一、介绍
工作流调度的可视化,主要是将任务的依赖关系展示出来,帮助用户尽快的发现和定位问题。面对业务数据量暴增(千万级)的情景下,如何从用户视角更好的展示调度关系,成为工作流调度可视化的重点和难点。
针对上述问题,我们从图渲染性能、布局以及交互三个方面,优化了工作流调度的可视化展示。
- 性能优化:基于新版G6,解决渲染层的性能;通过算法优化,解决业务数据处理的性能;
- 布局创新:结合Dagre和网格布局算法,实现Dagre+变种网格的子图布局方案;
-
二、业务背景
1. 业务介绍
工作流调度,意在通过上下游的设置,将不同的任务编排成一个DAG,从而满足处理过程中相互依赖的需求。工作流调度的可视化即需要将编排的DAG、以及DAG中节点的信息可视化的展示出来。
在DataWorks运维中心的业务中,DAG中需要包含的业务信息如下。 节点。包含名称、状态、实例序列、类型、跨项目、是否关联报警。
- 边。包含跨region关系、自依赖关系以及check流程关系。
- 工具栏。节点搜索功能。
- 信息卡片。展示更多节点的信息和操作。
节点详情。展示节点的全量信息,包括基本信息、运行日志和操作日志等。
2. 业务特征
DataWorks工作流的DAG图有以下三个特点:
数据量大。峰值情况达到 百万级别。
- 同层节点数多。峰值情况达到 十万级别。
- 关系复杂。关系数峰值达到 千万级别 。平均是节点数的3倍。
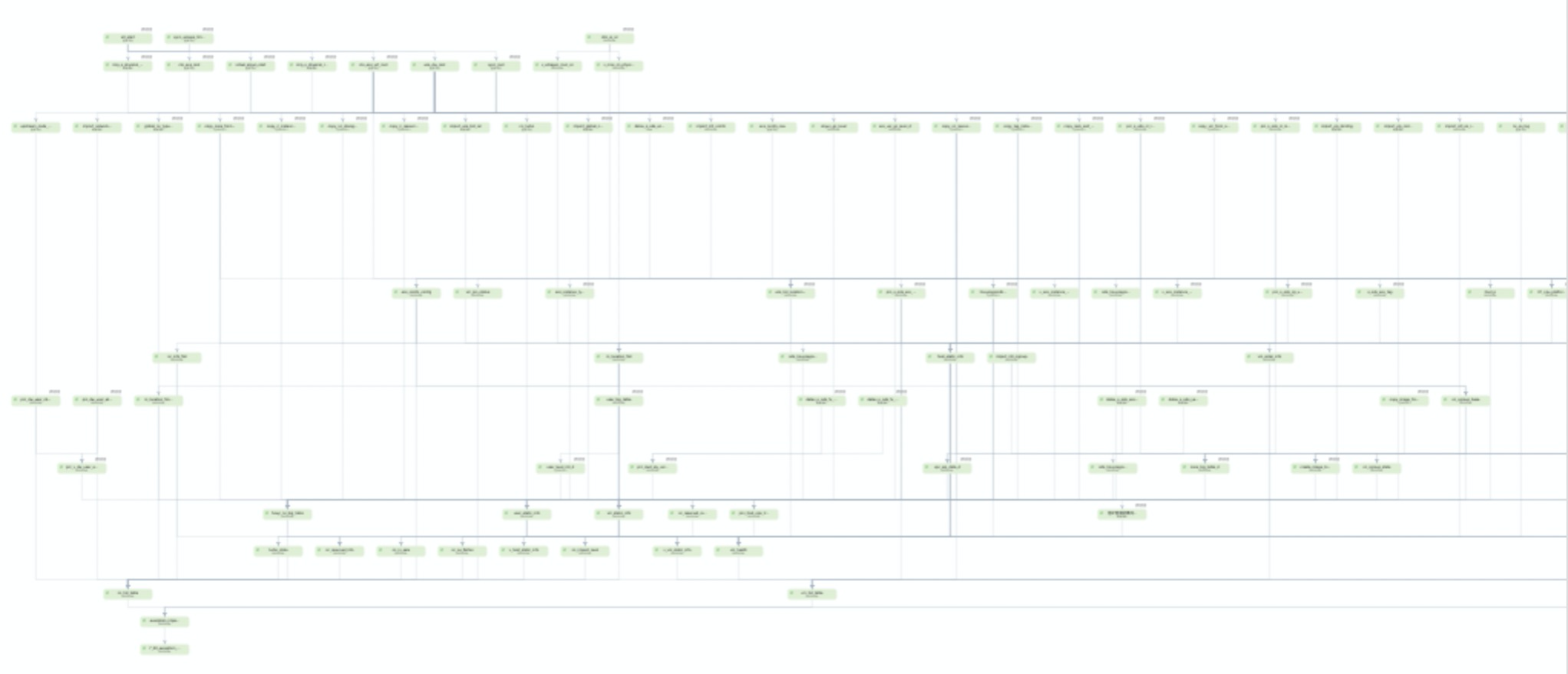
三、当前痛点
随着集团内数据业务的暴增,这张DAG越来越大,截止2020年,集团内的调度实例数已达千万级别。在如此大数据量的可视化展示中,遇到的挑战除了性能问题,还有就是如何将如此多的数据通过合理的方式,向用户传达其关心的信息。
遇到的具体问题和挑战主要包括以下三个方面:
1. 性能问题
由于数据处理的复杂以及底层引擎渲染的瓶颈,经常导致用户浏览器崩溃卡死。目前瓶颈数据如下:
- 前端瓶颈:之前DAG最多只能展示2000节点,超过2000后会直接导致浏览器崩溃。其中,底层依赖的G6引擎,渲染瓶颈是10000个图元,我们的业务场景中一个节点对应6个图元,所以节点数的瓶颈是10000/6=1666。
- 后端瓶颈:接口一次最多返回1w节点,主要来源是数据库和内存压力。
2. 布局问题
布局问题主要体现在以下两个方面。2.1 依赖关系不清晰
当依赖关系复杂时,用户无法从现有的图中清晰的看到节点的依赖关系。
如下图中,图a中展示的信息是ecs_dw_root以及rc_location_firs两个节点,均为impl_pet_plan以及exception_impact的上游节点。然而真实的依赖关系,如图b,rc_location_firs与impl_pet_plan以及exception_impact,并无依赖关系。
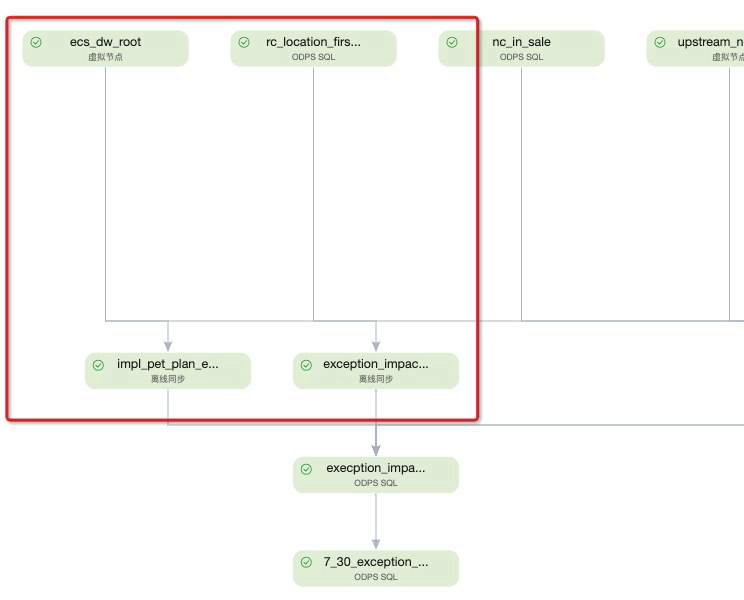
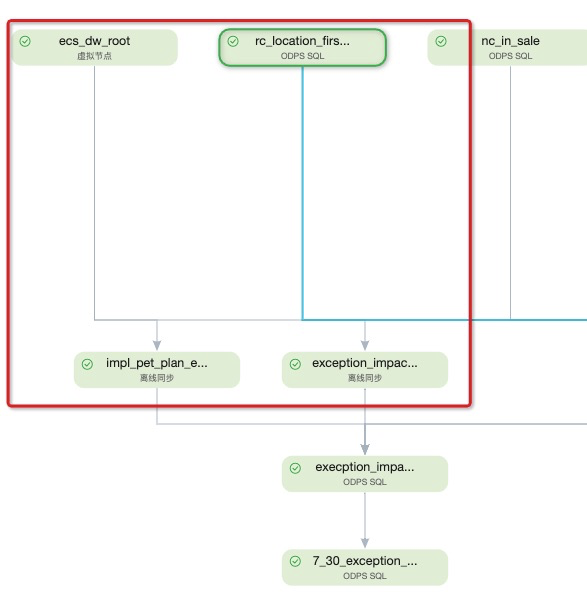
2.2 同层节点数多
业务特性,导致同层节点数可能非常多,往往会出现图c所展示的情况。用户无法一屏看到节点的所有下游关系,往往需要通过左右拖拽才能看到其他节点信息。
3. 缺失分析能力
可视化本身要解决的问题,就是将数据中展示的信息用更容易被人理解的形式传达给用户。回到工作流调度DAG本身的业务来说,其需要传达给用户的,主要有以下内容:
- 关系展示:以用户关心的节点为中心,展示该节点的上下游依赖。
- 上游分析:当节点运行被阻塞时,展示阻塞链路的原因和解法。
- 下游影响:针对某个节点,分析其下游影响面。
然而现在的可视化方案,并不能很好的传达以上的信息。如下图中,如何帮助用户快速定位graph_edge_inst节点的阻塞源头。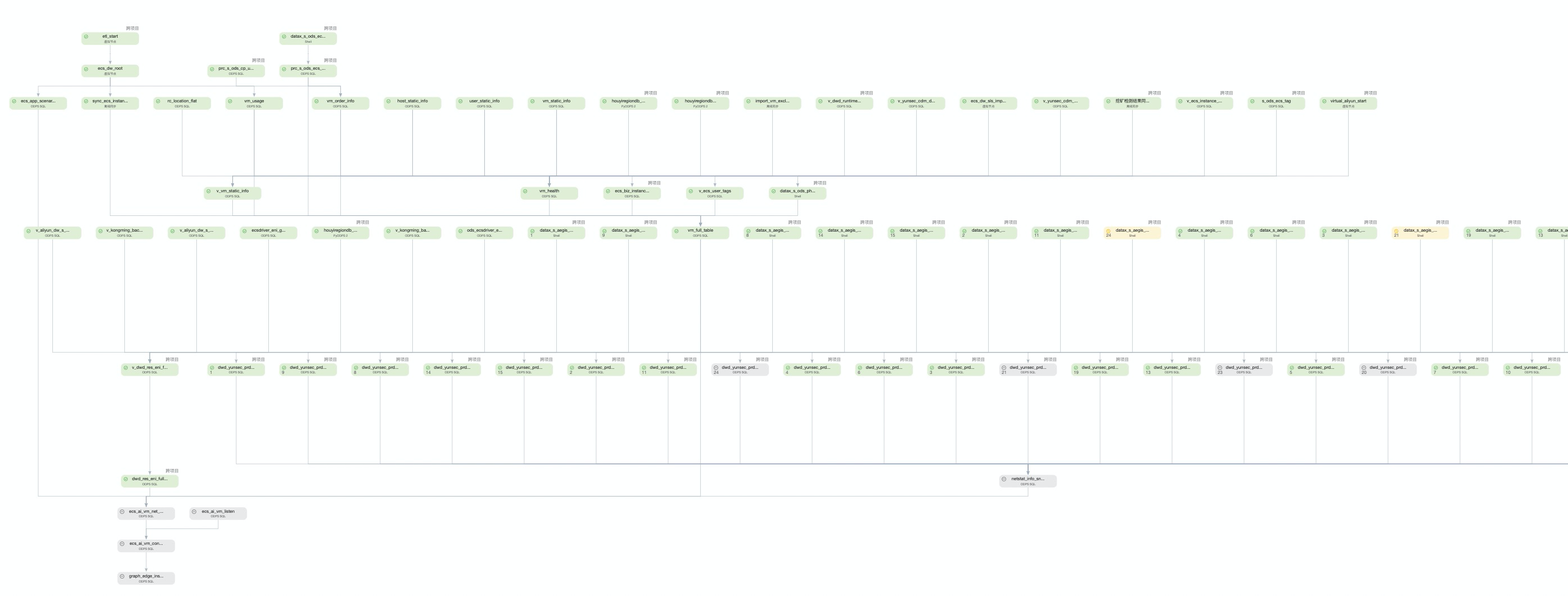
四、解决方案
1. 图元素设计
如业务介绍中描述的DAG元素中需要表达的业务信息,最终的设计样式如下:
1.1 节点
节点根据业务特性,需要分为两个类型:任务和实例。
任务:用户通常关心以下信息,任务名称、任务类型、任务是否跨项目依赖。
实例:用户通常关心以下信息,名称、实例状态、实例序列、任务类型、是否跨项目依赖、是否配置dqc校验规
则。
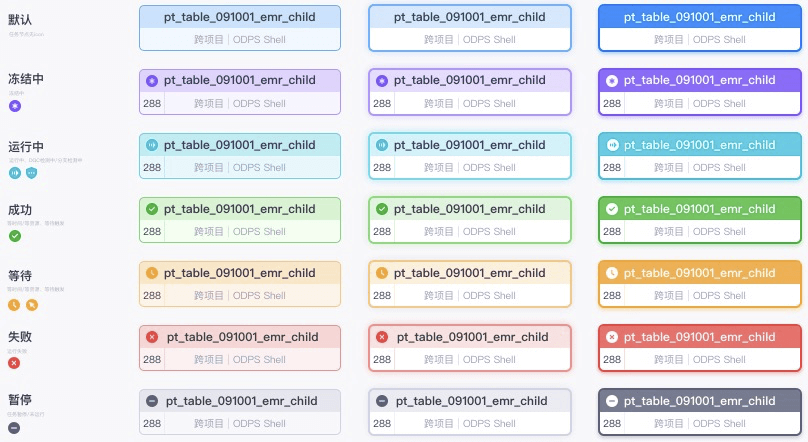
1.2 边
相对节点信息而言,边上展示的信息相对简单。
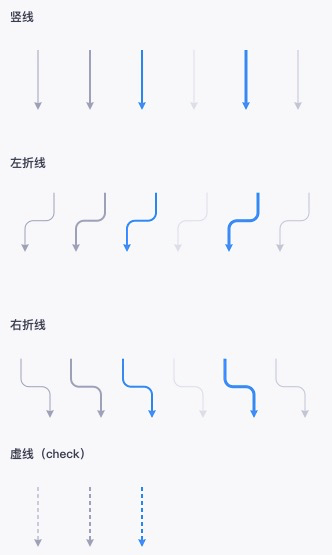
1.3 工具栏
工具栏中主要提供常用的图操作和一些基本的分析工具,包括:聚合工具、节点搜索、刷新、放大/缩小、视图切换等。
1.4 信息卡片
单击节点,触发信息卡片,将其作为一种辅助展示形式,用于展示更多的节点信息。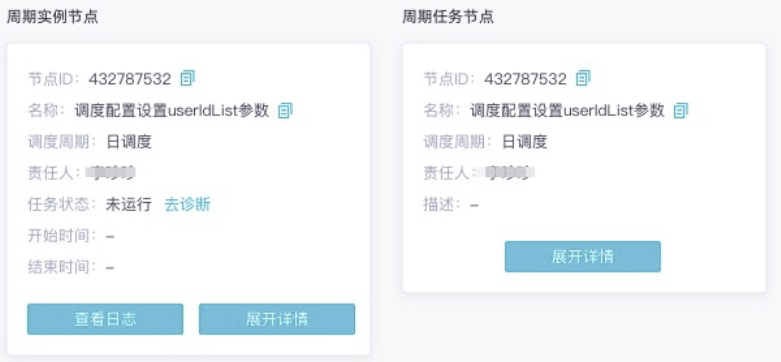
1.5 节点详情
双击节点,触发节点详情面板,用于展示节点的全量信息。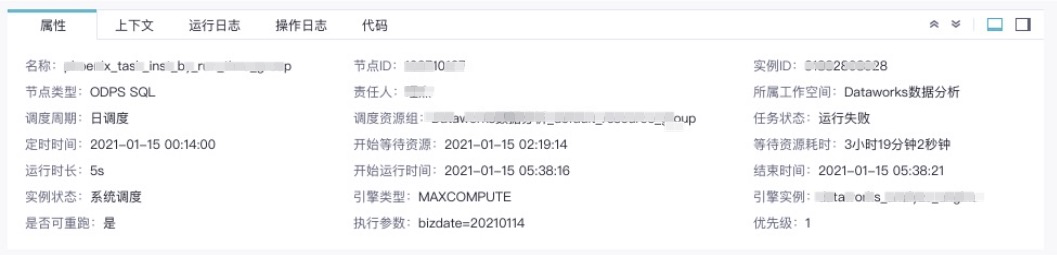
2. 图布局设计
图布局是指图中节点的排布方式,根据图的数据结构不同,布局可以分为两类:一般图布局、树图布局。适用于我们业务的是一般图布局。常见的图布局算法有:力导布局、Dagre布局、网格布局、同心圆布局等。
结合业务的“图宽”特征,发现单一的一种布局方式已经远远不能满足我们的业务需求。因此我们设计一种新的子图布局方案,方案核心:
- 同层分组:同层节点数过多时,进行分组聚合。
- 维度聚合:提供针对某个业务维度,对数据进行聚合分析。
- 辅助视角:聚合后损失的信息,通过辅助视角提供。
2.1 同层分组
同层分组的视角如下图所示,同时在分组内增加翻页功能,展示更多信息,节省画布空间。
分组后,针对分组内的节点,丢失了其直接上下游的信息,提供节点的独立操作,便于用户针对自己关心的节点进行进一步分析。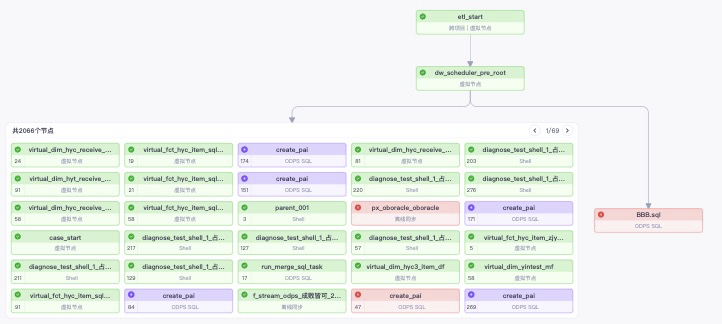
2.2 维度聚合
通过一些方式,对节点进行聚合操作。聚合节点的设计如下图所示:
与分组组合的设计如下图所示:
2.3 辅助展示
聚合后提供辅助视角,查看聚合后的节点详情。
3. 图分析设计
即便在上述的布局方案下,大数据量下的节点问题定位,对用户来说,还是很难。
因此我们针对用户常用的业务分析场景,提供了聚合分析、上游分析以及下游分析工具,尽可能的帮用户快速分析任务问题和影响。
3.1 聚合工具
当节点的上游或者下游过多时,没法一眼找到用户想要的节点。这时,可以通过对某个维度做聚合,然后再进行细分查找。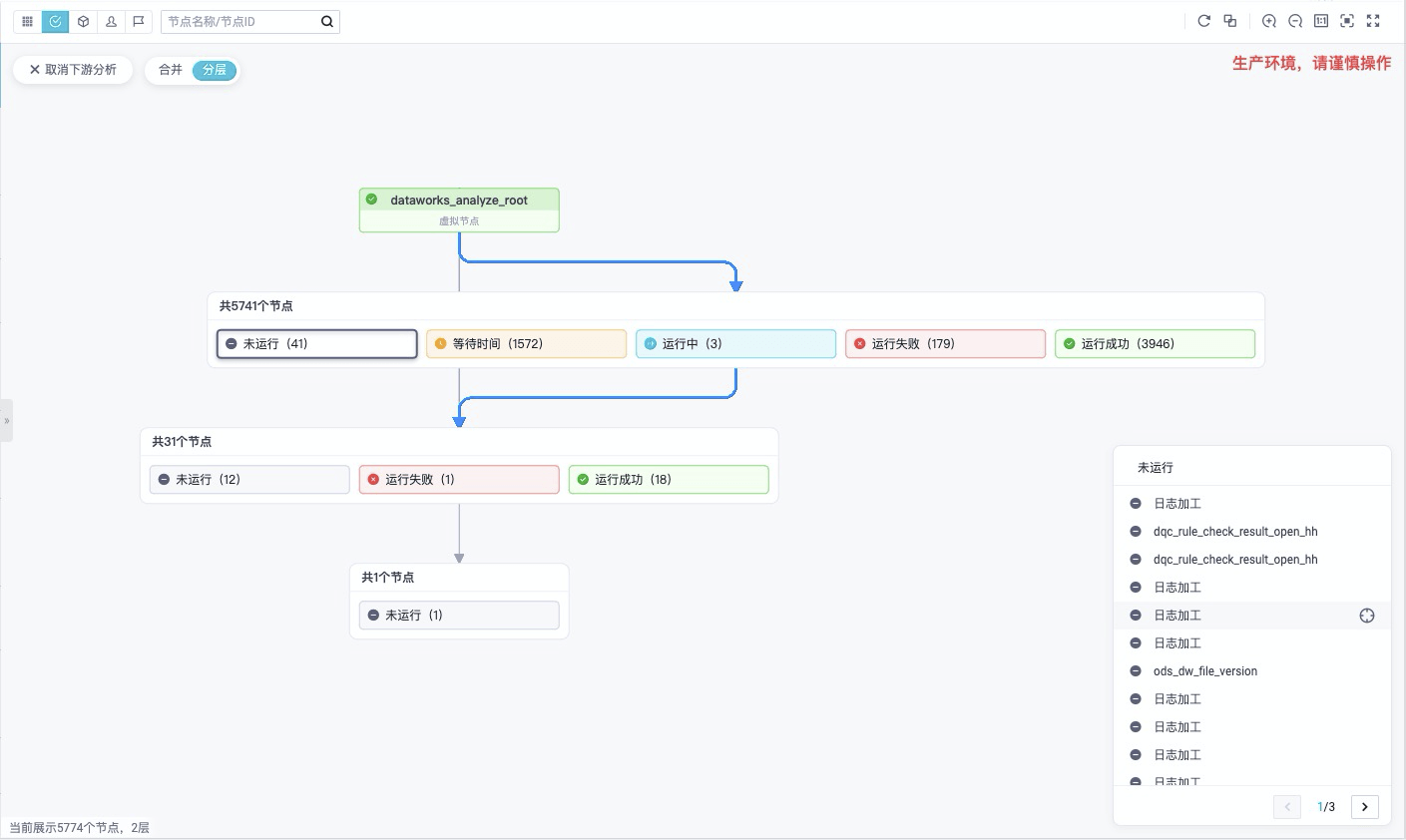
3.2 上游阻塞链路定位
当节点在期望时间内仍处于未运行状态时,用户需要查看阻塞任务的原因。
新增上游分析功能,针对未运行的节点,一键定位上游的阻塞节点。
- 上游分析页面只展示阻塞当前实例运行的实例,即:非成功态的上游实例
- 如果一级上游中存在未运行的实例,则需要对该实例进行上游分析,将阻塞该实例运行的上游展示出来。
出于性能和稳定性的考虑,默认分析6层上游,用户可以选择继续分析。
3.3 下游影响分析
当用户需要修改自己的节点时,需要清楚修改后的影响到的业务和范围。
新增下游分析功能,结合聚合视图,可高效直观地完成当前节点的影响分析。提供合并和分层两种视角。
- 合并视角下,对当前任务的所有下游(1/2/3/…级)做聚合,支持的聚合维度有:工作空间、责任人、优先级、状态。
- 分层视角下,对任务的各层下游分别做聚合,支持的维度同上。
- 当用户点击某个分组,画布右下角展示分组中的任务列表,点击某个任务可以跳转到对应的列表并定位该任务。
出于性能和稳定性的考虑,默认分析6层上游,用户可以选择继续分析。
五、参考文献
https://g6.antv.vision/zh/docs/manual/middle/layout/graph-layout
- https://airflow.apache.org/
- https://azkaban.readthedocs.io/en/latest/useAzkaban.html
- http://106.75.43.194:8888/dolphinscheduler/ui/#/home
- https://antv-g6.gitee.io/zh/docs/manual/middle/elements/edges/built-in/polyline
- https://www.gdcvault.com/play/1022094/JPS-Over-100x-Faster-than

若有收获,就点个赞吧
0 人点赞
