、初始顶点N
1、找出N的最小权边的顶点N
2、找出与N、N相连的最小权边的点N
3、……
4、找出与N、……、N相连的最小权边N
//D:保存与各个索引顶点的相连的最小权边// 其实D[s] = 0,其他 = INFINITY//s:起始顶点//类似最短路径算法。void Prim(Graph* G, int* D, int s){int V[G->n()]; //V存储MST树节点,V[v]=w,顶点v和w直接相连。int i, w;for(i = 0; i < G->n(); i++){int v = minVertex(G, D);G->setMark(v, VISITED);if(v != s) AddEdgetToMST(V[v], v);if(D[v] == INFINITY) return;for(w = G->first(v); w < G->n(); w = G->next(v, w))if(D[w] > G->weight(v, w)){ //w当前保存的最小权边 比vw边更大,替换掉D[w] = G->weight(v, w); //v,next到w的权最小V[w] = v; //w顶点来来源是v。}}}//使用优先队列的Prim//类似最短路径算法的优先队列。void Prim(Graph* G, int* D, int s){int i, v, w;int V[G->n()];DijkElem temp;DijkElem E[G->e()];temp.distance = 0;temp.vertex = s;E[0] = temp;minheap<DijkElem, DDComp> H(E, 1, G->e());for(i = 0; i < G->n(); i++){do{if(!H.removemin(temp)) return;v = temp.vertex;}while(G->getMark(v) == VISITED);G->setMark(v, VISITED);if(v != s) AddEdgetToMST(V[v], v);if(D[v] == INFINITY) return;for(w = G->first(v); w < G->n(); w = G->next(v, w))if(D[w] > G->weight(v, w)){D[w] = G->weight(v, w);V[w] = v;temp.distance = D[w];temp.vertex = w;H.insert(temp);}}}
求最小支撑树:Kruskal算法
算法复杂度:
最差O(**|E| log |E|**)
一般O(**|V| log |E|**)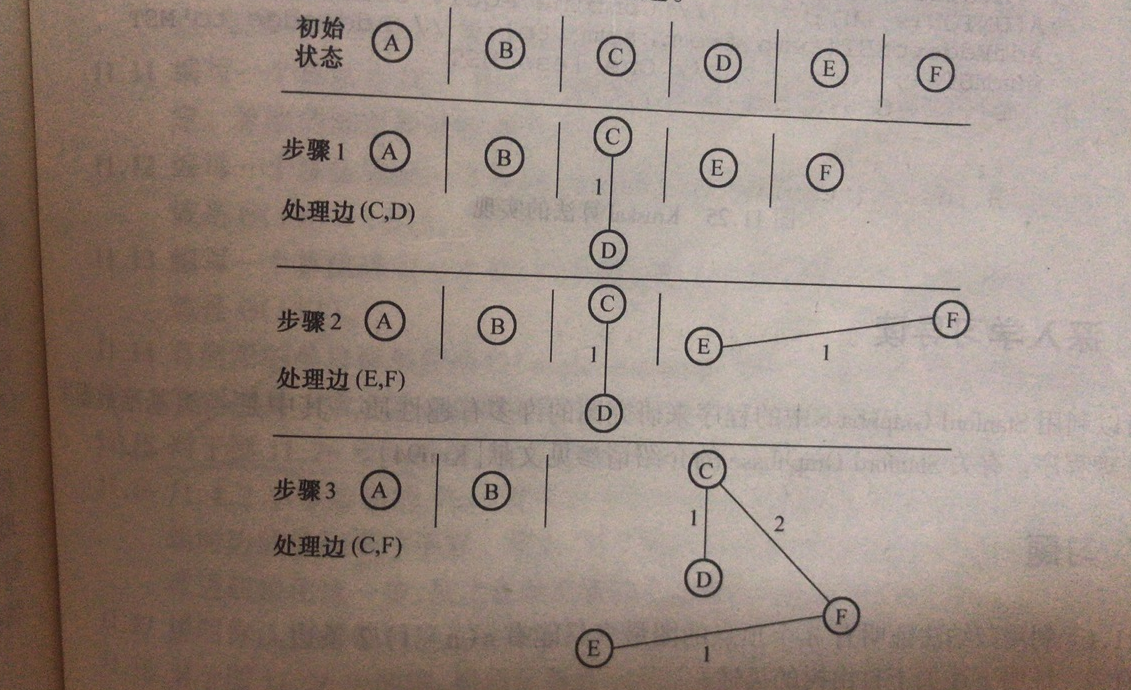
1、将所有顶点分为|V|个等价类。(UNION/FIND树)
2、优先处理权最小的边,边把两个等价类相连,则合并等价类
3、重复2步骤。
4、最后只剩一个等价类。

若有收获,就点个赞吧
0 人点赞
