一、实验目的
- 掌握支持向量机的原理、核函数选择以及核参数选择原则等;
-
二、实验内容
对bedroom,forest两组数据进行二分类
-
三、实验条件
libSVM安装包
- Matlab
四、实验方法与流程
4.1实验流程
4.2实验数据准备
“bedroom.mat”1015的矩阵,分别代表了不同的十张有关于bedroom的图片的15维属性;
“forest.mat”1015矩阵,分别代表了不同的十张有关于forest的图片的15维属性特征;
训练集:trainset(); 分别取bedroom(1:5,:)和forse(1:5,:)作为训练集;
测试集:testset(); 分别取bedroom(6:10,:)和forse(6:10,:)作为测试集;
标签集:label(); 取bedroom的数据为正类标签为1;forse的数据为负类标签为-1.4.3实验代码
```matlab clear; clc; % dataset是将bedroom和forest合并;dataset = [bedroom;forset];这行代码可以实现合并 %load dataset.mat %导入要分类的数据集 load bedroom.mat load forest.mat load labelset.mat %导入分类集标签集
% 选定训练集和测试集 dataset = [bedroom;MITforest];
% 将第一类的1-5,第二类的11-15做为训练集 train_set = [dataset(1:5,:);dataset(11:15,:)]; % 相应的训练集的标签也要分离出来 train_set_labels = [lableset(1:5);lableset(11:15)]; % 将第一类的6-10,第二类的16-20,做为测试集 test_set = [dataset(6:10,:);dataset(16:20,:)]; % 相应的测试集的标签也要分离出来 test_set_labels = [lableset(6:10);lableset(16:20)];
% 数据预处理,将训练集和测试集归一化到[0,1]区间
[mtrain,ntrain] = size(train_set); [mtest,ntest] = size(test_set);
test_dataset = [train_set;test_set]; % mapminmax为MATLAB自带的归一化函数 [dataset_scale,ps] = mapminmax(test_dataset’,0,1); dataset_scale = dataset_scale’;
train_set = dataset_scale(1:mtrain,:); test_set = dataset_scale( (mtrain+1):(mtrain+mtest),: );
%SVM网络训练 model = libsvmtrain(train_set_labels, train_set, ‘-s 2 -c 1 -g 0.07’);
%SVM网络预测 [predict_label] = libsvmpredict(test_set_labels, test_set, model);
%结果分析
% 测试集的实际分类和预测分类图 % 通过图可以看出只有一个测试样本是被错分的 figure; hold on; plot(test_set_labels,’o’); plot(predict_label,’r*’); xlabel(‘测试集样本’,’FontSize’,12); ylabel(‘类别标签’,’FontSize’,12); legend(‘实际测试集分类’,’预测测试集分类’); title(‘测试集的实际分类和预测分类图’,’FontSize’,12); grid on;
但是生成的结果会给你个惊喜,如图所示<br />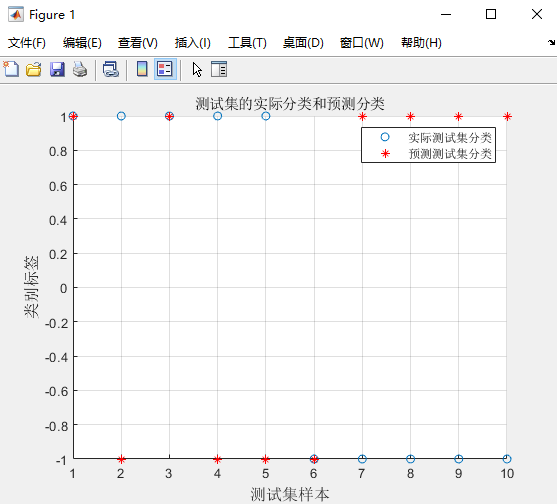<br />30%> *> optimization finished, #iter = 3> nSV = 6, nBSV = 4> Accuracy = 30% (3/10) (classification)所以,我们使用这个SVM最后出来的30%对准确率,这个肯定是有问题的,原来的博客中有人回答将<br />`model = libsvmtrain(train_set_labels, train_set, '-s 2 -c 1 -g 0.07');`改成下面这种的形式`model = libsvmtrain(train_set_labels, train_set, '-s 1 -c 1 -g 0.07');`,结果最后达到了100%。<br />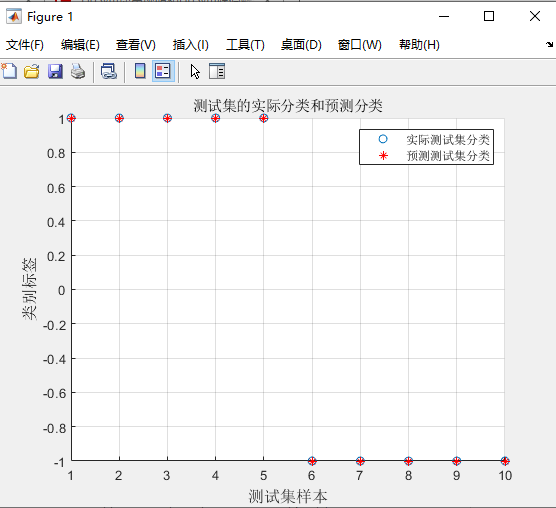<br />100%的准确率> *> optimization finished, #iter = 3> C = 1.548936> obj = 2.307635, rho = 0.002176> nSV = 6, nBSV = 4> Total nSV = 6> Accuracy = 100% (10/10) (classification)这样就达到了100%的准确率,这又是为什么呢?然后找了下关于libsvm的源码的一些解释,[这篇博客](https://blog.csdn.net/haoji007/article/details/80299198)中提到了一些源码的内容,如下:<a name="NOEah"></a>### svmtrain的用法由于我们在安装的时候,已经将其改名为libsvmtrain(这个在下面的安装过程中会提到),所以应该叫`libsvmtrain`的用法更合适,我们看上述问题对应的 `options`的内容```matlab-s~设置svm类型:0 – C-SVC/1 – v-SVC/2 – one-class-SVM/3 –ε-SVR/4 – n - SVR-t~设置核函数类型,默认值为2:0 --线性核:u'*v/1 --多项式核:(g*u'*v+coef0)degree/2 -- RBF核:exp(-γ*||u-v||2)/3 -- sigmoid核:tanh(γ*u'*v+coef0)-d~degree:设置多项式核中degree的值,默认为3-g~γ:设置核函数中γ的值,默认为1/k,k为特征(或者说是属性)数;-r~coef 0:设置核函数中的coef 0,默认值为0;-c~cost:设置C-SVC、ε-SVR、n - SVR中从惩罚系数C,默认值为1;-n~v:设置v-SVC、one-class-SVM与n - SVR中参数n,默认值0.5;-p~ε:设置v-SVR的损失函数中的e,默认值为0.1;-m~cachesize:设置cache内存大小,以MB为单位,默认值为40;-e~ε:设置终止准则中的可容忍偏差,默认值为0.001;-h~shrinking:是否使用启发式,可选值为0或1,默认值为1;-b~概率估计:是否计算SVC或SVR的概率估计,可选值0或1,默认0;-wi~weight:对各类样本的惩罚系数C加权,默认值为1;-v~n:n折交叉验证模式;123456789101112131415
五、安装libsvm
已经下载好的工具箱:libsvm-3.24.zip
数据集:data.zip
5.1 官网下载
在libsvm的官方主页上可以下载libsvm的扩展包,支持MATLAB、Java、Python等多种语言,这里我们选择MATLAB版本,下载zip文件即可。

注意下载完成后还要下载上面的数据集来完成测试
5.2 libSVM的安装
在\libsvm-3.23\matlab目录下,有一个README文件,详细说明了安装方法。
如果是windows 64位系统,预编译的二进制文件已经提供,在\libsvm-3.23\windows文件下,可以看到4个文件,分别是libsvmread.mexw64、libsvmwrite.mexw64、svmtrain.mexw64、svmpredict.mexw64。
这样可以跳过下面第一步的编译步骤。
1.编译
如果是win32位系统,需要自己重新编译c文件,生成MATLAB可识别的mexw32文件。编译方法在上述的README文件也有说明。
将MATLAB的工作文件夹调整到\libsvm-3.23\matlab目录下,在MATLAB的命令行窗口输入>> mex -setup,然后选择编译器如VS2010,最后输入指令>>make。编译完成后,当前路径下会生成对应的mexw32(32位系统)mexw64(64位系统)文件。
过程如下:
matlab>> mex -setup Would you like mex to locate installed compilers [y]/n? y Select a compiler: [1] Microsoft Visual C/C++ version 7.1 in C:\Program Files\Microsoft Visual Studio [0] None Compiler: 1 Please verify your choices: Compiler: Microsoft Visual C/C++ 7.1 Location: C:\Program Files\Microsoft Visual Studio Are these correct?([y]/n): y matlab>> make
注意:
我的操作系统是win7 64位,原先安装的是MATLAB2014a和VS2015,发现并不支持libsvm工具包中提供好的mexw64文件,原因是MATLAB的版本过低。
随后我考虑重新编译生成适合自己版本的mexw64文件,结果发现MATLAB2014a不支持识别VS2015,最高支持到VS2013。
所以解决方法有两种,一种是给给VS降级,一种是给MATLAB升级。由于前者涉及很多.net和c++库文件,比较繁琐,所以最方便的做法是安装新版本的MATLAB,新老版本的MATLAB只要不安装在一个文件夹下,一般不会出现干扰情况。
安装MATLAB2016及以上版本就可以支持以上的mexw64文件,同时也能识别更新的c/c++编译器。
MATLAB 2016b的下载、安装、激活方法,可以参考这个链接。
2.重命名函数
在得到libsvmread.mexw64、libsvmwrite.mexw64、svmtrain.mexw64、svmpredict.mexw64这4个文件后,为了避免和svm内置的函数冲突,最好将svmtrain.mexw64、svmpredict.mexw64这两个文件重命名为libsvmtrain.mexw64、libsvmpredict.mexw64。
3.添加到toolbox
将libsvm-3.23文件夹放置到\MATLAB R2016b\toolbox目录下;
主页> 设置路径> 添加文件夹> 选择libsvm-3.23文件夹;
添加并包含子文件夹> 选择libsvm-3.23文件夹;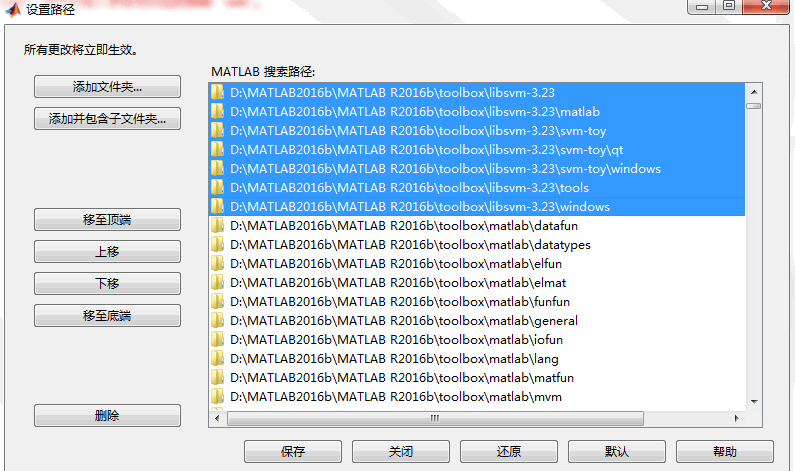
主页> 预设> 常规> 更新工具箱缓存> 确定
5.3 测试
在MATLAB命令行窗口输入一下指令:
load heart_scalemodel = libsvmtrain(heart_scale_label, heart_scale_inst, '-c 1 -g 0.07');[predict_label, accuracy, dec_values] = libsvmpredict(heart_scale_label, heart_scale_inst, model);
若出现以下结果,说明安装正确。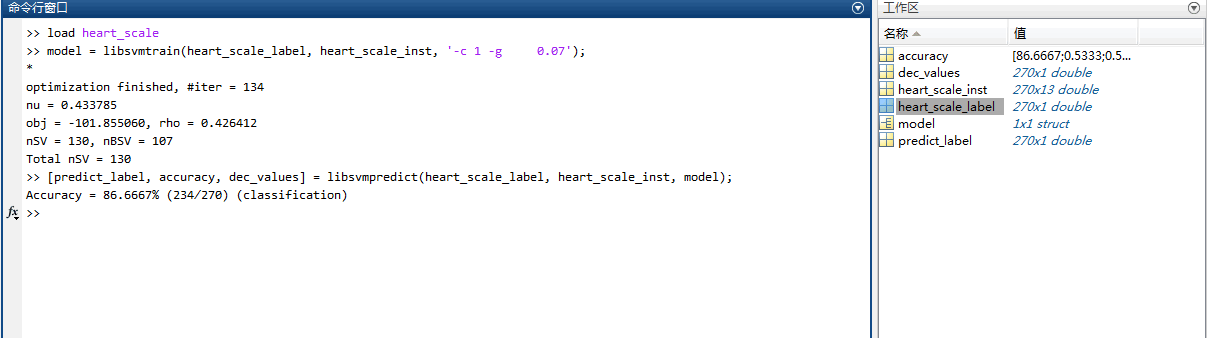
更详细的关于libsvm的使用方法可以参考libsvm文件夹下的README文件或者是官方主页的说明。

若有收获,就点个赞吧
0 人点赞
