前言🍕
前段时间,我写了一篇关于 可能的新原生 hook——useEvent 的文章:新的原生Hook?useEvent:一个显著降低Hooks心智负担的原生Hook
应该是我流量最多的文章了

本文的起因😗
有朋友在评论区里问:那为什么 React 不直接默认使用这种 memorized 的 hook呢?让全部东西都缓存~
嗯嗯?我刚打算去截图,结果发现好多评论给删掉了???🤨我那时还打了好长几段回答读者的问题……总共 五十多个评论,应该是有包括那些的… 从消息界面里找到了一部分

大概就是直接让所有的东西都 默认套上一层 useMemo 不就好了?
还真不行~
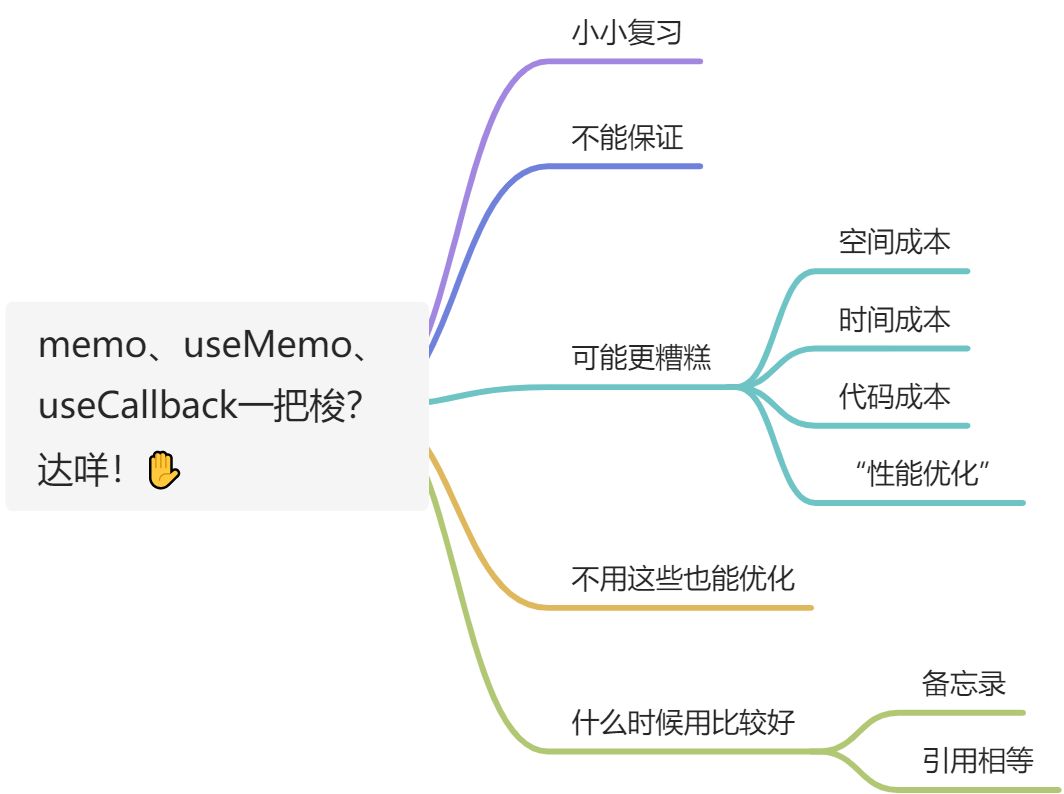
复习一下这三个玩意😛
memo
const MyComponent = React.memo(function MyComponent(props) {/* 使用 props 渲染 */});
React.memo 为高阶组件。 如果你的组件在相同 props 的情况下渲染相同的结果,那么你可以通过将其包装在 React.memo 中调用,以此通过记忆组件渲染结果的方式来提高组件的性能表现。这意味着在这种情况下,React 将跳过渲染组件的操作并直接复用最近一次渲染的结果。
useMemo
const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);
把待执行函数和依赖项数组作为参数传入 useMemo,返回一个 memoized 值。它仅会在某个依赖项改变时才重新计算 memoized值。这种优化有助于避免在每次渲染时都进行高开销的计算。
如果没有提供依赖项数组,useMemo 在每次渲染时都会计算新的值。
useCallback
const memoizedCallback = useCallback(() => {doSomething(a, b);},[a, b],);
把回调函数及依赖项数组作为参数传入 useCallback,它将返回该回调函数的 memoized 版本,该回调函数仅在某个依赖项改变时才会更新。
当你把回调函数传递给经过优化的并使用引用相等性去避免非必要渲染(例如 shouldComponentUpdate)的子组件时,它将非常有用。
useCallback(fn, deps)相当于 useMemo(() => fn, deps)。
网上关于React 性能优化的教程🤔
看起来啊,这两个 Hooks 确实是可以通过避免非必要渲染,减少我们页面的重绘,从而提高性能
网上有很多 React 的教程,其中提到性能优化时,也都会告诉你,用 React 开发者工具检测什么组件出现了太多次的渲染,以及是什么导致的,那就在那上面包裹一个 useMemo
“用它!用它!”
但有没有想过一个问题:这种特性,为什么 React 不直接在所有相关的东西里面都内部 实现呢?或者说为什么不把他们搞成 default 呢?
实际上🛬
不要把它当作语义上的保证
官方文档告诉你:
你可以把 useMemo 作为性能优化的手段,但不要把它当成语义上的保证。将来,React 可能会选择“遗忘”以前的一些 memoized 值,并在下次渲染时重新计算它们,比如为离屏组件释放内存。先编写在没有 useMemo 的情况下也可以执行的代码 —— 之后再在你的代码中添加 useMemo,以达到优化性能的目的。
为什么可能更糟糕🎂
比如现在有一个方法
const edit = id => {setList(list => list.filter(idx => idx !== id))}
我们“常规”地用 useCallback 优化一下
const edit = useCallback(id => {setList(list => list.filter(idx => idx !== id))}, [])
每行代码的成本😶
实际上,上面优化 后的代码实际上就相当于这样:
const edit = id => {setList(list => list.filter(idx => idx !== id))}const memorizedEdit = useCallback(edit, []) // 多了这一行
可以看作是多了一些东西:
- 一个数组:
deps - 调用
useCallback - 定义多一个函数,
Javascript在每次渲染的时候都会给函数定义分配内存,并且useCallback这个方法会让其需要更多的内存分配
啊,当然里面这个 deps数组可以用 useMemo将其 memorize,但是~ 这会导致到处都是 useMemo,以及 useMemo也会像上面 useCallback一样带来一些新的东西…
deps 空间成本以及其带来的时间成本
前面说到了使用这些肯定会带有dependency list,它是一个数组,当然有空间成本。除此之外,每次render时自然还要将数组中的每一个值进行一个比对的行为,检查是否有新的变化
遍历数组,这也是一个时间复杂度为O(N)的过程~
成本和收获相近时👻
实际上,哪怕成本和收获相近,那不就是他们其实啥也没干? 但你的代码大小、复杂度等等却是实实在在的增加了~ 甚至会进一步导致更容易写出糟糕的代码
日常开发的“性能优化”🚀
现在大部分日常项目中的“计算”,对于现代浏览器、电脑硬件等,都是非常微乎其微的。实际上,你可能并不需要这些“优化”。所以我建议大部分时候,先让能达成最终需求效果的代码跑成功了,遇到性能瓶颈了再添加这些优化的手段
小结🍱
也就是说,性能优化并不是 完全免费 的,这是绝对有成本的,甚至有时带来的好处不能抵消成本。
所以你需要做的是负责任地进行优化
选择优化,但或许可以不用这些玩意🍺
demo 例子
先来看看这个例子
import { useState } from "react";export default function App() {let [text, setText] = useState("zhou")return (<div><input value={text} onChange={e => setText(e.target.value)} /><p>{text}</p><Big /></div>);}function Big() {// ... 很大很麻烦就完事了return <p>so big to make it render slowly</p>;}
随着 text 的变化,每一次都要渲染非常难办的 <Big/>
哎不管他到底大不大,总之
render不想老是带ta玩就完事了
当然,你可能第一个想到的就是 套个 memo 就完了~
但是,有没有其他选择呢?即剩下 memo 的成本,又能对其进行性能优化?
抽离组件,带走 state🍖
实际上,只有这两行代码在意 text不是吗
<input value={text} onChange={e => setText(e.target.value)} /><p>{text}</p>
我们将它俩抽离出来为一个组件Small,把 state 放进去就好了~
export default function App() {return (<div><Small /><Big /></div>);}function Big() {// ... 很大很麻烦就完事了return <p>so big to make it render slowly</p>;}function Small() {let [text, setText] = useState("zhou")return (<><input value={text} onChange={e => setText(e.target.value)} /><p>{text}</p></>)}
现在好了,当 text改变,自然就只有 Small会重新渲染,讨厌的<Big/>就不会老来骚扰了,good~
抽离组件, 孤立 Big🥙
有时候,在意text的是父组件,但其中的“消耗大”的子组件其实并不在意,那该怎么将 care 的和 不 care 的隔离?
import { useState } from "react";export default function App() {let [text, setText] = useState("zhou")return (<div data-text = {text}><input value={text} onChange={e => setText(e.target.value)} /><p>{text}</p><Big /></div>);}function Big() {// ... 很大很麻烦就完事了return <p>so big to make it render slowly</p>;}
看起来没办法只将 在意state的部分抽离出来,让其带走state了… 那我们直接把不在意的孤立了不就好了~
export default function App() {let [text, setText] = useState("zhou")return (<TextAbout><Big /></TextAbout>);}function Big() {// ... 很大很麻烦就完事了return <p>so big to make it render slowly</p>;}function TextAbout({children}){let [text, setText] = useState("zhou")return (<div data-text={text}><input value={text} onChange={e => setText(e.target.value)} /><p>{text}</p>{children}</div>)}
我们将text相关的父组件和子组件全部拿出来,作为TextAbout。不关心text且麻烦的Big留在App中,作为children属性传入TextAbout中。当text变化,TextAbout会重新渲染,但是其中保留的仍是之前从App中拿到的children属性。
好惨的
<Big/>,被狠狠地孤立了,在里面,但不完全在里面 [doge]
小结
那到底应该什么时候用🍗
什么叫负责任地使用🥂
你怎么样判断付出的成本比收获的少?或许你可以好好地 测量 一下~
React 官方的测量API Profiler
Profiler 测量一个 React 应用多久渲染一次以及渲染一次的“代价”。 它的目的是识别出应用中渲染较慢的部分,或是可以使用类似 memoization 优化的部分,并从相关优化中获益。
具体用法看文档啦,搬一大段到文章上也没意思~
或许还有其他测量方法,自行查阅~
又或者你是完完全全地保证这个组件的渲染真的非常需要时间,能不渲染绝不再次渲染~
比如一些很大的动画?可视化的大屏?巨大图表?(我猜的 [doge])
或许真的有需要😏
真正“备忘录”的作用🍤
这个点其实原生 JS 也是一样的道理:一段代码执行比较耗时,但是执行的结果经常用到,那就用一个东西将其结果存起来,再用到的时候直接取~ 以空间换时间—
其实 React 这几个 API 某种程度也是有 空间换时间 的思想
大概是这样
const ans = useMemo(() => calculate(a, b), [a, b]);
有时需要“引用相等”🍚
写 JS 的都知道的:
{} !== {}[] !== []()=>{} !== ()=>{}
以上都为 true~
这意味着useEffect等hook中比对deps时会出现:他完全一样,但是 React 不认为他一样
React 中用的是
Object.is,但是对于这些情况,和===差不多
这时可能就需要用useCallback或者useMemo来助你一臂之力~
总结⛵
本文从 memo等api 的收获和成本讲起,(其实没提到的如PureComponent后者shouldComponentUpdate等类似“阻止渲染 & 减少渲染次数”功能的都有差不多的道理~)
细说了一下成本,以及一些可能不需要这些成本也能进行的优化方法,粗略地讲了一下可能真的有需求要用的场景,大概地讲述了一些不能一把梭这些玩意的论点~
其实最强力的论点就是:为什么 React 不把这些搞成
默认方法😛
一句话总结
关于是否使用这些,或许可以用一句话来总结:
如果没有性能瓶颈,那就建议不用,大部分项目你可能并不需要考虑以阻止 React 的渲染来提高性能 —— 甚至可以说如果你不能保证收获比成本大的“多”,那就尽量不用。
其实这上面这句话也藏着性能优化的原则之一:不要过早优化
浅浅升华一下主题🚩
想来这篇文章也是从技术角度讲这两句话:
- 世上没有免费的午餐——《严厉的月亮》
- 那时她还太年轻,不知道所有命运馈赠的礼物,早已在暗中标好了价格—— 《断头王后》
浅浅地升华了一下主题😎
学习 & 参考资源
- memorize
- React.memo
- useCallback
- useMemo
- Profiler
- Hooks FAQ
文中措辞、知识点、格式如有疑问或建议,欢迎评论~你对我很重要~ 🌊如果有所帮助,欢迎点赞关注,一起进步⛵这对我很重要~

若有收获,就点个赞吧
0 人点赞
