SVM到底是什么东东?
SVM是一种监督学习模型.
首先得有一个已经标记的数据集.
示例:我有一家公司,每天都会收到很多来自客户的电子邮件。其中一些电子邮件是投诉邮件,应尽快答复。我想要一种快速识别它们的方法,以便我优先回答这些电子邮件。
方法1:我可以使用关键字在gmail中创建标签,例如“紧急”,“投诉”,“帮助”
这种方法的缺点是,我需要考虑一些愤怒的用户可能使用的所有潜在关键字,而我可能会错过其中一些。随着时间的流逝,我的关键字列表可能会变得非常凌乱,并且很难维护。
方法2:我可以使用监督式机器学习算法。
Step1:我需要大量电子邮件,越多越好。
Step2:我将阅读每封电子邮件的标题,并说“这是投诉”或“这不是投诉”进行分类。它在每封电子邮件上贴上标签 。
Step3:我将在此数据集上训练模型。
Step4:我将评估预测的质量(使用交叉验证)。
Step5:我将使用此模型来预测电子邮件是否为投诉。
在这种情况下,如果我用大量电子邮件训练了该模型,那么它将运行良好。SVM只是您可以用来从这些数据中学习并进行预测的众多模型之一。
请注意,关键部分是步骤2。如果为SVM提供未标记的电子邮件,则它将无济于事。
SVM学习线性模型
现在,我们在前面的示例中看到,在第3步中,有监督的学习算法(例如SVM)使用标记的数据进行了训练。但是,它的训练目的是什么?它被训练来学习一些东西。
它学到什么?
对于SVM,它将学习线性模型。
什么是线性模型?用简单的话来说:这是一条线(用复杂的话说就是超平面)。
如果您的数据非常简单并且只有二维,那么SVM将学习一条能够分离数据的线。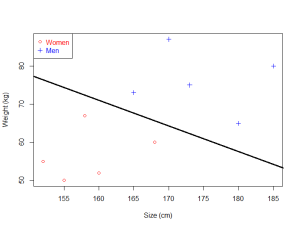
如果只是一条线,为什么我们要讨论线性模型?
因为你不能学线。
因此,除了:
- 1)我们假设要分类的数据可以用一行分隔
- 2)我们知道一条线可以由等式表示 ÿ= w x + by=wx+b (这是我们的模型)
- 3)我们知道通过改变的值可以获得无限的线 w 和 b
- 4)我们使用一种算法来确定哪些值是 w 和 b 给出分隔数据的“最佳”行。
算法还是模型
在文章的开头,我说过SVM是一种监督学习模型,现在我说它是一种算法。怎么了?术语算法经常被宽松地使用。例如,您有时会读到SVM是一种监督学习算法。如果您认为算法是为获得特定结果而执行的一组操作,则情况并非如此。顺序最小优化是训练SVM的最常用算法,但是您可以使用诸如Coordinatedescent的另一种算法训练SVM 。但是,大多数人对这样的细节不感兴趣,因此我们简化并说我们使用了SVM“算法”(没有详细说明我们使用的是哪个)。
SVM or SVMS
有时候人们会说SVM,有时候人们会说SVMS.
通常,维基百科非常擅长清楚地说明事情:
在机器学习中,支持向量机(SVMS) 是带有相关学习算法的监督学习模型 ,该算法分析用于分类和回归分析的数据。(维基百科)
SVM(Support Vector Machine)
维基百科告诉我们,支持向量机可以用来做两件事:分类或回归。
- SVM用于分类
- SVR(支持向量回归)用于回归
分类
1957年,弗兰克·罗森布拉特(Frank Rosenblatt)发明了一个称为Perceptron的简单线性模型来进行分类(实际上这是简单神经网络的组成部分之一,也称为多层Perceptron)。
几年后, Vapnik和Chervonenkis提出了另一种称为“最大保证间隔分类器”的模型,SVM诞生了。
然后,在1992年,Vapnik等人。有个想法就是应用所谓的Kernel Trick,它允许使用SVM对线性不可分离的数据进行分类。
最终,在1995年,Cortes和Vapnik引入了Soft Margin分类器,这使我们在使用SVM时可以接受一些错误分类。
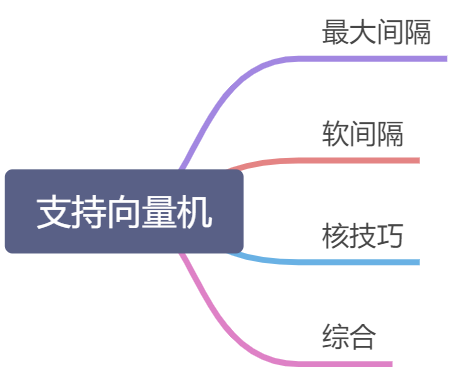
因此,当我们谈论分类时,已经有四种不同的支持向量机:
- 原始的:最大间隔分类器
- 使用内核技巧的内核版本
- 软间隔
- 软间隔+内核技巧版本(结合1、2和3)
当然,这是大多数时候使用的最后一个。这就是为什么SVM最初很难理解的原因,因为它们由随时间而来的几部分组成。
因此,在使用编程语言时,经常会要求您指定要使用的内核(由于内核技巧),以及要使用的超参数C的值(因为它控制软间隔的效果)。
回归
在1996年,Vapnik等人。提出了一个SVM版本来执行回归而不是分类。它称为支持向量回归(SVR)。与分类SVM一样,此模型包括C超参数和内核技巧。
我写了一篇简单的文章,解释了如何在R中使用SVR。
如果您想了解有关SVR的更多信息,可以阅读Smola和Schölkopft撰写的本教程。
历史总结
- 最大保证间隔分类器(1963或1979)
- 内核技巧(1992)
- 软间隔分类器(1995)
- 支持向量回归(1996)
如果您想了解更多信息,可以学习一下这个非常详细的历史概述。
结论
我们了解到,很难理解到底什么是SVM。这是因为有几种支持向量机用于不同目的。与往常一样,历史使我们可以更好地了解我们今天所知道的SVM是如何构建的。
我希望本文能使您对SVM全景图有更广泛的了解,并使您能够更好地了解这些机器。
如果您想了解有关SVM如何进行分类的更多信息,可以开始阅读数学系列:

若有收获,就点个赞吧
0 人点赞
