原文地址:https://zhuanlan.zhihu.com/p/148990503 如有侵权,请联系 @聚则(moyee-bzn) 删除
众所周知,图可视化是信息可视化中的一个重要领域,通过展示元素之间的关系,帮助用户观察和分析数据。图可视化无论在科学研究、工业生产还是日常生活领域中都起到举足轻重的作用:比如计算机网络, 生物信息学,社交关系等。
针对图可视化,很早就有各种各样的可视化工具和平台,如Gephi, Graphviz等。而随着各种前端框架的兴起,已经涌现了多种多样面向图可视化设计的库,比如G6,Echarts.js等。这些工具或者库提供的功能各不相同,可视化效果也各有千秋。为了对该领域的现状进行概括总结,我们介绍了目前国内外常见的包含图可视化的可视化系统/工具,并分别从上手难度、功能和美学等角度出发进行了详细的测评。
具体来讲,我们调查的可视化工具包括NodeXL, Gephi, Graphviz, Palantir, Cola.js, G6, ECharts.js。我们为上述每种可视化工具的功能特性都进行了阐述。内容中的介绍部分均来自于它们的官方网站,其他部分可能有参考其他文章,若有版权问题请第一时间联系我们。
NodeXL
官方介绍
NodeXL是一个功能强大且易于使用的交互式网络可视化和分析工具,它利用流行的Microsoft Excel应用程序作为表示通用图数据应用程序作为表示通用图数据、执行高级网络分析和网络可视化探索的平台。该工具支持将多个社交网络应用提供的图数据(节点和边的列表)导入Excel电子表格[1]。
基本功能
- 数据导入
NodeXL Pro将UCINet和GraphML文件以及包含边列表或邻接矩阵的Excel电子表格导入NodeXL工作簿。NodeXL Pro还允许通过一组导入工具快速收集社交媒体数据,包括电子邮件、Twitter、YouTube和Flickr。NodeXL在收集任何个人数据之前请求用户的许可,并专注于收集公开可用的数据,例如Twitter状态,并跟踪公开帐户之间的关注关系。这些特性允许NodeXL用户立即处理相关的社交媒体数据,并将社交媒体数据收集和分析的各个方面集成到一个工具中。
数据表示
NodeXL工作簿包含四个表:边、顶点、组和总体度量。图中实体及其关系的相关数据以行的格式存储在相应的工作表中。例如,“边”工作表至少包含两列,每行至少包含两个元素,这些元素对应于构成图中边的两个顶点。图度量、边和顶点的视觉特性在相应工作表的附加列中。此表示允许用户利用Excel电子表格快速编辑现有节点属性并生成新属性,例如,通过将Excel公式应用在现有列上。图分析
NodeXL Pro包含一个常用的图度量库:中心度、聚类系数、直径。NodeXL区分有向和无向网络。NodeXL Pro实现了多种社区检测算法,允许用户发现其社交网络中的聚类。图可视化
NodeXL生成用于图可视化的交互式画布。用户可以选择几种经典的力导向图绘制布局算法,比如Fruchterman-Reingold和Harel-Koren算法。NodeXL允许用户在画布上多选、拖放节点,并手动编辑它们的视觉属性(大小、颜色和不透明度)。此外,NodeXL允许用户将节点和边的视觉属性映射到它计算的度量,并且通常映射到边工作表和顶点工作表中的任意列。
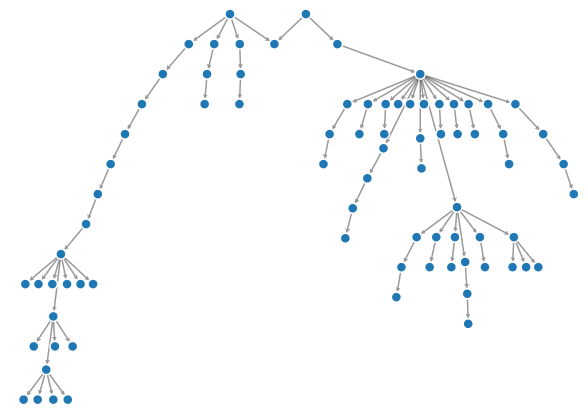
示例图: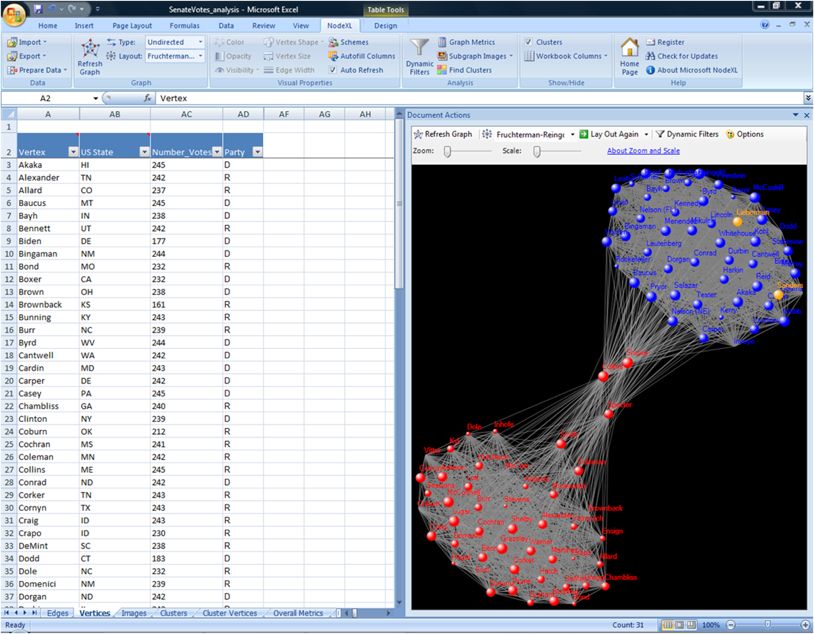
该工具包括一个Excel模板,可以方便直观地对图形数据进行操作
在NodeXL中使用Harel-Koren算法生成的聚类图
测评:
优点是容易上手,数据收集和对图的分析功能比较强大。缺点是,从网上获取的数据一般是半结构化甚至无结构的,在这种情况下数据清理会是一个问题,需要利用其他软件做数据清理后再用NodeXL进行分析。
Gephi
官方介绍
Gephi是数据分析师和科学家用来探索和理解图形的工具。与Photoshop类似,但是主要针对图形数据,用户可以通过与图形进行交互,操纵结构、形状和颜色来显示隐藏的数据模式。Gephi的目标是帮助数据分析人员在分析数据的过程中做出假设、直观地发现数据模式、突出数据结构或错误。这是一款用于探索性数据分析的软件,是可视分析领域的经典[2]。
基本功能
- 布局
Gephi为保证效率和质量,提供了12种不同的布局算法(主要是force-directed类型的算法)。布局面板允许用户在运行时更改布局设置,从而显著增加用户的反馈和体验。

统计和度量
Gephi为社交网络分析(SNA)和无标度网络提供了最常见的度量:中介度中心性、封闭性、直径、聚类系数、PageRank、社区检测(模块化)、随机生成器和最短路径等。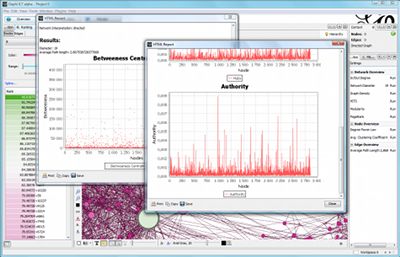
绘图
Gephi使用排序或分区使网络数据表示变得有意义。使用自定义颜色、大小或标签提供网络表示。矢量预览模块让您在使用SVG或PDF进行探索之前完成最后的操作并满足美学需求。Gephi可将结果定制为的PDF、SVG和PNG导出。动态过滤
Gephi根据网络结构或数据筛选网络以选择节点和/或边。使用交互式用户界面实时过滤网络中的节点数据。数据表及编辑
Gephi有自己的数据计算器,它有一个类似于excel的接口,可以操作数据列、搜索和转换数据。包括强大的搜索/替换、操作列、批量编辑、自定义列合并等数据操作方法。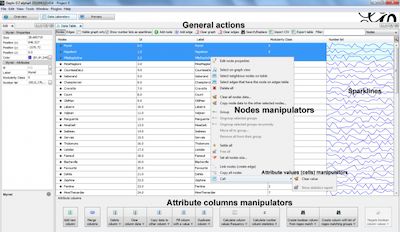
示例图: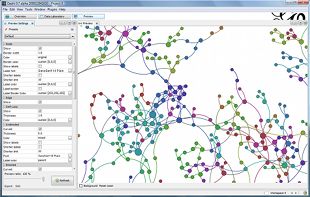
测评:
优点是系统简单易操作,新手上手容易,不需要代码基础,对简单图的分析效果也可以接受。缺点是数据需要转换成Gephi需要的数据格式,布局与配色不够美观,调整起来也需要花很多时间。
Graphviz
官方介绍
Graphviz是一款开源图形可视化软件。图可视化是将结构信息表示为抽象图和网络图的一种方法。它在网络、生物信息学、软件工程、数据库和网页设计、机器学习以及其他技术领域的视觉界面方面有重要的应用。Graphviz以简单的文本语言描述图形,并以有用的格式(如web页面的图像和SVG)生成图形,以供加入其他文件或显示在交互式图形浏览器中。Graphviz对于具体图有许多有用的特性,例如颜色、字体、表格节点布局、行样式、超链接和自定义形状的选项。这款软件在网页设计,机器学习以及其他技术领域的可视界面中具有重要的应用[3]。
基本功能
通过dot语言来描述如何绘制节点、如何绘制边,通过不同的布局算法实现最终产生布局。有C/C++、python库的实现。Dot语言算是比较容易简单上手。如下图所示:

对于节点,可以批量描述,也可以逐个描述。[]中描述颜色、字体或者自定义形状。对于布局,有以下几种:

示例图:
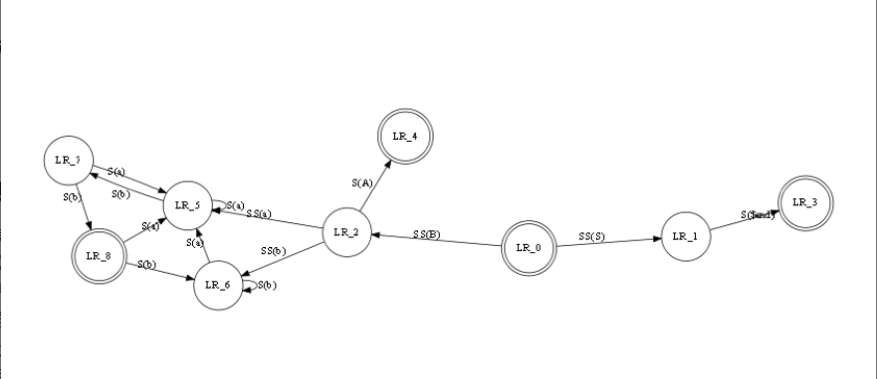
测评:
优点是dot语言容易上手,节点和边的形状自由度较高,可以自定义形状甚至是导入图片。缺点是不支持手动调整布局,而只能是通过上面描述的那几种布局方法产生。对于较大规模的数据,优点是可以通过如sfdp等方法快速进行布局,缺点是,需要编写脚本来处理得到符合dot语言的格式。
Palantir
官方介绍
Palantir是一个数据分析平台,公司有两个产品线:一个是Palantir Gotham, 主要是应用于国防与安全领域;另一个是Palantir Metropolis,主要应用于金融领域。
它允许以结构化(数据库表格,电子表格等)或非结构化(文档,演示文稿等)的格式导入数据,并通过图分析、地图或者统计和集合操作进行分析。平台帮助企业、政府、非营利机构客户整理、分析、利用不同来源的结构化和非机构化数据。Palantir的核心理念在于创造一种人脑智能和计算机智能“共生”的关系,着重交互,发挥两者各自的特长,解决实际、困难的数据分析问题[4]。
基本功能
- 数据集成
Palantir提供了多种方法来从不同的数据源中获取数据,并且基于本体创建本体对象,如下:
- 前端导入(Front End Import/FEI)。前端导入使用爬取、抽取、检测、转换(CEDT)架构将文档导入Palantir,根据文档类型来执行必要的操作。这种导入技术可以扩展,有用于创建CEDT插件的API接口。如果数据源为结构化的(excel,csv等),则将出现一个映射对话框,允许用户对表列与属性进行映射,并且还对由于处理数据表而应该创建的对象和关联进行模型。如果数据源是非结构化的,默认情况下直接导入到系统中,当然也可以创建一个CEDT扩展来处理源并自动标记内容。
- Kite导入/同步导入。Kite是Palantir提供的应用程序,它将结构化数据源转换为一种pXML中间格式,它描述了对象、属性、权限等级、附件和关联。工程师需要创建一个Kite XML配置以描述数据源的结构、如何解析数据项的详细说明、并定义输出对象讲如何组装。
- Raptor。Raptor是一个补充的软件包,可以用于大型文档存储的部署,例如一个组织的网络驱动器。使用Raptor时,在服务器上安装一个服务,并将给出的共享路径作为Raptor作业程序设置的一部分。然后,Raptor将抓取该目录下的文档,建立索引并把索引保存到服务器中。一旦Dispatch检测到该Raptor服务的存在,Raptor索引也将被包括在前台界面的搜索中。
- Phoenix。Phoenix是另一个补充的软件包,它是Palantir用于导入PB级规模、结构化数据的解决方案,如通话记录、交易日志或网络日志。Phoenix为用户提供了对海量数据源快速搜索数据子集的能力,例如给定号码的所有通话记录,然后将该子集导入Palantir的调查进行分析。
- 开发插件。最后的标准导入机制是使用Palantir开发API。用助手——Helper(Palantir一种插件类型)举例,如维基百科搜索助手,它可以提供一个搜索功能并向用户呈现结果列表,然后用户可以选择需要的结果,将整篇文章作为一个文档放进Palantir系统,为文档标记做准备。
搜索和发现
Palantir为分析师提供了多种搜索机制,使他们能够找到匹配的数据,并且挖掘出数据间的关系,从而发挥数据的价值。最独特的是它的环形检索(Search Around),其中最常用最重要的是快速搜索(Quick Search),当然这一切的基础是需要一个很好的本体。Palantir提供了生成复杂的搜索查询(布尔逻辑,变音位,模糊值)的能力,同时无需了解复杂的查询语法。知识管理
当用户从他们添加到系统的数据中发现新的信息或新的关系时,Palantir会添加新的信息并记录新数据源的信息。这意味着Palantir拥有完整的审计机制,同时更加重视信息的完整性以及出处,还根据用户的继承权限和默认权限保护新添加的数据,这表示添加到Palantir的所有数据都可以根据其授权级别赋权给其他用户。协作
Palantir允许分析师在私人调查中根据自己的思路开始调查,任何需要共享的调查结果都可以发布,分享给其他用户。同样,分析师可以选择何时接受其他用户的更新,也可以选择将共享分析图加载到当前调查或新建调查中,以便开展进一步的工作。算法引擎
在许多公司中存在一致的问题空间(破解欺诈,网络嗅探等),可以通过寻找趋势的通用算法来解决,这是算法引擎的基础[5]。
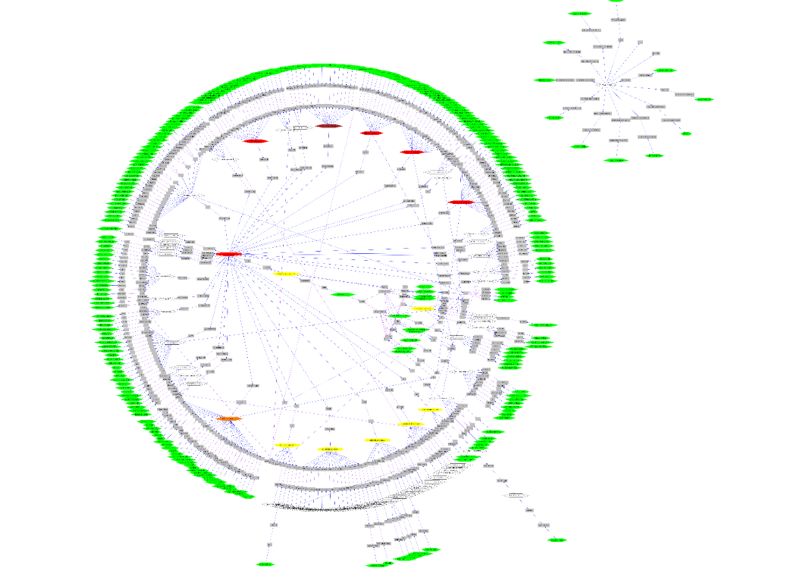
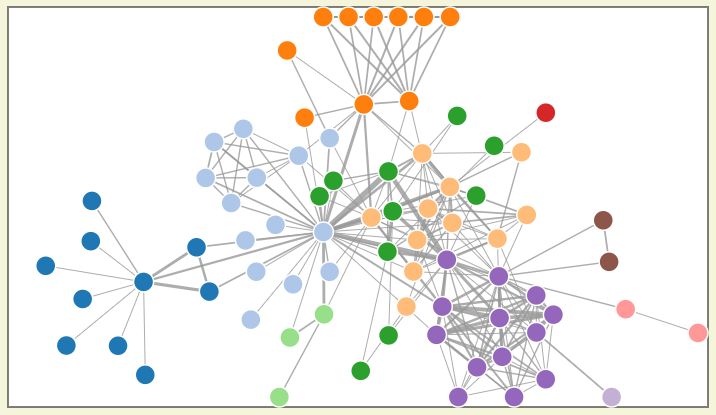
示例图
- 摘要视图
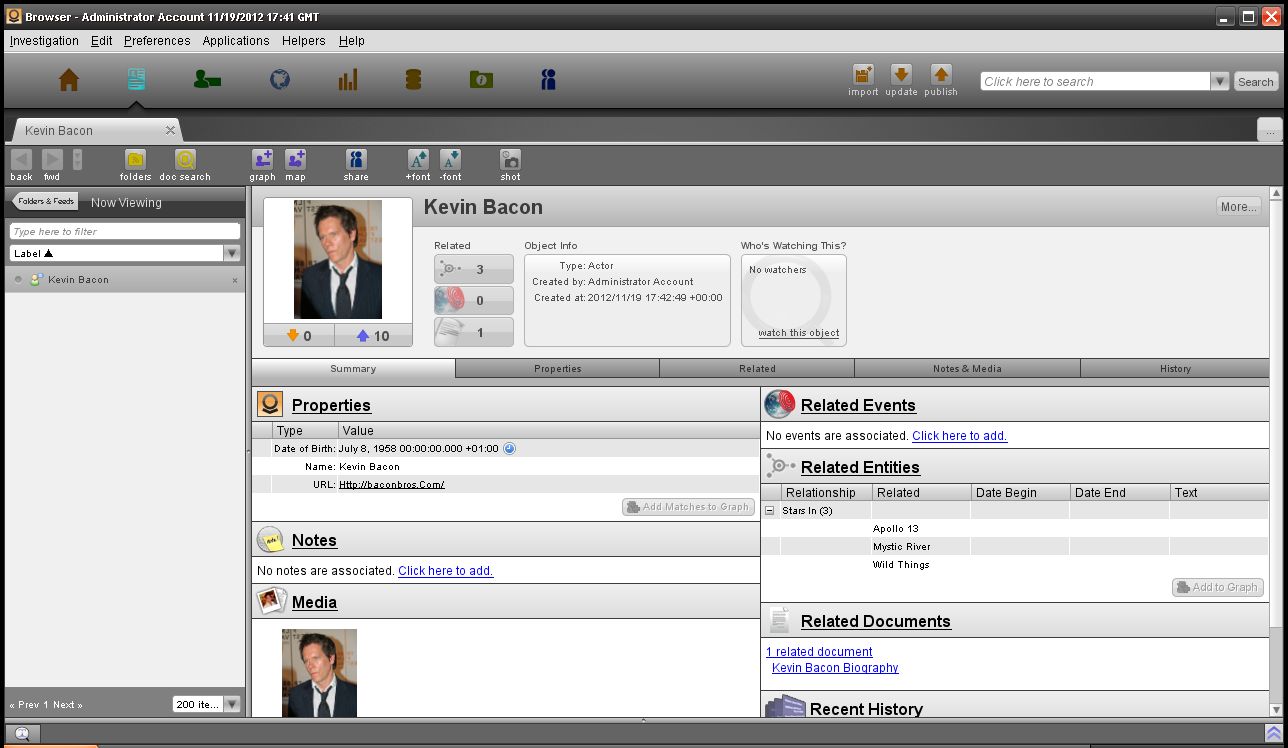
- 对象探索
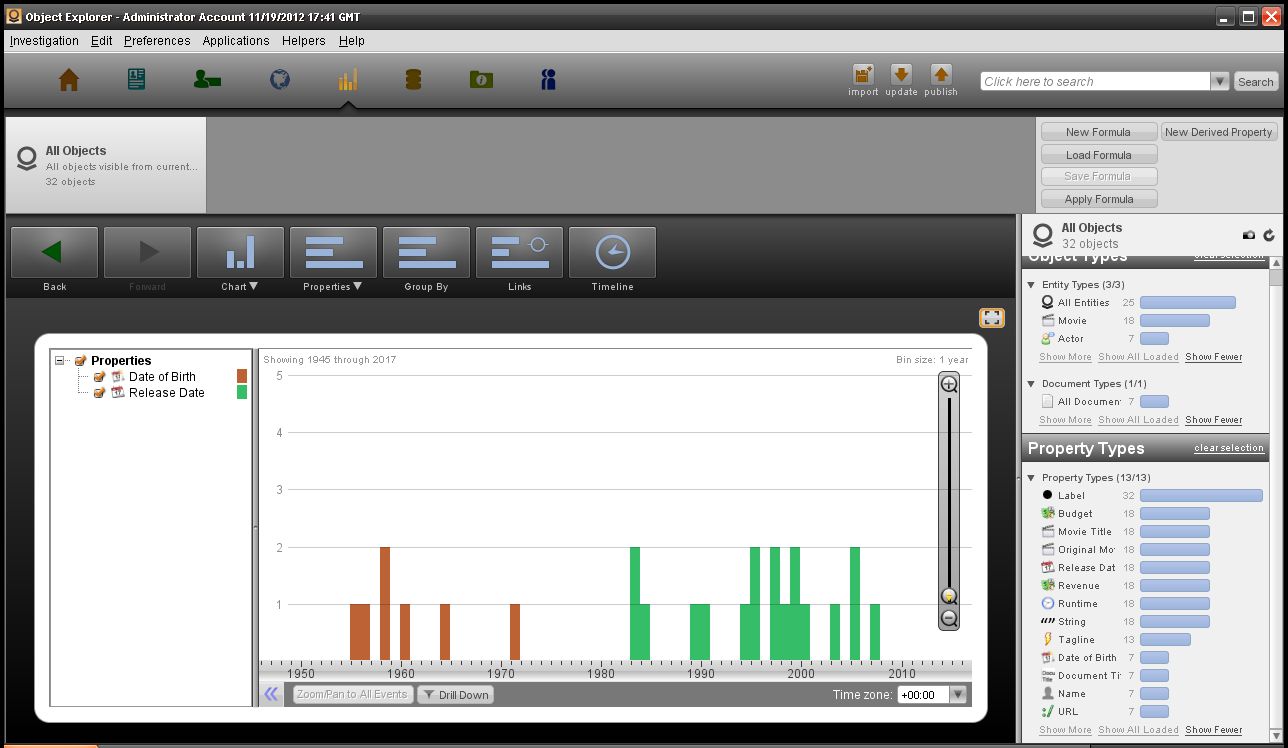
对象探索应用允许自顶向下分析整个数据集,通过将数据分解为集合和子集,然后以不同的方式可视化集合的内容。允许对大容量数据进行快速分析,这是由于分布式内存数据库赋予它的能力。
文档选项卡与标记
可以标记文档的内容,这是分析师用来构建非结构化数据的手段。如果没有标记,则不能在Palantir对象模型中使用文档,这也就大大地减少可以执行分析的数据量。所有被标记的对象都可以无缝地进行交互。如分析师可以在分析图中用环形搜索(searcharound)来搜索Kevin Bacon的关联实体,他的父母、妻子和孩子将会被搜索到;同样地搜索其中一个孩子的关联实体会返回其父母和其他兄弟姐妹;这些关联在对象探索(Object Explort)中也可用来进行自顶向下的分析。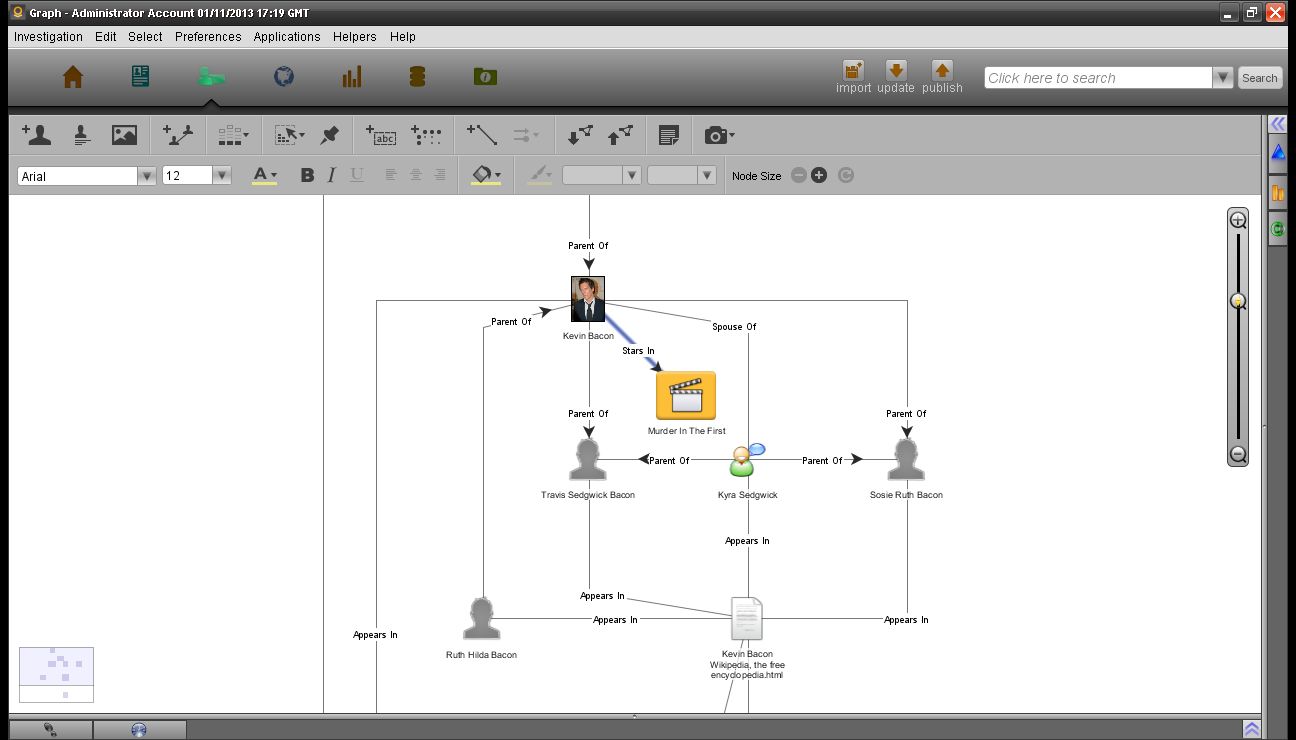
图分析
环形菜单
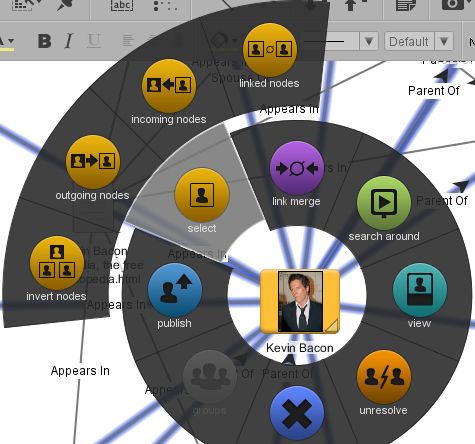
环形菜单的功能有:
发布——这允许将所选对象相关的任何新数据发布到基础库,以便其他用户提取新数据并在自己的调查中使用它。
选择——这会连带弹出一个可供多个选项的菜单。
关联节点——它选择与当前所选节点有一个分离度相关联的所有节点。
流入节点——选择与当前节点相关联而且这些节点流入所选节点;例如,该选项将选择Kevin Bacon的父母。
流出节点——选择与当前节点相关联、接收来自选定节点流入的节点;例如,该选项将选择Kevin Bacon的孩子。
反选节点——取消选择已选定的节点,并选择取消选择节点以外的节点。
节点之间的关联——如果选中两个或多个对象则该选项被激活,这将选择被选对象之间关联的所有边;这对两个对象之间已经关联合并的所选事件非常有用。
关联合并——如果分析图上有最少3个以上互相关联的对象,则可使用该功能将中心的对象关联合并,这将有效地将分析图转换为一根关联线连接两个实体,关联线实际成为了第三个实体。这个功能在对象之间存在很多事件的分析图上非常有用,比如可视化的事务日志,因为它可以有效地整理视图。
相关检索——允许用户对所选对象进行上下文相关检索。
查看——在浏览器打开所选对象详细信息,这在之前的文章中讨论过。
合并/取消合并——如果同时选中多个对象,则会显示“合并”选项;这允许用户将这些对象合并成一个对象,这在分析图中删除重复对象非常有用。一旦两个对象被合并,它们将由一个对象来表示,该对象具有之前那些对象的所有关联和属性。我将在以后的文章中讨论合并,因为它对有效使用系统非常重要。取消合并是反向操作,它被用于用户希望将合并的对象拆分回原来的状态。
删除——这将从分析图中移除对象,但是对象的数据没有被删除,对象仍然可以通过检索找到。
创建组——如果选中多个对象则该选项显示,这将为选定的对象创建一个命名组。
在环形菜单中经常使用的功能是相关检索,用来做演示效果非常好,可以非常动态地展现关联对象。
测评:
Palantir是一款基于语义的可视化的分析工具,同时具有数据集成、知识管理、分析协作的功效。它突出的能力有两个方面:
基于语义的非结构化数据与结构化数据的关联分析能力。Palantir可以多维度将不同来源的数据进行关联,特别是对非结构化数据的关联分析,比如邮件、社交网络信息、网络日志信息。从而挖掘和展现出未知的相关关系,为决策提供依据。
可视化的数据特征分析能力。产品设计思想中突出体现人驱动分析的思想,着重突出人在分析过程中与数据的交互能力。由于其语义表示的可视化做得比较到位,所以非常擅长在大量日志数据中寻找有特殊意义的信息。如Palantir Metropolis,简单的模型被作为更复杂模型的构建块,让分析人员可以表达出任何想象的东西;交互式用户界面整体展示所有集成的可用数据,并且实时更新。在后端,其整合多源的表格数据到连贯的模型中,并对模型执行复杂计算,同时共享和迭代分析产品;在前端,其提供一套集成的应用程序,让用户可以建立交互,包括自定义Metric、仪表盘、日期设置、浏览器、回归和电子表格等[6]。
但是,Palantir往往供给企业、政府、金融机构等组织,不适合个人使用,需要连接数据库应用平台,如果用户需要的是不连接数据库的独立应用不推荐使用Palantir;如果用户只通过单一的方式分析数据,并且不需要分享他们的成果,Palantir也不是好的选择。
Cola
官方介绍
Cola.js是一个开源的JavaScript库,使用基于约束的优化技术用于排列HTML5文档和图表。它在D3这样的库中工作得很好,核心是基于完全重写的Javascript的C++ libcola库。这个库是Monash大学的Tim Dwyer教授将自己相关的图可视化算法进行集成后产生的,算法都非常经典[7]。值得一提的是,Cola.js有为d3.js设计的适配器,允许将cola作为D3力布局的一个简易替换。Cola可以将布局收敛到局部最优,而D3通过简单的退火策略强制收敛。因此相对于D3,cola.js 有如下的特点:
- 能够实现更高质量的图布局。
- 在交互的应用中更加稳定(no “jitter”)。
- 允许用户指定特殊的约束例如alignments和grouping等。
- 可以自动地产生约束来避免overlapping nodes或者为directed graphs提供flow layout。
- 对于大图的扩展性较低。
基本功能
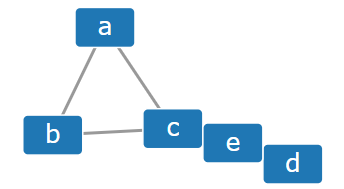
- Alignment constraints
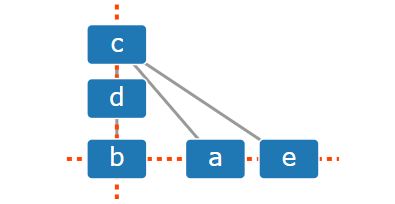
如图,节点“a”、“b”和“e”被约束到同一个x坐标。“b”、“c”和“d”被约束在同一个y坐标上。
2. Inequality constraints
{"axis":"y", "left":0, "right":1, "gap":25}
这表示图中ID为0的节点中心必须比ID为1的节点中心高至少25个像素。更准确地说,这是一个不等约束,要求:
graph.nodes[0].y + gap <= graph.nodes[1].y
- Equality constraints
直接在Inequality constraints中加上“equality”属性即可。如下:
表示:{"axis":"x", "left":0, "right":1, "gap":30, "equality":"true"}
通过以上的三种约束结合使用可以实现downward-pointing布局等。graph.nodes[0].x + 30 == graph.nodes[1].x
- Group constraints
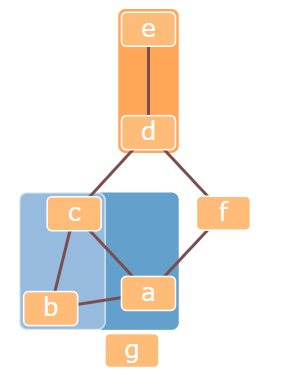
该图在节点上定义了分层结构。Cola生成约束来防止不相交组的边界框重叠,并使嵌套组完全包含在它们的父边界框中。
Separation constraints
该例子展示了Cola通过设置约束来将图节点保持在一个给定的边界框内。Non-overlap constraints
该例子节点“e”没有连接到图形的其余部分。在这种情况下,Cola生成约束来防止节点重叠。
- Flow layout & Edge routing
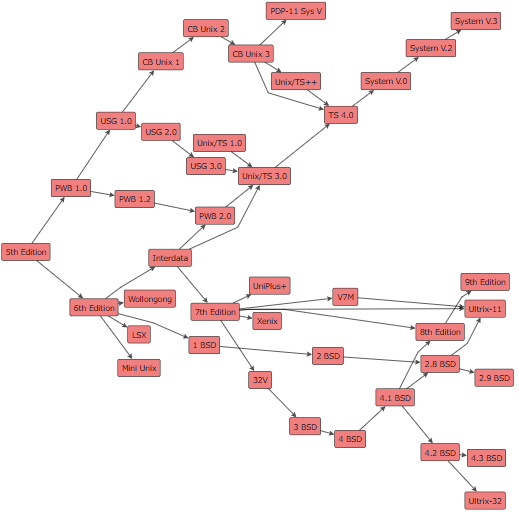
- Flow Layout:使得边在它们的连接两点之间生成一个分隔约束,最小间距设置为150。指定“x”轴实现了从左到右的流程布局,流程布局方向可以手动调整。
- Edge routing:在布局停止后,边路径被改变以避免通过节点边界。
- Fixed Node Positions
在cola中,可以将节点的位置固定/锁定到特定的x,y坐标。
9. Link lengths
Cola可以控制不同边的相对长度。
测评:
Cola对大图的扩展性小。目前只能在处理100个点以内的图数据。
可使用的约束有限。目前只能在水平和竖直方向上控制约束,不能实现圆形、星型等复杂形状约束以及固定两点距离的硬约束。(例:|p-q|=d,其中p 和q 是点的位置);
3. 用户设置约束时,Cola语法繁琐。例如如下语法:{"axis":"y", "left":0, "right":1, "gap":25}
设置ID为0的点和ID为1的点在Y轴的距离要大于25像素。
当对多个点进行约束时,要为个点对写一行代码,而没有更高层的API对多个点进行统一布局。
G6
官方介绍
G6是蚂蚁金服-AntV 旗下的针对关系数据的可视化前端js库。它提供了图的绘制、布局、分析、交互、动画等图可视化的基础能力。能使开发者很方便搭建图可视化,图分析或图编辑器应用[8]。
其特性包括
- 丰富的元素:内置丰富的节点与边元素,自由配置,支持自定义;
- 可控的交互:内置 10+ 交互行为,支持自定义交互;
- 强大的布局:内置了 10+ 常用的图布局,支持自定义布局;
- 便捷的组件:优化内置组件功能及性能;
- 友好的体验:根据用户需求分层梳理文档,支持 TypeScript 类型推断;
基本功能
- 内置多种图布局:包括图布局和树布局;
- 内置多种节点和边的图形属性(circle,rect,ellipse,polygon,fan,image,marker,path,text);
- 内置多种交互行为和动画(在交互上主要考虑了三个场景:展示关系数据,可视化建模和图分析);
- Graphics Group:组针对图形Shape层次的分组,可增强视觉效果;
- 提供了几种插件或工具:缩略图 (Minimap),Grid 网格,Edge Bundling;
- 可自定义图布局,自定义交互行为;
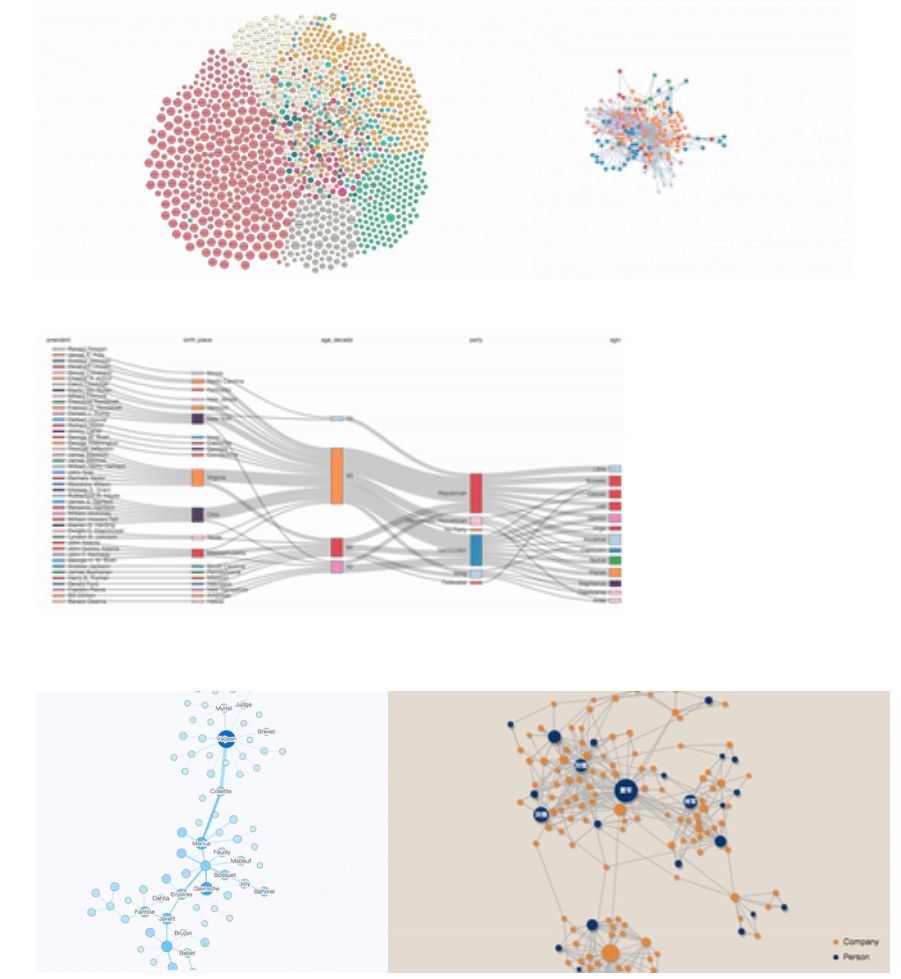
示例图
- Edge Bundling效果图
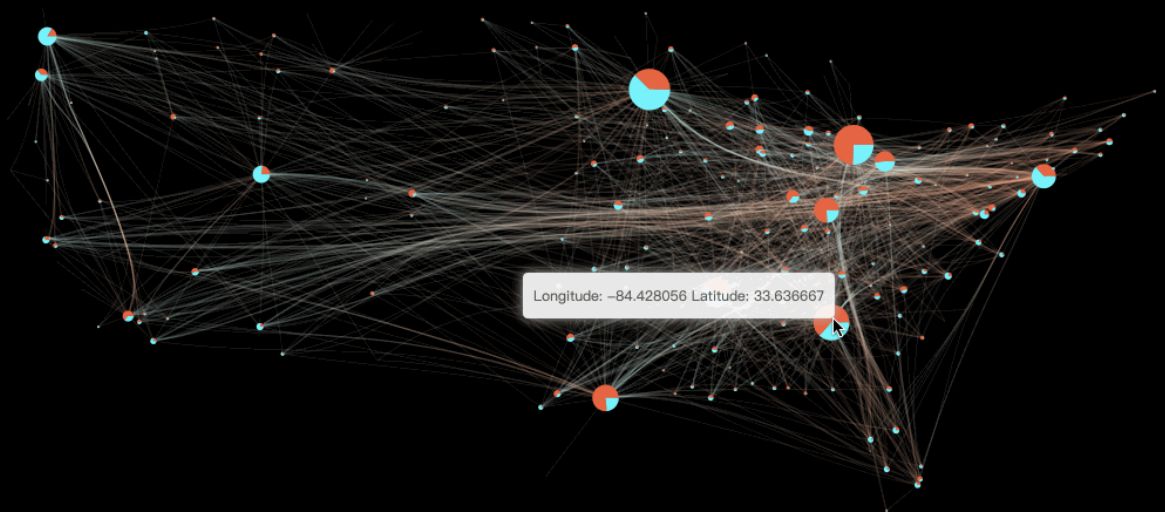
图分析应用效果图
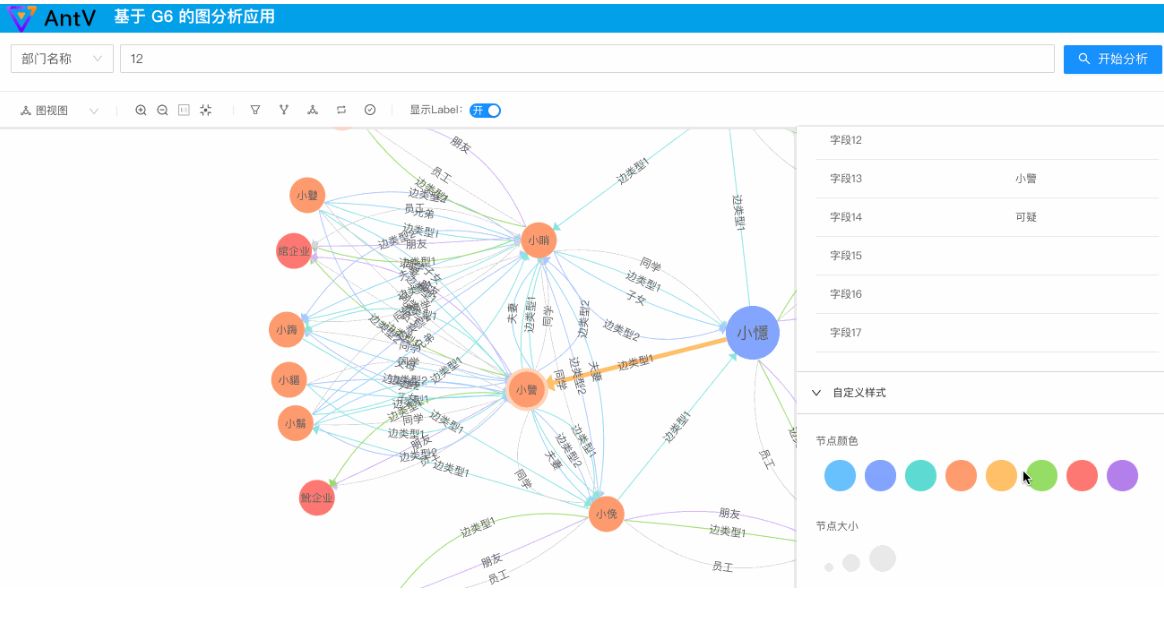
时序分析效果图
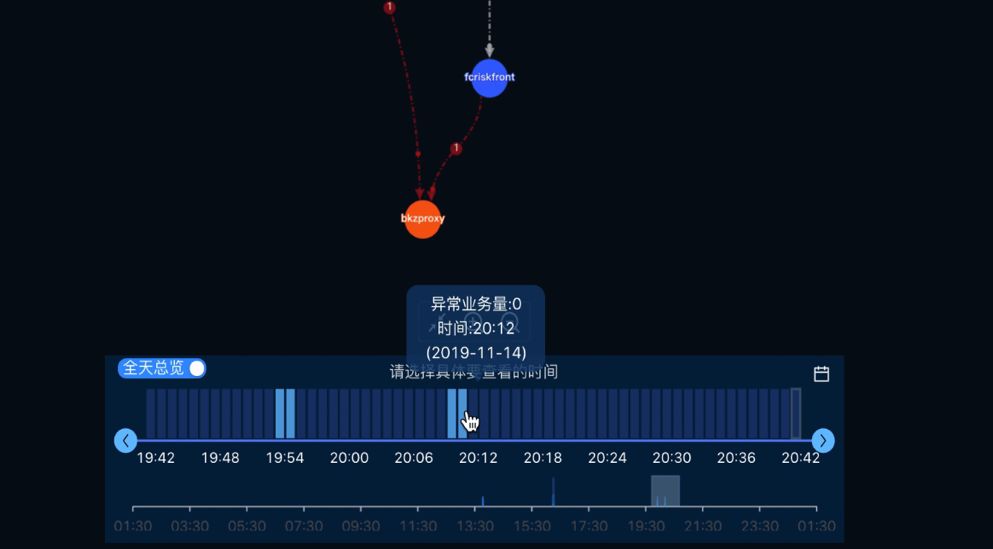
可直接编辑生成标准数据的编辑器
其他基础部分效果图
测评:
- 支持很高级的web页面应用,可以在web页面上直接编辑,生成标准数据格式:
- 提供多种现成的图布局方式,例如树,力导图布局,Dagre 流程图布局,Fruchterman 图布局,Radial 辐射布局,网格布局,MDS 布局等多种图布局方式,以及提供了大量的内置样式、交互方式、动画,操作简单易上手。
- 布局Layout和交互Behavior可自定义:当内置的布局无法满足需求时候,g6提供了一般图的自定义布局机制
- 支持Canvas和SVG两种渲染方式,可根据需求选择
- 多线程计算提高了图布局运算速度
- 提供了些较高级的功能如Edge Bundling,Minimap
- 给出的图美观性不高,颜色搭配不漂亮
Echarts
官方介绍
ECharts,一个使用 JavaScript 实现的开源可视化库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等),底层依赖矢量图形库 ZRender,提供直观,交互丰富,可高度个性化定制的数据可视化图表。
ECharts 提供了常规的折线图、柱状图、散点图、饼图、K线图,用于统计的盒形图,用于地理数据可视化的地图、热力图、线图,用于关系数据可视化的关系图、treemap、旭日图,多维数据可视化的平行坐标,还有用于 BI 的漏斗图,仪表盘,并且支持图与图之间的混搭。
除了已经内置的包含了丰富功能的图表,ECharts 还提供了自定义系列,只需要传入一个renderItem函数,就可以从数据映射到任何你想要的图形,更棒的是这些都还能和已有的交互组件结合使用而不需要操心其它事情[9]。
基本功能
众所周知,Echarts通过setOption 方法来指定图表的配置项和数据。
开发者在一个大的JavaScript对象options里面以json的格式指定各项配置,就可以画出自定义的图表。
一般来说,给定合适的数据,设置series.type =’graph’就可以绘制graph,且通过layout设置以下三种布局方式:
当数据中没有给定节点坐标,要想实现比较复杂的布局,需要开发者用算法决定。
示例图
以下为官网给的几个图可视化实例:
- 节点坐标在数据中给定。支持基本的交互,比如平移、缩放、tooltip和节点关系高亮。
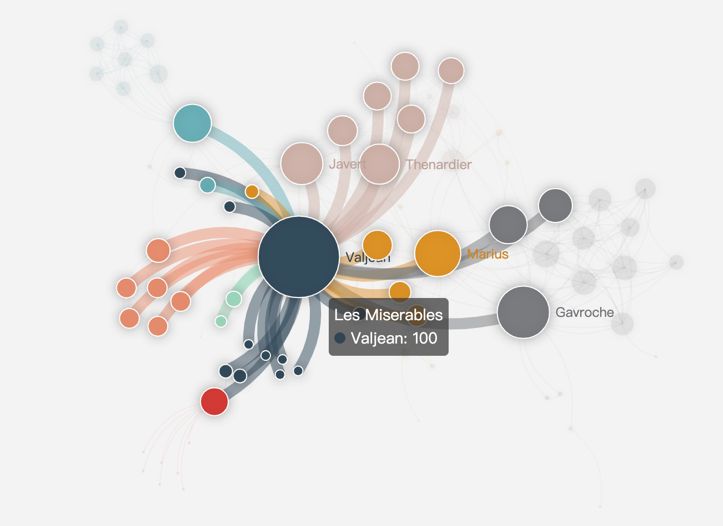
使用环形布局。
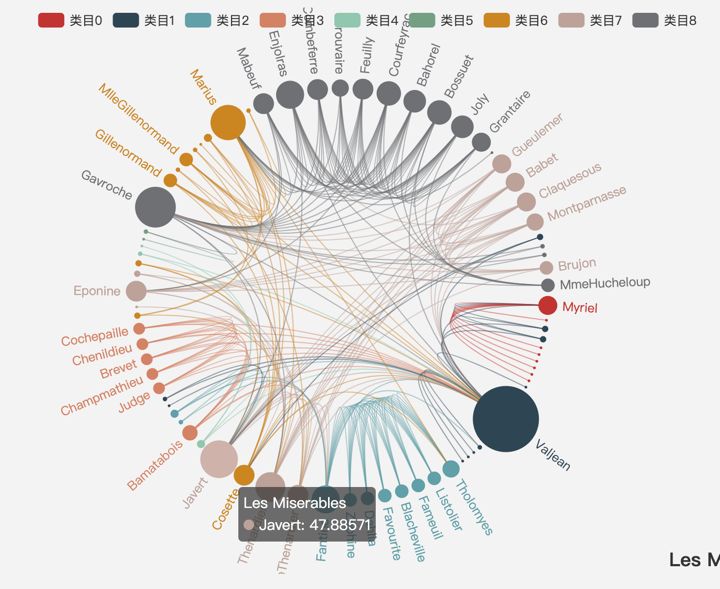
使用节点链接图。

节点的坐标通过力导向算法决定。忽略了图布局的两个要素:美观程度和易读程度。
测评:
- 美观性:较高。主要得益于官方示例中的色彩搭配。另外还支持一些渐变动画的定制。
- 交互性:较低。只能实现一些较基本的比如平移,缩放、拖拽操作,当我们需要一些稍微高阶的技巧如边捆绑、鱼眼放大镜时,只能自己去实现。
- 自由度:较低。Echarts给人的感觉就像给定了模板,你有了数据直接去套,然后稍微修改mark的大小,颜色。如果你有一个比较novel的idea但是Echarts没有对应模板,那就没办法了。
- 上手难度:较低,对于具备编程能力的人来说容易上手。
总结
经过上述的测评可以看出,各家工具没有统一的功能套路,各有所长。有的上手简单,但自由度低;有的自由度高,但没有很好的交互性。我们认为,目前还不存在一个上手简单而且功能、自由度和美观度俱全的图可视化工具。编者注 G6 正在努力成为一个上手简单而且功能、自由度和美观度俱全的图可视化引擎。
**
另外,几乎所有工具都没有针对减轻视觉混乱的设计,这在图数据规模较大时会给用户带来灾难性的阅读和分析障碍。为了解决这个问题,山东大学可视化实验室的工作创新性地提出三种改善图可视化结果的方法。在后面的文章中我们会进行详细介绍,敬请关注!

若有收获,就点个赞吧
0 人点赞
