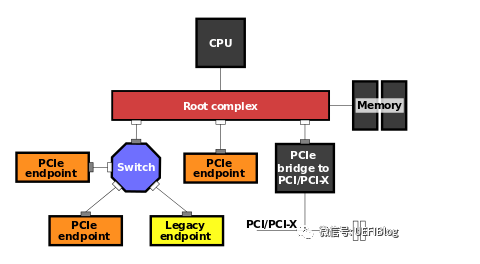
PCIE的传输层
相关文档
- PCI Express Base_r5_1.pdf 第2章
- PCIe学习笔记之Max payload size
- 《PCI+Express体系结构》第六章
相关书籍下载方式:
链接:https://pan.baidu.com/s/1zzWWt9ujVTr9oJSaJNP_mA
提取码:ahax
Posted 和Non Posted
参考:
- 《PCI+Express体系结构》 1.3.2章
- 了解PCI Express的Posted传输与Non-Posted传输
只有存储器写报文采用Posted模式,其他报文都采用 Non Posted模式。
什么时Posted和Non Posted模式?**
数据在PCIE链路过程中,因为可能要经过很多层 Switch 一级一级别的往下传输。
- Posted模式在传入下一级别的时候,可以释放上一级别的总线。 效率高。
Non Posted模式在传入下一级别的时候,不能及时释放上一级别的总线,
数据必须到达最终目的地后才能结束当前事务总线的传输方式。效率低。
针对 Non Posted模式采用Split传送,什么是Split传送?
Split传输可以看成是将请求和完成分开,分别使用Posted方式进行的传输。
TLP中负载参数
参考
- PCIe学习笔记之Max payload size
- 《PCI+Express体系结构》6.4章
- PCI Express Base_r5_1.pdf 中 7.5.3章节(PCIE CAP)
链路中的最大负载
PCI Express Base_r5_1.pdf 中 7.5.3章节(PCIE CAP,ID=0x10)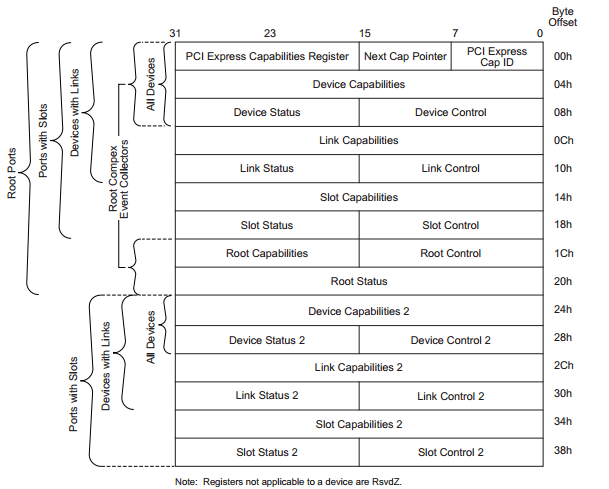
中关于Device部分又两个字段:
Device Capabilities Register (Offset 04h):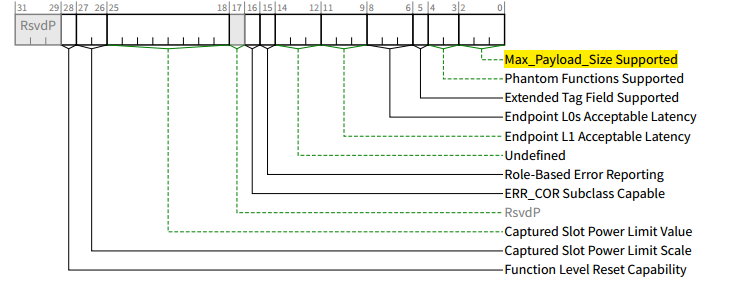
其中,Max_Payload_Size Supported - RO属性
Device Control Register (Offset 08h):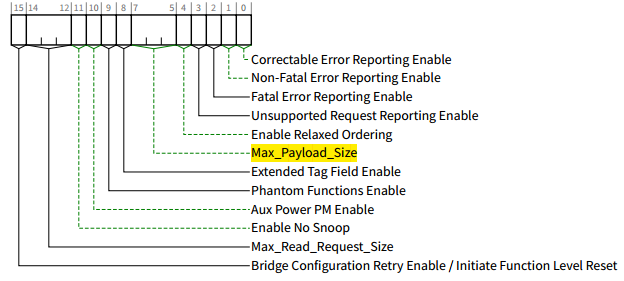
其中,Max_Payload_Size - RW属性,
PCIe设备是以TLP的形式发送报文的,而**max payload size(简称mps)**决定了pcie设备实际使用的tlp能够传输的最大字节数。mps的大小是由PCIe链路两端的设备协商决定的,PCIe设备发送TLP时,其最大payload不能超过mps的值。
允许仅支持128字节最大有效负载大小的函数将此字段硬连线到000b。
对于多功能设备的所有功能,不需要系统软件为该字段编程相同的值。有关重要指南,请参阅第2.2.2节。
对于ARI设备,最大有效负载大小仅由 Function 0 中的设置确定。其他功能中的设置总是返回软件为每个功能编程的任何值,但组件会忽略其他设置。
此字段的默认值为000b。
其中,Max Read Request_Size (简称mrrs) **表示每一个读请求所能够读到的最大字节数**。当PCIe设备发送memory读请求TLP时,该TLP所请求的数据的大小不能超过mrrs的值。
**
FAQ
为什么实际测试发现,使用 CPU进行 ioread8,ioread32, memcpy, memcpy_fromio等操作,实际抓到的数据长度为4?
https://stackoverflow.com/questions/41959436/memcpy-from-pcie-memory-takes-more-time-than-memcpy-to-pcie-memory
这里有一句话:
这是完全可以预期的,您对此无能为力。CPU只能发出串行字大小的读取和写入,由于协议开销,在PCIe链路上的吞吐量非常差。每个操作都具有与其相关的24或28字节时间的开销-这是12或16字节的TLP标头加上12字节时间的链路层开销,并且CPU一次只能操作4或8字节。 ..最好的情况是效率为25%(8 /(8 + 24)= 25%),最坏的情况下效率为12.5%(4 /(4 + 28)= 12.5%)。
另外,PCIE体系结构中P182页描述:
所以,有效负载好像是只有PCIE DMA才可以达到最大负载。
看网友的回复:http://bbs.chinaunix.net/thread-4259444-1-1.html 好像也只能用DMA进行负载测试。

若有收获,就点个赞吧
0 人点赞
