VC维

先来看几个概念:增长函数(growth function)、对分(dichotomy)和打散(shattering)。给定假设空间 和示例集
和示例集 ,中每个假设
,中每个假设 都能对
都能对 中示例赋予标记,标记结果可表示为:
中示例赋予标记,标记结果可表示为:
随着 的增大,中所有假设对中的示例所能赋予标记的可能结果也会增大。
的增大,中所有假设对中的示例所能赋予标记的可能结果也会增大。
例如:对二分类,若
种,若有3个示例,则可能结果
种。
定义12.6
对所有 ,假设空间的增长函数
,假设空间的增长函数 为
为
增长函数表示假设空间对个示例所能赋予标记的最大可能结果数。显然,对示例所能标记的可能结果数越大,的表示能力越强,对学习任务的适应能力越强。因此,增长函数描述了假设空间的表示能力,由此反映出假设空间的复杂度,我们可利用增长函数来估计经验误差与泛化误差之间的关系:
解析:这个是增长函数的定义式。增长函数
如果假设空间
能赋予这两个样本标签组合
则
。显然,
定理12.2
对假设空间 ,
, 有
有
解析:详细证明参见原论文 On the uniform convergence of relative frequencies of events to their probabilities.[3]
假设空间种不同的假设对于种示例赋予标记的结果可能相同,也可能不同;尽管可能包含无穷多个假设,但其对中示例赋予标记的可能结果数是有限的:对个示例,最多有 个可能结果。
个可能结果。
对二分类问题来说,中的假设对中示例赋予标记的每种可能结果称为对的一种”对分”(每个假设会把中示例分为两类,因此称为对分)。若假设空间能实现示例集上的所有对分,即 ,则称示例集能被假设空间“打散”。
,则称示例集能被假设空间“打散”。
定义12.7
假设空间的VC维是能被打散的最大示例集的大小,即
解析:这是
维的定义式:
分类的问题,那么定义式中底数需要变为
 表明存在大小为
表明存在大小为 的示例集能被假设空间打散,注意:这并不意味着所有大小为的示例集都能被假设空间打散。的定义与数据分布
的示例集能被假设空间打散,注意:这并不意味着所有大小为的示例集都能被假设空间打散。的定义与数据分布 无关。因此,在数据分布未知时仍能计算发出假设空间的维
无关。因此,在数据分布未知时仍能计算发出假设空间的维
通常这样来计算的维:若存在大小为的示例集能被打散,但不存在任何大小为 的示例集能被打散,则的维是。下面给出两个计算维的例子:
的示例集能被打散,则的维是。下面给出两个计算维的例子:
例12.1 实数区域中的区间
令表示实数域中所有闭区间构成的集合 。对
。对 ,若
,若 ,则
,则 ,否则
,否则 .
.
令 ,则假设空间中存在假设
,则假设空间中存在假设 将
将 打散,所以假设空间的维至少为2;则对任意大小为3的示例集
打散,所以假设空间的维至少为2;则对任意大小为3的示例集 ,不妨设
,不妨设 ,则中不存在任何假设
,则中不存在任何假设 能实现对分结果
能实现对分结果 。于是的维为2.
。于是的维为2.
例12.2 二维实平面上的线性划分:
令表示二维平面上所有线性划分构成的集合, 。由图12.1可知,存在大小为3的示例集可以被打散,但不存在大小为4的示例集可被打散,于是,二维实平面上所有线性划分构成的假设空间的维为3.
。由图12.1可知,存在大小为3的示例集可以被打散,但不存在大小为4的示例集可被打散,于是,二维实平面上所有线性划分构成的假设空间的维为3.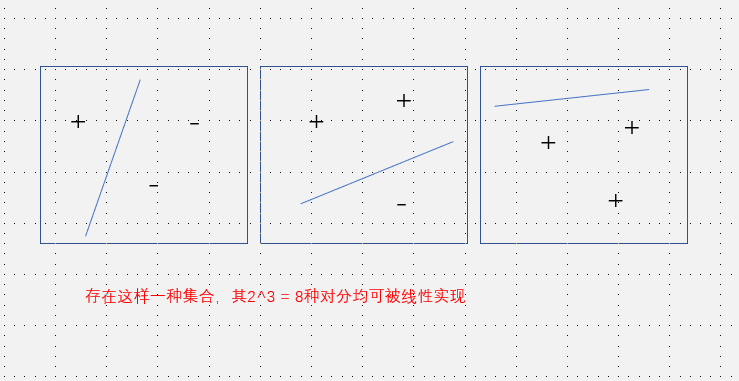
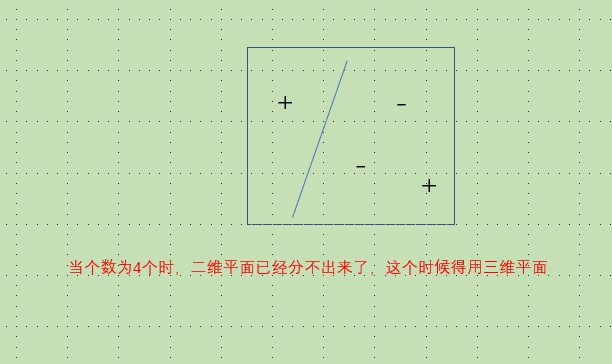
一维分两个数,二维分三个数,….(这个和支持向量机中的核函数类似)
引理12.2
若假设空间的维为,则对任意,有
解析:首先解释下数学归纳法的起始条件”当
或
时,定理成立”,当
可知
,否则
,式12.24右边为
,因此不等式成立。当
时,因为一个样本最多只能有两个类别,所以
,不等式右边为
,因此不等式成立。 在介绍归纳过程,这里采用的归纳方法是假设12.24对
和
成立,推导出其对
也成立。证明过程中引入观测集
和观测集
,其中
多一个样本
,它们对应的假设空间可以表示为:
如果假设
对
或
,那么任何出现在
中的串都会在
出现一次或者两次.这里举个例子就容易理解了,假设
:
其中串
在
,
均只在
,要么取
,要么都取到(至少两个假设
表示在
,有
由于
,根据增长函数的定义,假设空间
.因此
.又根据数学归纳法的前提假设,有
由记号
,因此
,由于样本集
.假设
表示能被
必对元素
必能被
,综上有
因此:
注:最后一步依据组合公式,推导如下:

证明:由数学归纳法证明,当或时,定理成立。假设定理对和成立。令

任何假设 对
对 的分类结果为或者,因此任何出现在的串都会在中出现一次或两次。令表示在出现两次的中串组成的集合,即
的分类结果为或者,因此任何出现在的串都会在中出现一次或两次。令表示在出现两次的中串组成的集合,即
考虑到中的串在出现了两次,但在仅出现了一次,有 的大小为,由假设可得
的大小为,由假设可得
令表示能被打散的集合,由定义可知 必能被打散,由于的维为,因此的维最大为,于是有:
必能被打散,由于的维为,因此的维最大为,于是有:
由式子(12.25-12.27)可得:
由集合的任意性,引理12.2得证。
从引理12.2可计算出增长函数的上界:
推论12.2
若假设空间的维为,则对任意整数 有
有
证明:
第一步到第二部和第三步到第四步均因为
其中,令
得
,最后一步得不等式即需证明
,因为
,根据自然对数
得定义,
,注意原文中用的是
,但是由于
的定义是一个极限,所以应该是用
.
定理12.3
若假设空间的维为,则对任意 和有
和有
推导:这里应该是作者的笔误,根据式子12.22,
应当被绝对值符号包裹.将式子12.28代入式子12.22得
令
可解得
代入式子12.22,则定理得证这个式子使用
(书上简化为
).
证明:令 ,解得
,解得
代入定理12.2,于是定理12.3得证。
由定理12.3可知,式子(12.29)的泛化误差只与样例数目有关,收敛速度为 ,与数据分布和样例集无关。因此,基于维的泛化误差是分布无关(distribution-free)、数据独立(data-independence)的。
,与数据分布和样例集无关。因此,基于维的泛化误差是分布无关(distribution-free)、数据独立(data-independence)的。
令表示学习算法 输出的假设,若满足
输出的假设,若满足
解析:这个是经验风险最小化得定义式,即从假设空间中找出能使经验风险最小得假设.
则称为满足经验风险最小化(Empirical Risk Minimization,简称ERM)原则的算法,我们有以下的定理:
定理12.4
任何维有限的假设空间都是(不可知)PAC可学习的。
证明:假设为满足经验风险最小化原则的算法,为学习算法输出的假设。令 表示中具有最小泛化误差的假设,即
表示中具有最小泛化误差的假设,即
解析:首先回忆PAC可学习概念,见定义12.2,而可知/不可知PAC可学习之间的区别仅在于概念类
是否包含于假设空间
结合这两个标记的转换,由推论12.1可知:
至少以
的概率成立.写成概率的形式即:
即
,因此
且
.再令
由式子12.29可知
且
成立.由
均成立可知事件
和事件
同时成立的概率为:
即
因此
再由
,因此上式可以简化为
根据式子12.32和式子12.34,可以求出
的多项式,因此根据定理12.2,定理12.5,得到结论任何
令

由推论12.1可知
至少以 的概率成立,令
的概率成立,令
则由定理12.3可知
从而可知
以至少 的概率成立。由式子(12.32)和(12.34)可以解出,再由的任意性可知定理12.4得证。
的概率成立。由式子(12.32)和(12.34)可以解出,再由的任意性可知定理12.4得证。

若有收获,就点个赞吧
0 人点赞
