速度和存储空间的优化
许多类似于xgboost这样的boosting工具都是使用的预先排序好的决策树学习基算法,这个解决方法很巧妙,但是很难优化。
而LightGBM使用基于直方图的算法,能够将连续的特征分成一个个的小块(深度学习中有这个),这样就加速了训练减少了存储空间需求。
准确率上的优化
许多的决策树学习的增长算法都是通过不断加深树的深度来进行的,就如图1所示: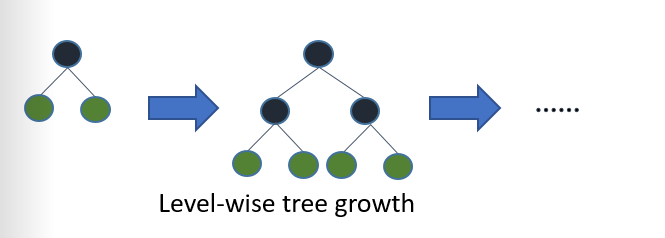
图1. 决策树生长算法
但是LightGBM是通过找到损失最大的节点,然后在这个节点的基础上进行生长,原先的生长算法随着整个树的宽度的增加,数据趋于过拟合,而LightGBM算法能够提升学习树的深度来避免过拟合。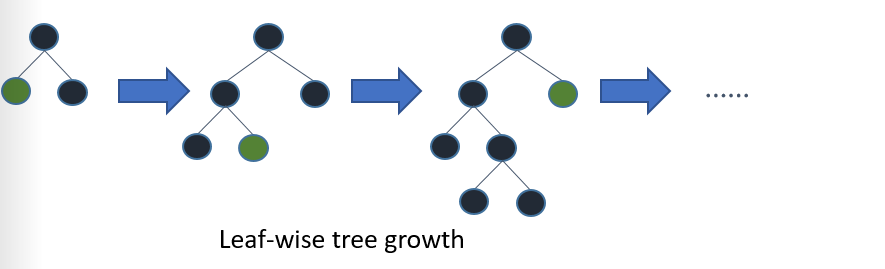
图2. LightGBM学习树生长算法
LightGBM的应用和指标
应用
LightGBM支持以下应用:
- 回归,它的目标函数是L损失
- 二分类问题(binary classfication),目标函数时
logloss - 多分类问题
- 交叉熵,目标函数是
logloss和支持非二分类标签的训练 lambdarank(?),目标函数是有NDCG的
lambdarank指标
L损失
- L损失
- Log 损失
- 分类错误率
- AUC
- NDCG
- MAP
- 多分类的log损失
- 多分类的错误率
- Fair
- Huber
- 泊松分布
- Quantile
- MAPE
- Kullback-Leibler
- Gamma
- Tweedie
更多的关于指标部分,https://github.com/microsoft/LightGBM/blob/master/docs/Parameters.rst#metric-parameters。
其他特征
- 决策树的最大深度
- DART
- L/L归一化
- Bagging
- 特征子样本
- 对于给定的GBDT模型的连续训练
- 对于给定分数文件的训练
- 权重训练
- 在训练期间的验证集的指标输出
- 多个验证集
- 多个指标
- Early stopping
- 预测结果
参考链接
参考链接:Features

若有收获,就点个赞吧
0 人点赞
