- IOVA
- VFIO
- 因为IOMMU和EPT共用页表项,所以也需要判断下是否支持内存虚拟化
- 判断CPU是否支持虚拟化,Intel系列CPU支持虚拟化的标志为“vmx”,AMD系列CPU的标志为“svm”
- 判断是否开启了基础虚拟化功能
- 判断是否开启VT-D,这个只支持Intel机器
- 假如设备如下
- 确定这个设备所属group,因为group 是IOMMU 进行DMA隔离的最小单元
- 如果设备对应的RC以及switch设备一旦不支持PCIE ACS路由功能,那么凉凉,
- 因为IOMMU会将整个RC都挂到同一个group中, 后边分离后会将整个RC桥都分离。
- 解除绑定
- 将设备挂到vfio上
- 直通或者SR-IOV设备
- VFIO-MDEV
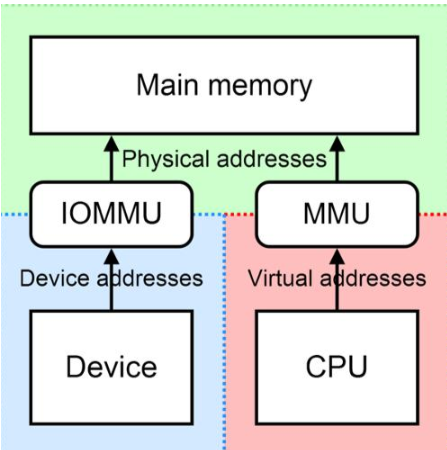
IOVA
IO 其实都知道,就是输入输出设备,VA也听说过,就是虚拟地址。IOVA?对,就是IO的虚拟地址。 个人理解就是: 总线地址, dma_addr_t 见过吧。
LDD3 P392: 一个 DMA 映射是 分配一个 设备的DMA 能访问到的内存。
它试图使用一个简单的对 virt_to_bus 的调用来获得这个地址, 但是有充分的理由来避免那个方法,它们中的第一个是合理的硬件带有一个 IOMMU 来为总线提供一套映射寄存器.
IOMMU 可为任何物理内存安排来出现在设备可存取的地址范围内, 并且它可使物理上散布的缓冲对设备看来是连续的. ===》 IOMMU可以解决 外设与CPU地址总线位数不一致问题; 也能对物理不连续的内存进行DMA传输
使用 IOMMU 需要使用通用的 DMA 层; virt_to_bus 不负责这个任务
DMA
在学习 VIDI-DMA学习 的时候,有部分这样描述的:
Dynamic DMA mapping Guide(翻译: DMA-API-HOWTO.txt)中 描述了虚拟地址和总线地址
驱动在调用dma_map_single/dma_alloc_coherent 这样的接口函数的时候会传递一个虚拟地址X,在这个函数中会设定IOMMU的页表,将地址X映射到Z,并且将返回z这个总线地址
CPU CPU BusVirtual Physical AddressAddress Address SpaceSpace Space+-------+ +------+ +------+| | |MMIO | Offset | || | Virtual |Space | applied | |C +-------+ --------> B +------+ ----------> +------+ A| | mapping | | by host | |+-----+ | | | | bridge | | +--------+| | | | +------+ | | | || CPU | | | | RAM | | | | Device || | | | | | | | | |+-----+ +-------+ +------+ +------+ +--------+| | Virtual |Buffer| Mapping | |X +-------+ --------> Y +------+ <---------- +------+ Z| | mapping | RAM | by IOMMU| | | || | | |+-------+ +------+
IOMMU这个部分是怎么转换的? 什么是IOVA?
这里要理解两个关键点:
- 外设访问主存,只能通过DMA方式。
- DMA设备使用的是总线地址,在有IOMMU的情况,总线地址和物理地址不一定相等。
IOVA
IOVA- io virtual address 文章中描述了几个部分:
- 总线地址的由来?因为给设备上带了个页表,也就是 IOMMU的诞生,使得 从DMA 去看内存 用的是虚拟地址。
- 有了IOMMU,总线地址不一定等于物理地址咯,所以 dma_alloc_coherent / dma_map_single 等 对于buffer的管理都需要先转到总线地址上。
- IOMMU也解决了 设备端 和 主机端 总线位数不一致情况。
- IOMMU可以使DMA支持虚拟地址, 因此可以将DMA导入到用户空间可用。
IOMMU下的DMA buffer申请
dma_alloc_coherent 一致性DMA
先简单看下DMA的代码流程
// 一致性dma buffer的申请流程dmam_alloc_coherent // drivers/base/dma-mapping.cdma_alloc_coherent // include/linux/dma-mapping.hdma_alloc_attrs // 重点接口const struct dma_map_ops *ops = get_dma_ops(dev);// dma_alloc_from_dev_coherent(.....) // 不用管,没实现// arch_dma_alloc_attrs(&dev, &flag) // 也不用管,不支持CONFIG_HAVE_GENERIC_DMA_COHERENTcpu_addr = ops->alloc(dev, size, dma_handle, flag, attrs);// debug_dma_alloc_coherent(dev, size, *dma_handle, cpu_addr); // 调试的接口// 先看下intel的 get_dma_ops(dev),也就是ops接口// 没开IOMMUconst struct dma_map_ops nommu_dma_ops = {.alloc = dma_generic_alloc_coherent,.free = dma_generic_free_coherent,.map_sg = nommu_map_sg,.map_page = nommu_map_page,.sync_single_for_device = nommu_sync_single_for_device,.sync_sg_for_device = nommu_sync_sg_for_device,.is_phys = 1,.mapping_error = nommu_mapping_error,.dma_supported = x86_dma_supported,};// 开了IOMMU 在intel_iommu_init中有: dma_ops = &intel_dma_ops;dma_ops = &intel_dma_ops;const struct dma_map_ops intel_dma_ops = {.alloc = intel_alloc_coherent,.free = intel_free_coherent,.map_sg = intel_map_sg,.unmap_sg = intel_unmap_sg,.map_page = intel_map_page,.unmap_page = intel_unmap_page,.mapping_error = intel_mapping_error,#ifdef CONFIG_X86.dma_supported = x86_dma_supported,#endif};
所以,在开启IOMMU之后,调用的dma接口是
intel_alloc_coherent(dev,size,dma_addr_t, gfp_t, 0)iommu_no_mapping // ???if (gfpflags_allow_blocking(flags)) { // 申请内存允许阻塞的话(GFP带阻塞标记)// 尝试从CMA去分配内存page = dma_alloc_from_contiguous(dev, count, order, flags);}// 如果是非阻塞方式,或者CMA分配内存失败,通过alloc_pagespage = alloc_pages(flags, order);// 管理虚拟地址到总线地址的映射 (重点)__intel_map_single(dev, page_to_phys(page), size,DMA_BIDIRECTIONAL,dev->coherent_dma_mask);
注释: 非PCIE 设备 使用 dma buffer时,会分配一个domain
https://patchwork.kernel.org/project/platform-driver-x86/patch/20190123230131.42094-1-sfruhwald@google.com/
> + #if IS_ENABLED(CONFIG_IOMMU_API) &&> defined(CONFIG_INTEL_IOMMU)> + dev->dev.archdata.iommu = INTEL_IOMMU_DUMMY_DOMAIN;> + #endif
dma_map_single 流式DMA
dma_map_single_attrsaddr = ops->map_page(dev, virt_to_page(ptr),...)// 在开启IOMMU情况 ops->map_page == intel_map_pageintel_map_page__intel_map_single(dev, page_to_phys(page) + offset, size,dir, *dev->dma_mask);
注: 关于__intel_map_single 的实现,后边分析intel iommu代码时在考虑。
个人理解:
在用IOMMU之前, dma接口申请的内存地址,其实就是物理地址HPA,所以存在 HPA==总线地址dma_addr_t。(当然不同架构可能有不同设计,好像PowerPC是加了个offset的线性映射)。
在使用IOMMU后,所有的DMA内存分配 经过 __intel_map_single 之后, 给的不再是 HPA, 吧对应 客户机的物理地址(GPA) 传给DMA就行。(在只开启stage2 的情况,如果开启了stage1,甚至可能将用户空间的虚拟地址给DMA都可以,牛逼不)。
IOVA是怎么解决物理地址不连续的问题?
LLDMA 是如何实现的
还记得LDD3中有一章 特别生涩难懂的 发散/汇聚映射 ? 一听都不想看,其实就是 scatter/gather 好像就是LLDMA (Link List DMA)
PCIe实践之路:DMA机制 中描述的很好(虽然图画的不怎么形象): 将每一个DMA传输 用链表连起来,一次发送多个DMA传输。
这样似乎解决了DMA需求的:内存物理地址连续。 但 实质上 是 将DMA化成了多次传输。 Linux下DMA驱动框架分析 的图片画的不错: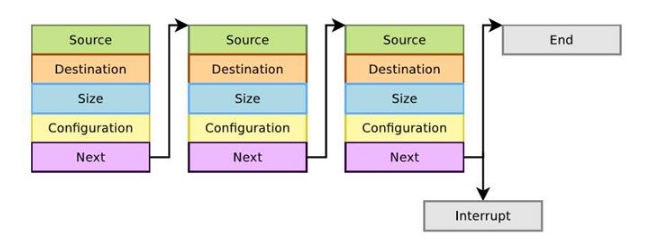
IOMMU是如何实现的?
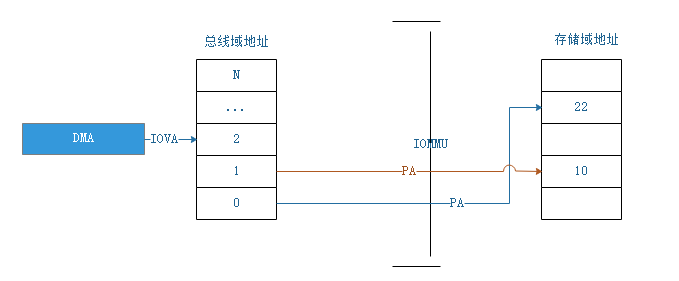
可以看到,DMA加入了IOMMU后,只要给总线域的地址(IOVA-在开启stage2 MMU情况下,IOVA就是GPA,在开启stage1+2 MMU情况下,IOVA是GVA)保持连续就好,也就是虚拟地址连续就行。DMA发出地址信号后,由IOMMU去关联到对应的存储域地址。
VFIO
VFIO基础知识
参考:
- An Introduction to PCI Device Assignment with VFIO - Williamson
- Introduction to VFIO
- QEMU/KVM源码解析及应用-李强 7.7章节
- Linux内核VFIO
VFIO的作用
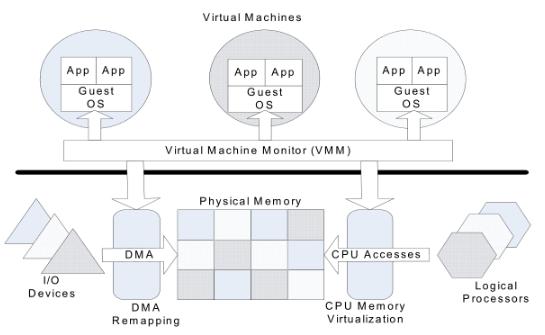
VFIO的目的是把设备的DMA能力直接暴露到用户态,也就是说:基于IOMMU功能,用户层可以直接用设备的DMA功能。
vfio的基本思想和原理
vfio是一个用户态驱动框架,利用硬件I/O虚拟化技术,将设备直通给虚拟机。
vfio的基本思想:
- 分解:将设备资源分解,并将资源接口导出到用户空间。
- 聚合:将硬件设备资源聚合,对虚拟化展示一个完整的设备接口。
IOMMU需要关注的事:
难点1:地址隔离,因为DMA可以指定任意地址。 IOMMU需要将主机保护起来,只允许DMA给自己当前 Guest 内存空间写入。
难点2:MSI的中断重定向, 使设备能根据自己所属domain,而只给当前Guest产生中断。
VFIO工作的机制:
IOVA- io virtual address 文章中对VFIO有了部分描述比较通俗易懂:
人们需要支持虚拟化,提出了VFIO的概念,需要在用户进程中直接访问设备,那我们就要支持在用户态直接发起DMA操作了,用户态发起DMA,它自己在分配iova,直接设置下来,要求iommu就用这个iova,那我内核对这个设备做dma_map,也要分配iova。这两者冲突怎么解决呢?
VFIO这样解决:
默认情况下,iommu上会绑定一个default_domain,它具有IOMMU_DOMAIN_DMA属性,原来怎么弄就怎么弄,这时你可以调用dma_map()。
但如果你要用VFIO,你就要先detach原来的驱动,改用VFIO的驱动,VFIO就给你换一个domain,这个domain的属性是IOMMU_DOMAIN_UNMANAGED,之后你爱用哪个iova就用那个iova,你自己保证不会冲突就好,VFIO通过iommu_map(domain, iova, pa)来执行这种映射。
等你从VFIO上detach,把你的domain删除了,这个iommu就会恢复原来的default_domain,这样你就可以继续用你的dma API了。
这种情况下,你必须给你的设备选一种应用模式,非此即彼。
所以这就是直通模式 和 SR-IOV模式时,必须先将PCIE设备unbind掉并添加到vfio-driver中,才可以导入到虚拟机。 其实就是 IOMMU-DOMAIN的更换。
VFIO框架
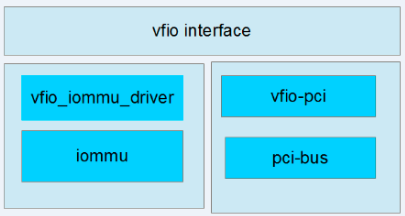
- VFIO Interface : 讲group,container,device 给用户层提供了字符设备接口,直接ioctl来控制设备。
- iommu driver 是物理硬件提供IOMMU的驱动实现,然后注册到vfio中,这里都是TYPE1
- pci bus : 物理pci设备驱动
- vfio_iommu 对底层iommu driver封装
- vfio-pci 是对设备驱动的封装。
VFIO的Container,group和device
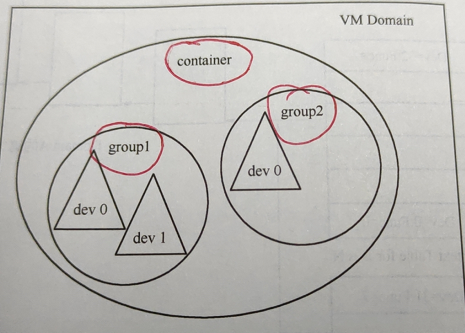
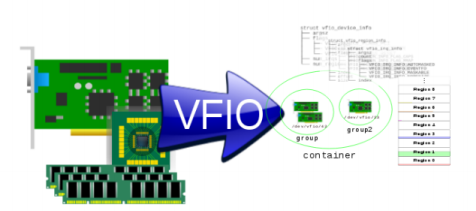
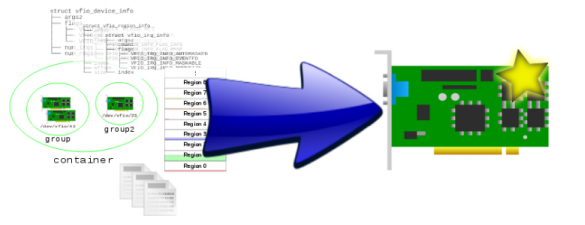
group 是IOMMU进行DMA隔离的最小单元, 一个group可以有1-N个设备。
container 是由多个group组成,为了更好的管理分割粒度,所以将多个group 看作一个container。
一般来说,一个进程/虚拟机可以看作一个container,这样一个container就共享同一组页表。
VFIO的三个子系统
听说过VFIO,VFIO-PCI,VFIO-MDEV(后边看),但这几个有什么区别?都是干什么的?
Linux iommu和vfio概念空间解构 中给了不错的解释:
首先说,vfio就是一个驱动模块,它的作用是通过device的override_driver接口(通过/sys直接强行重新绑定一个设备的驱动),让自己成为那个设备的驱动,在这个驱动中,把这个设备的io空间和iommu_group直接暴露到用户态。
/home/baiy/workspace/linux-git/drivers/vfioroot@inno-MS-7B89:vfio# ls -altotal 180drwxrwxrwx 5 baiy baiy 4096 12月 11 09:46 .drwxrwxrwx 131 baiy baiy 4096 12月 11 09:46 ..-rwxrwxrwx 1 baiy baiy 1462 12月 11 09:46 Kconfig-rwxrwxrwx 1 baiy baiy 402 12月 5 15:42 Makefiledrwxrwxrwx 2 baiy baiy 4096 12月 11 09:46 mdev // mdev子系统drwxrwxrwx 2 baiy baiy 4096 12月 11 09:46 pci // pci 子系统drwxrwxrwx 3 baiy baiy 4096 12月 11 09:46 platform // platform子系统-rwxrwxrwx 1 baiy baiy 59147 12月 11 09:46 vfio.c-rwxrwxrwx 1 baiy baiy 33818 12月 11 09:46 vfio_iommu_spapr_tce.c-rwxrwxrwx 1 baiy baiy 41122 12月 11 09:46 vfio_iommu_type1.c-rwxrwxrwx 1 baiy baiy 2812 12月 11 09:46 vfio_spapr_eeh.c-rwxrwxrwx 1 baiy baiy 5597 12月 11 09:46 virqfd.c
VFIO使用
- 首先确保是否开启了VT-d等硬件功能。
```bash
因为IOMMU和EPT共用页表项,所以也需要判断下是否支持内存虚拟化
判断CPU是否支持虚拟化,Intel系列CPU支持虚拟化的标志为“vmx”,AMD系列CPU的标志为“svm”
baiy@baiy-ThinkPad-E470c:~$ grep -E ‘svm|vmx’ /proc/cpuinfo flags : ….. vmx …..
判断是否开启了基础虚拟化功能
baiy@internal:baiy$ kvm-ok INFO: /dev/kvm exists KVM acceleration can be used
判断是否开启VT-D,这个只支持Intel机器
baiy@internal:baiy$ dmesg | grep “DMAR-IR: Enabled IRQ remapping” [ 0.004000] DMAR-IR: Enabled IRQ remapping in x2apic mode
- 其次确保内核有配置相关模块,对于编译成模块的在Ubuntu下建议放到 /etc/modules,参考[Loadable_Modules](https://help.ubuntu.com/community/Loadable_Modules)```bashroot@inno-MS-7B89:linux-git# vim /boot/config-$(uname -r).....CONFIG_VFIO_IOMMU_TYPE1=yCONFIG_VFIO_VIRQFD=yCONFIG_VFIO=yCONFIG_VFIO_NOIOMMU=yCONFIG_VFIO_PCI=yCONFIG_VFIO_PCI_VGA=yCONFIG_VFIO_PCI_MMAP=yCONFIG_VFIO_PCI_INTX=yCONFIG_VFIO_PCI_IGD=yCONFIG_VFIO_MDEV=m // 使用vfio-mdev需要将这两个模块也添加进去CONFIG_VFIO_MDEV_DEVICE=m
- 开启虚拟化时加入vfio设备-qemu方式
```bash
假如设备如下
26:00.0 Memory controller: Xilinx Corporation Device 9032 (rev 03)
确定这个设备所属group,因为group 是IOMMU 进行DMA隔离的最小单元
如果设备对应的RC以及switch设备一旦不支持PCIE ACS路由功能,那么凉凉,
因为IOMMU会将整个RC都挂到同一个group中, 后边分离后会将整个RC桥都分离。
root@inno-MS-7B89:pci0000:00# dmesg | grep group [ 1.070368] pci 0000:26:00.0: Adding to iommu group 18 [ 1.070400] pci 0000:26:00.1: Adding to iommu group 18 root@inno-MS-7B89:pci0000:00# ls -al /sys/bus/pci/devices/0000\:26\:00.0/iommu_group lrwxrwxrwx 1 root root 0 12月 19 15:23 /sys/bus/pci/devices/0000:26:00.0/iommu_group -> ../../../../kernel/iommu_groups/18
解除绑定
注:也可通过 https://github.com/andre-richter/vfio-pci-bind 提供的方法进行解除绑定 root@inno-MS-7B89:iommu_groups# lspci -s 26:00.0 -knx …… Kernel driver in use: xxxx
echo 0000:26:00.0 >/sys/bus/pci/devices/0000:26:00.0/driver/unbind
将设备挂到vfio上
echo “${vendor} ${device}” > /sys/bus/pci/drivers/vfio-pci/new_id
直通或者SR-IOV设备
-device vfio-pci,host=26:00.0,addr=xx # 在Guest上,这个addr就是在Guest上BDF的Device号,避免编号冲突而已。随便找个8*[0~31]就好了
- 开启Guest时加入vfio设备-libvirtd方式-TBD,没找到相关资料<a name="34RWV"></a>### VFIO代码分析> 这里不考虑 CONFIG_VFIO_NOIOMMU 的情况,虽然ubuntu默认支持。详情参考: [VFIO No-IOMMU支持](https://cateee.net/lkddb/web-lkddb/VFIO_NOIOMMU.html)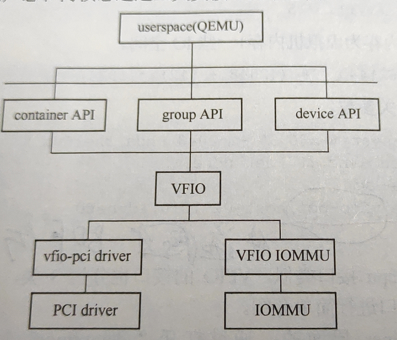<br />代码流程无非就是:** 容器操作,组操作,设备操作 三类,**这里参考《QEMU/KVM源码解析及应用-李强》 7.7章节,不在重复<a name="nDNLZ"></a>#### 容器的初始化代码容器初始化代码基本固定的。```c#include <linux/vfio.h>cfd = open("/dev/vfio/vfio", O_RDWR);if(ioctl(cfd, VFIO_GET_API_VERSION, buf) == 0){if(ioctl(cfd, VFIO_CHECK_EXTENSION, VFIO_TYPE1_IOMMU) == 0){ioctl(cfd, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU);}}close(cfd)
在内核初始化,以及容器 这部分初始化代码下,代码结构如下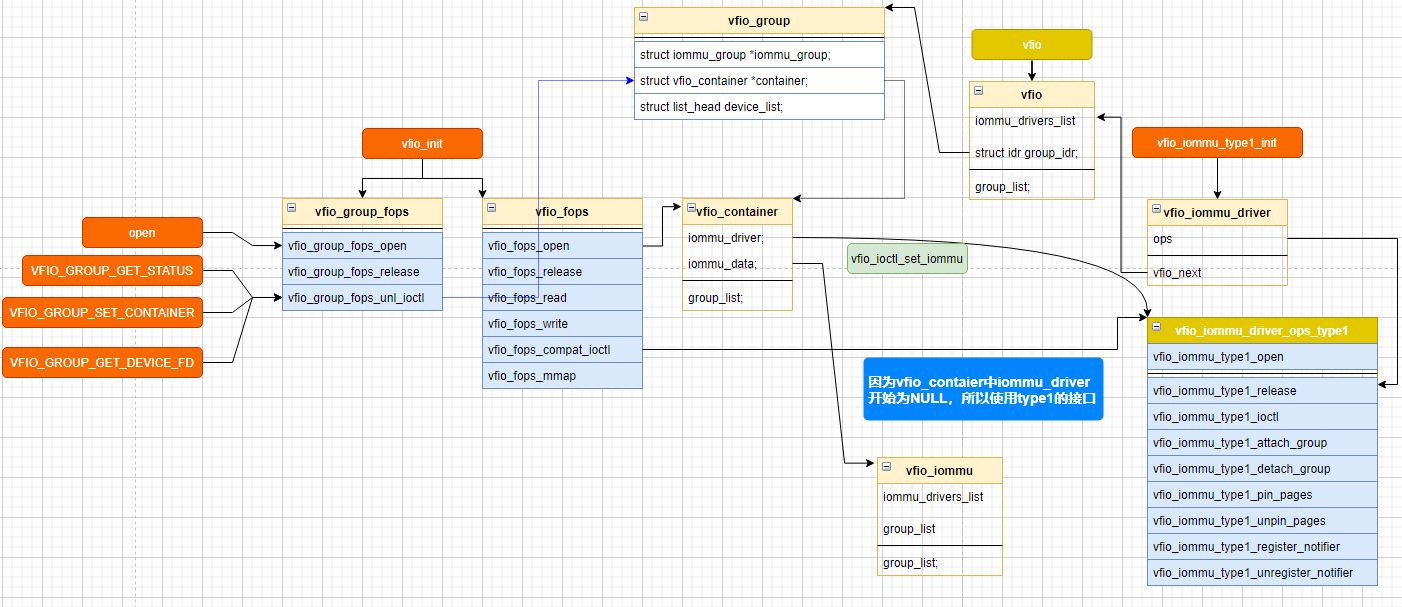
所以用户态调用ioctl接口,在vfio_ioctl_set_iommu之后,大部分都调用到 vfio_iommu_type1_ioctl 中(除获取版本等)。
# linux-git\drivers\vfio\vfio.cvfio_initmisc_register(&vfio_dev); // /dev/vfio/vfio misc字符设备,操作接口是:vfio_dev的vfio_fops这里可以看到ioctl在用户空间VFIO_SET_IOMMU ,会调用 vfio_iommu_type1_ioctl
group初始化
我们先不讨论一个pci设备是如何添加到 /dev/vfio/$(group num)的,假设已经添加进来(也就是后边pci设备bind到vfio中),有什么变化
// group操作gfd = open("/dev/vfio/18", O_RDWR); // file->private == vfio_groupif(gfd < 0){perror("open gfd failed\n");goto err1;}// 判断是否是个属于vfio的有效group,并绑定到容器中 , 根据container fd,将group绑定到container中err = ioctl(gfd, VFIO_GROUP_GET_STATUS, &group_status);if( (err == -1) || ((group_status.flags & VFIO_GROUP_FLAGS_VIABLE) == 0) ){perror("invaild group for vfio\n");goto err2;}if( group_status.flags & VFIO_GROUP_FLAGS_CONTAINER_SET) {printf("group has set\n");} else {ioctl(gfd, VFIO_GROUP_SET_CONTAINER, cfd);}err = ioctl(gfd, VFIO_GROUP_GET_STATUS, &group_status);
pci device
VFIO模拟PCIE 配置空间的方式.docx
先看下在probe之前vfio_pci都做了哪些准备. TBD
struct perm_bits {u8 *virt; /* read/write virtual data, not hw */u8 *write; /* writeable bits */int (*readfn)(struct vfio_pci_device *vdev, int pos, int count,struct perm_bits *perm, int offset, __le32 *val);int (*writefn)(struct vfio_pci_device *vdev, int pos, int count,struct perm_bits *perm, int offset, __le32 val);};static struct perm_bits cap_perms[PCI_CAP_ID_MAX + 1] = {[0 ... PCI_CAP_ID_MAX] = { .readfn = vfio_direct_config_read }};vfio_pci_init_perm_bits();
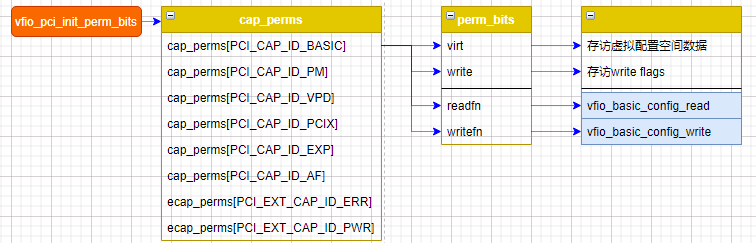
在进行
echo “${vendor} ${device}” > /sys/bus/pci/drivers/vfio-pci/new_id
的时候,肯定会进入到probe,看下probe都做了什么
vfio_add_group_dev(&pdev->dev, &vfio_pci_ops, vdev);struct iommu_group *iommu_group = iommu_group_get(dev); // 根据实际pcie设备获取所属的iommu_gruopstruct vfio_group *group = vfio_group_get_from_iommu(iommu_group);// struct vfio_device * = vfio_group_get_device(group, dev); 这里只是检测下是否已经有该设备,不允许多次添加struct vfio_device *device = vfio_group_create_device(group, dev, ops, device_data);
可见这部分代码主要是: 例化了vfio_group和vfio_device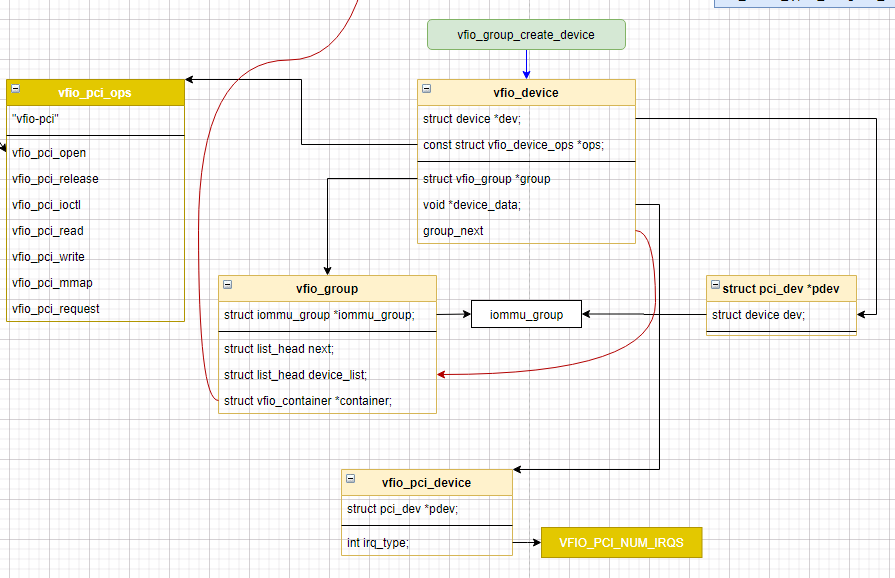
接下来看用户如何操作设备的
// 设备操作接口dfd = ioctl(gfd, VFIO_GROUP_GET_DEVICE_FD, "0000:26:00.0");if( (dfd == -1)){perror("get device failed\n");goto err2;}printf("get device OK\n");ioctl(dfd,VFIO_DEVICE_GET_INFO,&device_info);ioctl(dfd,VFIO_GET_IRQ_INFO,&irq);ioctl(dfd,VFIO_DEVICE_RESET);
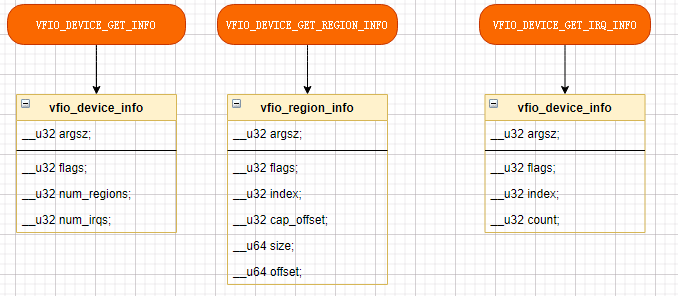
VFIO_GROUP_GET_DEVICE_FD 是如何获取fd的?(重点)
vfio_group_fops_unl_ioctlvfio_group_get_device_fd(group, buf);device->ops->open(device->device_data);vfio_pci_open(vfio_pci_device) // vfio_pci_probe 中的vdevvfio_pci_enable(vdev); // 第一次会使能PCIEpci_enable_device(pdev);pci_try_reset_function(pdev); // 所以之前遇到过 SR-IOV中VF复位异常原因anon_inode_getfile("[vfio-device]", &vfio_device_fops,); // 重点接口,vfio_device_fops 的接口最终都会调用到 vfio_pci_opsfd_install(ret, filep); // 返回文件描述符
重要接口快速查询
这里避免混乱,强调几个重要接口
container的操作接口: vfio_fops (在用户空间执行 VFIO_SET_IOMMU 之后,基本都是 vfio_iommu_driver_ops_type1 )
group的操作接口: vfio_group_fops
device的接口 vfio_pci_ops ,在VFIO_GROUP_GET_DEVICE_FD 获取到设备的文件描述符后,给用户层对接的接口是: vfio_device_fops, 然后这部分最终都调用vfio_pci_ops
VFIO-MDEV
相关资料
使用前提:
insmod /lib/modules/5.4.0-58-generic/kernel/drivers/vfio/mdev/mdev.koinsmod /lib/modules/5.4.0-58-generic/kernel/drivers/vfio/mdev/vfio_mdev.ko
vfio-mdev模型的核心在于mdev会对硬件设备的状态进行抽象,将硬件设备的“状态”保存在mdev device数据结构中, 设备驱动层面要求实现一个调度器,将多个mdev设备在硬件设备上进行调度(分时复用), 从而实现把一个物理硬件设备分享给多个虚拟机实例进行使用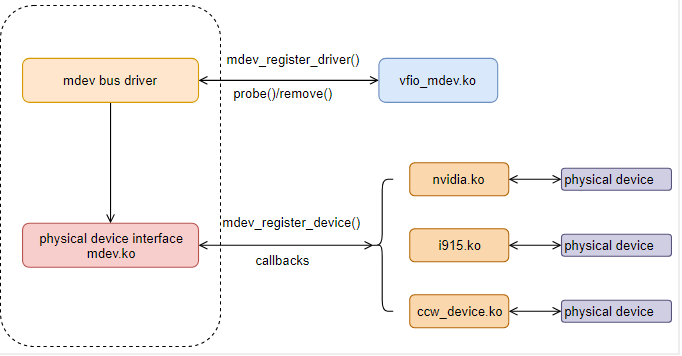
框架看起来很简单,接下来分析下: KERNEL_DOC-VFIO Mediated devices 中提供的 mtty.c 以及 vfio-mdev源码.
初始化过程
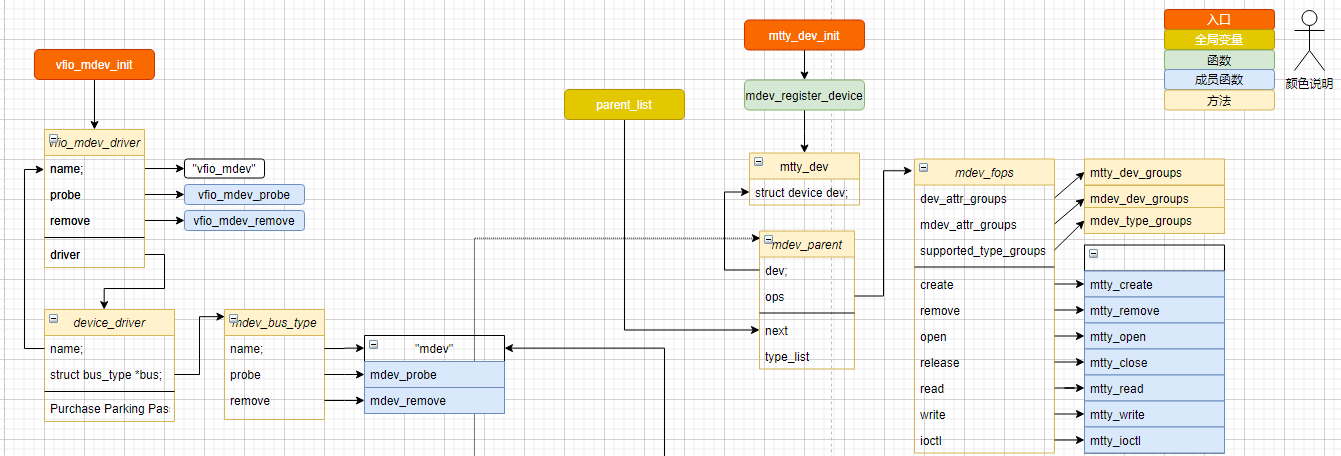
这里经过测试,很疑惑为什么会出现 mtty-1和mtty-2
root@inno-MS-7B89:testntty# pwd/sys/devices/virtual/mtty/testnttyroot@inno-MS-7B89:testntty# tree mdev_supported_types/mdev_supported_types/├── mtty-1│ ├── available_instances│ ├── create│ ├── device_api│ ├── devices│ └── name└── mtty-2├── available_instances├── create├── device_api├── devices│ └── 83b8f4f2-509f-382f-3c1e-e6bfe0fa1001 -> ../../../83b8f4f2-509f-382f-3c1e-e6bfe0fa1001└── name分析代码:mdev_register_deviceparent_create_sysfs_files(parent); // struct mdev_parent *parent;kset_create_and_add("mdev_supported_types",...); // 创建mdev_supported_types目录add_mdev_supported_type_groups(parent);parent->ops->supported_type_groups[i] // 所以主要看这部分 创建了 mtty-1和mtty-2,add_mdev_supported_type(parent, parent->ops->supported_type_groups[i]);这里ops 来源 调用mdev_register_devicemtty_dev_initmdev_register_device(&mtty_dev.dev, &mdev_fops); // mdev_fops 中 .supported_type_groups = mdev_type_groups,static struct attribute_group *mdev_type_groups[] = { // 两边属性一致,随意使用&mdev_type_group1,&mdev_type_group2,NULL,};
这里有几个部分需要注意下:
- mtty_dev_init->class_compat_register(“mdev_bus”) 所以 必须注册任意一个vfio-mdev驱动后,才会有 /sys/class/mdev_bus 节点
问题:加入有N个虚拟机,需要用channel来区分,怎么办?
考虑用uuid作为区分,然后根据uuid来索引channel index
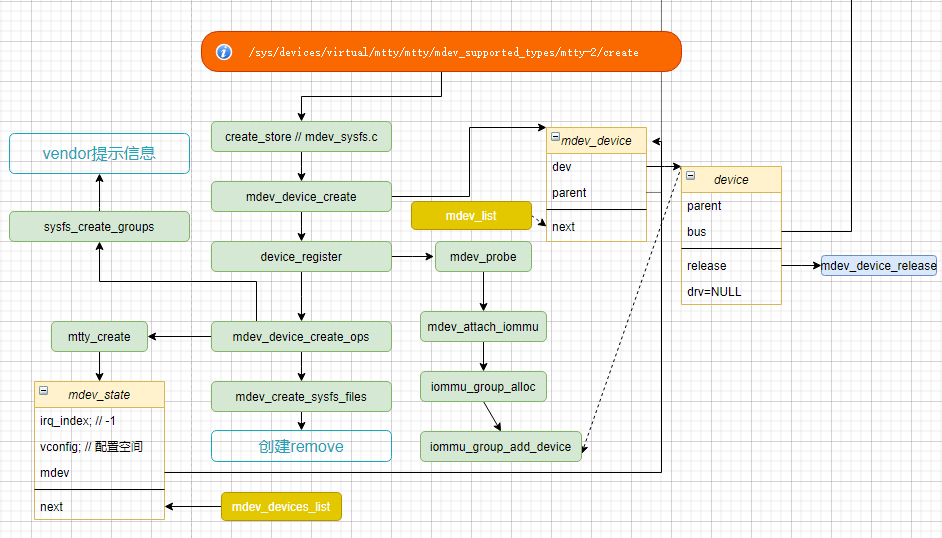
问题:如何区分channelmdev_device_createstruct mdev_device *mdev; // 创建了mdev;list_add(&mdev->next, &mdev_list); // 添加到全局变量memcpy(&mdev->uuid, &uuid, sizeof(uuid_le)); // uuid, 所以可以遍历mdev来根据uuid查找 mdev_device在用户空间创建接口的时候:mtty_createmdev_set_drvdata(mdev, mdev_state); // 分配私有的mdev_state结构 . 所以要加channel在这里加// 上层调用了 open/read/write/close等接口,会传递 struct mdev_device,// 在mtty中根据:struct mdev_state *mdev_state;mdev_state = mdev_get_drvdata(mdev); // 获取私有的mdev_state结构比如:echo "83b8f4f2-509f-382f-3c1e-e6bfe0fa1000" > /sys/devices/virtual/mtty/mtty/mdev_supported_types/mtty-1/create内核mtty_create打印uuid:注意:在create_store 会将断续转换[51509.484676] [vfio_get_channel:855] mdev id is[51509.484678] 0xf2[51509.484679] 0xf4[51509.484679] 0xb8[51509.484679] 0x83[51509.484679] 0x9f[51509.484680] 0x50[51509.484680] 0x2f[51509.484680] 0x38[51509.484681] 0x3c[51509.484681] 0x1e[51509.484681] 0xe6[51509.484681] 0xbf[51509.484682] 0xe0[51509.484682] 0xfa[51509.484682] 0x10[51509.484683] 0x00[51509.484880] vfio_mdev 83b8f4f2-509f-382f-3c1e-e6bfe0fa1000: Adding to iommu group 24[51509.484882] vfio_mdev 83b8f4f2-509f-382f-3c1e-e6bfe0fa1000: MDEV: group_id = 24echo 1 > /sys/bus/mdev/devices/83b8f4f2-509f-382f-3c1e-e6bfe0fa1000/remove
这里提供一个channel 控制脚本
if [ "$1" == "create" ]thenecho "Start create 16 channel"for ((i=0; i<3; ++i))doa=$(printf "%02x" $i)echo "83b8f4f2-509f-382f-3c1e-e6bfe0fa10$a" > /sys/devices/virtual/mtty/mtty/mdev_supported_types/mtty-1/createdoneelseecho "Start delete 16 channel"for ((i=0;i<3;++i))doa=$(printf "%02x" $i)echo 1 > "/sys/bus/mdev/devices/83b8f4f2-509f-382f-3c1e-e6bfe0fa10$a/remove"donefi
使用
注:环境支持参考 VFIO使用章节。
-device vfio-pci,addr=08,\sysfsdev=/sys/bus/mdev/devices/83b8f4f2-509f-382f-3c1e-e6bfe0fa1001
注意:这些字段间不能又空格
看见初始化代码,整体比较完整,但好像缺了一部分? mdev_bus_type注册了没使用? 目前由于没看到vfio-pci部分,猜测vfio-pci注册了vfio_mdev_driver 会调用这部分接口
static const struct vfio_device_ops vfio_mdev_dev_ops = {.name = "vfio-mdev",.open = vfio_mdev_open, ===> mdev_fops.open ==> mtty_open.release = vfio_mdev_release, ===> mdev_fops.release ==> mtty_close.mmap = vfio_mdev_mmap, ===> mdev_fops.mmap ==> NULL// 重点接口.ioctl = vfio_mdev_unlocked_ioctl, ===> mdev_fops.ioctl ==> mtty_ioctl.read = vfio_mdev_read, ===> mdev_fops.read ==> mtty_read.write = vfio_mdev_write, ===> mdev_fops.write ==> mtty_write};
所以,在vfio-mdev被Guest识别到后,调用的其实是 vfio_mdev_dev_ops,但这部分最终 只需要关心 mdev_fops 接口就好了。
create
echo "83b8f4f2-509f-382f-3c1e-e6bfe0fa1001" > \/sys/devices/virtual/mtty/mtty/mdev_supported_types/mtty-2/create
实现如下:
mtty_createstruct mdev_state *mdev_state;mdev_state->vconfig = kzalloc(MTTY_CONFIG_SPACE_SIZE, GFP_KERNEL); // 模拟PCI设备,创建配置空间mtty_create_config_space(mdev_state);list_add(&mdev_state->next, &mdev_devices_list);
qemu初始化操作
还记得前边描述的vfio是如何使用设备的?
- open
- ioctl VFIO_DEVICE_RESET
- ioctl VFIO_DEVICE_GET_INFO
- ioctl VFIO_DEVICE_GET_REGION_INFO
- ioctl VFIO_GET_IRQ_INFO
// 设备操作接口dfd = ioctl(gfd, VFIO_GROUP_GET_DEVICE_FD, "0000:26:00.0");vfio_group_get_device_fd(group, buf);device->ops->open(device->device_data);mtty_open(vfio_pci_device) //===> 先会调用open接口,获取到文件描述符,提供对用层VFS的接口 vfio_device_fops// 其实不用关心 vfio_device_fops,只需要关注自己设备注册的接口就好,最后调用的还是 mdev_fops// 可能会调用reset接口:VFIO_DEVICE_RESETprintf("get device OK\n");ioctl(dfd,VFIO_DEVICE_GET_INFO,&device_info); // VFIO_DEVICE_GET_INFOioctl(dfd,VFIO_DEVICE_GET_REGION_INFO,®); // VFIO_DEVICE_GET_REGION_INFOioctl(dfd,VFIO_GET_IRQ_INFO,&irq); // VFIO_DEVICE_GET_IRQ_INFOioctl(dfd,VFIO_DEVICE_RESET); // VFIO_DEVICE_RESET
Guest系统初始化
注:调试阶段最好吧mtty的打印信息打开
#define DEBUG_REGS 1#define DEBUG_INTR 1#define DEBUG 1
- 读取配置空间
- 读取OPTION ROM
- set IRQ
读写操作
上层接口无论读写BAR空间还是配置空间,接口都会调用到:mtty_write 和 mtty_read
还记得在:ioctl中 VFIO_DEVICE_GET_REGION_INFO 有一个很重要的信息:
mtty_get_region_info#define MTTY_VFIO_PCI_OFFSET_SHIFT 40region_info->offset = MTTY_VFIO_PCI_INDEX_TO_OFFSET(bar_index); // region_info->offset[63:40]代表区域mtty_read / mtty_write 中 ppos有个很大的作用:然后在 mdev_access (mtty_read / mtty_write 中会调用)index = MTTY_VFIO_PCI_OFFSET_TO_INDEX(pos); // 所以 ppos[63:40]代表读写区域offset = pos & MTTY_VFIO_PCI_OFFSET_MASK; // 所以 ppos[40:0]为串口操作属性,比如THR,IER等配置,或RX/TX 数据消息enum {VFIO_PCI_BAR0_REGION_INDEX,VFIO_PCI_BAR1_REGION_INDEX,VFIO_PCI_BAR2_REGION_INDEX,VFIO_PCI_BAR3_REGION_INDEX,VFIO_PCI_BAR4_REGION_INDEX,VFIO_PCI_BAR5_REGION_INDEX,VFIO_PCI_ROM_REGION_INDEX,VFIO_PCI_CONFIG_REGION_INDEX,VFIO_PCI_VGA_REGION_INDEX,VFIO_PCI_NUM_REGIONS = 9 /* Fixed user ABI, region indexes >=9 use *//* device specific cap to define content. */};
先简单看下串口的一些属性: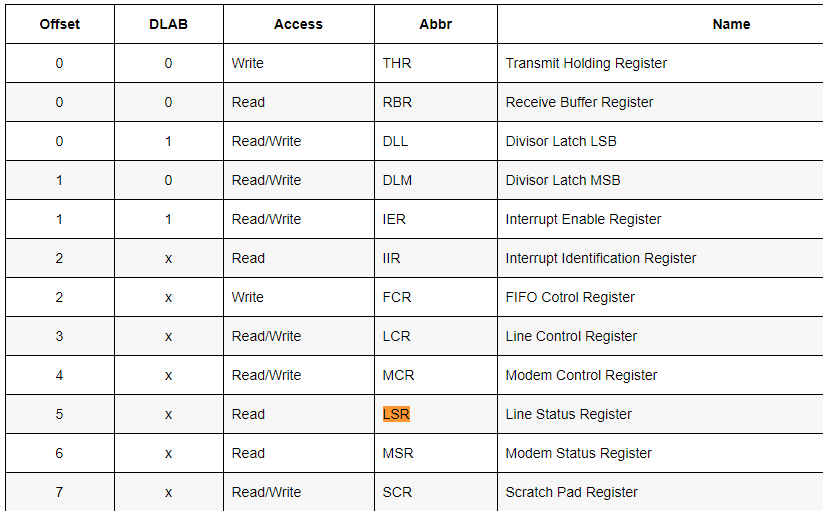
在分析打印日志的时候,注意读写操作的关键信息
# 数据读写mdev_access: BAR0 WR @0x4 MCR val:0x00 dlab:0BARn: 代表操作第几个portWR/RD: 读还是写MCR/TX/RX: 这串口的属性,也就是 ppos[39:0]的内容
中断触发
在测试的时候,会发现:如果没数据,单纯读,可能会无限阻塞,因为没中断。
在 KERNEL_DOC-VFIO Mediated devices 中最后描述了一句: 数据从主机mtty驱动程序环回。
所以我们要看读是怎么触发的,需要分析的是mtty_write->handle_bar_write->mtty_trigger_interrupt(mdev_state)
/** Trigger interrupt if receive data interrupt is* enabled and fifo reached trigger level*/if ((mdev_state->s[index].uart_reg[UART_IER] & UART_IER_RDI) && \(mdev_state->s[index].rxtx.count ==mdev_state->s[index].intr_trigger_level)){mtty_trigger_interrupt( mdev_uuid(mdev_state->mdev)); // mdev_uuid 在echo时调用 create_stor会赋值并绑定到mdev上}
这里判断 中断是否使能, 判断数据个数是否达到fifo阈值,然后进行触发中断
注:这里mttytrigger_interrupt 使用 Linux进程间通信:eventfd 来给qemu发送中断信息_,暂时不是我研究的重点,可以参考 Insight Into VFIO。
总结:如果说,VFIO PCI是 Guest 去访问硬件的中间层的话, 那么VFIO-MDEV就是模拟硬件,接到VFIO PCI上,作为一个伪PCI设备 来 欺骗VFIO_PCI。
VFIO-MTTY
其实看vfio-mtty代码得时候,我们不一定非要把pci设备当作一个uart设备,可以单纯当作一个PCIE设备,自己修改修改配置空间 ,
作为一个PCI设备,然后在Guest层加入自己得驱动。
另外,mtty read/write虽然代码只支持 1,2,4字节读写,看起来很low,但Guest 去读写后,也会转成1,2,4字节读写。
virt-manager如何添加vfio-pci设备
先在/etc/libvirt/qemu/ubuntu18.04.xml 中添加自己的配置
重点参考:formatdomain.html 中mdev描述
<hostdev mode='subsystem' type='mdev' managed='no' model='vfio-pci'><source><address uuid='83b8f4f2-509f-382f-3c1e-e6bfe0fa1001'/></source><address type='pci' domain='0x0000' bus='0x00' slot='0x09' function='0x0'/></hostdev>
注意:修改完成后一定要:更新配置 virsh define /etc/libvirt/qemu/ubuntu18.04.xml

若有收获,就点个赞吧
0 人点赞
