- 前言
- printf ☆
- putchar
- scanf ☆
- getchar
- rand、srand ☆
- strlen ☆
- strcpy ☆
- strncpy ☆
- strcat ☆
- strncat ☆
- strcmp ☆
gets- fgets
- time ☆
- gmtime
- time_t ☆
- ctime
- calloc ☆
- qsort
- malloc ☆
- free ☆
- exit
- sprintf ☆
- isdigit
- isalpha
- std::vector ☆
- auto ☆
- std::string ☆
- ifstream ☆
- std::stringstream ☆
- 文件 IO | 对比 C 的 FILE 风格和 C++ 的 ifstream 风格
- demo | 读取文件每一行的内容
- std::pair ☆
- std::make_pair ☆
- std::partial_sort ☆
- std::greater ☆
- std::thread ☆
- std::shared_ptr ☆
- std::to_string ☆
前言
C/C++ 内置的数据结构和工具函数通常称为标准库(Standard Library)的组成部分。
- C++ 标准库包括 STL(Standard Template Library,标准模板库),提供了诸如 vector、list、map 等常用容器和算法。
- C 标准库提供了一系列基本的输入输出、字符串处理、内存管理等函数,如 putchar、getchar 和 strcpy 等。
学习 Standard Library 对于学习 C/C++ 非常重要。标准库提供了许多实用的数据结构、算法和函数,它们为编程任务提供了基本的构建模块。熟练掌握标准库可以帮助你提高编程效率,避免重复发明轮子,并编写出更加简洁、易读和高效的代码。
C++ 标准库(包括 STL)为程序员提供了一系列高度优化的容器和算法,使得在许多情况下,程序员无需自行实现复杂的数据结构,可以直接利用现有的库进行高效开发。C 标准库虽然相对简单,但它为基本输入输出、字符串处理、内存管理等提供了必要的支持。
掌握 Standard Library 的使用,可以帮助你更好地理解 C/C++ 语言的特性和编程范式,以及如何有效地解决实际问题。
在 Standard Library 这一系列文档中,将记录学习过程中接触到的所有“标准库函数”、“标准库组件”。
printf ☆
- printf 是一个定义在 stdio.h 头文件中的 C 标准库函数,用于将格式化的输出写入到 stdout(通常是控制台)。它的主要特点和用途是在控制台上显示格式化的文本,可以方便地组合字符串、数字和其他数据类型进行输出。
- 函数签名:
int printf(const char *format, ...); - 输入:
format:一个以 null 结尾的字符串,包含文本和格式说明符(以 % 开头的占位符)- 格式化字符串:以 % 开头的字符表示占位符,具体形式:
%[flags][width][.precision][length]specifier - 格式化参数:flags、width、.precision、length 和 specifier 都是格式化参数,用于指定输出格式
- 格式化字符串:以 % 开头的字符表示占位符,具体形式:
...:表示可变数量的参数,与格式说明符一一对应
- 返回值:
- printf 函数返回成功写入到输出流的字符数。
- 如果发生错误,则返回负值。
- 应用场景:
- 在控制台上显示格式化的文本。
- 方便地组合字符串、数字和其他数据类型进行输出。
- 常用的格式化参数:
- %d、%i:用于输出十进制整数。
- %f:用于输出浮点数。
- %s:用于输出字符串。
- %c:用于输出字符。
- %p:用于输出指针的地址。
- %u:用于输出无符号整数。
- %o:用于输出八进制整数。
- %x、%X:用于输出十六进制整数。
- %e、%E:用于输出科学计数法表示的浮点数。
- %g、%G:用于输出浮点数,具体格式取决于数值的大小。
#include <stdio.h>int main() {int age = 25;double height = 1.75;const char *name = "Tom";printf("Name: %s, Age: %d, Height: %.2f meters\n", name, age, height); // => Name: Tom, Age: 25, Height: 1.75 metersreturn 0;}
#include <stdio.h>int main() {// 1. 字段宽度int i = 123;printf("[%6d]\n", i); // => [ 123]printf("[%06d]\n", i); // => [000123]// 2. 负号float x = 1234.567;printf("[%9.3f]\n", x); // => [ 1234.567]printf("[%-9.3f]\n", x); // => [1234.567 ]// 3. 字符*printf("[%*d]\n", 5, i); // => [ 123]int w = 6;printf("[%*d]\n", w, i); // => [ 123]printf("[%-*.*f]\n", 7, 2, x); // => [1234.57]return 0;}
#include <stdio.h>int main() {// 使用转义字符控制输出格式int m = 3, n = 12;printf("num1 = %d \t num2 = %d\n", m, n); // => num1 = 3 num2 = 12// 打印百分号printf("%f%%\n", 95.6); // => 95.600000%return 0;}
注意事项:
- 格式说明符必须与参数的类型和顺序匹配。否则,输出可能是不可预测的,并可能导致程序崩溃。
- 要确保
format字符串中的占位符数量与传递的参数数量相匹配。 - 如果要在字符串中插入
%字符,请使用%%。 - 使用 printf 时要注意防止缓冲区溢出和字符串格式化漏洞。在 C++ 中,推荐使用
iostream和std::cout进行输出操作,以减少潜在的安全风险。
putchar
- putchar 是一个定义在
<stdio.h>头文件中的 C 标准库函数,用于将一个字符写入 stdout(通常是控制台)。它的主要特点和用途是在控制台上逐个字符地显示文本。 - 函数签名:
int putchar(int c); - 输入:
c:要写入 stdout 的字符。虽然参数类型为 int,但只使用该整数的低 8 位表示字符。
- 返回值:
- putchar 函数返回写入的字符的 ASCII 码值
- 如果发生错误,则返回 EOF(通常是 -1)
- 应用场景:
- 在控制台上逐个字符地显示文本。
- 逐个处理字符串中的字符并进行输出。
- 注意事项:
- 当使用 putchar 时,输出不会自动换行。如有需要,请在适当的位置手动添加换行符
\n - 若要输出整数或其他非字符数据类型,请使用其他输出函数,如 puts 和 printf 等
- 在 C++ 中,您可以使用 std::cout 和 std::ostream::put 函数实现类似功能
- 当使用 putchar 时,输出不会自动换行。如有需要,请在适当的位置手动添加换行符
#include <stdio.h>int main() {const char *text = "Hello, World!";for (int i = 0; text[i] != '\0'; i++) {putchar(text[i]); // => Hello, World!}putchar('\n');return 0;}
#include <stdio.h>int main() {putchar('A');putchar(97);putchar(65);char c = '!';putchar(c);return 0;}// AaA!
思考:putchar 函数的参数为什么设计为 int 类型?
putchar 函数的参数类型为 int,是为了确保该函数能够处理字符的所有可能值。
- 范围问题:在 ASCII 字符集中,字符由 7 位表示,而第 8 位通常用于错误检测或语言特定的字符。通过使用 int 参数,该函数可以处理超出 char 范围的值,包括可能用于错误检测的负值。
- 符号问题:使用 int 而不是 char 可以帮助防止在输出字符时发生符号问题。根据编译器和平台的不同,char 类型可能被视为有符号或无符号,如果输出了一个大的字符值并且 char 类型被解释为有符号,则可能导致意外行为。通过使用 int 参数,可以避免这种潜在问题。
scanf ☆
- scanf 是一个定义在
stdio.h头文件中的 C 标准库函数,用于从 stdin(通常是控制台)读取格式化的输入。它的主要特点和用途是读取用户输入的数据,并将其存储到指定的变量中。 - 函数签名:
int scanf(const char* format, ...); - 输入:
format:格式字符串,用于指定输入数据的格式和类型。格式说明符(如 %d、%s 等)表示要读取的数据类型。...:变长参数列表,表示指向接收输入数据的变量的指针。
- 返回值:
- scanf 函数返回成功读取并赋值的变量数量。
- 如果发生错误或遇到文件结束(EOF),则返回 EOF(通常是 -1)。
- 应用场景:
- 从控制台读取用户输入的数据。
- 根据预定义的格式读取输入数据。
- 注意事项:
- 读取数据时,需要输入与指定格式相符的数据,否则会发生错误。
- 确保在格式字符串中使用正确的格式说明符,以匹配要读取的数据类型。否则,可能导致未定义行为。
- 传递给 scanf 的变量应为指针,因为函数需要将读取到的数据存储到指定的内存地址。
- 不能读取超过指定长度的字符串,否则会发生缓冲区溢出。
- 当读取字符串时,请确保为接收字符串的字符数组分配足够的空间,以避免缓冲区溢出。
- 在 C++ 中,您可以使用 std::cin 和 std::istream 函数实现类似功能。
- 在读取数据时会自动忽略空格、换行符等空白字符,但在格式字符串中使用空白字符时会强制要求输入中出现空白字符,否则会读取失败。
- scanf() 函数读取数据时遇到非法字符会停止读取,并将其放回输入流中,需要使用 getchar() 函数将其读取并丢弃。
#include <stdio.h>int main() {int age;float height;printf("请输入你的年龄:");scanf("%d", &age);printf("请输入你的身高(m):");scanf("%f", &height);printf("你的年龄是 %d 你的身高是 %.2f m\n", age, height);return 0;}/* 运行结果:请输入你的年龄:10请输入你的身高(m):1你的年龄是 10 你的身高是 1.00 m */
#include <stdio.h>int main() {int i, j;scanf("%d%d", &i, &j);printf("i = %d\tj = %d\n", i, j);scanf("%*d%d", &i, &j); // => warning: data argument not used by format string [-Wformat-extra-args]// scanf("%*d%d", &i);printf("i = %d\tj = %d\n", i, j);return 0;}
警告分析:warning: data argument not used by format string [-Wformat-extra-args]scanf("%*d%d", &i, &j); 等效写法 scanf("%*d%d", &i);
这个警告就是在提示我们,我们写得 &j 多余了,在输入时会跳过它

#include <stdio.h>int main() {int i, j;char ch;scanf("%d%d%c", &i, &j, &ch);printf("i = %d\tj = %d\tch = %c\n", i, j, ch);return 0;}
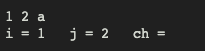
#include <stdio.h>int main() {int i, j;char ch;scanf("%d%d %c", &i, &j, &ch);printf("i = %d\tj = %d\tch = %c\n", i, j, ch);return 0;}

#include <stdio.h>int main() {int i, j;char ch;scanf("%d,%d,%c", &i, &j, &ch);printf("i = %d\tj = %d\tch = %c\n", i, j, ch);return 0;}
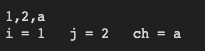
getchar
- getchar 是一个定义在
<stdio.h>头文件中的 C 标准库函数。 - 函数签名:
int getchar(void); - 输入:无
- 输出:从输入流(通常是标准输入,如键盘)读取的一个字符。
- 返回值:
- getchar 函数读取用户在标准输入设备上输入的字符,然后将字符转换为整数形式返回,即返回其 ASCII 码值(int 类型)
- 如果遇到文件结束(EOF)或发生错误,则返回 EOF
- 应用场景:
- 从标准输入(如键盘)读取单个字符
- 在循环中逐个读取输入字符,直到遇到文件结束(EOF)
- 注意事项:
- 当 getchar 遇到文件结束(EOF)时,它会返回 EOF 常量。您可以使用 feof 函数检查输入流是否已到达文件末尾。
- getchar 读取的字符包括换行符,所以如果你在输入中有换行符,它也会被读取。如果需要忽略换行符,可以使用条件语句来处理。
- getchar 函数会将输入的字符缓存起来,如果程序中有多次使用 getchar 函数,缓存中的字符将依次被读取
- 如果读取的字符是回车符 \n,那么表示一行的输入结束,getchar 函数将读取并返回回车符
- 如果读取的字符是文件结束符 EOF(End Of File,即 Ctrl+Z 或 Ctrl+D),那么表示输入结束,getchar 函数将返回 EOF,该值是一个负整数
#include <stdio.h>int main() {printf("请输入一个字符:");int ch = getchar();printf("您输入的字符是:%c\n", ch);return 0;}/* 运行结果:请输入一个字符:123您输入的字符是:1请输入一个字符:abc您输入的字符是:a*/
#include <stdio.h>int main() {char c;int c1, c2;c = getchar();c1 = c - 1; c2 = c + 1;printf("%c\t%c\t%c\n", c1, c, c2);printf("%d\t%d\t%d\n", c1, c, c2);return 0;}/* 运行结果:BA B C65 66 67 */
rand、srand ☆
rand:
- rand 是一个定义在 stdlib.h 头文件中的 C 标准库函数,用于生成的一个 伪随机整数。
- 函数签名:
int rand(void); - 输入:无
- 返回值:返回一个在 0 到
RAND_MAX(通常是 32767)之间的伪随机整数。 - 应用场景:
- 生成伪随机整数,用于测试、模拟和游戏等场景。
- 结合数学运算生成指定范围内的随机数。
- 伪随机数:
- 计算机程序生成的看似随机的数,其实是基于确定的 算法 和 种子值 生成的,而非真正的随机数
- 伪随机数的值是由随机数生成器的 算法 和 初始种子值 共同决定的。随机数生成器的算法是确定的,只要初始种子值一样,生成的随机数序列也是一样的。
srand:
- srand 是一个定义在
<stdlib.h>头文件中的 C 标准库函数,用于设置随机数种子。 - 函数签名:
void srand(unsigned int seed); - 输入:
seed一个无符号整数,用于设置随机数生成器的初始值(随机数种子)。 - 返回值:无
- 应用场景:
- 初始化伪随机数生成器,以产生不同的随机数序列。
- 在使用 rand 函数之前调用,以避免生成相同的随机数序列。
#include <stdio.h>#include <stdlib.h>#include <time.h>int main() {srand(time(NULL)); // 使用当前时间作为随机数种子printf("生成 0 到 99 之间的随机数:");int random_num = rand() % 100;printf("%d\n", random_num); // => 生成 0 到 99 之间的随机数:70return 0;}/* notes:srand(time(NULL));这条语句的作用:确保 rand() 生成的是一个真随机数而非伪随机数 */
srand(time(NULL)); // 使用当前时间作为种子值int randomNumber = rand(); // 生成伪随机数
srand(time(NULL));
srand(time(NULL))作用是 初始化随机数生成器的种子,使每次生成的随机数序列不同time(NULL)函数返回的是一个时间戳,因为当前时间是一直变化的,用它来作为 srand 函数的种子参数是比较合适的- 每次调用 rand() 获取随机数之前,调用一下
srand(time(NULL))即可确保每次运行程序时都会得到不同的随机数序列,以得到一个“真随机数”
srand((unsigned)time(NULL)); // 使用当前时间作为种子值int randomNumber = rand(); // 生成伪随机数
srand((unsigned)time(NULL));
- time(NULL) 函数返回的是 time_t 类型的值,而不是 unsigned 类型
(unsigned)time(NULL)这种写法相当于对 time 函数的返回值的类型做了一个强制类型转换,将其强制转换为 unsigned 类型srand((unsigned)time(NULL));这么做是为了 将 time_t 类型的时间值转换成一个适合作为随机数种子的无符号整数
问:类型 time_t 和类型 unsigned 之间的差异? time_t 类型和 unsigned 类型是两种不同的数据类型,虽然它们 都可以表示非负整数,但它们的 语义和用法不同。
time_t类型是一个表示时间的整数类型,通常被用来表示从某个特定时间点起到现在所经过的秒数,例如time(NULL)返回的就是当前时间距离 Unix 时间戳起点(1970 年 1 月 1 日 0 时 0 分 0 秒)的秒数。unsigned类型则是一个不带符号的整数类型,可以表示从 0 开始的任意非负整数。它通常被用于计算机的位运算和计算机内存地址等场景中。
注意事项:
- rand 函数生成的是伪随机数,而不是真正的随机数。它们是基于一个初始值(称为随机数种子)计算得出的。如果使用相同的种子,rand 函数将生成相同的随机数序列。
- 如果未调用 srand 函数,rand 函数将使用默认的随机数种子(通常为 1),这将导致每次运行程序时生成相同的随机数序列。
- 为了生成不同的随机数序列,需要使用 srand 函数设置一个不同的随机数种子。通常情况下,我们使用当前时间(通过 time 函数获取)作为种子,因为时间是一个不断变化的值。
- 只需在程序开始时调用一次 srand 即可,不需要在每次调用 rand 之前都调用它。反复设置随机数种子可能导致生成的随机数序列有规律,从而降低随机性。
- rand 函数生成的随机数是均匀分布的,但如果需要生成其他分布(如正态分布)的随机数,需要使用其他方法。
- srand 函数可以接受一个整数参数,用于设置随机数的种子
- 生成随机性更高的随机数:为了生成更为随机的伪随机数,需要不断改变种子值。
问:srand 的调用次数到底是应该调用一次呢?还是多次呢?
问题描述:
有关 srand 的使用,这两种说法是否矛盾,一个说只用调用一次,一个说需要调用多次,哪种说法才是正确的呢?
- 说法 1:只需在程序开始时调用一次 srand 即可,不需要在每次调用 rand 之前都调用它。反复设置随机数种子可能导致生成的随机数序列有规律,从而降低随机性。
- 说法 2:为了生成更为随机的伪随机数,需要不断改变种子值。
参考回复:两种说法都没错,它们各自适用于不同的场景。
在大多数情况下,说法 1 更为常见。通常,只需在程序开始时调用一次 srand 即可,不需要在每次调用 rand 之前都调用它。因为在同一个种子值下,rand 函数会生成相同的随机数序列,只要在程序开始时设置一次种子,后续的 rand 调用就会生成不同的随机数。反复设置随机数种子可能导致生成的随机数序列有规律,从而降低随机性。
然而,在某些特殊场景下,说法 2 也有一定的道理。为了生成更为随机的伪随机数,可以在程序运行过程中适当改变种子值。但这种做法需要谨慎使用,否则可能导致随机数的生成变得有规律。这种情况通常适用于对随机性要求较高的场景,例如 密码学应用。在这类应用中,可以使用更高质量的随机数生成器,如 C++11 提供的
小结:
- 在大多数情况下,遵循说法 1,在程序开始时调用一次 srand 即可
- 在特殊场景下,可以考虑适当改变种子值,以提高随机性
strlen ☆
- strlen 是一个定义在
<cstring>(C++)或<string.h>(C)头文件中的 C 标准库函数。 - 函数签名:
size_t strlen(const char* str); - 输入:
str指向以空字符'\0'结尾的 C 风格字符串的指针 - 返回值:返回字符串 str 的长度(不包括空字符)
- 应用场景:
- 计算 C 风格字符串的长度。
- 在处理字符串时,确定循环的次数或者数组的大小。
- 注意事项:
- 传递给 strlen 的字符串必须以空字符
'\0'结尾,否则 strlen 无法确定字符串的长度,可能导致未定义行为。 - strlen 返回的长度是以字节为单位的,而不是字符数。在处理多字节字符(如 UTF-8 编码的字符串)时,需要注意这个区别。
- 传递给 strlen 的字符串必须以空字符
#include <iostream>#include <cstring>int main() {const char* str = "Hello, World!";size_t length = strlen(str);std::cout << "字符串长度:" << length << std::endl; // => 字符串长度:13// printf("字符串长度: %zu\n", length);return 0;}
在上述程序中,以下这两种写法都是等效的
std::cout << "字符串长度:" << length << std::endl;printf("字符串长度: %zu\n", length);
strcpy ☆
- strcpy 是定义在
<cstring>(C++)或<string.h>(C)头文件中的 C 标准库函数。它用于 将源字符串复制到目标字符串。 - 函数签名:
char* strcpy(char* dest, const char* src); - 输入:
- dest:指向目标字符数组的指针,用于存储复制后的字符串。目标字符数组的大小必须足够大以容纳源字符串的副本(包括空字符)。
- src:指向源字符串的指针,该字符串将被复制到目标字符串中。
- 返回值:
- strcpy 函数返回指向目标字符串(即 dest)的指针。
- 应用场景:
- 将一个字符串复制到另一个字符串中。
- 初始化字符数组。
- 注意事项:
- 确保目标字符数组的大小足够大,以防止缓冲区溢出。
- 为了提高安全性,可以使用 strncpy 函数,它允许指定复制的最大字符数,避免缓冲区溢出。
#include <cstring>#include <iostream>int main() {const char* src = "Hello, World!";char dest[20];strcpy(dest, src);std::cout << "复制后的字符串:" << dest<< std::endl; // => 复制后的字符串:Hello, World!return 0;}
strncpy ☆
- strncpy 是定义在
<cstring>(C++)或<string.h>(C)头文件中的 C 标准库函数。它用于将源字符串的前 n 个字符复制到目标字符数组。 - 函数签名:
char* strncpy(char* dest, const char* src, size_t n); - 输入:
- dest:指向目标字符数组的指针,源字符串的前 n 个字符将被复制到这个字符数组。
- src:指向源字符串的指针。
- n:要从源字符串复制的最大字符数。
- 返回值:strncpy 函数返回指向目标字符数组(即 dest)的指针。
- 应用场景:
- 复制字符串,但限制复制的最大字符数。
- 在复制字符串时防止缓冲区溢出。
- 注意事项:
- 如果源字符串的长度小于 n,strncpy 将在目标字符串的末尾添加空字符,直到复制了 n 个字符。
- 如果源字符串的长度大于或等于 n,strncpy 不会在目标字符串末尾添加空字符。为了确保目标字符串以空字符结尾,可以手动添加空字符。
#include <iostream>#include <cstring>int main() {char dest[10];const char* src = "Hello, World!";strncpy(dest, src, sizeof(dest) - 1); // 留出空间放置空字符dest[sizeof(dest) - 1] = '\0'; // 手动添加空字符std::cout << "复制后的字符串:" << dest << std::endl; // => 复制后的字符串:Hello, Woreturn 0;}
strcat ☆
- strcat 是定义在
<cstring>(C++)或<string.h>(C)头文件中的 C 标准库函数。它用于 将源字符串追加到目标字符串的末尾。 - 函数签名:
char* strcat(char* dest, const char* src); - 参数:
- dest:指向目标字符数组的指针,目标字符串后将追加源字符串。目标字符数组的大小必须足够大以容纳源字符串和目标字符串的合并(包括空字符)。
- src:指向源字符串的指针,该字符串将被追加到目标字符串的末尾。
返回值:
- 返回值:strcat 函数返回指向目标字符串(即 dest)的指针。
- 应用场景:
- 连接两个字符串。
- 将字符串添加到现有字符串的末尾。
- 注意事项:
- 确保目标字符数组的大小足够大,以防止缓冲区溢出。
- 为了提高安全性,可以使用 strncat 函数,它允许指定追加的最大字符数,避免缓冲区溢出。
#include <iostream>#include <cstring>int main() {char dest[30] = "Hello";const char* src = ", World!";strcat(dest, src);std::cout << "连接后的字符串:" << dest << std::endl; // => 连接后的字符串:Hello, World!return 0;}
strncat ☆
- strncat 是定义在
<cstring>(C++)或<string.h>(C)头文件中的 C 标准库函数。它用于 将源字符串的前 n 个字符附加到目标字符串的末尾。 - 函数签名:
char* strncat(char* dest, const char* src, size_t n); - 参数:
- dest:指向目标字符串的指针,源字符串的前 n 个字符将被附加到这个字符串的末尾。
- src:指向源字符串的指针。
- n:要从源字符串附加的最大字符数。
- 返回值:strncat 函数返回指向目标字符串(即 dest)的指针。
- 应用场景:
- 附加字符串,但限制附加的最大字符数。
- 在连接字符串时防止缓冲区溢出。
- 注意事项:
- strncat 不会检查目标字符串是否有足够的空间容纳附加的字符。为了防止缓冲区溢出,请确保目标字符串有足够的空间容纳附加的字符。
- 如果源字符串的长度小于 n,strncat 将附加整个源字符串。如果源字符串的长度大于或等于 n,strncat 仅附加前 n 个字符。在任何情况下,strncat 都会在目标字符串末尾添加空字符。
#include <iostream>#include <cstring>int main() {char dest[15] = "Hello";const char* src = "World!";strncat(dest, src, sizeof(dest) - strlen(dest) - 1); // 限制附加字符数,留出空间放置空字符std::cout << "连接后的字符串:" << dest << std::endl; // => 连接后的字符串:HelloWorld!return 0;}
#include <iostream>#include <cstring>int main() {char dest[10] = "Hello";const char* src = "World!";strncat(dest, src, sizeof(dest) - strlen(dest) - 1);std::cout << "连接后的字符串:" << dest << std::endl; // => 连接后的字符串:HelloWorlreturn 0;}
sizeof(dest) - strlen(dest) - 1 限制附加字符数,留出空间放置空字符
sizeof(dest)返回 dest 数组在内存中的 总字节数,即 15(一共能装多少)strlen(dest)返回 dest 数组中的 字符串长度,即 5(目前已经装了多少)sizeof(dest) - strlen(dest)表示还剩多少空间可用1表示留给空字符的字节数是 1,目的是为了防止 dest 数组溢出缓冲区
strcmp ☆
- strcmp 是定义在
<cstring>(C++)或<string.h>(C)头文件中的 C 标准库函数。它用于 比较两个字符串,并根据它们的字典顺序返回比较结果。 - 函数签名:
int strcmp(const char* s1, const char* s2); - 参数:
- s1:指向第一个字符串的指针。
- s2:指向第二个字符串的指针。
- 返回值:
- 如果 s1 和 s2 相等(即它们的字符顺序相同),则返回 0。
- 如果 s1 字典顺序小于 s2,则返回负整数。
- 如果 s1 字典顺序大于 s2,则返回正整数。
- 应用场景:
- 比较两个字符串是否相等。
- 对字符串进行字典顺序排序。
- 注意事项:
- strcmp 函数比较字符串时,是逐个字符进行比较,一旦遇到第一个不同的字符,就会返回比较结果。如果字符串中包含空字符(’\0’),strcmp 会在遇到空字符时停止比较。
- strcmp 会区分字符的大小写。如果需要进行大小写不敏感的字符串比较,可以使用 strcasecmp(Linux/Unix)或 _stricmp(Windows)等函数。
#include <stdio.h>#include <string.h>int main() {const char* str1 = "Apple";const char* str2 = "Banana";const char* str3 = "Apple";const char* str4 = "Apricot";int result = strcmp(str1, str2);printf("比较 str1 和 str2,得到的结果是:%d\n", result);if (result < 0) printf("前者小于后者\n");else if (result > 0) printf("前者大于后者\n");else printf("两者相等\n");result = strcmp(str1, str3);printf("比较 str1 和 str3,得到的结果是:%d\n", result);if (result < 0) printf("前者小于后者\n");else if (result > 0) printf("前者大于后者\n");else printf("两者相等\n");result = strcmp(str4, str1);printf("比较 str4 和 str1,得到的结果是:%d\n", result);if (result < 0) printf("前者小于后者\n");else if (result > 0) printf("前者大于后者\n");else printf("两者相等\n");return 0;}/* 运行结果:比较 str1 和 str2,得到的结果是:-1前者小于后者比较 str1 和 str3,得到的结果是:0两者相等比较 str4 和 str1,得到的结果是:2前者大于后者 */
strcmp 的比较机制:这里的大小比较是基于字符串的字典序,也就是按照 ASCII 码表顺序进行比较。比较的方式是从字符串的第一个字符开始,逐一比较对应的字符:
- 如果有不同的字符,则返回它们的 ASCII 码之差(即按照 ASCII 码表顺序比较)
- 如果字符串长度不同,则会在较短的字符串结束时返回它们的长度之差
gets
gets是一个定义在<stdio.h>头文件中的 C 标准库函数,用于从标准输入(通常是键盘)读取一行文本,并将其存储在指定的字符数组中。- 函数签名:
char* gets(char* s); - 参数:
- s:指向字符数组的指针,用于存储读取到的字符串。
- 返回值:
- 如果成功读取一行文本,函数返回指向字符数组(即输入参数 s)的指针。
- 如果遇到文件结束(EOF)或发生错误,函数返回 NULL。
- 应用场景:
- 从键盘或其他标准输入设备读取一行文本。
- 注意事项:
**gets**函数已被废弃,因为它存在缓冲区溢出的风险。gets不检查目标字符数组的大小,因此可能导致读取过长的行时覆盖数组边界之外的内存。建议使用fgets函数代替gets,因为fgets允许指定最大读取字符数,从而避免缓冲区溢出的风险。
#include <stdio.h>#include <stdlib.h>int main() {char buffer[100];printf("请输入一行文本:");if (gets(buffer) != NULL) {printf("您输入的文本是:%s\n", buffer);} else {printf("发生错误或遇到文件结束符\n");}return 0;}
这个示例代码使用了 gets,但实际上不建议在新的项目中使用它。请考虑使用 fgets 代替。
#include <stdio.h>#include <stdlib.h>#include <string.h>int main() {char buffer[100];printf("请输入一行文本:");if (fgets(buffer, sizeof(buffer), stdin) != NULL) {// 用 strlen 函数去掉输入字符串的结尾换行符buffer[strlen(buffer) - 1] = '\0';printf("您输入的文本是:%s\n", buffer);} else {printf("发生错误或遇到文件结束符\n");}return 0;}/* 运行结果:请输入一行文本:Hello world.您输入的文本是:Hello world.*/
fgets
- fgets 是定义在
cstdiostdio.h头文件中的 C 标准库函数。 - 函数签名:
char* fgets(char* str, int count, FILE* stream); - 参数:
- str:指向字符数组的指针,用于存储从流中读取的字符串。
- count:要读取的字符数(包括空字符
'\0')。 - stream:指向 FILE 类型的指针,例如 stdin 或已打开的文件,表示要从中读取内容的文件流。
- 输出:str 将从输入流中读取的字符串存储在该字符数组中
- 返回值:
- 如果成功,返回指向 str 的指针
- 如果遇到文件结束或发生错误,返回 NULL
- 应用场景:
- 从文件或标准输入(stdin)中按行读取文本,特别是处理 C 风格的字符串
- 在读取文件时,逐行处理文件内容。
- 注意事项:
- fgets 会将换行符(’\n’)包含在返回的字符串中,因此在处理字符串时可能需要删除换行符。
- 为防止缓冲区溢出,请确保 count 不超过 str 指向的字符数组的大小。
- 如果读取的行长于 count - 1 个字符,fgets 只会读取 count - 1 个字符,并在末尾添加空字符。为确保正确读取长行,请检查是否读取了完整的行(如检查换行符是否存在)并进行相应处理。
- 当 fgets 遇到文件结束(EOF)时,它会设置文件流的 eofbit。您可以使用 feof 函数检查是否已到达文件末尾。
#include <stdio.h>#include <stdlib.h>#include <string.h>int main() {char buffer[100];printf("请输入一行文本:");if (fgets(buffer, sizeof(buffer), stdin) != NULL) {// 用 strlen 函数去掉输入字符串的结尾换行符buffer[strlen(buffer) - 1] = '\0';printf("您输入的文本是:%s\n", buffer);} else {printf("发生错误或遇到文件结束符\n");}return 0;}/* 运行结果:请输入一行文本:Hello world.您输入的文本是:Hello world.*/
#include <cstdio>int main() {const char* name = "test.txt";FILE* file = fopen(name, "r");if (!file) {perror("无法打开文件");return 1;}char buffer[256];int i = 0;while (fgets(buffer, sizeof(buffer), file)) {printf("读取到第 %d 行:%s", ++i, buffer);}printf("%s 文件一共有 %d 行内容", name, i);fclose(file);return 0;}

time ☆
- time 是定义在
ctime头文件中的 C 标准库函数。 - 函数签名:
time_t time(time_t* timer); - 参数
timer:指向 time_t 类型的指针,用于存储当前时间的秒数。如果传入 NULL,则不会存储时间值。 - 返回值:返回自纪元(1970 年 1 月 1 日 00:00:00 UTC)以来的秒数。如果获取时间失败,返回 -1。
- 应用场景:
- 获取当前时间戳
- 计算程序运行时间
- 设置随机数种子
- 与其他时间处理函数(如 localtime、gmtime、strftime 等)结合使用,以获取更详细的时间信息
- 注意事项:
- time_t 通常表示为长整型,但具体类型可能因编译器和平台而异。在比较或输出 time_t 值时,请注意类型匹配和转换。
- 使用 time 函数设置随机数种子时,可以与 srand 函数结合使用:
srand(static_cast(time(NULL)))
#include <ctime>#include <iostream>int main() {time_t currentTime = time(NULL);if (currentTime == (time_t)-1) {std::cerr << "获取时间失败" << std::endl;return 1;}std::cout << "当前时间戳(秒):" << currentTime << std::endl; // => 当前时间戳(秒):1681800870return 0;}
gmtime
- gmtime 函数位于 time.h 头文件中
- 函数签名:
struct tm *gmtime(const time_t *timep); - 参数
timep:指向一个 time_t 类型的指针,表示要转换的时间值 - 返回值:gmtime 函数返回一个指向 tm 结构体的指针
- 注意事项:
- gmtime 函数将 time_t 结构体指针指向的时间值解释为格林威治标准时间下的时间,即不考虑时区的影响。
- 在使用 gmtime 函数时,需要注意 time_t 类型的时间值可能会溢出。
- 如果需要将一个本地时间转换为 GMT 时间,应该使用 localtime 函数。
#include <stdio.h>#include <time.h>int main() {time_t now = time(NULL); // 获取当前时间struct tm* gmt = gmtime(&now); // 将当前时间转换为 GMT 时间// 输出 GMT 时间信息printf("GMT Time: %04d-%02d-%02d %02d:%02d:%02d\n", gmt->tm_year + 1900,gmt->tm_mon + 1, gmt->tm_mday, gmt->tm_hour, gmt->tm_min,gmt->tm_sec);return 0;}
time_t ☆
- 在 C 语言标准库中,time_t 是一种数据类型,定义在 time.h 头文件中,用于表示从某个特定时间点(通常是1970年1月1日00:00:00 UTC)起经过的秒数。
- time_t 类型通常用于存储当前时间或者计算时间间隔。
- time_t 类型被很多其他的标准库函数(如 time、mktime、difftime 等)所使用。
- time_t 类型在不同的操作系统和编译器中可能会有所不同,包括其精度和取值范围等方面。在一些平台上,time_t 类型可能是一个整数类型,而在另一些平台上可能是一个结构体类型。因此,在使用 time_t 类型时,需要根据具体的平台和编译器来进行处理。
- time_t 类型只能表示到 秒级别的时间精度,对于更高精度的时间表示(如毫秒、微秒、纳秒等),需要使用特殊的库或者扩展数据类型来处理。
- 如果使用 C 语言中的 printf 来打印 time_t 类型的数据,那么应该使用
%ld作为格式控制字符。
#include <stdio.h>#include <time.h>int main() {time_t now = time(NULL); // 获取当前时间printf("Current timestamp: %ld\n", now); // 输出时间戳return 0;}/* 运行结果:Current timestamp: 1681801765 */
ctime
#include <stdio.h>#include <time.h>int main() {time_t now = time(NULL); // 获取当前时间char* str = ctime(&now); // 将当前时间转换为字符串printf("Current time: %s\n", str); // 输出字符串格式的时间return 0;}/* 运行结果:Current time: Tue Apr 18 07:07:17 2023 */
calloc ☆
calloc 是定义在 <stdlib.h> 头文件中的 C 标准库函数,用于在内存中分配一块连续的空间并初始化为零。
函数签名:void* calloc(size_t num, size_t size);
输入:
num:需要分配的元素个数。size:每个元素的大小(以字节为单位)。
返回值:
- 如果分配成功,则返回指向分配内存区域的指针;
- 如果分配失败,则返回空指针(NULL)。
以下是一个使用 calloc 函数分配并初始化内存空间的示例代码:
#include <stdio.h>#include <stdlib.h>int main() {int* ptr;int n = 5;// 分配内存空间ptr = (int*) calloc(n, sizeof(int));if (ptr == NULL) {printf("内存分配失败。\n");exit(1);}// 初始化内存空间for (int i = 0; i < n; i++) {ptr[i] = i + 1;}// 打印内存空间中的值for (int i = 0; i < n; i++) {printf("%d ", ptr[i]);}// 释放内存空间free(ptr);return 0;}
在上面的示例代码中,calloc 函数将为 n 个 int 类型的元素分配内存空间,并将每个元素初始化为零。然后,程序使用循环语句初始化内存空间中的值,再打印出每个元素的值。最后,需要使用 free 函数释放分配的内存空间。
注意事项:
calloc函数分配的内存空间是连续的,可用于存储数组等数据结构。calloc函数返回的指针类型为void*,需要使用类型转换将其转换为正确的指针类型。- 如果分配的内存空间不再使用,应使用
free函数释放内存空间,以免造成内存泄漏问题。 - 在分配内存空间时,应该谨慎考虑所需内存大小,避免分配过大或过小的内存空间,造成内存资源的浪费或不足。
qsort
qsort 是定义在 <stdlib.h> 头文件中的 C 标准库函数,用于对数组进行快速排序。
函数签名:void qsort(void* base, size_t num, size_t size, int (*compare)(const void*, const void*));
输入:
base:要排序的数组的起始地址。num:要排序的元素个数。size:每个元素的大小(以字节为单位)。compare:比较函数的指针,用于指定排序的方式。
比较函数的定义如下:
int compare(const void* a, const void* b) {// 返回值 < 0:a 排在 b 前面// 返回值 = 0:a 和 b 相等// 返回值 > 0:a 排在 b 后面}
返回值:无。
以下是一个使用 qsort 函数对整型数组进行排序的示例代码:
#include <stdio.h>#include <stdlib.h>int compare(const void* a, const void* b) {return (*(int*) a - *(int*) b);}int main() {int arr[] = { 2, 6, 1, 8, 4, 7, 9, 3, 5 };int n = sizeof(arr) / sizeof(int);qsort(arr, n, sizeof(int), compare);printf("排序后的数组:\n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;}
在上面的示例代码中,qsort 函数将按照 compare 函数指定的排序方式对整型数组进行排序。然后,程序打印排序后的数组。
注意事项:
- 在编写
compare函数时,应该根据实际情况返回适当的比较结果,以确保排序结果正确。 - 在使用
qsort函数时,应该考虑数组元素的类型和大小,避免出现类型转换错误和内存越界等问题。 qsort函数使用快速排序算法,对于大型数据集的排序速度较快,但对于小型数据集,可能会存在较大的开销。
malloc ☆
malloc 是定义在 <stdlib.h> 头文件中的 C 标准库函数,用于在堆上动态分配指定大小的内存块。
函数签名:void* malloc(size_t size);
输入:
- `size`:要分配的内存块大小,以字节为单位。
返回值:分配成功则返回指向该内存块的指针,否则返回空指针(NULL)。
以下是一个使用 malloc 函数动态分配内存块的示例代码:
#include <stdio.h>#include <stdlib.h>int main() {int* ptr = NULL;int n = 5;ptr = (int*) malloc(n * sizeof(int));if (ptr == NULL) {printf("内存分配失败\n");exit(1);}printf("请输入 %d 个整数:\n", n);for (int i = 0; i < n; i++) {scanf("%d", &ptr[i]);}printf("您输入的 %d 个整数是:\n", n);for (int i = 0; i < n; i++) {printf("%d ", ptr[i]);}printf("\n");free(ptr);return 0;}
在上面的示例代码中,malloc 函数将在堆上动态分配一个可以存储 n 个整数的内存块,然后程序通过指针 ptr 访问该内存块,接着读取 n 个整数,最后打印读取的整数并释放动态分配的内存块。
注意事项:
- 使用
malloc函数分配的内存块需要手动释放,否则可能会导致内存泄漏。 - 在分配内存块时,应该考虑要分配的内存块大小,以及分配内存块的次数,以避免内存碎片的问题。
- 在使用
malloc函数时,应该根据实际情况检查分配是否成功,以及释放内存块是否正确。
free ☆
free 是定义在 <stdlib.h> 头文件中的 C 标准库函数,用于释放动态分配的内存块。
函数签名:void free(void* ptr);
输入:
ptr:指向动态分配的内存块的指针。
返回值:无。
以下是一个使用 malloc 和 free 函数动态分配和释放内存块的示例代码:
#include <stdio.h>#include <stdlib.h>int main() {int* ptr = NULL;int n = 5;ptr = (int*) malloc(n * sizeof(int));if (ptr == NULL) {printf("内存分配失败\n");exit(1);}printf("请输入 %d 个整数:\n", n);for (int i = 0; i < n; i++) {scanf("%d", &ptr[i]);}printf("您输入的 %d 个整数是:\n", n);for (int i = 0; i < n; i++) {printf("%d ", ptr[i]);}printf("\n");free(ptr);ptr = NULL;return 0;}
在上面的示例代码中,free 函数释放了之前使用 malloc 函数动态分配的内存块,并将指针 ptr 的值设为 NULL。
注意事项:
- 使用
free函数释放动态分配的内存块时,必须确保指针指向有效的动态分配的内存块,否则可能会导致未定义的行为。 - 在释放内存块之后,为了避免指针悬空的问题,应将指针设置为
NULL。
exit
exit 是定义在 <stdlib.h> 头文件中的 C 标准库函数,用于正常终止程序的执行。
函数签名:void exit(int status);
输入:
status:表示程序的退出状态码,通常使用 0 表示正常退出,其他数值则表示异常退出。
返回值:无。
下面是一个使用 exit 函数终止程序的示例代码:
#include <stdio.h>#include <stdlib.h>int main() {printf("程序开始执行...\n");// 模拟一些复杂的计算int sum = 0;for (int i = 1; i <= 100000; i++) {sum += i;}printf("计算结果:%d\n", sum);printf("程序即将退出...\n");exit(0); // 正常退出,状态码为 0// 下面的代码不会被执行printf("这行代码永远不会被执行\n");return 0;}
在上面的示例代码中,exit 函数被调用以正常终止程序的执行,并返回状态码 0。
注意事项:
- 在使用
exit函数时,应确保释放了已分配的内存和其他资源。 exit函数不会调用被释放的动态对象的析构函数,因此如果程序使用了 C++ 等带有自动对象的语言,建议使用atexit函数在程序结束时自动调用析构函数。- 在正常情况下,程序不应该使用
exit函数来退出程序,而是应该使用return语句从main函数中返回。
exit 是定义在 <stdlib.h> 头文件中的 C 标准库函数,用于正常终止程序的执行。
函数签名:void exit(int status);
输入:
status:表示程序的退出状态码,通常使用 0 表示正常退出,其他数值则表示异常退出。
返回值:无。
下面是一个使用 exit 函数终止程序的示例代码:
#include <stdio.h>#include <stdlib.h>int main() {printf("程序开始执行...\n");// 模拟一些复杂的计算int sum = 0;for (int i = 1; i <= 100000; i++) {sum += i;}printf("计算结果:%d\n", sum);printf("程序即将退出...\n");exit(0); // 正常退出,状态码为 0// 下面的代码不会被执行printf("这行代码永远不会被执行\n");return 0;}
在上面的示例代码中,exit 函数被调用以正常终止程序的执行,并返回状态码 0。
注意事项:
- 在使用
exit函数时,应确保释放了已分配的内存和其他资源。 exit函数不会调用被释放的动态对象的析构函数,因此如果程序使用了 C++ 等带有自动对象的语言,建议使用atexit函数在程序结束时自动调用析构函数。- 在正常情况下,程序不应该使用
exit函数来退出程序,而是应该使用return语句从main函数中返回。
sprintf ☆
sprintf是定义在<stdio.h>头文件中的 C 标准库函数,用于将格式化的数据写入字符串缓冲区中。- 函数签名:
int sprintf(char* str, const char* format, ...); - 参数:
str:指向要写入数据的字符串缓冲区。format:格式化字符串,它包含了要写入到缓冲区中的数据以及格式化信息。- 可变参数列表:要写入到缓冲区中的数据。
- 返回值:返回写入到缓冲区中的字符数,不包括空字符。如果写入失败,则返回负值。
- 注意事项:
- 在使用
sprintf函数时,要确保指定的缓冲区有足够的空间来容纳格式化后的字符串,以避免缓冲区溢出。 sprintf函数的格式化字符串和printf函数的格式化字符串是相同的,因此在使用时应遵循相应的格式化规则。- 在使用
sprintf函数时,应注意不要将格式化字符串和数据中包含的敏感信息输出到日志文件或其他可读取的地方。
- 在使用
#include <stdio.h>#include <stdlib.h>int main() {char buffer[100];int value = 123;sprintf(buffer, "这是一个整数:%d", value);printf("格式化后的字符串:%s\n", buffer);return 0;}/* 运行结果:格式化后的字符串:这是一个整数:123 */
#include <stdio.h>int main() {char buffer[50];int num1 = 42;double num2 = 3.14159;// 将格式化的输出写入 buffersprintf(buffer, "整数:%d,浮点数:%.2f", num1, num2);// 打印 bufferprintf("格式化字符串: %s\n", buffer);return 0;}/* 运行结果:格式化字符串: 整数:42,浮点数:3.14 */
#include <stdio.h>#include <string.h>int main() {char str[100];int num = 10;float fnum = 3.1415926;sprintf(str, "The value of num is %d and the value of fnum is %.2f", num,fnum);printf("%s\n", str);return 0;}/* 运行结果:The value of num is 10 and the value of fnum is 3.14 */
isdigit
isdigit 是定义在 <ctype.h> 头文件中的 C 标准库函数,用于判断指定的字符是否是数字。
函数签名:int isdigit(int c);
输入:
c:要判断的字符。
返回值:
- 如果
c是数字,则返回非零值(通常是 1),否则返回零。
下面是一个使用 isdigit 函数判断字符是否为数字的示例代码:
#include <stdio.h>#include <ctype.h>int main() {char c1 = '1';char c2 = 'A';if (isdigit(c1)) {printf("%c 是一个数字\n", c1);}if (!isdigit(c2)) {printf("%c 不是一个数字\n", c2);}return 0;}
在上面的示例代码中,isdigit 函数被用于判断字符 c1 是否为数字,并根据判断结果输出不同的信息。另外,!isdigit(c2) 表示字符 c2 不是数字。
注意事项:
- 在使用
isdigit函数时,应将要判断的字符转换为int类型传入函数中。 isdigit函数只能判断单个字符是否为数字,如果要判断一个字符串是否全由数字组成,则需要遍历整个字符串并逐个判断。
isalpha
isalpha 是定义在 <ctype.h> 头文件中的 C 标准库函数,用于判断指定的字符是否是字母。
函数签名:int isalpha(int c);
输入:
c:要判断的字符。
返回值:
- 如果
c是字母,则返回非零值(通常是 1),否则返回零。
下面是一个使用 isalpha 函数判断字符是否为字母的示例代码:
#include <stdio.h>#include <ctype.h>int main() {char c1 = 'a';char c2 = '1';if (isalpha(c1)) {printf("%c 是一个字母\n", c1);}if (!isalpha(c2)) {printf("%c 不是一个字母\n", c2);}return 0;}
在上面的示例代码中,isalpha 函数被用于判断字符 c1 是否为字母,并根据判断结果输出不同的信息。另外,!isalpha(c2) 表示字符 c2 不是字母。
注意事项:
- 在使用
isalpha函数时,应将要判断的字符转换为int类型传入函数中。 isalpha函数只能判断单个字符是否为字母,如果要判断一个字符串是否全由字母组成,则需要遍历整个字符串并逐个判断。std::vector ☆
std::vector是 C++ 标准库中的一个 动态数组容器,是一个封装了动态分配数组的类模板,它允许您存储可调整大小的元素序列std::vector相较于普通数组,它提供了更多高级功能,包括 动态内存管理、元素插入和删除、以及一组有用的辅助方法std::vector可以存储任何类型的元素,包括自定义类型和基本类型
主要特点:
- 动态大小:
std::vector的 大小可以根据需要动态调整。当您向容器中添加元素时,它会自动调整大小以适应新的元素。同样,在删除元素时,容器可以自动调整大小。 - 内存连续:
std::vector中的 元素在内存中是连续存储的,这使得它可以高效地进行随机访问(random access)。您可以通过下标或迭代器访问元素,时间复杂度为 O(1),支持在尾部进行元素的增加和删除操作,时间复杂度为 O(1)。
容量和大小:
std::vector管理两个重要属性:大小size(当前存储的元素数量)和容量capacity(为元素分配的内存数量)。- 容量通常大于或等于大小,以便 在添加新元素时不需要频繁地重新分配内存。
#include <iostream>#include <vector>int main() {std::vector<int> numbers;// 添加元素到 vectorfor (int i = 0; i < 10; ++i) {numbers.push_back(i);}// 使用下标访问和修改元素numbers[0] = 42;// 使用范围 for 循环遍历并打印 vector 中的所有元素for (const auto &number : numbers) {std::cout << number << " ";}std::cout << std::endl;return 0;}
std::vector 提供了许多有用的成员函数,如 push_back pop_back insert erase clear size capacity resize 等,以方便地操作容器。
std::vector<int> numbers;numbers.push_back(42); // numbers 现在包含一个元素:42
std::vector<int> numbers = {1, 2, 3};numbers.pop_back(); // numbers 现在包含两个元素:1 和 2
std::vector<int> numbers = {1, 2, 3};numbers.insert(numbers.begin() + 1, 42); // numbers 现在包含:1, 42, 2, 3
std::vector<int> numbers = {1, 2, 3, 4};numbers.erase(numbers.begin() + 1); // numbers 现在包含:1, 3, 4
std::vector<int> numbers = {1, 2, 3};numbers.clear(); // numbers 现在为空
std::vector<int> numbers = {1, 2, 3};std::cout << "The size of the vector is: " << numbers.size() << std::endl; // 输出:3
std::vector<int> numbers = {1, 2, 3};std::cout << numbers.capacity() << std::endl; // => 3
std::vector<int> numbers = {1, 2, 3};numbers.resize(5, 42); // numbers 现在包含:1, 2, 3, 42, 42numbers.resize(2); // numbers 现在包含:1, 2
#include <iostream>#include <vector>using namespace std;int main() {// 创建 vector 容器vector<int> vec;// 在 vector 中添加元素vec.push_back(1);vec.push_back(2);vec.push_back(3);// 使用迭代器访问 vector 中的元素for (vector<int>::iterator it = vec.begin(); it != vec.end(); it++) {cout << *it << " ";}cout << endl;// 在 vector 中更改元素vec[0] = 10;// 使用迭代器删除元素vec.erase(vec.begin() + 1);// 输出 vector 的大小cout << "Size of vec: " << vec.size() << endl;// 使用迭代器访问 vector 中的元素for (vector<int>::iterator it = vec.begin(); it != vec.end(); it++) {cout << *it << " ";}cout << endl;return 0;}
以上示例展示了如何创建一个 std::vector 对象,使用 push_back() 函数在 vector 末尾插入元素,使用迭代器访问 vector 中的元素,使用 erase() 函数与迭代器来删除元素,以及使用 size() 函数获取 vector 的大小。
需要注意的是,vector 支持动态化的内存分配和释放。在向 vector 添加元素时,如果当前 vector 的容量不够用,则会自动扩展内存,以容纳更多的元素。反之,在删除元素时,如果占用的内存数量变得很小,则 vector 会自动释放多余的内存。
最后,需要注意避免 vector 的随机访问越界操作,可能会触发 undefined behavior 错误。使用迭代器访问 vector 的元素通常是比使用下标更加安全和稳定的。
std::vector<int> numbers = {1, 2, 3};std::cout << numbers.capacity() << std::endl; // => 3
在声明 vector 对象 numbers 时,容器的初始大小设置为了 3,因此它的容量也为 3
std::vector<int> nums;nums.push_back(1);nums.push_back(2);nums.push_back(3);std::cout << nums.capacity() << std::endl; // => 3 或者比 3 更大的值
输出结果是不确定的,取决于 vector 的具体实现。通常情况下,在操作 vector 对象的元素时,vector 会自动调整容量,以避免过于频繁地重新分配内存。在这个例子中,输出结果可能是 3,也可能是更大的数值。
不要误以为 capacity() 函数返回的值的单位是“字节”,实际上是 vector 容器分配的内存空间的个数,可以说是木有单位的,可以理解为 vector 容器对于该类型的数据所能够容纳的数量。如果想要获取容器 vector 容量的“字节”数,那么可以通过公式 capacity() * sizeof(T) 来计算。
#include <iostream>#include <string>#include <vector>using namespace std;int main() {vector<int>v1 = {1, 2, 3};vector<int>v2;v2.push_back(1);v2.push_back(2);v2.push_back(3);cout << "v1 的容量:" << v1.capacity() << endl;cout << "v1 占用的字节数" << v1.capacity() * sizeof(int) << endl;cout << "v2 的容量:" << v2.capacity() << endl;cout << "v2 占用的字节数" << v2.capacity() * sizeof(int) << endl;return 0;}/* 运行结果:v1 的容量:3v1 占用的字节数12v2 的容量:4v2 占用的字节数16*/
auto ☆
auto 关键字在 C++11 中引入,它允许 编译器自动推导变量的类型,从而简化代码并提高可读性,特别是在处理复杂类型时。需要注意的是,使用 auto 时,变量必须在声明时初始化,否则编译器无法推导出变量的类型。
#include <iostream>#include <vector>#include <map>int main() {// 基本类型auto i = 42; // intauto d = 3.14; // double// STL 容器std::vector<int> numbers = {1, 2, 3, 4, 5};auto it = numbers.begin(); // std::vector<int>::iterator// 使用范围 for 循环遍历容器for (auto n : numbers) { // n 的类型被推导为 intstd::cout << n << " ";}std::cout << std::endl;// 复杂类型std::map<std::string, int> name_to_age = {{"Alice", 30}, {"Bob", 25}, {"Cathy", 28}};for (const auto &pair : name_to_age) { // pair 的类型被推导为 const std::pair<std::string, int>&std::cout << pair.first << " is " << pair.second << " years old." << std::endl;}return 0;}
std::string ☆
#include <iostream>#include <string>using namespace std;int main() {string s1 = "hello", s2 = "world";cout << s1 + s2 << endl; // => helloworldcout << s1 + ", " + s2 + "!" << endl; // => hello, world!}
#include <iostream>#include <string>using namespace std;int main() {string s1 = "hello", s2 = "world", s3;s3 = s1 + ", " + s2 + "!";cout << "s3 的内容为:" << s3 << endl; // => s3 的内容为:hello, world!cout << "s3 的长度为:" << s3.length() << endl; // => s3 的长度为:13}
#include <iostream>#include <string>using namespace std;int main() {string s1 = "hello", s2 = "world", s3;s3 = s1 + ", " + s2 + "!";cout << "在字符串 s3 \"" << s3 << "\" 查找子串 \"world\"" << endl;int index1 = s3.find("world");if (index1 != string::npos) {cout << "子串 \"world\" 找到了,下标为:" << index1 << endl;} else {cout << "子串 \"world\" 没找到,find 函数的返回值为:" << string::npos << endl;}}/* 运行结果:在字符串 s3 "hello, world!" 查找子串 "world"子串 "world" 找到了,下标为:7*/
#include <iostream>#include <string>using namespace std;int main() {string s1 = "hello", s2 = "world", s3;s3 = s1 + ", " + s2 + "!";cout << "在字符串 s3 \"" << s3 << "\" 查找子串 \"world1\"" << endl;int index1 = s3.find("world1");if (index1 != string::npos) {cout << "子串 \"world1\" 找到了,下标为:" << index1 << endl;} else {cout << "子串 \"world1\" 没找到,find 函数的返回值为:" << string::npos << endl;}}/* 运行结果:在字符串 s3 "hello, world!" 查找子串 "world1"子串 "world1" 没找到,find 函数的返回值为:18446744073709551615*/
string::npos
string::npos是一个 static const 的 size_t 类型的常量,表示 string 类型中无效位置的值。- 在使用 find() 或 rfind() 成员函数查找字符串时,如果没有找到匹配的字符串,则返回 string::npos。
string::npos的值通常是 -1,但是由于它的类型是 size_t,所以不能保证它的值一定是 -1- 判断没有找到的条件表达式应该这么写
index1 != string::npos而不是index1 != -1这么写 - 应该使用 string::npos 来判断是否找到了匹配的字符串,而不是使用 -1 来判断
- 判断没有找到的条件表达式应该这么写
#include <iostream>#include <string>using namespace std;int main() {string s1 = "hello", s2 = "world", s3, s4, s5, s6;s3 = s1 + ", " + s2 + "!";s4 = s3.substr(7); // 从位置 7 开始截,截取到结尾s5 = s3.substr(s3.length() - 1);s6 = s3.substr(7, 5); // 从位置 7 开始截,连续截取 5 个字符cout << s4 << endl; // => world!cout << s5 << endl; // => !cout << s6 << endl; // => world// substr 不会影响源字符串 s3cout << s3 << endl; // => hello, world!// 从 0 开始截,相当于拷贝一份字符串cout << s3.substr(0) << endl; // => hello, world!// 第一个参数表示截取的开始位置,如果起始位置不在范围 [0, s3.length()] 之内,会导致程序崩溃// cout << s3.substr(-1) << endl;// cout << s3.substr(100) << endl;}
#include <iostream>#include <string>using namespace std;int main() {string input;cout << "请输入一个字符串:"; // => 请输入一个字符串:Hello World!getline(cin, input);cout << "您输入的字符串为:" << input << endl; // => 您输入的字符串为:Hello World!}
ifstream ☆
测试数据说明:
测试文件 1.txt 与 main.cpp 文件位于同一个目录:
#include <fstream>#include <iostream>#include <string>using namespace std;int main() {string filename;cout << "请输入打开的文件名:";getline(cin, filename);ifstream file(filename); // 打开文件 filenameif (!file) {cerr << "打开" << filename << "失败" << endl;return 1;} else {cout << "打开" << filename << "成功" << endl;string line;int i = 1;while (getline(file, line)) {cout << "读取到的第" << i++ << "行内容:" << line << endl;}file.close(); // 关闭文件cout << filename << "文件内容读取完毕,关闭文件" << endl;}return 0;}
请输入打开的文件名:1.txt打开1.txt成功读取到的第1行内容:this is first line...读取到的第2行内容:this is second line...读取到的第3行内容:读取到的第4行内容:this is 4th line...读取到的第5行内容:读取到的第6行内容:6th读取到的第7行内容:读取到的第8行内容:第八行读取到的第9行内容:1.txt文件内容读取完毕,关闭文件
请输入打开的文件名:1打开1失败
修改测试文件 1.txt 的相对位置,丢到 test 目录中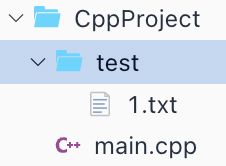
请输入打开的文件名:1.txt打开1.txt失败
请输入打开的文件名:test/1.txt打开test/1.txt成功读取到的第1行内容:this is first line...读取到的第2行内容:this is second line...读取到的第3行内容:读取到的第4行内容:this is 4th line...读取到的第5行内容:读取到的第6行内容:6th读取到的第7行内容:读取到的第8行内容:第八行读取到的第9行内容:test/1.txt文件内容读取完毕,关闭文件
我们前面测试的文件,都是使用文件的相对路径的方式来写的,但是 std::ifstream 打开文件的时候既可以使用 相对路径 也可以使用 绝对路径。
#include <fstream>#include <iostream>#include <string>using namespace std;int main() {string filename;cout << "请输入打开的文件名:";getline(cin, filename);ifstream file(filename);if (!file) {cerr << "打开" << filename << "失败" << endl;return 1;} else {cout << "打开" << filename << "成功" << endl;string line, file_data = "";int i = 1;while (getline(file, line)) {cout << "读取到的第" << i++ << "行内容:" << line << endl;file_data += line + '\n';}file.close();cout << filename << "文件内容读取完毕,关闭文件" << endl;cout << filename << "文件内容如下:\n[" << file_data << "]" << endl;}return 0;}
请输入打开的文件名:./test/1.txt打开./test/1.txt成功读取到的第1行内容:this is first line...读取到的第2行内容:this is second line...读取到的第3行内容:读取到的第4行内容:this is 4th line...读取到的第5行内容:读取到的第6行内容:6th读取到的第7行内容:读取到的第8行内容:第八行读取到的第9行内容:./test/1.txt文件内容读取完毕,关闭文件./test/1.txt文件内容如下:[this is first line...this is second line...this is 4th line...6th第八行]
#include <fstream>#include <iostream>#include <string>using namespace std;int main() {string filename;cout << "请输入打开的文件名:";getline(cin, filename);ifstream file(filename);if (!file) {cerr << "打开" << filename << "失败" << endl;return 1;} else {cout << "打开" << filename << "成功" << endl;string line, file_data = "";int i = 1;char buf[1024];while (file.getline(buf, sizeof(buf))) {line = buf;cout << "读取到的第" << i++ << "行内容:" << line << endl;file_data += line + '\n';}file.close();cout << filename << "文件内容读取完毕,关闭文件" << endl;cout << filename << "文件内容如下:\n[" << file_data << "]" << endl;}return 0;}
file.getline(buf, sizeof(buf)) 使用 ifstream 类的对象 file 身上的 getline 方法,也可以读取文件内容
参数 1:buf 表示读取到的这一行内容存放到哪块空间中,传入的是一个地址
参数 2:传入的是一个整型,表示这一行最多读取多少个字符
#include <fstream>#include <iostream>#include <string>using namespace std;int main() {string filename;cout << "请输入打开的文件名:";getline(cin, filename);ifstream file(filename);if (!file) {cerr << "打开" << filename << "失败" << endl;return 1;} else {cout << "打开" << filename << "成功" << endl;const int MAX_LINE_LENGTH = 1000; // 假设每行最多有 1000 个字符char file_data[100][MAX_LINE_LENGTH]; // 存储文件内容的二维字符数组int i = 0;while (file.getline(file_data[i++], MAX_LINE_LENGTH));// while (file.getline(file_data[i++], MAX_LINE_LENGTH)) {// cout << "读取到的第" << i << "行内容:" << file_data[i - 1] << endl;// }file.close();cout << filename << "文件内容读取完毕,关闭文件" << endl;cout << filename << "文件内容如下:\n[";for (int j = 0; j < i - 1; j++) {cout << file_data[j] << "\n";}cout << "]" << endl;}return 0;}
char file_data[100][MAX_LINE_LENGTH]; while (file.getline(file_data[i++], MAX_LINE_LENGTH));
如果存储文件内容的数据结构是一个二维字符数组,那么读取文件内容可以进一步简写到一行中。
请输入打开的文件名:./test/1.txt打开./test/1.txt成功./test/1.txt文件内容读取完毕,关闭文件./test/1.txt文件内容如下:[this is first line...this is second line...this is 4th line...6th第八行]
std::stringstream ☆
std::stringstream 是 C++ 标准库中的一个类,它允许将字符串作为流进行处理,即实现字符串的读入、输出和格式化等操作。通常,我们可以使用 std::stringstream 类来方便地进行字符串的转换和处理。
以下是 std::stringstream 的主要特点和用途:
std::stringstream是一个字符串流类,可以将一个字符串对象当作流进行处理。- 可以使用
<<和>>运算符在std::stringstream对象中进行输入和输出。 - 能够将字符串按指定格式进行解析(例如格式化输入)。
- 通常,可以使用
std::stringstream类对字符串进行分割、转换和处理等操作。
std::stringstream 类的用法和其他输入输出流类似,可以按照以下步骤进行:
- 创建一个
std::stringstream对象。 - 把需要处理的字符串赋值给该对象的字符串缓冲区。
- 通过
<<运算符向对象中写入数据并将其转换为字符串。 - 通过
>>运算符从对象中获取数据,并进行处理或存储。
#include <iostream>#include <sstream>#include <string>int main() {std::string str = "42";std::stringstream ss(str);int n;ss >> n;std::cout << "The number is: " << n << std::endl;return 0;}
在上面的示例中,我们首先创建了一个字符串 str,然后定义了一个 std::stringstream 对象 ss,并将字符串 str 赋值给该对象的字符串缓冲区。接着,我们通过 >> 运算符将字符串转换为整数,并将其存储在 n 中,最后将 n 输出到标准输出流中。
需要注意的是,std::stringstream 类支持格式化输入和输出,可以通过一系列的 << 和 >> 运算符的组合进行使用,从而实现更丰富的字符串处理和转换功能。此外,std::stringstream 也支持使用 STL 中的迭代器进行读写操作,具有比较灵活和高效的特点。
文件 IO | 对比 C 的 FILE 风格和 C++ 的 ifstream 风格
当需要读取本地文件时,可以选择使用 C 风格的 FILE 或 C++ 风格的 ifstream。两种方法在某些情况下是可以互换的,但它们之间存在一些差异。
C 风格的 FILE:
- 使用标准 C 库函数(如 fopen、fread、fwrite、fclose 等)进行文件操作。
- 更底层,需要手动管理文件指针和内存分配。
- 可以 跨平台 使用,因为它是标准 C 库的一部分。
C++ 风格的 ifstream:
- 使用 C++ 流库进行文件操作,提供更高级的抽象。
- 更容易使用,因为 C++ 流库会自动处理内存分配和文件指针操作。
- 类型安全,可以避免某些常见的类型转换错误。
- 适用于 C++ 对象的序列化和反序列化。
问:如何选择?
- 如果你正在编写纯 C 代码,或者需要确保代码能在 C 环境中运行,则推荐使用 C 风格的 FILE。
- 如果你的项目是用 C++ 编写的,并且需要处理 C++ 对象或使用 C++ 特性(如异常处理、模板等),那么推荐使用 C++ 风格的 ifstream。
- 如果你希望代码易于阅读和维护,同时也喜欢使用 C++ 提供的高级特性,那么推荐使用 C++ 风格的 ifstream。
小结:
- 在大多数情况下,使用 C++ 风格的 ifstream 会让代码更加简洁、易读和易于维护。
- 如果项目需要与纯 C 代码兼容或者需要在不同平台上运行,那么使用 C 风格的 FILE 也是一个合适的选择。
demo | 读取文件每一行的内容
#include <fstream>#include <iostream>using namespace std;int main() {char name[] = "test.txt";string line;int count = 0;ifstream input(name);if (input.is_open()) {while (getline(input, line)) count++;input.close();}cout << "文件共有 " << count << " 行内容。" << endl; // => 文件共有 15 行内容。return 0;}
#include <cstdio>int main() {const char* name = "test.txt";FILE* file = fopen(name, "r");if (!file) {perror("无法打开文件");return 1;}char buffer[256];int i = 0;while (fgets(buffer, sizeof(buffer), file)) {printf("读取到第 %d 行:%s", ++i, buffer);}printf("\n%s 文件一共有 %d 行内容\n", name, i);fclose(file);return 0;}
123112233哈哈哈abcasdff

思考:为什么明明是 16 行,但是程序输出的却是 15 行呢?
在文本文件中,每一行都会以一个特殊字符 \n 结尾,这个字符表示换行符。当我们使用 getline() 函数获取一行文本时,默认情况下,它会读取到遇到的第一个换行符为止,然后返回该行文本。对于最后一行,如果没有换行符,getline()函数就不会返回任何内容,并认为该行为空行。
程序统计的行数是按照换行符的数量进行计算的,由于最后一行没有换行符,所以该行不会被算作一行,行数会比实际行数少 1,如果一个文本文件中有 n 行内容,并且最后一行没有换行符,那么程序运行的结果应该是 n-1 行。
123112233哈哈哈abcasdff

注意:如果最有一行有内容,即便是一个空格,它也将被视作一行。
以下是两种读取文件每一行内容的方式的对比 写法 1:
- 使用 C++ 的文件流(ifstream)和 getline 函数进行文件读取。
- 更符合 C++ 风格,易于理解和使用。
- 适用于 C++ 项目,与 C++ 标准库函数和容器(如 string)更兼容。
- 使用了 C++ 的命名空间 std,简化了代码。
- 使用 string 类型存储每一行内容,自动管理内存。
- getline 默认会去掉换行符,使得处理文本更方便。
写法 2:
- 使用 C 语言的文件指针(FILE*)和 fgets 函数进行文件读取。
- 对于熟悉 C 语言的人更易于理解。
- 可用于 C 项目和兼容 C 语言接口的 C++ 项目。
- 需要手动管理缓冲区大小,注意防止缓冲区溢出。
- fgets 在读取的字符串中保留换行符,需要在处理字符串时删除换行符。
- 适用于 C 和 C++ 混合编程的项目。
总结:
- 如果项目主要使用 C++,推荐使用写法 1,因为它更符合 C++ 风格,易于理解和使用。
- 如果项目需要兼容 C 语言或者主要使用 C 语言,可以考虑使用写法 2。
std::pair ☆
std::make_pair ☆
std::partial_sort ☆
std::greater ☆
std::thread ☆
std::shared_ptr ☆
std::to_string ☆

若有收获,就点个赞吧
0 人点赞
