数据库基础
定义
数据库(database) 保存有组织的数据的容器;
数据库与数据库软件是两回事,Mysql是数据库软件;
要素
- 表(table)某种特定类型数据的结构化清单
- 列(column)表中的一个字段。所有表都有一列或者多列组成的。每一列都有对应的数据类型
- 行(row)表中的一个记录
主键
主键(primary key)一列(或一组列),其值能够唯一区分表中每个行。
表中每一行都应该有可以唯一标识自己的一列。
表中的任何列都可以作为主键,但是必须满足以下条件:任意两行都不具有相同的主键;
每个行都必须具有一个主键;
主键就像一个人的身份证号码一样,作为一个合法的公民,必须要有而且独一无二;
Sql介绍
SQL是结构化查询语言(Structured Query Language)的缩写,专门用来与数据库进行通信的语言;
SQL不是某个特定的数据库专用语言,几乎所有的DBMS(DataBase Management System)都支持SQL;
SQL简单易学,需要学习的关键词很少;
SQL可以进行非常复杂和高级的数据库操作;
Mysql
Mysql就是一种数据库管理系统,所占的市场份额还是比较大的,那自然就有它的优势可言:
- 免费开源,低成本
- 执行速度快,性能好
- 简单易学使用
- 可信赖的软件
Sql入门
下面就可以真正进行实操了,对于截图中的表结构,可参见该链接;
使用Mysql
选择数据库
- use database;
了解数据库和表
- show databases;
- show tables;
- show columns from table;
检索数据
检索列
- 检索单个列:select col1 from table;
- 检索多个列:select col1,col2 from table;
- 检索全部列:select * from table;
检索不同行
- 在列名之前使用distinct关键词,只返回唯一值:select distinct col in table;
- 不能部分使用distinct,它会作用在全部列上;
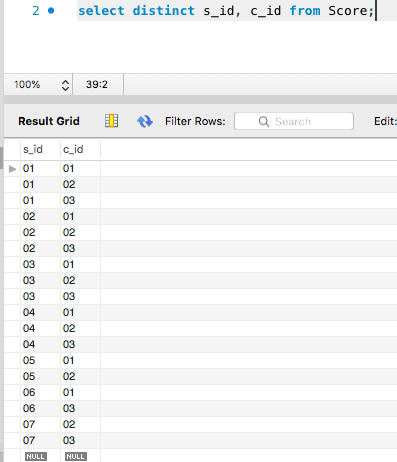
如图所示:可以看到Mysql是将s_id和c_id作为一个整体进行distinct处理了;
限制结果
- limit关键字确保只返回有限的行数:select col1 from table limit 10 (返回不多于10行)
- 指定起始位置:select col1 from table limit 10,5 (10为开始位置,5为行数)
注意细节
- 结果是无序的,返回的是数据被添加到表的顺序
- 使用分号 ; 结束SQL语句
- SQL不区分大小写
- 所有多余的空格均被忽略
排序检索数据
排序数据
- 使用order by
- select col1 from table order by col1
- 也可以依据没有显示的列进行排序
多列排序
- 列名之间用逗号 , 隔开
- select * from table order by col1, col2
- 排序将会先按照col1排序,再按照col2排序
指定排序方向
- 默认是升序排列(A-Z, 1-9)
- 指定关键词DESC降序,ASC升序
- 关键字只作用于特定列,如果需要指定多个列,必须每列都指定关键字
案例
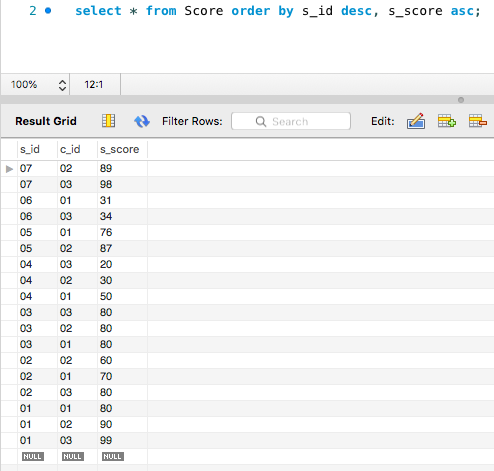
过滤数据
使用where子句
- 对数据进行条件过滤,必须在from子句之后给出
- 检查单个值: where col > 10
- 不匹配检查:where col <> ‘big’
- 范围检查:where col between 1 and 10
- 空值检查:wher col is null
组合where子句
- AND: 组合多个条件语句;同时满足
- OR:匹配任一条件
- 计算次序:SQL优先处理AND语句,后处理OR语句;使用圆括号自定义处理顺序
IN与NOT操作符
- IN操作符用来指定条件范围,范围中的每一条都可以进行匹配,在圆括号中用逗号分隔值
- NOT操作符用于否定全部的过滤子句
通配符
什么是通配符?
通配符(wildcard)是用来匹配值的一部分的特殊字符。在搜索子句中使用通配符必须使用like操作符
百分号 % 通配符
- ‘abc%’ 以abc开头,任意字符结尾的数据
- ‘%abc’ 以abc结尾,任意字符开头的数据
- ‘%abc%’ 任意字符开头和结尾,中间包含abc的数据
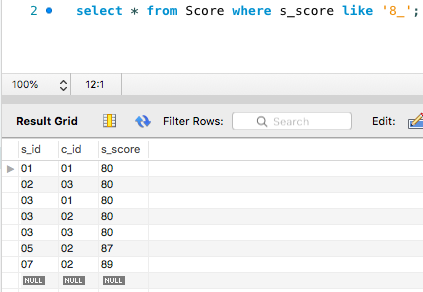
下划线 _ 通配符
- 只匹配单个字符
- ‘_abc’ 以abc结尾,开头只有一个长度的任意字符
注意
- 通配符搜索比较慢,尽可能使用其它操作符
- 尽可能不要把通配符置于搜索的开始之处
- 注意尾部的空格
- 注意null值处理
文本处理函数
注意:SQL支持函数,但是函数却不像SQL具有很强的可移植性,因为不同厂商的DBMS会指定不同的特殊函数,这里我们以mysql为例;
文本处理函数,主要是用于处理文本的函数,对文本数据进行提取转换操作
- rtrim() 删除字符串右边空格
- ltrim() 删除字符串左边空格
- length() 计算字符串长度
- upper() 字符串大写
- lower() 字符串小写
- substring() 字符串子集
- left() 返回字符串最左边的n个字符
时间日期函数
这里,同样以mysql为例;
时间与日期采用了特殊的数据类型和特殊格式存储。Mysql中最常用的数据格式是:yyyy-mm-dd
- curdate() 返回当前日期
- curtime() 返回当前时间
- date() 返回日期时间的日期部分
- datediff() 计算两个日期差
- dayofweek() 返回星期几
- year() 返回年份
- month() 返回月份
- day() 返回天数
- hour() 返回小时
- minute() 返回分钟
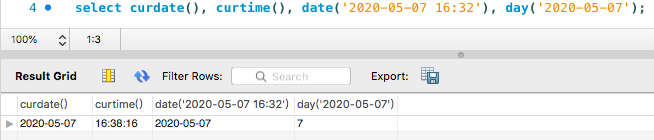
汇总函数
聚合函数
- 运行在行组上,计算和返回单个值的函数
- 常用的avg/count/max/min/sum
null值
- 聚合函数会忽略null值
- 但是count函数特殊,count(*)不会忽略,指定列的时候忽略
组合聚合函数
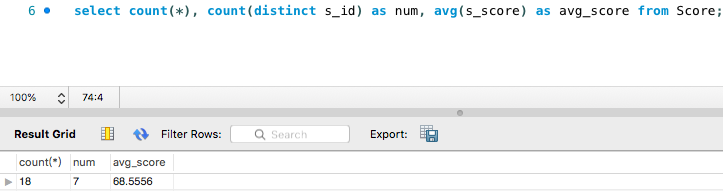
Sql进阶
分组计算
创建分组
- 使用grouo by关键词: select col1, count(*) from table group by col1
- GROUP BY 子句可以包含任意数量的列
- 对指定的分组列一起计算
- SELECT检索的列必须是group by的列
- null值将作为单独一组
过滤分组
- 使用having关键字,规定包含与排除哪些分组:select col1, count() from table group by col1 having count() > 10
- 与where的区别在于:where作用于行,having作用于组
- where在数据分组前过滤,having在数据分组后过滤。where过滤排除的行不在分组中
分组与排序
- 使用order by可以对 组进行排序:select col1, count() as num from table group by col1 having count() > 10 order by num
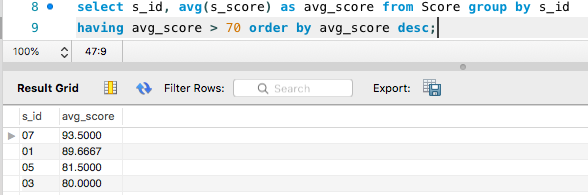
如上图所示:查询平均成绩在70分以上的学生,并将结果按平均分倒叙排列
Tips
- 当数据量特别大时,使用group by获取不同的列名比使用distinct要快哦
- 需要记住的子句顺序:where > group by > having > order by
- having和order by子句是可以直接使用查询列的别名的
子查询
子查询(subquery):嵌套在其它查询中的查询
利用子查询进行过滤:
作为where关键词的字句,进行数据过滤
select col1, col2 from table1 where col3 in (select col from table2)
作为计算字段使用子查询:
在select关键字之后使用,作为结果字段
select col1, col2, (select col1 from table2 where table1.col = table2.col) as col3 from table1
表联结
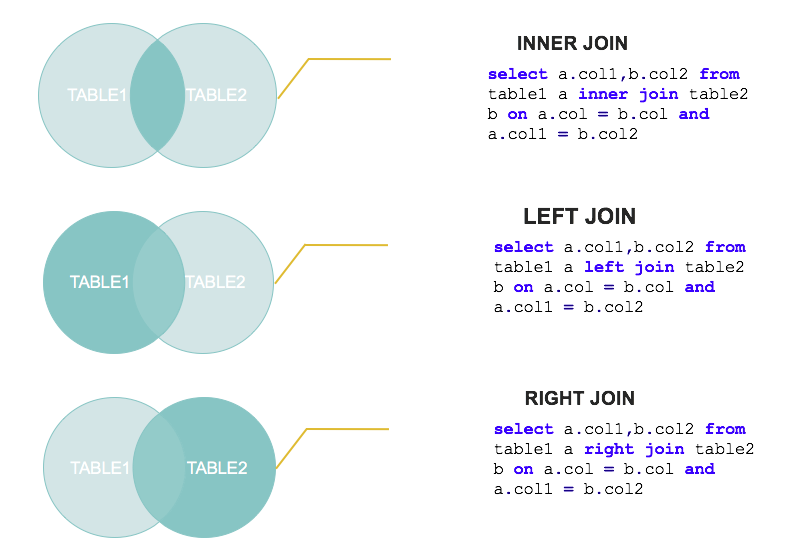
有时候,我们会见到如下的写法
select * from Teacher a, Teacher b;
select * from Teacher a join Teacher b;
select * from Teacher a inner join Teacher b;
此时输出的结果为表a和表b的笛卡尔积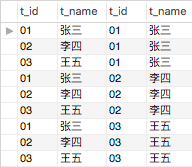
这说明了from table1, table2 其实就是内连接;join不强调left或right时也是内连接;这两种情况都属于是inner join。通常来说,我们应该避免产生笛卡尔积的查询结果,请在后面添加where条件,并尽可能使用到索引
组合查询
组合查询就类似于堆积木,但每个积木的大小(列数),颜色(数值类型)要一样
UNION规则
- UNION必须由两条或者两条以上select语句组成
- 每个子句都必须包含相同数的列、聚合函数等
- 列数据类型必须兼容
使用UNION
- 在各条select语句之间加上union关键字
- 注意:union 会自动对结果进行去重;而union all则不会
案例
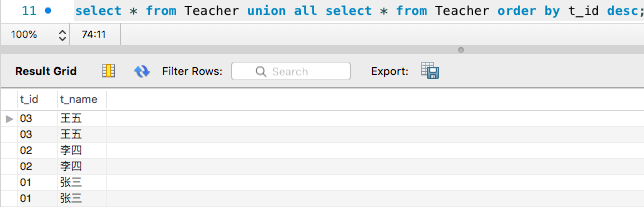
表的创建
创建表
- 新建表的名字
- 表列的名字与定义,逗号隔开
CREATE TABLE table1 (
id int NOT NULL AUTO_INCREMENT,
col1 int NOT NULl,
col2 char(20) NULL,
PRIMARY KEY(id) );
NULL值与默认值
- NULL值就是没有或者缺值
- NULL值不是空串
- 允许NULL值的列允许在插入行时不给出该列的值
- 不允许NULL值的列在插入时必须给出该列的值
- 创建表时可以指定默认值
- 插入该列没有指定值时,就使用默认值
CREATE TABLE table1 (
id int NOT NULL AUTO_INCREMENT,
col1 int NOT NULl DEFAULT 1,
col2 char(20) NULL,
PRIMARY KEY(id) );
主键
- 主键的值必须唯一
- 如果使用多列作为主键,那么组合值必须唯一
- 主键不允许有NULL值
CREATE TABLE table1 (
id int NOT NULL AUTO_INCREMENT,
sub_id int NOT NULL,
col1 int NOT NULl,
col2 char(20) NULL,
PRIMARY KEY(id,sub_id) );
AUTO_INCREMENT
- 每个表只允许一个AUO_INCREMENT列,而且必须被索引
- 在使用insert增加一行时,该列自动增量
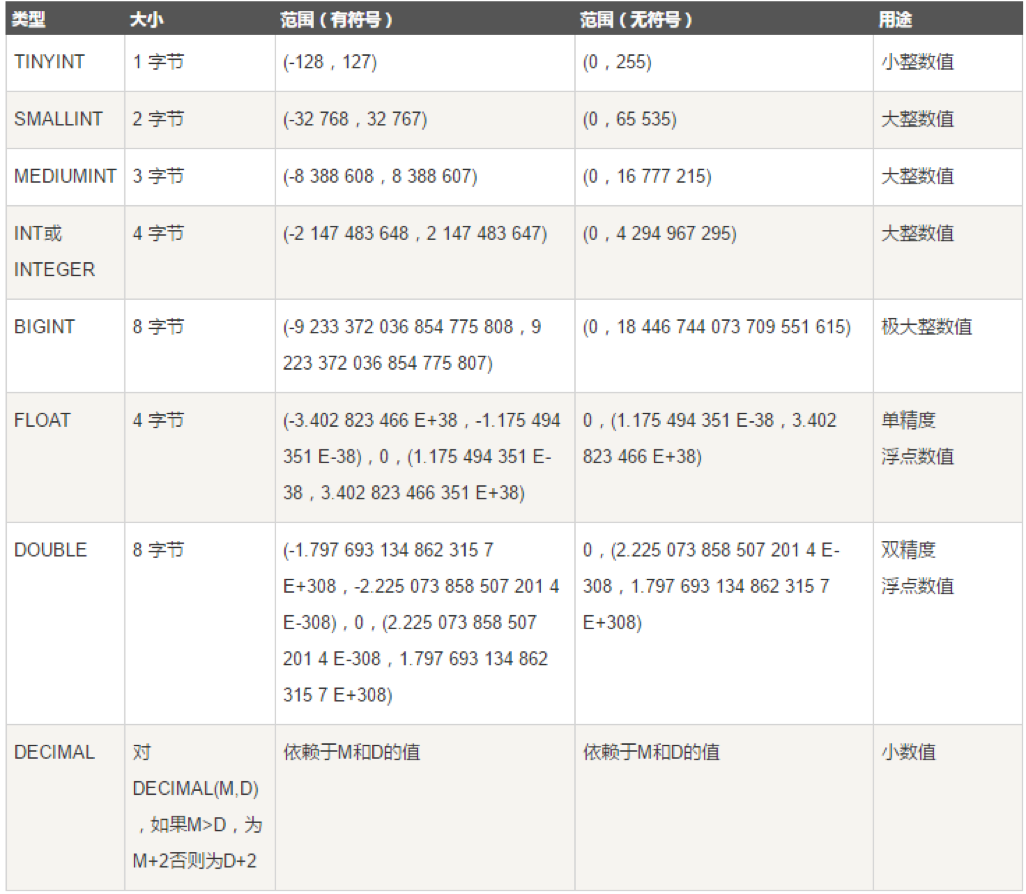
数据类型
数字类型的数据类型如下:
日期类型的数据类型如下:
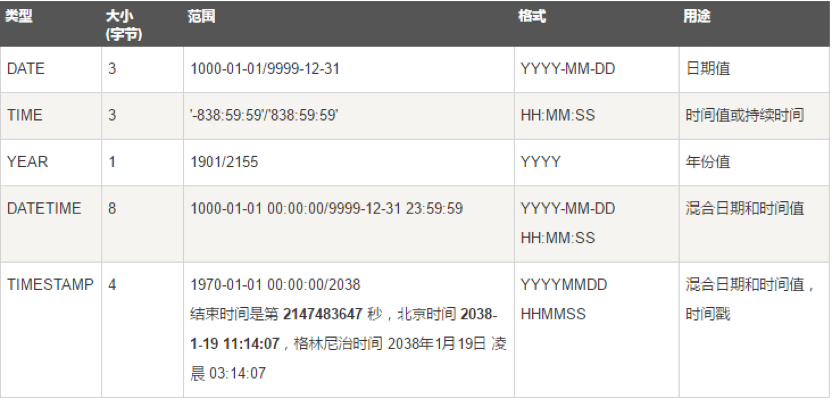
字符串类型的数据类型如下:
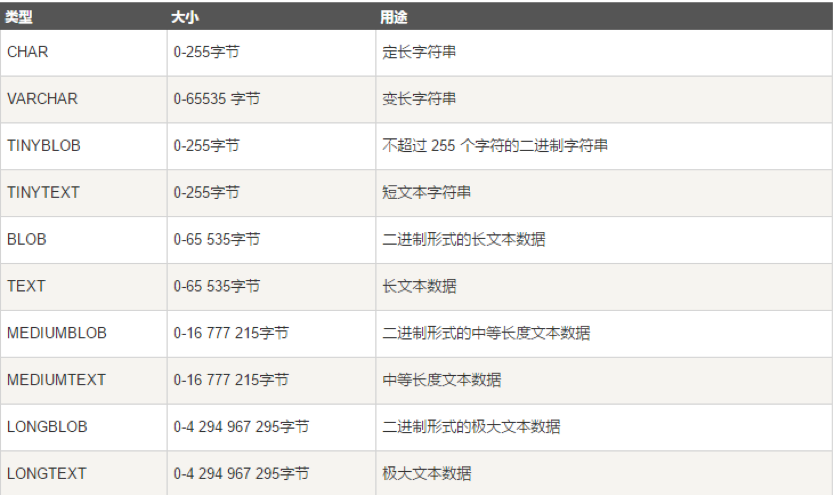
插入数据
插入完整的行
INSERT INTO TABLE1(COL1,COL2,COL3) VALUES(VALUE1,VALUE2,VALUE3);
插入多个行
INSERT INTO TABLE1(COL1,COL2,COL3) VALUES(VALUE1,VALUE2,VALUE3),(VALUE1_,VALUE2_,VALUE3_);
插入检索出的数据
INSERT INTO TABLE1(COL1,COL2,COL3) SELECT COL1,COL2,COL3 FROM TABLE1
Mysql并不关心列的名字,仅关心列的位置,只要顺序对应就可以
表的操作
更新表
ALTER TABLE table1 ADD col INT;
ALTER TABLE table1 DROP COLUMN col;
- 尽可能避免使用alter table,在表设计之初就应该尽可能考虑周全
- 在更改表之前,应该先对表数据做一次备份,以防出错
删除表
DROP TABLE table1;
重新命名表
RENAME TABLE table1 to table2;
更新和删除数据
更新数据(关键字update)
UPDATE table1 SET col1 = value1, col2 = value2
WHERE condition
- 不要省略where字段,否则会更新表中全部的值
删除数据(关键字delete)
DELETE FROM table1
WHERE condition
- 不要省略where字段,否则会删除表中全部的值
一些原则
- Mysql数据库是没有撤销按钮的,所以一定要仔细注意自己的操作
- 一定要使用where子句,除非确认更改每一行
- 在使用UPDATE与DELETE之前,应该先使用SELECT进行测试
Sql执行顺序
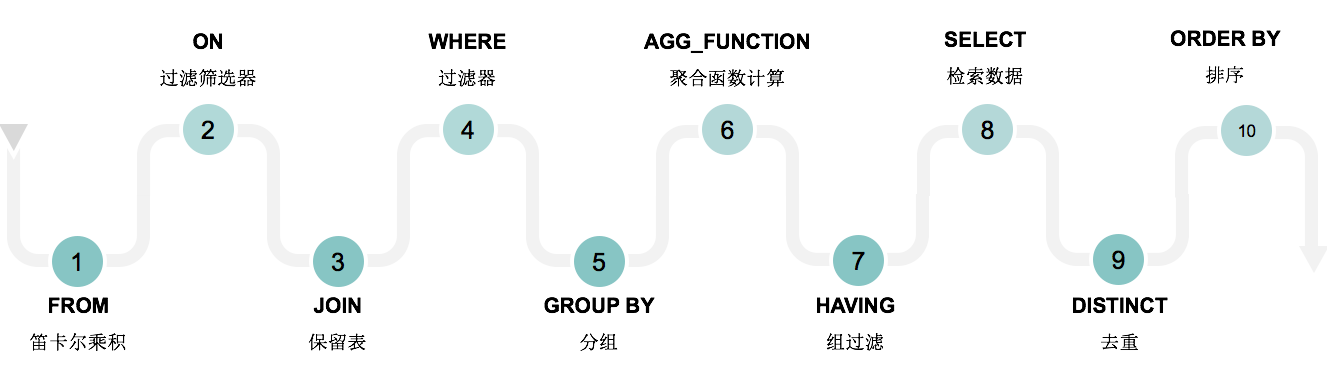
补充
- 上图中的聚合函数是针对每个group执行的
- 如果包含子查询,那么子查询是优于from先执行的
- order by操作后面还可以放limit操作

若有收获,就点个赞吧
0 人点赞
