基础知识
计算学习理论(computational learning theory)是机器学习的理论基础。
给定样例集 ,本章的二分类
,本章的二分类 。假设
。假设 中所有的样本服从一个隐含未知的分布
中所有的样本服从一个隐含未知的分布 中所有样本都是独立地从这个分布上采样而得,即独立同分布(independent and identically distributed)样本。
中所有样本都是独立地从这个分布上采样而得,即独立同分布(independent and identically distributed)样本。
令 为从到
为从到 的一个映射,其泛化误差定义为
的一个映射,其泛化误差定义为
解析:该式为泛化误差的定义式,所谓泛化误差,是指当样本
从真实的样本分布
中采样后其预测值
不等于真实值
的概率。在现实世界中,我们很难获得样本分布
[也叫观测集、样本集],注意
在上的经验误差定义为
解析:该式为经验误差的定义式,所谓经验误差,是指观测集
的预测值
和真实值
的期望误差。
由于是的独立同分布采样,因此的经验误差的期望等于其泛化误差。在上下文明确时,我们将 和
和 分别简记为
分别简记为 和
和 。令
。令 为的上限,即
为的上限,即 ;我们通常用
;我们通常用 表示预先设定的学得模型满足的误差要求,亦称”误差参数”。
表示预先设定的学得模型满足的误差要求,亦称”误差参数”。
本章后面部分将研究经验误差与泛化误差之间的逼近程度。若在数据集上的经验误差为0,则称与一致,否则称其与不一致。对任意两个映射 ,可通过其”不合”(disagreement)来度量它们之间的差别:
,可通过其”不合”(disagreement)来度量它们之间的差别:
解析:假设我们有两个模型
和
,将它们同时作用于样本
上,那么它们的”不合”度定义为这两个模型预测值不相同的概率。
我们常用的几个不等式:
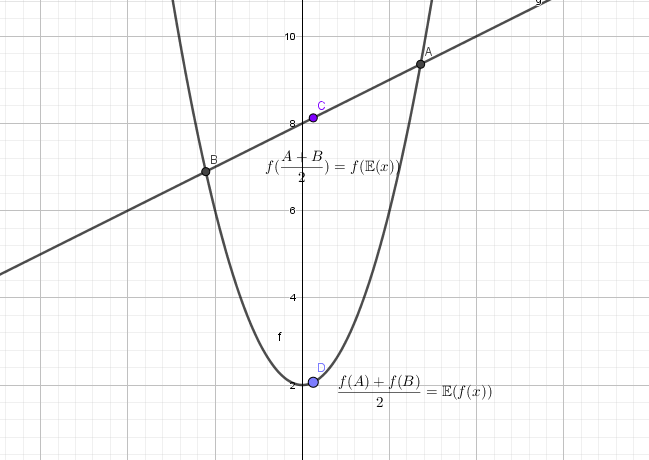
- Jensen不等式:对任意凸函数
 ,有
,有

解析:Jensen不等式:这个式子可以做很直观的理解,比如说在二维空间上,凸函数可以想象成开口向上的抛物线,加入我们有两个
,那么
表示的是两个点的均值的纵坐标,而
表示的是两个纵坐标的均值,因为两个点的均值落在抛物线的凹处,所以均值的纵坐标会小一些。(这里的凸函数是下凸函数,也就是凹函数)
- Hoeffding不等式:若
 为
为 个独立随机变量,且满足
个独立随机变量,且满足 ,则对任意
,则对任意 ,有
,有

解析:Hoeffding不等式:对于独立随机变量
的均值
总是和他们期望
的均值
相近,上式从概率的角度来说对这样一个结论进行了描述:即他们之间误差值不小于
,可以看出当观测到的变量越多,观测值的均值越逼近期望的均值。
- McDiarmid不等式:若为个独立随机变量,且对任意
 ,函数
,函数 满足
满足

则对任意,有
解析:McDiarmid不等式:首先解释下前提条件:
变到
的时候,其变化的上确界
仍满足不大于
。所谓上确界
和其期望值
也相近,从概率的角度描述是:他们之间差值不小于
,可以看出当每次变量改动带来函数值改动的上限很小,函数值和其期望越相近。
PAC学习
计算学习理论中最基本的是概率近似正确(Probably Approximately Correct,简称PAC)学习理论。
对同样大小的不同训练集,学得结果也可能有所不同。因此,我们希望以比较大的把握学得比较好的模型,也就是说,也较大的概率学得误差满足预设上限的模型,这就是”概率””近似正确”的含义。令 表示置信度,可定义
表示置信度,可定义
定义12.1 PAC辨识(PAC Identify)
对 ,所有
,所有 和分布,若存在学习算法
和分布,若存在学习算法 ,其输出假设
,其输出假设 满足:
满足:
解析:PAC的辨识:
,那么我们称学习算法
中PAC辨识概念类
。 下面的式子(2-6)的公式是为了回答一个问题:到底需要多少样例才能学得目标改变c的有效近似。只要训练集
则称算法能从假设空间中PAC辨识概念类。
这样的学习算法能以较大的概率(至少)学得目标概念 的近似(误差最多为),在此基础上定义:
的近似(误差最多为),在此基础上定义:
定义12.2 PAC可学习(PAC Learnable)
令表示从分布中独立同分布采样得到的样例数目, ,对所有分布,若存在学习算法和多项式函数
,对所有分布,若存在学习算法和多项式函数 ,使得对于任何
,使得对于任何 能从假设空间中PAC辨识概念类,则称概念类对假设空间而言是PAC可学习的,有时也简称概念类是PAC可学习的。
能从假设空间中PAC辨识概念类,则称概念类对假设空间而言是PAC可学习的,有时也简称概念类是PAC可学习的。
对计算机算法来说,必然要考虑时间复杂度,于是:
定义12.3 PAC学习算法(PAC Learning Algorithm)
若学习算法使概念类为PAC可学习的,且的运行时间也是多项式函数 ,则称概念类是高效PAC可学习(efficiently PAC learnable)的,则称为概念类的PAC学习算法。
,则称概念类是高效PAC可学习(efficiently PAC learnable)的,则称为概念类的PAC学习算法。
假定学习算法处理每个样本的时间为常数,则的时间复杂度等价于样本复杂度。于是,我们对算法时间复杂度的关心就转化为样本复杂度的关心。
定义12.4 样本复杂度(Sample Complexity)
满足PAC学习算法所需的 中最小的,称为学习算法的样本复杂度
中最小的,称为学习算法的样本复杂度
显然,PAC学习给出了一个抽象地刻画机器学习能力的框架,基于这个框架对很多重要问题进行理性探讨,例如研究某任务在什么样的条件下可学得较好的模型?某算法在什么样的条件下可进行有效的学习?需多少训练样例才能获得较好的模型?
PAC学习中一个关键因素是假设空间的复杂度。包含了学习算法所有可能输出的假设,若在PAC学习中假设空间与概念类完全相同,即 ,这称为”恰PAC可学习”(properly );直观地看,这意味着学习算法的能力与学习任务”恰好匹配”。
,这称为”恰PAC可学习”(properly );直观地看,这意味着学习算法的能力与学习任务”恰好匹配”。
然而,这种让所有候选假设都来自概念类的要求看似合理,但却不实际,因为在现实应用中我们对概念类通常一无所知,更别说获得一个假设空间与概念类恰好相同的算法。显然,更重要的是研究假设空间与概念类不同的清醒,即 。一般而言,越大,其包含任意目标概念的可能性越大,但从中找到某个具体目标概念的难度也越大,
。一般而言,越大,其包含任意目标概念的可能性越大,但从中找到某个具体目标概念的难度也越大, 有限时,我们称为”有限假设空间”,否则称为”无限假设空间”.
有限时,我们称为”有限假设空间”,否则称为”无限假设空间”.
有限假设空间
可分情形
可分情形意味着目标概念属于假设空间,即 。给定包含个样例的训练集,如何找出满足误差参数的假设呢?
。给定包含个样例的训练集,如何找出满足误差参数的假设呢?
容易想到一种简单的学习策略:既然中样例标记都是由目标概念所赋予的,并且存在于假设空间中,那么,任何在训练集上出现标记错误的假设肯定不是目标概念。于是,我们只需保留与一致的假设,剔除与不一致的假设。若训练集足够大,则可不断借助中的样例剔除不一致的假设,直到中仅剩下一个假设为止,这个假设就是目标概念。通常情况下,由于训练集规模有限,假设空间可能存在不止一个与一致的”等效”假设,对这些等效假设,无法根据来对它们的优劣做进一步区分。
到底需多少样例才能学得目标概念的有效近似呢?对PAC学习来说,只要训练集的规模能使学习算法以概率找到目标假设的近似即可。
我们先估计泛化误差大于但在训练集上仍表现完美的假设出现的概率,假定的泛化误差大于,对分布上随机采样而得的任何样例 ,有
,有
解析:
因为它们是对立事件,
是泛化误差的定义,由于我们定义了泛化误差
,因此有

由于包含个从独立同分布采样而得的样例,因此,与表现一致的概率为:
解析:先解释什么是
为True。因为每个事件是独立的,所以上式可以写成
根据对立事件的定义有:
又根据式子(2)有

我们事先并不知道学习算法会输出中的哪个假设,但仅需保证泛化误差大于,且在训练集上表现完美的所有假设出现概率之和不大于即可:
解析:首先解释为什么”我们事先不知道学习算法
,根据式子(3),每一个这样的假设
假设一共有
和
成立的事件是互斥的,因此总的概率
就是这些互斥事件之和即
小于号依据公式(3).第二个小于号时间上是要证明
,即证明
,其中
是正整数。 推导如下: 当
时,显然成立,当
时,因为左式和右式的值域均大于0,所以可以左右两边同时取对数,又因为对数函数是单调递增函数,所以即证明
,所以即证明
,这个式子很容易证明:令
,其中
取极大值,因此
,也即
令式子(4)不大于,即
解析:回到我们要回答的问题:到底需要多少样例才能学得目标概念
因此学习算法
这个概率我们甚至希望至少是

可得
推导:
解析:这个式子告诉我们,在假设空间
。这也是我们在机器学习中的一个共识,即可供模型训练的观测集样本数量越多,机器学习模型的泛化性能越好。
由此可知,有限假设空间都是PAC可学习的,所需的样例数目如式子(6)所示,输出假设的泛化误差岁样例数目的增多而收敛到0,收敛速度为。
不可分情形
对较为困难的学习问题,目标概念往往不存在于假设空间中,假定对任何 ,也就是说,中的任意一个假设都会在训练集上出现或多或少的错误。由Hoeffding不等式易知:
,也就是说,中的任意一个假设都会在训练集上出现或多或少的错误。由Hoeffding不等式易知:
引理12.1
若训练集包含个从分布上独立同分布采样而得的样例, ,若对任意
,若对任意 ,有
,有
推论12.1
若训练集包含个从分布上独立同分布采样而得的样例,,则对任意,式子(10)以至少的概率成立
推导:令
,则
,由式子(9)
带入
推论12.1表明,样例数目较大时,的经验误差是其泛化误差很近的近似,对于有限假设空间,我们有:
定理12.1
若为有限假设空间, ,则对任意,有
,则对任意,有
推导:令
表示假设空间
这一步是很好理解的,存在一个假设
概率可以表示为对假设空间内所有的假设
,使得
这个事件的”或”事件,因为
,而
,所以最后一行的不等式成立.由式子(9)可知
因此:
其对立事件:
令
,则
,代入上式中可得到:
其中
这个前置条件可以省略.
证明: 令表示假设空间中的假设,有
由式子(9)可得
于是,令 即可得式子(11)
即可得式子(11)
显然,当时,学习算法 无法学得目标概念得近似,但是,当假设空间给定时,其中必存在一个泛化误差最小的假设,找出此假设得近似也不失为一个较好得目标。中泛化误差最小得假设是
无法学得目标概念得近似,但是,当假设空间给定时,其中必存在一个泛化误差最小的假设,找出此假设得近似也不失为一个较好得目标。中泛化误差最小得假设是 ,于是,以此为目标可将PAC学习推广到
,于是,以此为目标可将PAC学习推广到 得情况,这称为”不可知学习”(agnostic learning)。相应地我们有
得情况,这称为”不可知学习”(agnostic learning)。相应地我们有
定义12.5 不可知PAC学习
令表示从分布中独立同分布采样得到得样例数目, ,对所有分布,若存在学习算法和多项式函数
,对所有分布,若存在学习算法和多项式函数 ,使得对于任何
,使得对于任何 能从假设空间中输出满足式(12)得假设:
能从假设空间中输出满足式(12)得假设:
解析:这个式子是”不可知PAC可学习”的定义式,不可知是指当前目标概念
,且这个假设的泛化误差满足其与目标概念的泛化误差的差值不大于
则称假设空间是不可知PAC可学习的。
与PAC可学习类似,若学习算法的运行时间也是多项式函数,则称假设空间是高效不可知PAC可学习的,学习算法则称为空间的不可知PAC学习算法,满足上述要求的最小称为学习算法的样本复杂度。

若有收获,就点个赞吧
0 人点赞
