7.1贝叶斯决策论
贝叶斯决策论(Bayesian decision theory):所有相关概率已知的情况下,如何基于这些概率和误判损失来选择最优的类别标记。
例子:假设有N种可能的类别标记,即 是将一个真实标记为
是将一个真实标记为 的样本误分类为
的样本误分类为 所产生的损失,基于后验概率
所产生的损失,基于后验概率 可获得将样本
可获得将样本 分类为所产生的期望损失(expected loss),即在样本的“条件风险”(conditional risk)。
分类为所产生的期望损失(expected loss),即在样本的“条件风险”(conditional risk)。
我们的任务是寻找一个判定准则 以最小化总体风险
以最小化总体风险
对每个样本,如果 能最小化风险
能最小化风险 ,则总体风险
,则总体风险 也将被最小化。这就产生了贝叶斯判定准则(Bayes decision rule):为最小化总体风险,只需在每个样本上选择那个能使条件风险
也将被最小化。这就产生了贝叶斯判定准则(Bayes decision rule):为最小化总体风险,只需在每个样本上选择那个能使条件风险 最小的类别标记,即:
最小的类别标记,即:
此时, 称为贝叶斯最优分类器(Bayes optimal classifier),与之对应的总体风险
称为贝叶斯最优分类器(Bayes optimal classifier),与之对应的总体风险 称为贝叶斯风险(Bayes risk)。
称为贝叶斯风险(Bayes risk)。 反映了分类器所能达到的最好性能,即通过机器学习所能产生的模型精度的理论上限。
反映了分类器所能达到的最好性能,即通过机器学习所能产生的模型精度的理论上限。
具体来说,若目标是最小化分类错误率,则误判损失 可写为:
可写为:
此时条件风险
于是,最小化分类 错误率的贝叶斯最优分类器
即对每个样本 ,选择能使后验概率
,选择能使后验概率 最大的类别标记。
最大的类别标记。
所以,要想使用贝叶斯判定准则来最小化决策风险,首先要获得后验概率。然而,在现实任务中后验概率通常很难获得。所以,机器学习要实现的是基于有限的训练样本集尽可能准确地估计出后验概率大体来说,主要有两种策略:
- 给定,通过直接建模来预测
 ,这样得到的是”判别式模型”(discriminative models)。
,这样得到的是”判别式模型”(discriminative models)。 - 先对联合概率分布
 建模,然后再由此获得,这样得到的是”生成式模型”(generative models)。
建模,然后再由此获得,这样得到的是”生成式模型”(generative models)。
显然,前面介绍的决策树、BP神经网络、支持向量机等,都可归入判别式模型的范畴,对生成式模型来说,有:
基于贝叶斯定理,可以写为
其中, 是类”先验”(prior)概率;
是类”先验”(prior)概率; 是样本相对于类标记的类条件概率(class-conditional probability),或称为”似然”(likelihood);
是样本相对于类标记的类条件概率(class-conditional probability),或称为”似然”(likelihood); 是用于归一化的”证据”(evidence)因子。
是用于归一化的”证据”(evidence)因子。
对给定样本,证据因子 与类标记无关,因此估计
与类标记无关,因此估计 的问题就转化为如何基于训练数据
的问题就转化为如何基于训练数据 来估计
来估计
先验概率和似然。
例子**:** .
. :颜色深的西瓜中好西瓜的概率.
:颜色深的西瓜中好西瓜的概率. :好西瓜中颜色深的西瓜的概率.
:好西瓜中颜色深的西瓜的概率.
- 类先验概率表达了样本空间中各类样本所占的比例,根据大数定律,当训练集包含充足的独立同分布样本时,可通过各类样本出现的频率来进行估计。
- 对类条件概率来说,由于它设计关于所有属性的联合概率,直接根据样本出现的频率来估计将会遇到严重的困难.例如,假设样本的
 个属性都是二值的(例如:西瓜颜色深浅;西瓜尾巴的大小),则样本空间就有
个属性都是二值的(例如:西瓜颜色深浅;西瓜尾巴的大小),则样本空间就有 种可能的取值.在现实应用中,这个值远远大于训练样本
种可能的取值.在现实应用中,这个值远远大于训练样本 ,也就是说,很多样本取值在训练集中根本没有出现,直接使用频率来估计显然不行.
,也就是说,很多样本取值在训练集中根本没有出现,直接使用频率来估计显然不行.
7.2极大似然估计
7.3朴素贝叶斯分类器
不难发现,基于贝叶斯公式(7-8)来估计后验概率的主要困难在于:类条件概率是所有属性上的联合概率(例子中的好西瓜可能有尾巴和响声等属性)的联合概率,难以从有限的训练样本直接估计而得.为避开这个障碍,朴素贝叶斯分类器(naive Bayes classifier)采用了”属性条件独立性假设”(attribute conditional independence assumption):对已知类别,假设所有属性相互独立(尾巴的大小和响声之间没有关系).换言之,假设每个属性独立地对分类结果产生影响.
基于属性条件独立性假设,式子(7-8可以重写为):
其中为属性数目, 为在第
为在第 个属性上的取值.
个属性上的取值.
由于对所有类别来说 相同,因此基于式子(7-6)的贝叶斯判定准则有
相同,因此基于式子(7-6)的贝叶斯判定准则有
这就是朴素贝叶斯分类器的表达式.
显然,朴素贝叶斯分类器的训练过程就是基于训练集来估计类先验概率,并为每个属性估计条件概率 .
.
令 表示训练集中第类样本组成的集合,若有充足的独立同分布样本,则可容易地估计出类先验概率
表示训练集中第类样本组成的集合,若有充足的独立同分布样本,则可容易地估计出类先验概率
对离散属性而言,令 表示中在第个属性取值为
表示中在第个属性取值为 的样本组成的集合,则条件概率可估计为
的样本组成的集合,则条件概率可估计为
比如在好瓜中,颜色深的西瓜有10个.好瓜有15个.
对连续属性可以考虑概率密度函数,假定 ,其中
,其中 和
和 分别是第类样本在第个属性上取值的均值和方差,则有
分别是第类样本在第个属性上取值的均值和方差,则有
下面我们使用西瓜数据3.0训练一个朴素贝叶斯分类器,对训练例”测1”进行分类:
西瓜数据
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.774 | 0.376 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.634 | 0.264 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 0.608 | 0.318 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.556 | 0.215 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.403 | 0.237 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 0.481 | 0.149 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 0.437 | 0.211 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.666 | 0.091 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 0.243 | 0.267 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 0.245 | 0.057 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 0.343 | 0.099 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 0.639 | 0.161 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 0.657 | 0.198 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 0.360 | 0.370 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 0.593 | 0.042 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 0.719 | 0.103 | 否 |
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 密度 | 含糖率 | 好瓜 |
|---|---|---|---|---|---|---|---|---|---|
| 测1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 0.697 | 0.460 | ? |
首先估计类先验概率,显然有
然后为每个属性估计类条件概率:
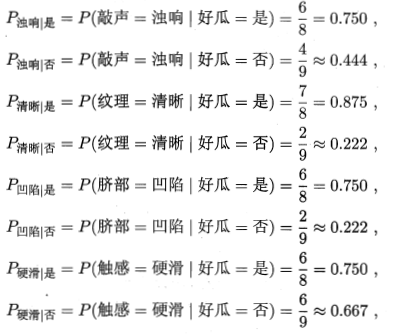


结果:
需注意,若某个属性值在训练集中没有与某个类同时出现过,则直接基于式子(7-17)进行概率估计,再根据式子(7-15)进行判别将出现问题.例如,在使用西瓜数据集训练朴素贝叶斯分类器时,对一个”敲声=清脆”的测试例,有
由于式子(7-15)的连乘式计算出的概率值为0,因此,无论该样本的其他属性是什么,分类结果都会是”好瓜=否”,这显然不合理.
为了避免其他属性携带的信息被训练集中未出现的属性值”抹去”,在估计概率值时通常要进行”平滑”(smoothing),常用”拉普拉斯修正”(Laplaction correction).具体来说,令 表示训练集中中可能的类别数,
表示训练集中中可能的类别数, 表示第个属性可能的取值数,则式子(7-16)和(7-17)分别修正为:
表示第个属性可能的取值数,则式子(7-16)和(7-17)分别修正为: 例如,在本节的例子中,类先验概率可估计为:
例如,在本节的例子中,类先验概率可估计为:
类似地, 和
和 可估计为:
可估计为:
同时,上文提到的概率 可估计为
可估计为
同时,上文提到的概率可估计为
显然,拉普拉斯修正避免了因训练集样本不充分而导致概率估值为0的问题,并且在训练集变大时,修正过程所引入的先验(prior)的影响也会逐渐变得可忽略,使得估值渐趋向于实际概率值.
在现实任务中朴素贝叶斯分类器有多种使用方式.例如,若任务对以讹传讹速度要求较高,则对给定训练集,可将贝叶斯分类器所设计的所有概率估值事先计算好存储起来,这样在进行预测时只需”查表”即可进行判别;若任务数据更替频繁,则可采用”懒惰学习“(lazy learning)方式,先不进行任何训练,待收到预测请求时再根据当前数据集进行概率估值;若数据不断增加,则可在现有估值基础上,仅对新增样本的属性值所设计的概率估值进行计数修正即可实现增量学习.
7.4 半朴素贝叶斯分类器
为了降低贝叶斯公式(7-8)中估计后验概率 的困难,朴素贝叶斯分类器采用了属性条件独立性假设,但在现实任务中这个假设往往很难成立,人们尝试对属性条件独立性假设进行一定程度的放松,由此产生了一类称为”半朴素贝叶斯分类器”(semi-naive Bayes classifiers)的学习方法。
的困难,朴素贝叶斯分类器采用了属性条件独立性假设,但在现实任务中这个假设往往很难成立,人们尝试对属性条件独立性假设进行一定程度的放松,由此产生了一类称为”半朴素贝叶斯分类器”(semi-naive Bayes classifiers)的学习方法。
半朴素贝叶斯分类器的基本想法是适当考虑一部分属性间的相互依赖信息,从而既不需要进行完全概率计算,又不至于彻底忽略了比较强的属性依赖关系。“独依赖估计”(One-Dependent Estimator,简称ODE)是半朴素贝叶斯分类器最常用的一种策略。顾名思义,所谓“独依赖”就是假设每个属性在类别之外最多仅依赖于一个其他属性,即
其中 为属性所依赖的属性,称为的父属性。此时,对每个属性,若其父属性已知,则可采用类似式子(7-20)的办法来估计概率值
为属性所依赖的属性,称为的父属性。此时,对每个属性,若其父属性已知,则可采用类似式子(7-20)的办法来估计概率值 。于是,问题的关键就转换为如何确定每个属性的父属性,不同的做法产生不同的独依赖分类器。
。于是,问题的关键就转换为如何确定每个属性的父属性,不同的做法产生不同的独依赖分类器。
最直接的做法是假设所有属性都依赖于同一个属性,称为”超父”(super-parent),然后通过交叉验证等模型选择方法来确定其超父属性,由此形成了SPODE(Super-Parent ODE方法)。例如,图7.1(b)中, 是超父属性。
是超父属性。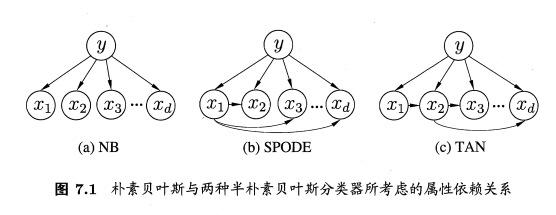
TAN(Tree Augmented naive Bayes)则是在最大带权生成树(maximum weighted spanning tree)算法的基础上,通过以下步骤将属性间依赖关系约简为图7.1(c)所示的树形结构。
- 1.计算任意两个属性之间的条件互信息(conditional mutual information)

- 2.以属性为结点构建完全图,任意两个结点之间边的权重设为
 ;
; - 3.构建此完全图的最大带权生成树,挑选根变量,将边置为有向;
- 4.加入类别节点
 ,增加从到每个属性的有向边。
,增加从到每个属性的有向边。
容易看出,条件互信息刻画了和 在已知类别情况下的相关性,因此,通过最大生成树算法,TAN实际上仅保留了强相关属性之间的依赖性。
在已知类别情况下的相关性,因此,通过最大生成树算法,TAN实际上仅保留了强相关属性之间的依赖性。
AODE(Averaged One-Dependent Estimator)是一种基于集成学习机制、更为强大的独依赖分类器。与SPODE通过模型选择确定超父属性不同,AODE尝试将每个属性作为超父来构建SPODE,然后将那些具有足够训练数据支撑的SPODE集成起来作为最终结果,即
其中, 默认为30.
默认为30.
其中 是在第个属性上取值为的样本的集合,为阈值常数,显然,AODE需估计
是在第个属性上取值为的样本的集合,为阈值常数,显然,AODE需估计 和
和 。类似式子(7-20),有
。类似式子(7-20),有
其中 是第个属性可能的取值数,是类别为且在第个属性上取值为的样本集合,
是第个属性可能的取值数,是类别为且在第个属性上取值为的样本集合, 是类别为且在第个和第
是类别为且在第个和第 个属性上取值分别为和的样本集合。例如,对西瓜数据集有:
个属性上取值分别为和的样本集合。例如,对西瓜数据集有:
不难看出,与朴素贝叶斯分类器相似,AODE的训练过程也是”计数”,即在训练数据集上对符合条件的样本进行计数的过程。与朴素贝叶斯分类器相似,AODE无需模型选择,既能通过预计算节省预测时间,也能采取懒惰学习方式在预测时再进行计数,并且易于实现增量学习。
既然将属性条件独立性假设放松为独依赖假设可能获得泛化性能的提升,那么,能否通过考虑属性间的高阶依赖来进一步提升泛化性能呢?也就是说,将式子(7-23)中的属性替换为包含 个属性的集合
个属性的集合 ,从而将ODE拓展为kDE。需注意的是,随着k的增加,准确估计概率
,从而将ODE拓展为kDE。需注意的是,随着k的增加,准确估计概率 ,所需的训练样本数量将以指数级增加。因此,若训练数据非常充分,泛化性能有可能提升;样本有限下,会陷入估计高阶联合概率的泥沼。
,所需的训练样本数量将以指数级增加。因此,若训练数据非常充分,泛化性能有可能提升;样本有限下,会陷入估计高阶联合概率的泥沼。
7.5 贝叶斯网
贝叶斯网(Bayesian network)也称”信念网”(belief network),它借助有向无环图(Directed Acyclic Graph,简称DAG)来刻画属性之间的依赖关系,并使用条件概率来表示(Conditional Probability Table,简称CPT)来描述属性的联合概率分布。
具体来说,一个贝叶斯网 由结构
由结构 和参数
和参数 两部分构成,即
两部分构成,即 。网络结构
。网络结构 是一个有向无环图,其每个节点对应于一个属性,若两个属性有直接依赖关系,则它们有一条边连接起来;参数定量描述这种依赖关系,假设属性在中的父节点集为
是一个有向无环图,其每个节点对应于一个属性,若两个属性有直接依赖关系,则它们有一条边连接起来;参数定量描述这种依赖关系,假设属性在中的父节点集为 ,则包含了每个属性的条件概率表示
,则包含了每个属性的条件概率表示 。
。
例子:图7-2给出了西瓜问题的一种贝叶斯网结构和属性”根蒂”的条件概率表。从图中网结构可看出,”色泽”直接依赖于好瓜和”甜度”,而”根蒂”则直接依赖于”添堵”;进一步从条件概率表能得到”根蒂”对”甜度”量化依赖关系,如 等。
等。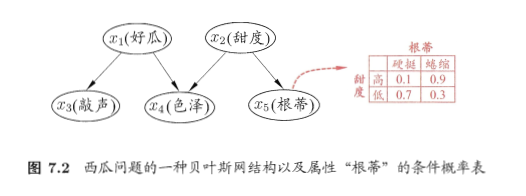
7.5.1 结构
贝叶斯网络结构有效地表达了属性间的条件独立性。给定父结点集,贝叶斯网假设每个属性与它的非后裔属性独立,于是 将属性
将属性 的联合概率分布定义为:
的联合概率分布定义为:
以图7-2为例,联合概率分布定义为
显然, 和
和 在给定的取值时独立,和
在给定的取值时独立,和 在给定
在给定 的取值时独立,分别简记为
的取值时独立,分别简记为 和
和 。
。
图7-3显示出贝叶斯网中三个变量之间的典型依赖关系,其中前两种在式子(7-26)中已有所体现。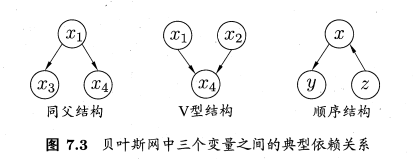
在”同父”结构中,给定父结点的取值,则与条件独立。在”顺序”结构中,给定的值,则与 条件独立。V型结构(V-structure)亦称”冲撞”结构,给定子结点的取值,与必不独立;奇妙的是,若的取值完全未知,则V型结构下,与却是相互独立的。我们做一个简单的验证:
条件独立。V型结构(V-structure)亦称”冲撞”结构,给定子结点的取值,与必不独立;奇妙的是,若的取值完全未知,则V型结构下,与却是相互独立的。我们做一个简单的验证: 这样的独立性称为”边际独立性”(marginal independence),记为
这样的独立性称为”边际独立性”(marginal independence),记为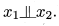
事实上,一个变量取值的确定与否,能对另两个变量间的独立性发生影响,这个现象并非v型结构所特有。例如在同父结构中,条件独立性成立,但若的取值未知,则和就不独立,即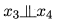 不成立;在顺序结构中,
不成立;在顺序结构中, ,但
,但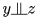 不成立。
不成立。
为了分析有向图中变量的条件独立性,可使用”有向分离”(D-separation)。我们先把有向图转换成一个无向图:
- 找出有向图中的所有V型结构,在V型结构的两个父结点之间加上一条无向边;
- 将所有有向边改为无向边。
由此产生的无向图称为”道德图”(moral graph),令父结点相连的过程称为”道德化”(moralization)。(道德图也称为端正图。”道德化”的蕴义:孩子的父母应建立牢靠的关系,否则是不道德的。)
基于道德图能直观、迅速地找到变量间的条件独立性。假定道德图中有变量 和变量集合
和变量集合 ,若变量能在图上被
,若变量能在图上被 分开,即从道德图中将变量集合去除后,和分属两个连通分支,则称变量和被
分开,即从道德图中将变量集合去除后,和分属两个连通分支,则称变量和被 有向分离,
有向分离, 成立。例如,图7-2所对应的道德图如图7-4所示,从图中能容易地找出所有的条件独立关系:
成立。例如,图7-2所对应的道德图如图7-4所示,从图中能容易地找出所有的条件独立关系: 等。
等。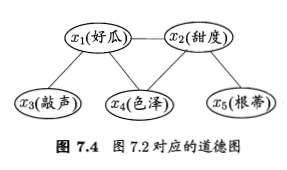
7.5.2 学习
若网络结构已知,即属性间的依赖关系已知,则贝叶斯网的学习过程相对简单,只需通过对训练样本”计数”,估计出每个结点的条件概率表即可。但在现实应用中我们往往并不知晓网络结构,于是,贝叶斯网学习的首要任务就是根据训练数据集来找出结构最”恰当”的贝叶斯网。“评分搜索“是求解这一问题的常用办法。具体来说,我们先定义一个评分函数(score function),以此来评估贝叶斯网与训练数据的契合程度,然后基于这个评分函数来寻找结构最优的贝叶斯网。显然,评分函数引入了关于我们希望获得什么样的贝叶斯网的归纳偏好。
常用评分函数通常基于信息论准则,此类准则将学习问题看作一个数据压缩任务,学习的目标是找到一个能以最短编码长度描述训练数据的模型,此时编码的长度包括了描述模型本身所需的字节长度和和使用该模型描述数据所需的字节长度。对贝叶斯网学习而言,模型就是一个贝叶斯网。同时,每个贝叶斯网描述了一个在训练数据上的概率分布。于是,我们应选择那个综合编码长度(包括描述网络和编码数据)最短的贝叶斯网,这就是”最小描述长度”(Minimal Description Length ,简称MDL)准则。
给定训练集 ,贝叶斯网在上的评分函数可写为
,贝叶斯网在上的评分函数可写为
其中, 是贝叶斯网的参数个数;
是贝叶斯网的参数个数; 表示描述每个参数
表示描述每个参数 所需的字节数;而
所需的字节数;而
是贝叶斯网的对数似然。显然,式子(7-28)的第一项是计算编码贝叶斯网所需的字节数,第二项是计算所对应的概率 需多少字节来描述。于是,学习任务就转化为一个优化任务,即寻找一个贝叶斯网是评分函数
需多少字节来描述。于是,学习任务就转化为一个优化任务,即寻找一个贝叶斯网是评分函数 最小。
最小。
若 ,即每个参数用1字节描述,则得到AIC(Akaike Information Criterion)评分函数
,即每个参数用1字节描述,则得到AIC(Akaike Information Criterion)评分函数
若 ,即每个参数用
,即每个参数用 字节描述,则得到BIC(Bayesian Information Criterion)评分函数
字节描述,则得到BIC(Bayesian Information Criterion)评分函数
显然,若 ,即不计算对网络进行编码的长度,则评分函数退化为负对数似然。相应的,学习任务退化为极大似然估计。
,即不计算对网络进行编码的长度,则评分函数退化为负对数似然。相应的,学习任务退化为极大似然估计。
不难发现,若贝叶斯网 的网络结构固定,则评分函数
的网络结构固定,则评分函数 的第一项为常数。此时,最小化等价对参数的极大似然估计。由式子(7-29)和(7-26)可知,参数
的第一项为常数。此时,最小化等价对参数的极大似然估计。由式子(7-29)和(7-26)可知,参数 能直接在训练数据上通过经验估计获得,即
能直接在训练数据上通过经验估计获得,即
其中 是上的经验分布。因此,为了最小化评分函数
是上的经验分布。因此,为了最小化评分函数 ,只需对网络结构进行搜索,而候选结构的最优参数可直接在训练集上计算得到。
,只需对网络结构进行搜索,而候选结构的最优参数可直接在训练集上计算得到。
不幸的是,从所有可能的网络结构空间搜索最有贝叶斯网结构是一个NP难问题,难以快速求解。有两种常用的策略能在有限时间内求得近似解:第一种是贪心法,例如从某个网络结构出发,每次调整一条边(增加、删除或调整方向),直到评分函数值不再降低未知;第二种是通过网络结构施加约束来削减搜索空间,例如将网络结构限定为树形结构等。
7.5.3 推断
贝叶斯网训练好之后就能用来回答”查询”(query),即通过一些属性变量的观测值来推测其他属性变量的取值。例如,在西瓜问题中,若我们观测到西瓜色泽青绿、敲声浊响、根蒂蜷缩,想知道他是否成熟、甜度如何。这样通过已知变量观测值来推测待查询变量的过程称为”推断”(inference),已知变量观测值称为”证据”(evidence)。
最理想的直接根据贝叶斯网定义的联合概率分布来精确计算后验概率,不幸的是,这样的”精确推断”已被证明是NP难的;换言之,当网络结点较多、连接稠密时,难以进行精确推断,此时需借助”近似推断”,通过降低精度要求,在有限时间内求得近似解。在现实应用中,贝叶斯网的近似推断常使用吉布斯采样(Gibbs sampling)来完成,这是一种随机采样方法,我们来看看它是如何工作的。
令 表示待查询变量,
表示待查询变量, 为证据变量,已知其取值为
为证据变量,已知其取值为 。目标是计算后验概率
。目标是计算后验概率 ,其中
,其中 是待查询的一组取值。以西瓜问题为例,待查询变量为
是待查询的一组取值。以西瓜问题为例,待查询变量为 ,证据变量为
,证据变量为 且已知其取值为
且已知其取值为 ,查询的目标值是
,查询的目标值是 ,即这是好瓜且甜度高的概率有多大。
,即这是好瓜且甜度高的概率有多大。
如图7-5所示,吉布斯采样算法随机产生一个与证据 一致的样本
一致的样本 作为初始点,然后每步从当前样本出发产生下一个样本。具体来说,在第
作为初始点,然后每步从当前样本出发产生下一个样本。具体来说,在第 次采样中,算法先假设
次采样中,算法先假设 ,然后对非证据变量逐个进行采样改变其取值,采样概率根据贝叶斯网和其他变量的当前取值(即
,然后对非证据变量逐个进行采样改变其取值,采样概率根据贝叶斯网和其他变量的当前取值(即  )计算获得。假定经过
)计算获得。假定经过 次采样得到的与
次采样得到的与 一致的样本共有
一致的样本共有 个,则可估算出后验概率
个,则可估算出后验概率
实质上,吉布斯采样是在贝叶斯网所有变量的联合状态空间与证据 一致的子空间中进行”随机漫步”(random walk)。每一步仅依赖于前一步的状态,这是一个”马尔可夫链”(Markov chain)。在一定条件下,无论从什么初始状态开始,马尔可夫链第步的状态分布在
一致的子空间中进行”随机漫步”(random walk)。每一步仅依赖于前一步的状态,这是一个”马尔可夫链”(Markov chain)。在一定条件下,无论从什么初始状态开始,马尔可夫链第步的状态分布在 必定收敛于一个平稳分布(stationary distribution);对于吉布斯采样来说,这个分布恰好是
必定收敛于一个平稳分布(stationary distribution);对于吉布斯采样来说,这个分布恰好是 。因此,在很大时。吉布斯采样相当于根据
。因此,在很大时。吉布斯采样相当于根据 采样,从而保证了式子(7-33)收敛于
采样,从而保证了式子(7-33)收敛于 。
。
需注意的是,由于马尔科夫链通常需很长时间才能趋于平稳分布,因此吉布斯采样算法的收敛速度较慢。此外,若贝叶斯网中存在极端概率”0”或”1”,则不能保证马尔科夫链存在平稳分布,此时吉布斯采样会给出错误的估计结果。
7.6 EM算法
在前面的讨论中,我们一直假设训练样本所有属性变量的值都已被观测到,即训练样本是”完整”的。但在现实应用中往往会遇到”不完整”的训练样本,例如:由于西瓜的根蒂已脱落,无法看出是”蜷缩”还是”硬挺”,则训练样本的”根蒂”属性变量值未知。在这种存在”未观测”变量的情形下,是否仍能对模型参数进行估计呢?
未观测变量的学名是”隐变量”(latent variable)。令 表示已观测变量集,
表示已观测变量集, 表示隐变量集,表示模型参数.欲对做极大似然估计,则应最大化对数似然
表示隐变量集,表示模型参数.欲对做极大似然估计,则应最大化对数似然
然而由于 是隐变量,上式无法直接求解.此时我们可通过对计算期望,来最大化已观测数据的对数”边际似然”(marginal likelihood)
是隐变量,上式无法直接求解.此时我们可通过对计算期望,来最大化已观测数据的对数”边际似然”(marginal likelihood)
EM(Expectation-Maximization)算法是常用的估计参数隐变量的利器,它是一种迭代式的方式,其基本思想是:若参数已知,则可根据训练参数推断出最优隐变量的值(E步);反之,若的值已知,则可方便地对参数做极大似然估计(M步)
于是,以初始值 为起点,对式(7-35),可迭代执行以下步骤直至收敛:
为起点,对式(7-35),可迭代执行以下步骤直至收敛:
- 基于
 推断隐变量的期望,记为
推断隐变量的期望,记为 ;
; - 基于已观测变量
 和对参数做极大似然估计,记为
和对参数做极大似然估计,记为 ;
;
这就是EM算法的原型。
进一步,若我们不是取的期望,而是基于计算隐变量的概率分布 ,则EM算法的两个步骤是:
,则EM算法的两个步骤是:
- E步(Expectation):以当前参数推断隐变量分布,并计算对数似然
 关于的期望
关于的期望

- M步(Maximization):寻找参数最大化期望似然,即

简要来说,EM算法使用两个步骤交替计算:第一步是期望(E)步,利用当前估计的参数值来计算对数似然的期望值;第二步是最大化(M)步,寻找能使E步产生的似然期望最大化的参数值.然后,新的到的参数值重新被用于E步,….直至收敛到局部最优解.
事实上,隐变量估计问题也可通过梯度下降等优化算法求解,但由于求和的项数将随着隐变量的数目将以指数级上升,会给梯度计算带来麻烦;而EM算法则可看作一种非梯度优化方法.

若有收获,就点个赞吧
0 人点赞
