https://www.mathworks.com/help/stats/fitensemble.html#bu_rbq9-5
函数
函数形式
Mdl = fitensemble(Tbl, ResponseVarName, Method, NLearn, Learners)Mdl = fitensemble(Tb1, formula, Method, NLearn, Learners)Mdl = fitensemble(Tbl, Y, Method, NLearn, Learners)Mdl = fitensemble(X, Y, Method, NLearn, Learners)Mdl = fitensemble(__, Name, Value)函数解释
fitensemble可以boost或者bag决策树或者判别分类器,还可以训练随机子空间集合的KNN或判别分类器。
对于更简单的分类和回归的分类器接口函数,可以使用fitcensemble和fitrensemble。函数一
Mdl = fitensemble(Tbl, ResponseVarName, Method, NLearn, Learners)
输入参数:
- Tb1:包含的变量
- ResponseVarName:变量的名字,就是我们的label标签变量名
- Method:提升方式
- NLearn:学习周期
- Learners:基学习器
输出参数:
- Mdl:分类或回归的学习器的组合形式
例子:
这个例子中的carsmall数据集包含的数据:Acceleration:100x1, Cylinders:100x1, Displacement:100x1, Horsepower:100x1, Mfg:100x13char, Model:100x33char, Model_Year:100x1char, MPG:100x1, Origin:100x7,
Weight:100x1
%{使用回归树集成学习器预测汽车用油价格。变量有:汽车的缸数、缸排量、马力和重量等%}load carsmall;Tb1 = table(Cylinders, Displacement, Horsepower, Weight, MPG); %选取变量t = templateTree('Surrogate','On'); %这个回归树模型使用Surrogate提升准确率%使用LSBoost提升,回归的价格是MPG,100是学习周期,t是学习的基学习器Mdl1 = fitensemble(Tb1, 'MPG', 'LSBoost', 100, t);predMPG = predict(Mdl1, [4, 200, 150, 3000]) %根据模型预测价格%{预测结果predMPG =22.8462%}%--------使用Displacement以外的变量重新训练一个分类器------------formula = 'MPG ~Cylinders + Horsepower + Weight';Mdl2 = fitensemble(Tb1, formula, 'LSBoost', 100, t);predMPG2 = predict(Mdl2, [4, 150, 3000])%{预测结果predMPG2 =23.9478%}%-----------计算均方误差-------------------------mse1 = resubLoss(Mdl1)%{计算结果mse1 =6.4721%}mse2 = resubLoss(Mdl2)%{计算结果mse2 =7.8599%}
函数二
Mdl = fitensemble(Tb1, formula, Method, NLearn, Learners)
函数三
Mdl = fitensemble(Tbl, Y, Method, NLearn, Learners)
函数四
Mdl = fitensemble(X, Y, Method, NLearn, Learners)
例子
数据集:ionosphere 包含X:351x34,Y:351x1大小,是分类的例子
load ionosphere;%-------------训练分类器-------------ClassTreeEns = fitensemble(X,Y,'AdaBoostM1',100,'Tree');%------------计算累计损失----------------rsLoss = resubLoss(ClassTreeEns, 'Mode', 'Cumulative');%------------画出损失图-------------------plot(rsLoss);xlabel('Number of Learning Cycles');ylabel('Resubstitution Loss');
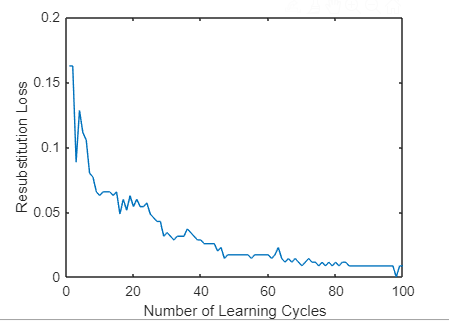
函数五
Mdl = fitensemble(__, Name, Value)
例子
%找到合适的分割数据的点和要提升的树的类型load carsmallX = [Acceleration, Displacement, Housepower, Weight];Y = MPG;%{寻找到合适的分割点的步骤:1.2. 交叉验证这些提升器3. 对于每个提升的分类器,计算MSE4. 比较不同的提升器的MSE,选择MSE最小的一个,就是最大的一个分割点数,最好的树的数量和最好的学习率%}MdlDeep = fitrtree(X, Y, 'CrossVal', 'on', 'MergeLeaves', 'off', 'MinParentSize', 1, 'Surrogate', 'on');MdlStump = fitrtree(X, Y, 'MaxNumSplits', 1, 'CrossVal', 'on', 'Surrogate', 'on');%{使用150个回归树训练提升器,使用5折交叉验证。学习率选取{0.1, 0.25, 0.5, 1}%}n = size(X, 1);m = floor(log2(n - 1));lr = [0.1, 0.25, 0.5, 1];maxNumSplits = 2.^(0:m);numTrees = 150;Mdl = cell(numel(maxNumSplits), numel(lr));rng(1); %For reproducibilityfor k = 1:numel(lr) %选取不同的学习率for j = 1:numel(maxNumSplits) %选取不同的分割点t = templateTree('MaxNumSplits', maxNumSplits(j), 'Surrogate', 'on');Mdl{j, k} = fitensemble(X,Y, 'LSBoost', numTrees, t, 'Type', 'regression', ...'KFole', 5, 'LearnRate', lr(k));endend%--------计算每个提升器的MSEkflAll = @(x)kfoldLoss(x, 'Mode', 'cumulative'); %得到函数句柄errorCell = cellfun(kflAll, Mdl, 'Uniform', false); %对于每个单元都是用这个函数计算error = reshape(cell2mat(errorCell), [numTrees, numel(maxNumSplits), numel(lr)]);errorDeep = kfoldLoss(MdlDeep);errorStump = kfoldLoss(MdlStump);%{观察一下随着树的深度和树桩的数目的增加提升器的MSE是怎么变化的%}mnsPlot = [1, round(numel(maxNumSplits)/2, numel(maxNumSplits))];figure;for k = 1:3subplot(2, 2, k);plot(squeeze(error(:, mnsPlot(k), :)), 'LineWidth', 2);axis tight;hold on;h = gca;plot(h.XLim, [errorDeep, errorDeep], '-.b', 'LineWidth', 2);plot(h.XLim, [errorStump, errorStump], '-.r', 'LineWidth', 2);plot(h.XLim, min(min(error(:, mnsPlot(k), :))).*[1, 1], '--k');h.YLim = [10, 50];xlabel('Number of trees');ylabel('Cross-validated MSE');title(sprintf('MaxNumSplits = %0.3g', maxNumSplits(mnsPlot(k))));hold off;endhL = legend([cellstr(num2str(lr', 'Learning Rate = %0.2f')); 'Deep Tree'; 'Stump'; 'Min.MSE']);hL.Position(1) = 0.6;
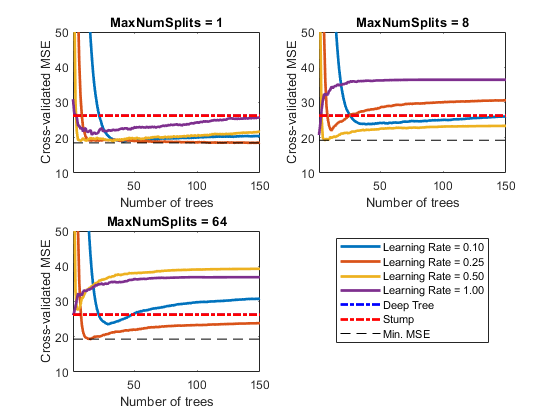
图2. 损失函数图
[minErr, minErrIdxLin] = min(error(:));[idxNumTrees, idxMNS, idxLR] = ind2sub(size(error), minErrIdxLin);fprintf('\nMin.MSE = %0.5f', minErr);%{Min. MSE = 18.42979%}fprintf('\nOptimal Parameter Vaules:\nNum. Trees = %d', idxNumTrees)%{Optimal Parameter Values:Num. Trees = 1%}fprintf('\nMaxNumSplits = %d\nLearning Rate = %0.2f\n', maxNumSplits(idxMNS), lr(idxLR))%{MaxNumSplits = 4Learning Rate = 1.00%}
参数
输入参数
Tbl
Tbl:采样的数据
每列代表一个不同的变量,行数为点数。
- 如果
Tbl包含要标签,然后想用除了标签的以外的数据来预测的话,使用ResponseVarName(标签的变量名) - 如果
Tbl包含标签,并且标签以外的数据并不想全部使用的话,使用formula - 如果
Tbl不包含标签数据,我们就把标签数据这1个向量用Y表示
Method
二分类的提升方式:
- AdaBoostM1
- LogitBoost
- GentleBoost
- RobustBoost
- LPBoost
- TotalBoost
- RUSBoost
- Subspace
- Bag
三分类及以上的提升方式:
- AdaBoostM2
- LPBoost
- TotalBoost
- RUSBoost
- Subspace
- Bag
回归
- LSBoost
- Bag
Learners
| Weak Learner | Weak-Learner Name | Template Object Creation Function | Method Setting | | —- | —- | —- | —- | | Discriminant analysis | ‘Discriminant’ | templateDiscriminant | 推荐’Subspace’ | | k nearest neighbors | ‘KNN’ | templateKNN | 只有’Subspace’ | | Decision tree | ‘Tree’ | templateTree | 除了’Subspace’ |

若有收获,就点个赞吧
0 人点赞
