DMA
DMA原理
DMA的作用
DMA即Direct Memory Access,是一种允许 外设和主内存之间直接传输 数据 而没有CPU参与的技术,当外设对于该块内存的读写完成之后,DMAC通过中断通知CPU,然后由CPU完成后处理。
这种技术多用于对数据量和数据传输速度都有很高要求的外设控制,比如显示设备等。
注:DMA 依赖于系统。每一种体系结构DMA传输不同,编程接口也不同。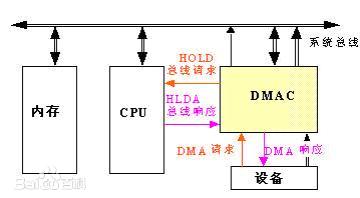
DMA的两种方式(软件请求和硬件异步传输)
数据传输可以以两种方式触发:一种软件请求数据,另一种由硬件异步传输。
在第一种情况下,调用的步骤可以概括如下(以read为例):
(1)在进程调用 read 时,驱动程序的方法分配一个 DMA 缓冲区,随后指示硬件传送它的数据。进程进入睡眠。
(2)硬件将数据写入 DMA 缓冲区并在完成时产生一个中断。
(3)中断处理程序获得输入数据,应答中断,最后唤醒进程,该进程现在可以读取数据了。
第二种情形是在 DMA 被异步使用时发生的。以数据采集设备为例:
(1)硬件发出中断来通知新的数据已经到达。
(2)中断处理程序分配一个DMA缓冲区。
(3)外围设备将数据写入缓冲区,然后在完成时发出另一个中断。
(4)处理程序利用DMA分发新的数据,唤醒任何相关进程。
网卡传输也是如此,网卡有一个循环缓冲区(通常叫做 DMA 环形缓冲区)建立在与处理器共享的内存中。每一个输入数据包被放置在环形缓冲区中下一个可用缓冲区,并且发出中断。然后驱动程序将网络数据包传给内核的其它部分处理,并在环形缓冲区中放置一个新的 DMA 缓冲区。
DMA的传送过程
DMA的数据传送分为预处理、数据传送和后处理3个阶段。
(1)预处理
由CPU完成一些必要的准备工作。首先,CPU执行几条I/O指令,用以测试I/O设备状态,向DMA控制器的有关寄存器置初值,设置传送方向、启动该设备等。然后,CPU继续执行原来的程序,直到I/O设备准备好发送的数据(输入情况)或接受的数据(输出情况)时,I/O设备向DMA控制器发送DMA请求,再由DMA控制器向CPU发送总线请求(统称为DMA请求),用以传输数据。
(2)数据传送
DMA的数据传输可以以单字节(或字)为基本单位,对于以数据块为单位的传送(如银盘),DMA占用总线后的数据输入和输出操作都是通过循环来实现。需要特别之处的是,这一循环也是由DMA控制器(而不是通过CPU执行程序)实现的,即数据传送阶段是完全由DMA(硬件)来控制的。
(3)后处理
DMA控制器向CPU发送中断请求,CPU执行中断服务程序做DMA结束处理,包括检验送入主存的数据是否正确,测试传送过程中是否出错(错误则转入诊断程序)和决定是否继续使用DMA传送其他数据块等。
DMA与缓存一致性
Cache与DMA本身并不相关。但Cache被CPU当作内存的缓存使用。
假如DMA操作的内存范围与Cache并没有重叠,那DMA与Cache没关系。但DMA的内存与Cache缓存有重叠区域,那么CPU读取Cache的数据可能与内存数据不一致(内存对应数据被DMA修改,但CPU不知道,认为Cache的数据就是内存中的数据)。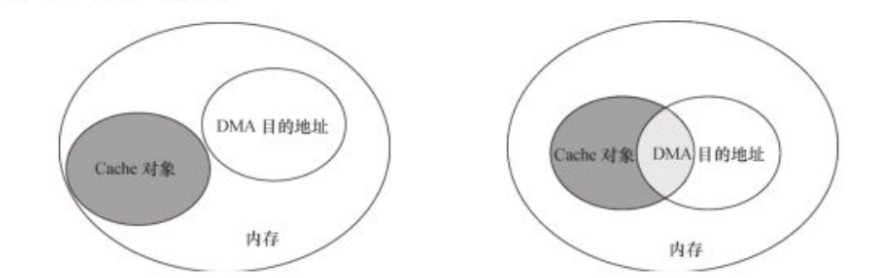
总线地址和存储域地址
简单说,就是 在不同得角度存在三种地址空间:
CPU角度: MMIO体系得CPU将所有得外设,内存 等设备 看成统一编址得地址空间, 比如32位CPU支持 2^32=4G得存储域地址空间,具体有多大范围看CPU访问得总线位宽。
DDR控制器角度: 内存地址空间 , 只能看到自己内存条得实际物理空间。
总线地址空间: 从总线外边得角度,看待主机, 也有一套自己得地址空间寻址。
Dynamic DMA mapping Guide(翻译: DMA-API-HOWTO.txt)中 描述了虚拟地址和总线地址
驱动在调用dma_map_single/dma_alloc_coherent 这样的接口函数的时候会传递一个虚拟地址X,在这个函数中会设定IOMMU的页表,将地址X映射到Z,并且将返回z这个总线地址
CPU CPU BusVirtual Physical AddressAddress Address SpaceSpace Space+-------+ +------+ +------+| | |MMIO | Offset | || | Virtual |Space | applied | |C +-------+ --------> B +------+ ----------> +------+ A| | mapping | | by host | |+-----+ | | | | bridge | | +--------+| | | | +------+ | | | || CPU | | | | RAM | | | | Device || | | | | | | | | |+-----+ +-------+ +------+ +------+ +--------+| | Virtual |Buffer| Mapping | |X +-------+ --------> Y +------+ <---------- +------+ Z| | mapping | RAM | by IOMMU| | | || | | |+-------+ +------+
DMA的使用
基础知识(重点)
参考文献
- Dynamic DMA mapping Guide (翻译: DMA-API-HOWTO.txt):详细描述了哪些内存可以被DMA设备访问到。
- linux驱动之DMA :详细举例说明了ARM的DMA历程(使用外设的DMA),另外他的参考文献也挺多。
- zynq PS侧DMA驱动 : 详细说明了ARM的DMA历程(使用HOST DMA)。
重点:
DMA buffer的物理地址连续(除非启用IOMMU)。
vmalloc等申请的内存,是不可以用dma传输的。 即使用了scatter-gather,也非常麻烦。推荐用 get_free_pages或者kmalloc系列接口,或者一致性DMA等。
虚拟地址通过 **__pa(va) ** 转成物理地址, 也一定不要直接使用,需要调用 dma_map_single 转成 总线地址才可以。
注:在AMD机器上开了IOMMU,使用DMA直接给__pa(va) 传输一定会出现 page_fault。
注:一致性DMA(会判断是否开启IOMMU)直接返回的就是总线地址,不需要再转换。
- dma总线位数限制 通过dma_set_mask去配置;
- 一致性的DMA映射并不意味着不需要memory barrier这样的工具DMA_BIDIRECTIONAL来保证memory order,CPU有可能为了性能而重排对consistent memory上内存访问指令 (其实用LDD3在流式DMA中的话来说:一旦映射后,驱动就别瞎JB去修改这部分存储,直到释放后,再来修改**)**
```c
// 虚拟地址转 直接 换为总线地址
include
define dma_map_single(d, a, s, r) dma_map_single_attrs(d, a, s, r, 0)
define dma_unmap_single(d, a, s, r) dma_unmap_single_attrs(d, a, s, r, 0)
或者直接调用 static inline dma_addr_t DMA_BIDIRECTIONAL(struct device dev, void ptr, size_t size, enum dma_data_direction dir, unsigned long attrs) // ……中间驱动一定别去修改,否则后果未知…. static inline void dma_unmap_single_attrs(struct device dev, dma_addr_t addr, size_t size, enum dma_data_direction dir, unsigned long attrs) / 枚举类型dma_data_direction: DMA_TO_DEVICE 数据发送到设备(如write系统调用) DMA_FROM_DEVICE 数据被发送到 CPU DMA_BIDIRECTIONAL 数据可双向移动 DMA_NONE 出于调试目的。 */
// dma_set_mask int using_dac; if (!dma_set_mask(dev, DMA_BIT_MASK(64))) { using_dac = 1; } else if (!dma_set_mask(dev, DMA_BIT_MASK(32))) { using_dac = 0; } else { dev_warn(dev, “mydev: No suitable DMA available\n”); goto ignore_this_device; }
**疑问: dma_map_single 和 dma_unmap_single 其实就是流式DMA映射,推断这部分在调用后,不仅仅获取了总线地址,更重要的是 刷新了下cache(dma_map_single ) 和 标记 cache invalidate(dma_unmap_single_attrs),但看没有IOMMU的操作时,并没有关于cache的部分啊??const struct dma_map_ops nommu_dma_ops 压根就没实现 unmap啊?**<br />有人说:X86的硬件比较牛逼,可以自己管理缓存?- DMA也根据所处位置,分为设备端和HOST端。有的外设上自带DMA,比如PCIE,可以直接用外设的DMA。有的只能使用HOST的DMA去配置。
// PC端的HOST DMA 好像都是DMA/PCI桥设备,反正当DMA用就好了。 baiy@inno-MS-7B89:linux-git$ ls -al /sys/class/dma total 0 drwxr-xr-x 2 root root 0 12月 9 14:33 . drwxr-xr-x 71 root root 0 12月 9 14:33 .. lrwxrwxrwx 1 root root 0 12月 9 14:33 dma0chan0 -> ../../devices/pci0000:00/0000:00:08.1/0000:28:00.1/dma/dma0chan0 lrwxrwxrwx 1 root root 0 12月 9 14:33 dma0chan1 -> ../../devices/pci0000:00/0000:00:08.1/0000:28:00.1/dma/dma0chan1 lrwxrwxrwx 1 root root 0 12月 9 14:33 dma0chan2 -> ../../devices/pci0000:00/0000:00:08.1/0000:28:00.1/dma/dma0chan2 lrwxrwxrwx 1 root root 0 12月 9 14:33 dma0chan3 -> ../../devices/pci0000:00/0000:00:08.1/0000:28:00.1/dma/dma0chan3 lrwxrwxrwx 1 root root 0 12月 9 14:33 dma0chan4 -> ../../devices/pci0000:00/0000:00:08.1/0000:28:00.1/dma/dma0chan4
注:AMD机器上这个dma0chan0是Encryption注册的 baiy@inno-MS-7B89:test03$ lspci -s 28:00.01 28:00.1 Encryption controller: Advanced Micro Devices, Inc. [AMD] Device 1486
__dma_request_channel // 是从HOST端去分配DMA的 dma_request_chan // 是从设备端去分配DMA的,相应的ACPI和设备树上需要描述。
<a name="hgXBX"></a>#### DMA使用流程<a name="5NJyu"></a>#### dmaengine标准API使用(重点)相关参考:- [蜗窝科技-DMA Engine](http://www.wowotech.net/tag/dma) 系列 和 [Linux 4.0的dmaengine编程](https://blog.csdn.net/were0415/article/details/54095899)- [Linux DMAEngine documentation](https://www.kernel.org/doc/html/v4.15/driver-api/dmaengine/index.html#id1)- [linux内核之dmaengine](https://blog.csdn.net/heliangbin87/article/details/81530448)<a name="I9ucs"></a>##### dma信息(生产者-producers)DMA驱动初始化dmaengine描述```cstruct dma_device {unsigned int chancnt; // 支持得DMA CHANNEL个数unsigned int privatecnt; // 已经使用了多少个DMA_CHANNELstruct list_head channels; // 链表头,保存该controller支持的所有struct dma_chan 链表struct list_head global_node; //struct dma_filter filter; //dma_cap_mask_t cap_mask; // DMA支持得CAP能力,可用来筛选合适得DMA// DMA_MEMCPY:内存到内存的拷贝// DMA_SG:设备支持内存到内存的分散/聚合传输// DMA_XOR:设备在内存区域执行XOR操作,如raid5等// DMA_PQ:内存到内存的P+Q计算// DMA_SLAVE:设备能处理设备到内存传输,包括分散/聚合传输// DMA_CYCLIC:设备能处理循环传输,如音频传输unsigned short max_xor;unsigned short max_pq;enum dmaengine_alignment copy_align;enum dmaengine_alignment xor_align;enum dmaengine_alignment pq_align;enum dmaengine_alignment fill_align;#define DMA_HAS_PQ_CONTINUE (1 << 15)int dev_id;struct device *dev; // struct device, 如果是pci设备,可以直接挂到pci设备得dev上u32 src_addr_widths; // src总线位宽u32 dst_addr_widths; // dst总线位宽u32 directions; // 传输方向 BIT(DMA_MEM_TO_MEM) | BIT(DMA_MEM_TO_DEV) | BIT(DMA_DEV_TO_MEM) | BIT(DMA_DEV_TO_DEV)u32 max_burst;bool descriptor_reuse;enum dma_residue_granularity residue_granularity;int (*device_alloc_chan_resources)(struct dma_chan *chan); // 分配资源,并返回描述符void (*device_free_chan_resources)(struct dma_chan *chan); // release DMA channel's resourcesstruct dma_async_tx_descriptor *(*device_prep_dma_memcpy)(struct dma_chan *chan, dma_addr_t dst, dma_addr_t src,size_t len, unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_xor)(struct dma_chan *chan, dma_addr_t dst, dma_addr_t *src,unsigned int src_cnt, size_t len, unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_xor_val)(struct dma_chan *chan, dma_addr_t *src, unsigned int src_cnt,size_t len, enum sum_check_flags *result, unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_pq)(struct dma_chan *chan, dma_addr_t *dst, dma_addr_t *src,unsigned int src_cnt, const unsigned char *scf,size_t len, unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_pq_val)(struct dma_chan *chan, dma_addr_t *pq, dma_addr_t *src,unsigned int src_cnt, const unsigned char *scf, size_t len,enum sum_check_flags *pqres, unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_memset)(struct dma_chan *chan, dma_addr_t dest, int value, size_t len,unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_memset_sg)(struct dma_chan *chan, struct scatterlist *sg,unsigned int nents, int value, unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_interrupt)(struct dma_chan *chan, unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_slave_sg)(struct dma_chan *chan, struct scatterlist *sgl,unsigned int sg_len, enum dma_transfer_direction direction,unsigned long flags, void *context);struct dma_async_tx_descriptor *(*device_prep_dma_cyclic)(struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,size_t period_len, enum dma_transfer_direction direction,unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_interleaved_dma)(struct dma_chan *chan, struct dma_interleaved_template *xt,unsigned long flags);struct dma_async_tx_descriptor *(*device_prep_dma_imm_data)(struct dma_chan *chan, dma_addr_t dst, u64 data,unsigned long flags);int (*device_config)(struct dma_chan *chan,struct dma_slave_config *config);int (*device_pause)(struct dma_chan *chan);int (*device_resume)(struct dma_chan *chan);int (*device_terminate_all)(struct dma_chan *chan);void (*device_synchronize)(struct dma_chan *chan);enum dma_status (*device_tx_status)(struct dma_chan *chan,dma_cookie_t cookie,struct dma_tx_state *txstate); // 必须实现:void (*device_issue_pending)(struct dma_chan *chan); // 必须实现:};
参考示例代码
drivers/crypto/ccp/ccp-dmaengine.c 中ccp_dmaengine_register 函数:dma_dev->dev = ccp->dev;dma_dev->src_addr_widths = CCP_DMA_WIDTH(dma_get_mask(ccp->dev));dma_dev->dst_addr_widths = CCP_DMA_WIDTH(dma_get_mask(ccp->dev));dma_dev->directions = BIT(DMA_MEM_TO_MEM); // 这里写的有BUG,没有带BIT()dma_dev->residue_granularity = DMA_RESIDUE_GRANULARITY_DESCRIPTOR;dma_cap_set(DMA_MEMCPY, dma_dev->cap_mask);dma_cap_set(DMA_INTERRUPT, dma_dev->cap_mask);dma_dev->device_free_chan_resources = ccp_free_chan_resources;dma_dev->device_prep_dma_memcpy = ccp_prep_dma_memcpy;dma_dev->device_prep_dma_interrupt = ccp_prep_dma_interrupt;dma_dev->device_issue_pending = ccp_issue_pending;dma_dev->device_tx_status = ccp_tx_status;dma_dev->device_pause = ccp_pause;dma_dev->device_resume = ccp_resume;dma_dev->device_terminate_all = ccp_terminate_all;ret = dma_async_device_register(dma_dev); // 注册dma设备
INTEL下的DMA
INTEL下用的是CBDMA引擎,来实现内存拷贝的优化:NFV加速利器,CPU中的CBDMA引擎
这个DMA主要用来实现 memcpy,但是否支持内存到外设? 需要测试。 DMA throughput evaluation 这个人需求跟我挺相似:
Intel®Xeon®Gold 6258R CPU @ 2.70GHz(4 NUMA)上测试100G NIC(Mellanox connect X5),并对使用的DMA有一些疑问。我们有2个选项: 1)使用NIC上可用的DMA(通过PCIe总线连接的NIC)。 2)使用主机DMA引擎 主机DMA规范如下: 系统外围设备:英特尔公司的Sky Lake-E CBDMA寄存器(版本07) 子系统:英特尔公司Sky Lake-E CBDMA寄存器
使用的内核驱动程序:ioatdma
内核模块:ioatdma
有16个这样的寄存器(每个NUMA 8个),在检查DMA通道时,我们可以看到16:
root@inno-S2600WFT:~# ls /sys/class/dma/ -al...lrwxrwxrwx dma1chan0 -> ../../devices/pci0000:00/0000:00:04.1/dma/dma1chan0lrwxrwxrwx dma2chan0 -> ../../devices/pci0000:00/0000:00:04.2/dma/dma2chan0root@inno-S2600WFT:~# lspci -s 00:04.100:04.1 System peripheral: Intel Corporation Sky Lake-E CBDMA Registers (rev 04)ioat3_dma_probe 函数dma = &ioat_dma->dma_dev;dma->device_prep_dma_memcpy = ioat_dma_prep_memcpy_lock;dma->device_issue_pending = ioat_issue_pending;dma->device_alloc_chan_resources = ioat_alloc_chan_resources;dma->device_free_chan_resources = ioat_free_chan_resources;
host测DMA
参考:zynq PS侧DMA驱动 和 DMA Test Guide(源码),wowo:Linux DMA Engine framework(2)_功能介绍及解接口分析
#include <linux/dmaengine.h>// 1.申请dma 通道dma_cap_zero(mask);dma_cap_set(DMA_MEMCPY, mask);dma_chan = dma_request_channel(mask, dma_filter_fn fn, void *fn_param);其中,fn和fn_param是过滤参数,根据过滤规则,查找dma_device_list 中列表:也就是ls /sys/class/dma 注册的部分。// 2.自己申请缓存// 3.配置dma按照wowo的说法,需要进行:device_configdmaengine_prep_dma_cyclic但看代码,主机端未实现这两个接口,所以好像不能用。desc = dmaengine_prep_dma_memcpy(dma_chan,d_baddr, s_baddr, 1024, DMA_CTRL_ACK | DMA_PREP_INTERRUPT);// 4.使能desc->callback = test_dma_cb; // 回调接口desc->callback_param = NULL;cookie = dmaengine_submit(desc); // 使能// 5.查看状态dmaengine_tx_status(dma_chan,cookie,&state);// 释放dma通道void dma_release_channel(struct dma_chan *chan);
X86 ISA设备的DMA(了解)
因为这个DMA有诸多限制,这里不细讲,简单描述下
这部分在IOVA- io virtual address 中描述了:
话说,盘古开天的时候,设备访问内存(DMA)就只接受物理地址,所以CPU要把一个地址告诉设备,就只能给物理地址。但设备的地址长度还比CPU的总线长度短,所以只能分配低地址来给设备用(16M)。所以CPU这边的接口就只有dma=dma_alloc(dev, size),分配了物理地址,然后映射为内核的va,然后把pa作为dma地址,CPU提供给设备,设备访问这个dma地址,就得到内存里面的那个数据了。
kernel/dma.c
/boot/config-5.4.0-56-generic 中有配置:CONFIG_GENERIC_ISA_DMA=ykernel/Makefileobj-$(CONFIG_GENERIC_ISA_DMA) += dma.obaiy@inno-MS-7B89:linux-git$ cat /proc/dma4: cascade#define MAX_DMA_CHANNELS 8baiy@inno-MS-7B89:test03$ sudo cat /proc/ioports0000-03af : PCI Bus 0000:000000-001f : dma1...00c0-00df : dma2
DMA控制器依赖于平台硬件,这里只对X86的8237 DMA控制器做简单的说明,它有两个控制器,8个通道,具体说明如下:
控制器1: 通道0-3,字节操作, 端口为 00-1F
控制器2: 通道4-7, 字操作, 端口为 C0-DF
- 所有寄存器是8 bit,与传输大小无关。
- 通道 4 被用来将控制器1与控制器2级联起来。
- 通道 0-3 是字节操作,地址/计数都是字节的。
- 通道 5-7 是字操作,地址/计数都是以字为单位的。
- 传输器对于(0-3通道)必须不超过64K的物理边界,对于5-7必须不超过128K边界。
- 对于5-7通道pageregisters 不用数据 bit 0, 代表128K页
- 对于0-3通道pageregisters 使用 bit 0, 表示 64K页
DMA 传输器限制在低于16M物理内存里。装入寄存器的地址必须是物理地址,而不是逻辑地址。
相关参考: Linux内核DMA机制 和 ldd3 第15章都有示例
相关API
DMA 控制器被dma_spin_lock 的自旋锁所保护。使用函数claim_dma_lock和release_dma_lock对获得和释放自旋锁。这两个函数的声明列出如下(在kernel/dma.c中): unsigned long claim_dma_lock(); 获取 DMA 自旋锁,该函数会阻塞本地处理器上的中断,因此,其返回值是”标志”值,在重新打开中断时必须使用该值。 void release_dma_lock(unsigned long flags); 释放 DMA 自旋锁,并且恢复以前的中断状态。 DMA 控制器的控制设置信息由RAM 地址、传输的数据(以字节或字为单位),以及传输的方向三部分组成。下面是i386平台的8237 DMA控制器的操作函数说明(在include/asm-i386/dma.h中),使用这些函数设置DMA控制器时,应该持有自旋锁。但在驱动程序做I/O 操作时,不能持有自旋锁。 void set_dma_mode(unsigned int channel, char mode); 该函数指出通道从设备读(DMA_MODE_WRITE)或写(DMA_MODE_READ)数据方式,当mode设置为 DMA_MODE_CASCADE时,表示释放对总线的控制。 void set_dma_addr(unsigned int channel, unsigned int addr); 函数给 DMA 缓冲区的地址赋值。该函数将 addr 的最低 24 位存储到控制器中。参数 addr 是总线地址。 void set_dma_count(unsigned int channel, unsigned int count);该函数对传输的字节数赋值。参数 count 也代表 16 位通道的字节数,在此情况下,这个数字必须是偶数。 除了这些操作函数外,还有些对DMA状态进行控制的工具函数: void disable_dma(unsigned int channel); 该函数设置禁止使用DMA 通道。这应该在配置 DMA 控制器之前设置。 void enable_dma(unsigned int channel); 在DMA 通道中包含了合法的数据时,该函数激活DMA 控制器。 int get_dma_residue(unsigned int channel); 该函数查询一个 DMA 传输还有多少字节还没传输完。函数返回没传完的字节数。当传输成功时,函数返回值是0。 void clear_dma_ff(unsigned int channel) 该函数清除 DMA 触发器(flip-flop),该触发器用来控制对 16 位寄存器的访问。可以通过两个连续的 8 位操作来访问这些寄存器,触发器被清除时用来选择低字节,触发器被置位时用来选择高字节。在传输 8 位后,触发器会自动反转;在访问 DMA 寄存器之前,程序员必须清除触发器(将它设置为某个已知状态)。
#include <asm-generic/dma.h>// 自己找个通道申请下,注意:0-3通道8bit对齐,5-7通道16bit对齐,4通道不能用,用来级联两路dma的extern int request_dma(unsigned int dmanr, const char *device_id);extern void free_dma(unsigned int dmanr);
注:这里 set_dma_addr 是 申请DMA缓存的前24位地址,所以只有16M。
DMA内存分配
相关参考: DMA BUFFER的使用
三种DMA的比较
| DMA类型 | 一致性DMA | 流式DMA | DMA池 |
|---|---|---|---|
| 如何避免缓存一致性的 | 可以理解成:这部分内存是no-cache的,CPU访问这部分内存是直接跳过cache | 可以理解成:申请一片内存。在DMA传输前,将内存刷新到关联的cache。在DMA传输后,将关联的cache标记为invalidate无效 | 基于一致性DMA,用在频繁的小内存(小于1页)进行拷贝。 |
| 应用场景 | 如果同一片内存,长期的用来进行DMA交互,那么用一致性DMA。 | 如果只是一次DMA传输,那么用流式DMA。| |
基于一致性DMA,用在频繁的小内存(小于1页)进行拷贝。 |
| 限制 | 一致性DMA必须物理上连续 | 每次DMA传输也必须物理上连续,只是支持了DMA传输链,可以将多个不连续的DMA传输打包成一次。 |
DMA内存分布代码流程
先简单看下DMA的代码流程
// 一致性dma buffer的申请流程dmam_alloc_coherent // drivers/base/dma-mapping.cdma_alloc_coherent // include/linux/dma-mapping.hdma_alloc_attrs // 重点接口const struct dma_map_ops *ops = get_dma_ops(dev);// dma_alloc_from_dev_coherent(.....) // 不用管,没实现// arch_dma_alloc_attrs(&dev, &flag) // 也不用管,不支持CONFIG_HAVE_GENERIC_DMA_COHERENTcpu_addr = ops->alloc(dev, size, dma_handle, flag, attrs);// debug_dma_alloc_coherent(dev, size, *dma_handle, cpu_addr); // 调试的接口// 先看下intel的 get_dma_ops(dev),也就是ops接口// 没开IOMMUconst struct dma_map_ops nommu_dma_ops = {.alloc = dma_generic_alloc_coherent,.free = dma_generic_free_coherent,.map_sg = nommu_map_sg,.map_page = nommu_map_page,.sync_single_for_device = nommu_sync_single_for_device,.sync_sg_for_device = nommu_sync_sg_for_device,.is_phys = 1,.mapping_error = nommu_mapping_error,.dma_supported = x86_dma_supported,};// 开了IOMMU 在intel_iommu_init中有: dma_ops = &intel_dma_ops;dma_ops = &intel_dma_ops;const struct dma_map_ops intel_dma_ops = {.alloc = intel_alloc_coherent,.free = intel_free_coherent,.map_sg = intel_map_sg,.unmap_sg = intel_unmap_sg,.map_page = intel_map_page,.unmap_page = intel_unmap_page,.mapping_error = intel_mapping_error,#ifdef CONFIG_X86.dma_supported = x86_dma_supported,#endif};
#define dma_map_single(d, a, s, r) dma_map_single_attrs(d, a, s, r, 0)#define dma_unmap_single(d, a, s, r) dma_unmap_single_attrs(d, a, s, r, 0)#define dma_map_sg(d, s, n, r) dma_map_sg_attrs(d, s, n, r, 0)#define dma_unmap_sg(d, s, n, r) dma_unmap_sg_attrs(d, s, n, r, 0)#define dma_map_page(d, p, o, s, r) dma_map_page_attrs(d, p, o, s, r, 0)#define dma_unmap_page(d, a, s, r) dma_unmap_page_attrs(d, a, s, r, 0)dma_map_single_attrsaddr = ops->map_page(dev, virt_to_page(ptr),offset_in_page(ptr), size,dir, attrs);
pci_dma传输demo
if (pci_set_dma_mask(pdev, DMA_BIT_MASK(64))|| pci_set_consistent_dma_mask(pdev, DMA_BIT_MASK(64)))if (pci_set_dma_mask(pdev, DMA_BIT_MASK(32))|| pci_set_consistent_dma_mask(pdev, DMA_BIT_MASK(32))) {TW_PRINTK(host, TW_DRIVER, 0x23, "Failed to set dma mask");retval = -ENODEV;goto out_disable_device;}

若有收获,就点个赞吧
0 人点赞
