简述
掌握文件的使用方法,理解一二维数据,掌握wordcloud库,能够处理包含一二维数据的文件,能够用程序绘制词云。
课件
代码汇总
"中国是一个伟大的国家"
tf = open("f.txt", "rt")print(tf.readline()) # "中国是一个伟大的国家"tf.close()
tf = open("f.txt", "rb")print(tf.readline()) # b'"\xe4\xb8\xad\xe5\x9b\xbd\xe6\x98\xaf\xe4\xb8\x80\xe4\xb8\xaa\xe4\xbc\x9f\xe5\xa4\xa7\xe7\x9a\x84\xe5\x9b\xbd\xe5\xae\xb6"'tf.close()
f = open("f.txt") # 文本形式、只读模式、默认值f = open("f.txt", "rt") # 文本形式、只读模式、同默认值f = open("f.txt", "w") # 文本形式、覆盖写模式f = open("f.txt", "a+") # 文本形式、追加写模式+ 读文件f = open("f.txt", "a") # 文本形式、追加写模式(不能读)f = open("f.txt", "x") # 文本形式、创建写模式f = open("f.txt", "b") # 二进制形式、只读模式f = open("f.txt", "wb") # 二进制形式、覆盖写模式
fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')txt = fo.read() # 一次读入,统一处理fo.close()
fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')txt = fo.read(2) # 按数量读入,逐步处理while txt != "":txt = fo.read(2)fo.close()
fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')for line in fo.readline(): # 一次读入,分行处理print(line)fo.close()
fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')for line in fo: # 分行读入,逐行处理print(line)fo.close()
fo = open("output.txt", "w+")ls = ["中国", "法国", "美国"]fo.writelines(ls)# fo.seek(0)for line in fo:print(line)fo.close()'''输出结果为空'''
fo = open("output.txt", "w+")ls = ["中国", "法国", "美国"]fo.writelines(ls)fo.seek(0)for line in fo:print(line)fo.close()'''中国法国美国'''
300,0,144,1,0,0300,0,144,0,1,0300,0,144,0,0,1300,0,144,1,1,0300,0,108,0,1,1184,0,72,1,0,1184,0,72,0,0,0184,0,72,0,0,0184,0,72,0,0,0184,1,72,1,0,1184,1,72,0,0,0184,1,72,0,0,0184,1,72,0,0,0184,1,72,0,0,0184,1,720,0,0,0
import turtle as tt.title("自动轨迹绘制")t.setup(800, 600, 0, 0)t.pencolor("red")t.pensize(5)# 数据读取datals = []f = open("data.txt")for line in f:print('line:', line)line = line.replace("\n", "")datals.append(list(map(eval, line.split(","))))print('datals:', datals)f.close()# 自动绘制for i in range(len(datals)):t.pencolor(datals[i][3], datals[i][4], datals[i][5])t.fd(datals[i][0])if datals[i][1]:t.rt(datals[i][2])else:t.lt(datals[i][2])if i == (len(datals) - 1):t.done()"""line: 300,0,144,1,0,0line: 300,0,144,0,1,0line: 300,0,144,0,0,1line: 300,0,144,1,1,0line: 300,0,108,0,1,1line: 184,0,72,1,0,1line: 184,0,72,0,0,0line: 184,0,72,0,0,0line: 184,0,72,0,0,0line: 184,1,72,1,0,1line: 184,1,72,0,0,0line: 184,1,72,0,0,0line: 184,1,72,0,0,0line: 184,1,72,0,0,0line: 184,1,720,0,0,0datals: [[300, 0, 144, 1, 0, 0],[300, 0, 144, 0, 1, 0],[300, 0, 144, 0, 0, 1],[300, 0, 144, 1, 1, 0],[300, 0, 108, 0, 1, 1],[184, 0, 72, 1, 0, 1],[184, 0, 72, 0, 0, 0],[184, 0, 72, 0, 0, 0],[184, 0, 72, 0, 0, 0],[184, 1, 72, 1, 0, 1],[184, 1, 72, 0, 0, 0],[184, 1, 72, 0, 0, 0],[184, 1, 72, 0, 0, 0],[184, 1, 72, 0, 0, 0],[184, 1, 720, 0, 0, 0]]"""

中国 美国 日本 德国 法国 英国 意大利
filename = "1.txt"f = open(filename)txt = f.read()ls = txt.split()print('ls:', ls) # ls: ['中国', '美国', '日本', '德国', '法国', '英国', '意大利']f.close()
中国$美国$日本$德国$法国$英国$意大利
filename = "1.txt"f = open(filename)txt = f.read()ls = txt.split('$')print('ls:', ls) # ls: ['中国', '美国', '日本', '德国', '法国', '英国', '意大利']f.close()
ls = ["中国", "美国", "日本"]fname = "1.txt"f = open(fname, "w")f.write(" ".join(ls))f.close()
中国 美国 日本
ls = ["中国", "美国", "日本"]fname = "1.txt"f = open(fname, "w")f.write("$".join(ls))f.close()
中国$美国$日本
城市,环比,同比,定基北京,101.5,120.7,121.4上海,101.2,127.3,127.8广州,101.3,119.4,120.0深圳,102.0,140.0,145.5沈阳,100.0,101.4,101.6
fname = "1.csv"fo = open(fname)ls = []for line in fo:line = line.replace("\n", "")ls.append(line.split(","))fo.close()print(ls)"""[["城市", "环比", "同比", "定基"],["北京", "101.5", "120.7", "121.4"],["上海", "101.2", "127.3", "127.8"],["广州", "101.3", "119.4", "120.0"],["深圳", "102.0", "140.0", "145.5"],["沈阳", "100.0", "101.4", "101.6"],]"""
fname = "output.csv"ls = [["1", "2", "3"], ["4", "5", "6"], ["7", "8", "9"]] # 二维列表f = open(fname, "w")for item in ls:f.write(",".join(item) + "\n")f.close()
1,2,34,5,67,8,9
import wordcloudc = wordcloud.WordCloud() # 1. 配置对象参数c.generate("wordcloud by Python") # 2. 加载词云文本c.to_file("pywordcloud.png") # 3. 输出词云文件

import wordcloudtxt = "life is short, you need python"w = wordcloud.WordCloud(background_color="white")w.generate(txt)w.to_file("pywcloud.png")

import jiebaimport wordcloudtxt = "程序设计语言是计算机能够理解和\识别用户操作意图的一种交互体系,它按照\特定规则组织计算机指令,使计算机能够自\动进行各种运算处理。"w = wordcloud.WordCloud(width=1000, font_path="msyh.ttc", height=700)w.generate(" ".join(jieba.lcut(txt))) # 中文想要先分词并组成空格字符串w.to_file("pywcloud.png")

import jiebaimport wordcloudf = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc")w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc")w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", max_words=15)w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", max_words=15)w.generate(txt)w.to_file("grwordcloud.png")

素材:


import jiebaimport wordcloudimport imageiomask = imageio.imread("fivestart.png")excludes = {}f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudimport imageiomask = imageio.imread("fivestart.png")excludes = {}f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudfrom imageio import imreadmask = imread("chinamap.jpg")excludes = {}f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudimport imageiomask = imageio.imread("chinamap.jpg")excludes = {}f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

f = open("latex.log")s = 0for line in f:line = line.strip("\n")if len(line) == 0:continues += 1print("共{}行".format(s)) # 共4951行
f = open("latex.log")cc = 0# 初始化一个记录 26 个字母出现次数的字典d = {}for i in range(26):d[chr(ord("a") + i)] = 0for line in f:for c in line:d[c] = d.get(c, 0) + 1cc += 1print("共{}字符".format(cc), end="")for i in range(26):if d[chr(ord("a") + i)] != 0:print(",{}:{}".format(chr(ord("a") + i), d[chr(ord("a") + i)]), end="")"""共244019字符,a:9620,b:525,c:8769,d:1046,e:15585,f:8653,g:4548,h:8882,i:17587,j:62,k:122,l:9090,m:736,n:25730,o:13812,p:961,q:132,r:13755,s:12948,t:14049,u:4850,v:294,w:427,x:276,y:359,z:4"""
f = open("latex.log")ls = f.readlines()s = set(ls)for i in s:ls.remove(i)t = set(ls)print("共{}独特行".format(len(s) - len(t))) # 共291独特行
1,2,3,4,5,6,78, 3, 2, 7, 1, 4, 6, 56, 1, 3, 8, 5, 7, 4, 2'a','b','c','x','y','z','i','j','k''k', 'b', 'j', 'c', 'i', 'y', 'z', 'a', 'x''z', 'c', 'b', 'a', 'k', 'i', 'j', 'y', 'x''a', 'y', 'b', 'x', 'z', 'c', 'i', 'j', 'k'5, 2, 4, 7, 1, 6, 8, 3
f = open("data.csv")for line in f:line = line.strip("\n")ls = line.split(",")ls = ls[::-1]print(",".join(ls))f.close()"""7,6,5,4,3,2,15, 6, 4, 1, 7, 2, 3,82, 4, 7, 5, 8, 3, 1,6'k','j','i','z','y','x','c','b','a''x', 'a', 'z', 'y', 'i', 'c', 'j', 'b','k''x', 'y', 'j', 'i', 'k', 'a', 'b', 'c','z''k', 'j', 'i', 'c', 'z', 'x', 'b', 'y','a'3, 8, 6, 1, 7, 4, 2,5"""
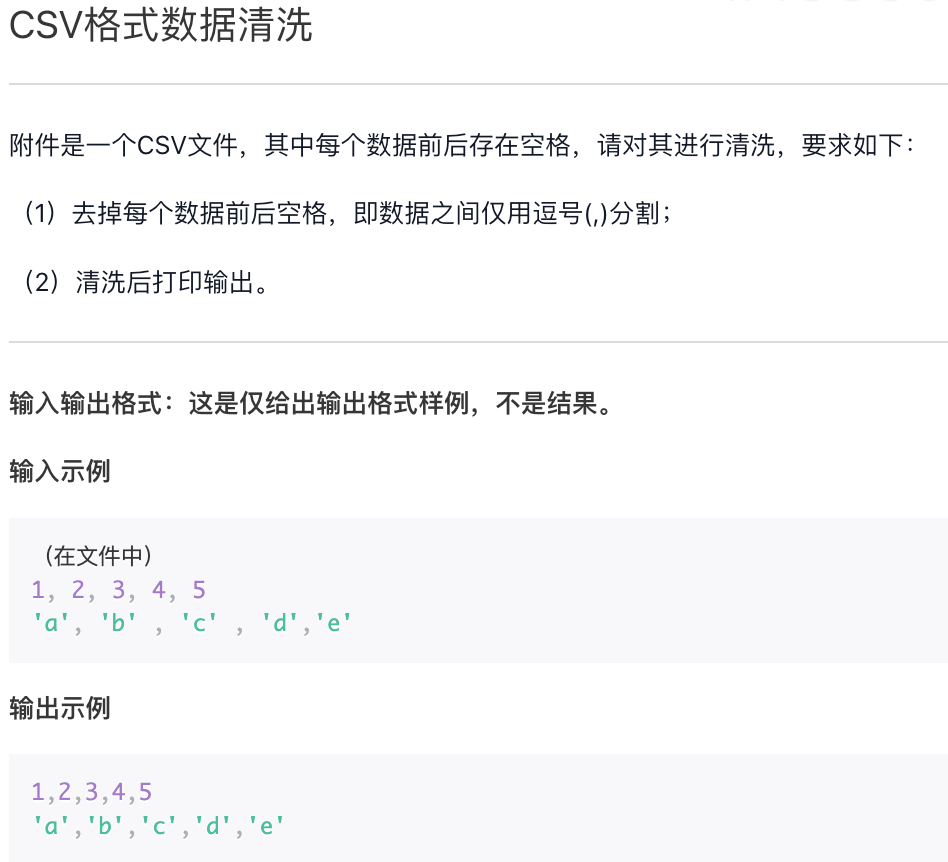
1,2,3,4,5,6,78, 3, 2, 7, 1, 4, 6, 56, 1, 3, 8, 5, 7, 4, 2'a','b','c','x','y','z','i','j','k''k', 'b', 'j', 'c', 'i', 'y', 'z', 'a', 'x''z', 'c', 'b', 'a', 'k', 'i', 'j', 'y', 'x''a', 'y', 'b', 'x', 'z', 'c', 'i', 'j', 'k'5, 2, 4, 7, 1, 6, 8, 3
f = open("data.csv")s = f.read()s = s.replace(" ", "")print(s)f.close()"""1,2,3,4,5,6,78,3,2,7,1,4,6,56,1,3,8,5,7,4,2'a','b','c','x','y','z','i','j','k''k','b','j','c','i','y','z','a','x''z','c','b','a','k','i','j','y','x''a','y','b','x','z','c','i','j','k'5,2,4,7,1,6,8,3"""
导学
前课复习
![[8.1.1]--前课复习(1).mp4 (51.18MB)](/uploads/projects/huyouda@public/7f2f55e32159afeaa752aaa4983cc03b.png) .mp4%22%2C%22size%22%3A53669945%2C%22taskId%22%3A%22ua0665a35-ddb2-4ad6-99fa-4d8d3aa1795%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481002465-bd27a895-b1ec-4afe-aa08-afe4736d789b.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22ouWnq%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#ouWnq)
.mp4%22%2C%22size%22%3A53669945%2C%22taskId%22%3A%22ua0665a35-ddb2-4ad6-99fa-4d8d3aa1795%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481002465-bd27a895-b1ec-4afe-aa08-afe4736d789b.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22ouWnq%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#ouWnq)
本课概要
.mp4%22%2C%22size%22%3A39090251%2C%22taskId%22%3A%22u68094013-f516-46c3-9d8c-05da6e608d4%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481002466-d5f6005e-df85-495f-980b-d786ea06fef6.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22E2ENp%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#E2ENp)
格式化:
- 字符串格式化:将字符串按照一定规格和式样进行规范
"{ }{ }{ }".format() - 数字格式化:将一组数据按照一定规格和式样进行规范:表示、存储、运算等
文件的使用
单元开篇
.mp4%22%2C%22size%22%3A6553678%2C%22taskId%22%3A%22u5435fad7-8eb8-4be0-922b-d298ac052f5%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481012096-1329864e-987c-4397-a24a-52b83e4737ca.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22kzTXR%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#kzTXR)
文件的类型
.mp4%22%2C%22size%22%3A101602096%2C%22taskId%22%3A%22ua61d7138-0177-4717-9729-2902f25fe67%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481012094-f2d27911-6f3a-4373-a9a9-7a953730c454.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22oZlAw%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#oZlAw)
文件是数据的抽象和集合
- 文件是存储在辅助存储器上的数据序列
- 文件是数据存储的一种形式
- 文件展现形态:文件文本和二进制文件
文本文件 VS 二进制文件
- 文本文件和二进制文件只是文件的展示方式
- 本质上,所有文件都是二进制形式存储
- 形式上,所有文件采用两种方式展示
文本文件:
- 由单一特定编码组成的文件,如 UTF-8 编码
- 由于存在编码,也被看成是存储着的长字符串
- 适用于例如:
.txt文件、.py文件等
二进制文件:
- 直接由比特 0 和 1 组成,没有统一字符编码
- 一般存在二进制 0 和 1 的组织结构,即文件格式
- 适用于例如:
.png文件、.avi文件等
"中国是一个伟大的国家"
tf = open("f.txt", "rt")print(tf.readline()) # "中国是一个伟大的国家"tf.close()
tf = open("f.txt", "rb")print(tf.readline()) # b'"\xe4\xb8\xad\xe5\x9b\xbd\xe6\x98\xaf\xe4\xb8\x80\xe4\xb8\xaa\xe4\xbc\x9f\xe5\xa4\xa7\xe7\x9a\x84\xe5\x9b\xbd\xe5\xae\xb6"'tf.close()
文件的打开和关闭
.mp4%22%2C%22size%22%3A160906872%2C%22taskId%22%3A%22uf3fd705d-f2ac-4ffc-a801-b19be408394%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481012119-299b3d83-7127-4b92-b8e9-c5061476ef70.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22aD9lt%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#aD9lt)
文件处理的步骤:
- 打开
- 操作
- 关闭
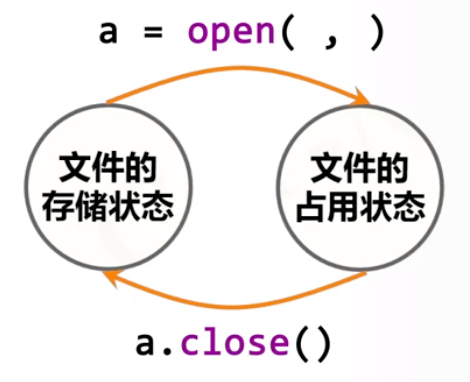
文件的两个状态:
- 存储状态
- 占用状态
在占用状态下,一个程序可以对文件进行唯一的、排他的进行处理,以免出现多个程序同时处理一个文件导致冲突的问题。



f = open("f.txt") # 文本形式、只读模式、默认值f = open("f.txt", "rt") # 文本形式、只读模式、同默认值f = open("f.txt", "w") # 文本形式、覆盖写模式f = open("f.txt", "a+") # 文本形式、追加写模式+ 读文件f = open("f.txt", "a") # 文本形式、追加写模式(不能读)f = open("f.txt", "x") # 文本形式、创建写模式f = open("f.txt", "b") # 二进制形式、只读模式f = open("f.txt", "wb") # 二进制形式、覆盖写模式

回顾上一节的两个读 f.txt 文件的小 demo:

tf = open("f.txt", "rt")print(tf.readline()) # "中国是一个伟大的国家"tf.close()
tf = open("f.txt", "rb")print(tf.readline()) # b'"\xe4\xb8\xad\xe5\x9b\xbd\xe6\x98\xaf\xe4\xb8\x80\xe4\xb8\xaa\xe4\xbc\x9f\xe5\xa4\xa7\xe7\x9a\x84\xe5\x9b\xbd\xe5\xae\xb6"'tf.close()
文件内容的读取
.mp4%22%2C%22size%22%3A100088590%2C%22taskId%22%3A%22udd880086-9bdf-4ecd-8c97-fe54868483f%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481012120-7d13077b-6eb1-4e77-9718-2ff2fd9ca108.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22vIH9a%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#vIH9a)


fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')# 一次读入,统一处理txt = fo.read()fo.close()
fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')# 按数量读入,逐步处理txt = fo.read(2)while txt != "":txt = fo.read(2)fo.close()
fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')# 一次读入,分行处理for line in fo.readline():print(line)fo.close()
fname = input("请输入要打开的文件名称:")fo = open(fname, 'r')# 分行读入,逐行处理for line in fo:print(line)fo.close()
数据的文件写入
.mp4%22%2C%22size%22%3A109999511%2C%22taskId%22%3A%22u257e16bc-cf59-485b-943b-8b424825238%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481012123-290541fe-0109-4650-8a54-085fe829717f.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22lDO8g%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#lDO8g)

<f>.writelines(lines) 将列表中的元素拼接写入到文件 <f> 中,这种做法写入的效果并不会自动完成换行,每一个列表元素会挨着上一个的结尾写入文件。

注意:文件指针
思考:请问为什么示例 1 打印的结果为空,而示例 2 可以将 output.txt 文件中的内容打印出来?
fo = open("output.txt", "w+")ls = ["中国", "法国", "美国"]fo.writelines(ls)# fo.seek(0)for line in fo:print(line)fo.close()'''输出结果为空'''
fo = open("output.txt", "w+")ls = ["中国", "法国", "美国"]fo.writelines(ls)fo.seek(0)for line in fo:print(line)fo.close()'''中国法国美国'''
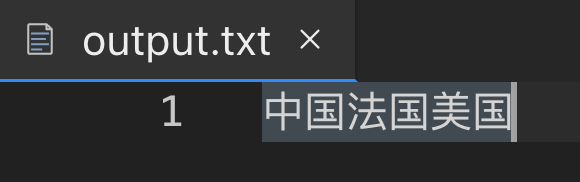
这两个示例都是在操作同一个文件output.txt,并向文件中写入一个字符串列表,然后尝试读取并打印出文件中的内容。
在示例 1 中,你直接在写入后进行了读取,但是没有先设置文件的读取位置(即文件指针),默认文件指针停在文件尾部。当你尝试读取时,因为你已经在文件的尾部,没有更多的内容可以读取,所以输出结果为空。
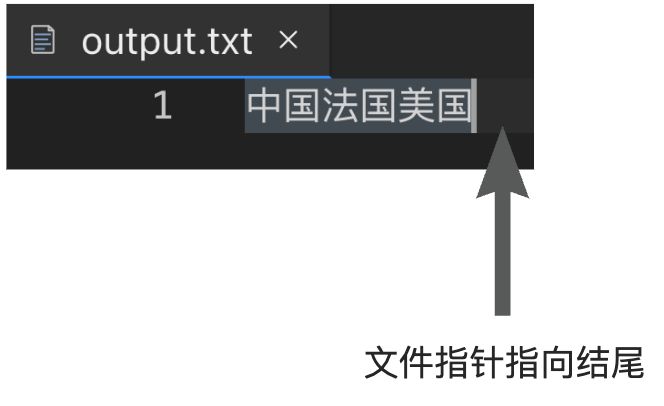
在示例 2 中,写入后,你通过调用**fo.seek(0)**设置了文件的读取位置回到文件的开始位置。然后你读取并打印出文件的内容,这时因为文件指针在文件的开始位置,所以你能读取并打印出文件中的内容,输出中国法国美国。
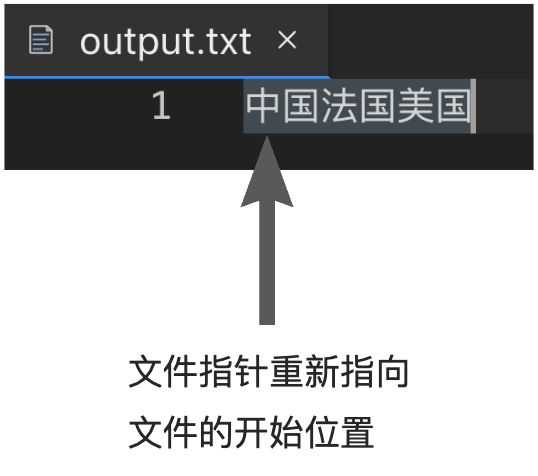
fo.seek(offset)函数用于移动文件读写指针到指定位置,offset表示要移动的字节数,0 表示文件的开头。
所以当你打开文件时,既需要读又需要写,并且希望在写入后立即读取,需要记住设置文件的读取位置,这样才能按照你的期望读取到文件的内容。
单元小结
.mp4%22%2C%22size%22%3A18925447%2C%22taskId%22%3A%22udbd828ac-5f65-4ea5-8766-617fe44341f%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481018750-86081fe1-3173-4d8c-b7f7-07acd49ff52b.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22tW8Nm%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#tW8Nm)
- 文件的使用方式:打开-操作-关闭
- 文本文件&二进制文件,
open( , )和.close() - 文件内容的读取:
.read().readline().readlines() - 数据的文件写入:
.write().writelines().seek()
实例11: 自动轨迹绘制
问题分析
.mp4%22%2C%22size%22%3A26113378%2C%22taskId%22%3A%22ud70c77c3-f0e3-4d9e-9bdd-80d7932d4e1%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481032970-abb00f8b-5a2b-4c5c-bc75-313411392759.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22A4zaV%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#A4zaV)
实例讲解
.mp4%22%2C%22size%22%3A165992749%2C%22taskId%22%3A%22u3eedd0c6-dc56-4c7d-82d4-aa200079c3a%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481049713-ab4a6ade-6a9b-4f1b-87e7-2bf6f408c25c.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22kvtBt%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#kvtBt)
300,0,144,1,0,0300,0,144,0,1,0300,0,144,0,0,1300,0,144,1,1,0300,0,108,0,1,1184,0,72,1,0,1184,0,72,0,0,0184,0,72,0,0,0184,0,72,0,0,0184,1,72,1,0,1184,1,72,0,0,0184,1,72,0,0,0184,1,72,0,0,0184,1,72,0,0,0184,1,720,0,0,0
import turtle as tt.title("自动轨迹绘制")t.setup(800, 600, 0, 0)t.pencolor("red")t.pensize(5)# 数据读取datals = []f = open("data.txt")for line in f:print('line:', line)line = line.replace("\n", "")datals.append(list(map(eval, line.split(","))))print('datals:', datals)f.close()# 自动绘制for i in range(len(datals)):t.pencolor(datals[i][3], datals[i][4], datals[i][5])t.fd(datals[i][0])if datals[i][1]:t.rt(datals[i][2])else:t.lt(datals[i][2])if i == (len(datals) - 1):t.done()"""line: 300,0,144,1,0,0line: 300,0,144,0,1,0line: 300,0,144,0,0,1line: 300,0,144,1,1,0line: 300,0,108,0,1,1line: 184,0,72,1,0,1line: 184,0,72,0,0,0line: 184,0,72,0,0,0line: 184,0,72,0,0,0line: 184,1,72,1,0,1line: 184,1,72,0,0,0line: 184,1,72,0,0,0line: 184,1,72,0,0,0line: 184,1,72,0,0,0line: 184,1,720,0,0,0datals: [[300, 0, 144, 1, 0, 0],[300, 0, 144, 0, 1, 0],[300, 0, 144, 0, 0, 1],[300, 0, 144, 1, 1, 0],[300, 0, 108, 0, 1, 1],[184, 0, 72, 1, 0, 1],[184, 0, 72, 0, 0, 0],[184, 0, 72, 0, 0, 0],[184, 0, 72, 0, 0, 0],[184, 1, 72, 1, 0, 1],[184, 1, 72, 0, 0, 0],[184, 1, 72, 0, 0, 0],[184, 1, 72, 0, 0, 0],[184, 1, 72, 0, 0, 0],[184, 1, 720, 0, 0, 0]]"""
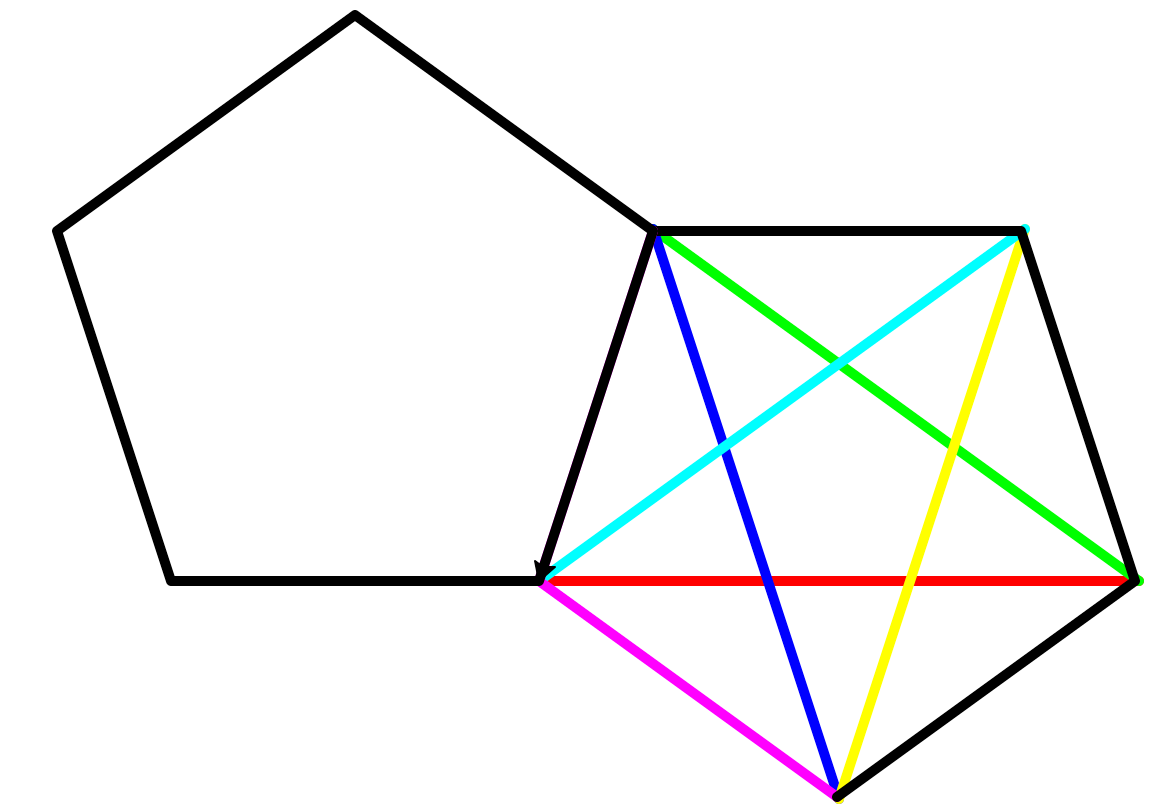
举一反三
.mp4%22%2C%22size%22%3A65157950%2C%22taskId%22%3A%22u65ad1779-22e9-4f76-aede-dd408127865%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481056080-40826c26-7cb0-40f5-9480-86ef710a1683.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22SuXzr%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#SuXzr)
- 自动化思维:数据和功能分离,数据驱动的自动运行
- 接口化设计:格式化设计接口,清晰明了
- 二维数据应用:应用维度组织数据,二维数据最常用
一维数据的格式化和处理
单元开篇
.mp4%22%2C%22size%22%3A8823308%2C%22taskId%22%3A%22u8e7d570d-b1df-4fd0-914e-0aec339e60e%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481056083-2549b5c1-87b4-4df3-ad7f-30bcc037407d.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22gsq4u%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#gsq4u)
数据组织的维度
.mp4%22%2C%22size%22%3A70946639%2C%22taskId%22%3A%22ud456a84e-c6da-43fd-81aa-c7f9e7061dc%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481057344-65f27f19-882e-4309-a5d2-2c5e076511dd.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22wW9rs%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#wW9rs)

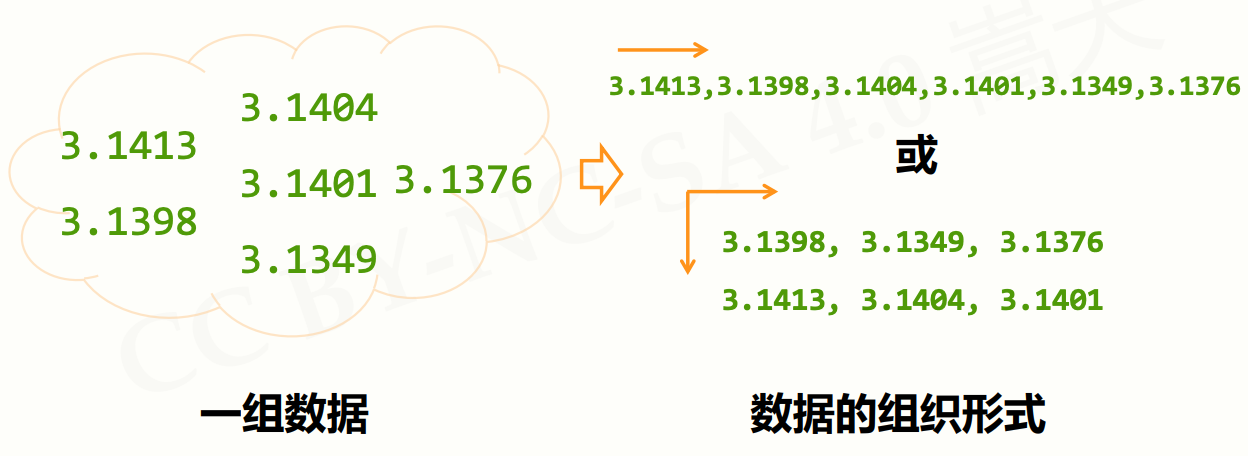
一维数据:由对等关系的有序或无序数据构成,采用线性方式组织
在 Python 中,一维数据对应的数据类型:
- 列表
- 数组
- 集合
- ……
二维数据:由多个一维数据构成,是一维数据的组合形式
多维数据:由一维或二维数据在新维度上扩展形成
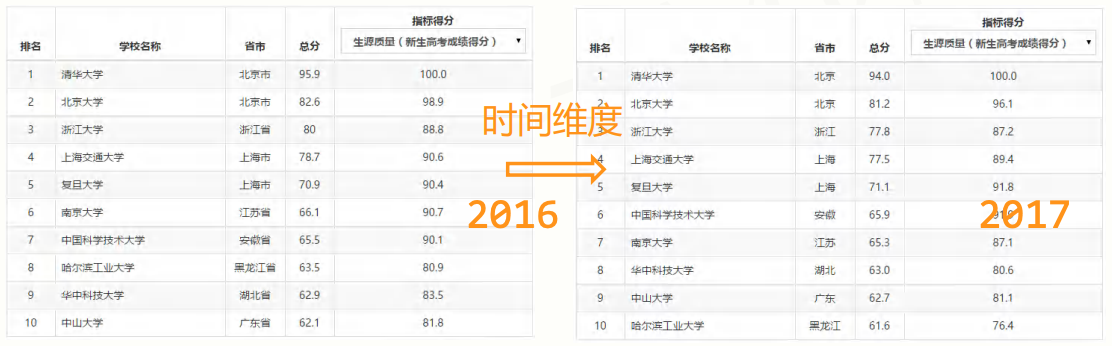
高纬数据:仅利用最基本的二元关系展示数据间的复杂结构

数据的操作周期:
一维数据的表示
.mp4%22%2C%22size%22%3A15727873%2C%22taskId%22%3A%22ufef68f59-43c9-4882-af8f-5eb917a6554%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481063830-46529d10-2514-430e-b165-a38c709deb26.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22x0viD%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#x0viD)
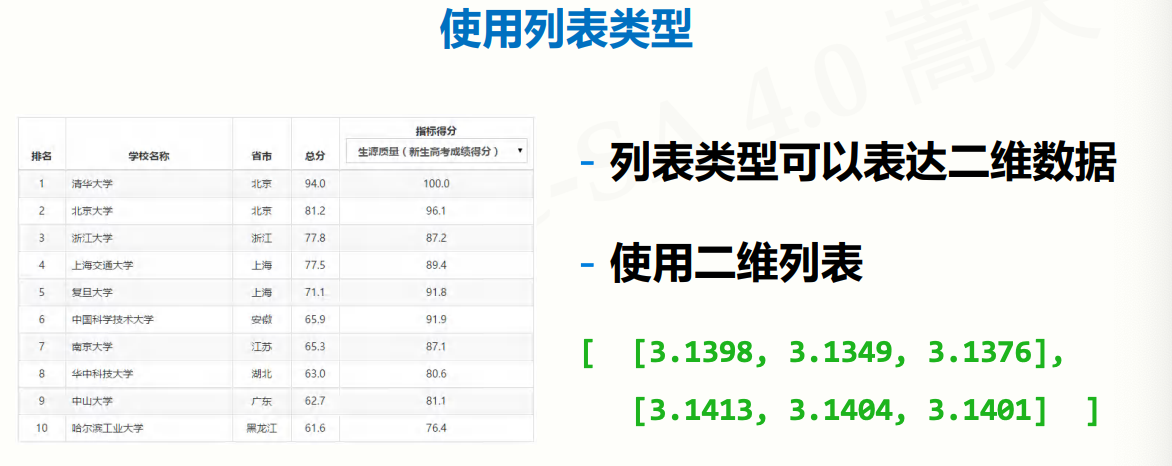
如果数据间有序:使用列表类型
ls = [3.1398, 3.1349, 3.1376]
- 列表类型可以表达一维有序数据
- for 循环可以遍历数据,进而对每个数据进行处理
如果数据间无序:使用集合类型
st = {3.1398, 3.1349, 3.1376}
- 集合类型可以表达一维无序数据
- for 循环可以遍历数据,进而对每个数据进行处理
一维数据的存储
.mp4%22%2C%22size%22%3A31478602%2C%22taskId%22%3A%22u18932164-f320-4b83-b567-078c163d9b2%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481074878-519e7d8f-b6b4-46f3-b6e3-3832b5848010.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22udUSZ%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#udUSZ)



一维数据的处理
.mp4%22%2C%22size%22%3A46903463%2C%22taskId%22%3A%22u374197e6-aa25-40a4-a412-c485e44133f%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481075824-8ce2e4cf-231c-412b-8683-5a39b333e93a.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22XA2KD%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#XA2KD)
从空格分隔的文件中读入数据
中国 美国 日本 德国 法国 英国 意大利
filename = "1.txt"f = open(filename)txt = f.read()ls = txt.split()print('ls:', ls) # ls: ['中国', '美国', '日本', '德国', '法国', '英国', '意大利']f.close()
从特殊符号分隔的文件中读入数据
中国$美国$日本$德国$法国$英国$意大利
filename = "1.txt"f = open(filename)txt = f.read()ls = txt.split('$')print('ls:', ls) # ls: ['中国', '美国', '日本', '德国', '法国', '英国', '意大利']f.close()
采用空格分隔方式将数据写入文件
ls = ["中国", "美国", "日本"]fname = "1.txt"f = open(fname, "w")f.write(" ".join(ls))f.close()
中国 美国 日本
采用特殊分隔方式将数据写入文件
ls = ["中国", "美国", "日本"]fname = "1.txt"f = open(fname, "w")f.write("$".join(ls))f.close()
中国$美国$日本
单元小结
.mp4%22%2C%22size%22%3A13071662%2C%22taskId%22%3A%22u9c497d66-ae8b-42aa-ad71-880aea69c1c%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481084230-d132becd-80fb-4322-aa8c-30c507ea371d.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22CuZlO%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#CuZlO)
- 数据的维度:一维、二维、多维、高维
- 一维数据的表示:列表类型(有序)和集合类型(无序)
- 一维数据的存储:空格分隔、逗号分隔、特殊符号分隔
- 一维数据的处理:字符串方法 .split() 和 .join()
二维数据的格式化和处理
单元开篇
.mp4%22%2C%22size%22%3A9484313%2C%22taskId%22%3A%22u9984d026-c1a0-493f-810b-b0c4fb4aec6%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481088352-99c7e41f-c16c-47b7-9866-d2c3563d73b0.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22vJOI4%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#vJOI4)
二维数据的表示
.mp4%22%2C%22size%22%3A37525904%2C%22taskId%22%3A%22u4ac984ba-a020-40e8-9d10-2ac1d551259%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481091232-32944cdf-f128-4233-8157-192149bda9f7.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22th7mB%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#th7mB)
二维数据的遍历
- 使用两层 for 循环遍历每个元素
- 外层列表中每个元素可以对应一行,也可以对应一列
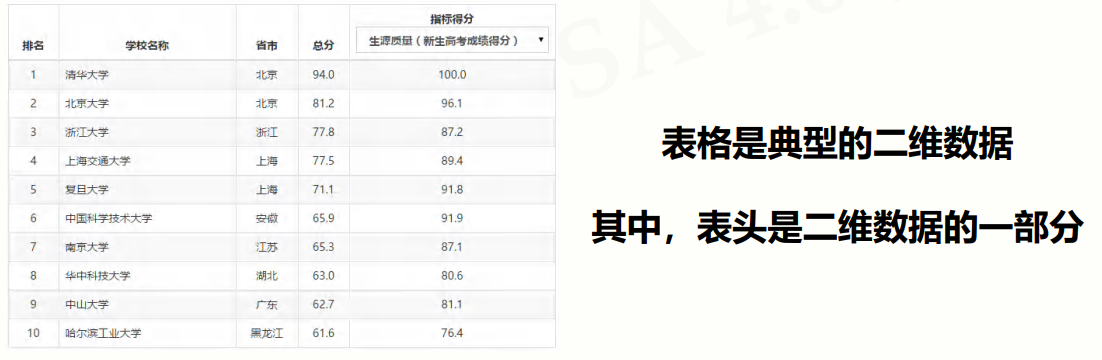
数据维度是数据的组织形式

CSV 格式与二维数据存储
.mp4%22%2C%22size%22%3A85721527%2C%22taskId%22%3A%22u7d64a2d1-aefd-470a-8c97-e38aa790361%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481092557-6e4c8887-b79a-4f7a-afaf-1c913e998be0.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22DhmfH%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#DhmfH)
CSV:Comma-Separated Values
逗号分隔的值
- 国际通用的一、二维数据存储格式,一般
**.csv**扩展名 - 每行一个一维数据,采用逗号分隔,无空行
- Excel 和一般编辑软件都可以读入或另存为 csv 文件
- 如果某个元素缺失,逗号仍要保留
- 二维数据的表头可以作为数据存储,也可以另行存储
- 逗号为英文半角逗号,逗号与数据之间无额外空格
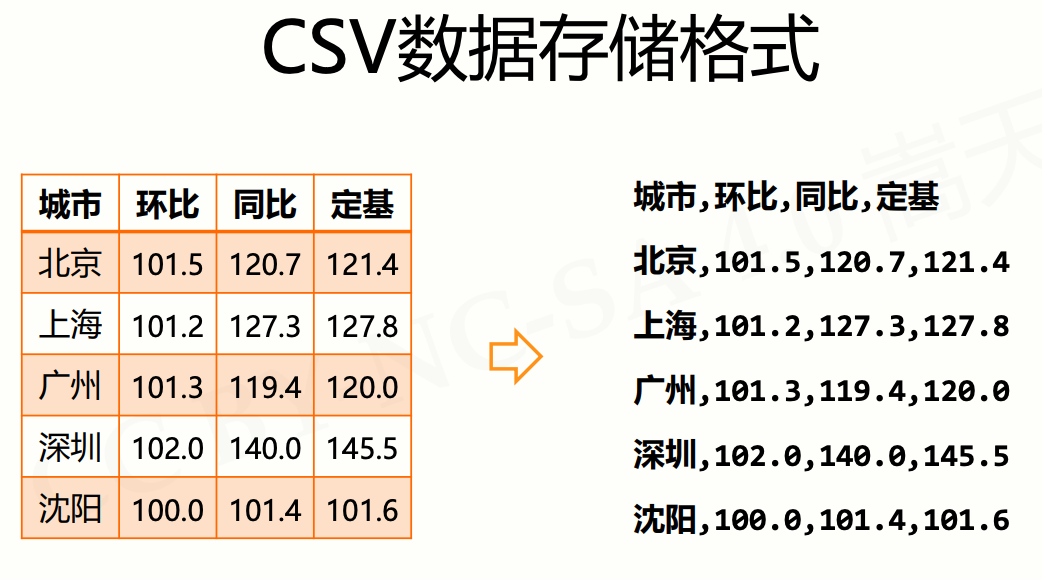
二维数据的存储
- 按行存
- 按列存
- 按行存或者按列存都可以,具体由程序决定
- 一般索引习惯:
ls[row][column],先行后列 - 根据一般习惯,外层列表每个元素是一行,按行存
二维数据的处理
.mp4%22%2C%22size%22%3A41174244%2C%22taskId%22%3A%22u9cdb806b-f38a-4337-9c72-5ffe12e4207%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481093968-46af58dc-34d2-41b1-89f5-967b9309c194.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22zHjxc%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#zHjxc)
从 CSV 格式的文件中读入数据
城市,环比,同比,定基北京,101.5,120.7,121.4上海,101.2,127.3,127.8广州,101.3,119.4,120.0深圳,102.0,140.0,145.5沈阳,100.0,101.4,101.6
fname = "1.csv"fo = open(fname)ls = []for line in fo:line = line.replace("\n", "")ls.append(line.split(","))fo.close()print(ls)"""[["城市", "环比", "同比", "定基"],["北京", "101.5", "120.7", "121.4"],["上海", "101.2", "127.3", "127.8"],["广州", "101.3", "119.4", "120.0"],["深圳", "102.0", "140.0", "145.5"],["沈阳", "100.0", "101.4", "101.6"],]"""
将数据写入 CSV 格式的文件
fname = "output.csv"ls = [["1", "2", "3"], ["4", "5", "6"], ["7", "8", "9"]] # 二维列表f = open(fname, "w")for item in ls:f.write(",".join(item) + "\n")f.close()
1,2,34,5,67,8,9
单元小结
.mp4%22%2C%22size%22%3A19491036%2C%22taskId%22%3A%22u8be7f0e2-9a04-4e03-95cd-a7ff53c44c5%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481095097-a895aca6-89ca-4971-b6eb-f220de98db35.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22wU5iK%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#wU5iK)
- 二维数据的表示:列表类型,其中每个元素也是一个列表
- CSV 格式:逗号分隔表示一维,按行分隔表示二维
- 二维数据的处理:
for 循环、.split()、.join()
模块6: wordcloud 库的使用
:::warning 温 馨 提 示
微软雅黑字体压缩包:msyh.ttc.zip
在教程提供的一些生成词云的示例中,需要用到 msyh.ttc 字体,若程序找不到这个字体文件,那么运行时会报错。
如果示例在运行时出现找不到字体的报错,需要先下载字体文件,然后把文件丢到当前程序所在目录即可。 :::
wordcloud 库基本介绍
.mp4%22%2C%22size%22%3A16601078%2C%22taskId%22%3A%22u38092530-5db2-476f-bf8f-3f7d3d26cb7%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481107554-9c0ed8f1-9546-4035-a83d-96e1bf8c41a1.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22khR4T%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#khR4T)
- wordcloud github:https://github.com/amueller/word_cloud
- wordcloud doc:https://amueller.github.io/word_cloud/
wordcloud 是优秀的词云展示第三方库
词云以词语为基本单位,更加直观和艺术地展示文本
pip install wordcloud
wordcloud 库使用说明
.mp4%22%2C%22size%22%3A213870062%2C%22taskId%22%3A%22u3c37ed4b-03cd-4b1c-a444-409dd23d1a6%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481108223-2b98452b-6d01-4c4f-b58d-8546418d5c96.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22fGVSJ%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#fGVSJ)
wordcloud 库把词云当作一个 WordCloud 对象
wordcloud.WordCloud()代表一个文本对应的词云- 可以根据文本中词语出现的频率等参数绘制词云
- 词云的绘制形状、尺寸和颜色都可以设定
w = wordcloud.WordCloud()
- 以 WordCloud 对象为基础
- 配置参数、加载文本、输出文件
wordcloud 库常规方法

使用 wordcloud 库的 3 个步骤:
- 配置对象参数
- 加载词云文本
- 输出词云文件
import wordcloudc = wordcloud.WordCloud() # 1. 配置对象参数c.generate("wordcloud by Python") # 2. 加载词云文本c.to_file("pywordcloud.png") # 3. 输出词云文件


配置对象参数
w = wordcloud.WordCloud(<参数>)




import wordcloudtxt = "life is short, you need python"w = wordcloud.WordCloud(background_color="white")w.generate(txt)w.to_file("pywcloud.png")

import jiebaimport wordcloudtxt = "程序设计语言是计算机能够理解和\识别用户操作意图的一种交互体系,它按照\特定规则组织计算机指令,使计算机能够自\动进行各种运算处理。"w = wordcloud.WordCloud(width=1000, font_path="msyh.ttc", height=700)w.generate(" ".join(jieba.lcut(txt))) # 中文想要先分词并组成空格字符串w.to_file("pywcloud.png")

实例12: 政府工作报告词云
问题分析
.mp4%22%2C%22size%22%3A39144229%2C%22taskId%22%3A%22ub97fc1dd-8d11-4812-b751-2506f04c440%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481108913-741b4af7-ac7b-43d2-a6b5-2d92efae009e.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22tYG9Z%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#tYG9Z)


https://python123.io/resources/pye/新时代中国特色社会主义.txt

https://python123.io/resources/pye/关于实施乡村振兴战略的意见.txt
实例讲解(上)
(1).mp4%22%2C%22size%22%3A104164060%2C%22taskId%22%3A%22ue63d7a6b-1650-4061-9334-30fdf3d8005%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481111854-21bd14a2-884e-4036-9a70-148f73f9b46c.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22VrzMh%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#VrzMh)
import jiebaimport wordcloudf = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc")w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc")w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", max_words=15)w.generate(txt)w.to_file("grwordcloud.png")

import jiebaimport wordcloudf = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", max_words=15)w.generate(txt)w.to_file("grwordcloud.png")

实例讲解(下)
(1).mp4%22%2C%22size%22%3A24756949%2C%22taskId%22%3A%22u682055b5-4d01-4f79-b79b-88b7e43310e%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481117225-ef9dcd37-0814-42fa-ba64-447d7828c148.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22wY5ME%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#wY5ME)
素材:


import jiebaimport wordcloudimport imageiomask = imageio.imread("fivestart.png")excludes = {}f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudimport imageiomask = imageio.imread("fivestart.png")excludes = {}f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudfrom imageio import imreadmask = imread("chinamap.jpg")excludes = {}f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

import jiebaimport wordcloudimport imageiomask = imageio.imread("chinamap.jpg")excludes = {}f = open("关于实施乡村振兴战略的意见.txt", "r", encoding="utf-8")t = f.read()f.close()ls = jieba.lcut(t)txt = " ".join(ls)w = wordcloud.WordCloud(width=1000, height=700, background_color="white", font_path="msyh.ttc", mask=mask)w.generate(txt)w.to_file("grwordcloudm.png")

举一反三
.mp4%22%2C%22size%22%3A31176329%2C%22taskId%22%3A%22u4e29068d-e49d-4232-95da-6631f8b9eaa%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481125150-6231559a-6b2a-42da-822d-a48c419b0226.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22d1Euf%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#d1Euf)
作业与练习
.mp4%22%2C%22size%22%3A5450168%2C%22taskId%22%3A%22u58afed12-6c93-42f6-9a81-aca364dc44c%22%2C%22taskType%22%3A%22upload%22%2C%22url%22%3Anull%2C%22cover%22%3Anull%2C%22videoId%22%3A%22inputs%2Fprod%2Fyuque%2F2023%2F2331396%2Fmp4%2F1688481126082-77e139af-c325-4cc8-9c66-72e0b95e44d9.mp4%22%2C%22download%22%3Afalse%2C%22__spacing%22%3A%22both%22%2C%22id%22%3A%22OkpUt%22%2C%22margin%22%3A%7B%22top%22%3Atrue%2C%22bottom%22%3Atrue%7D%2C%22card%22%3A%22video%22%7D#OkpUt)
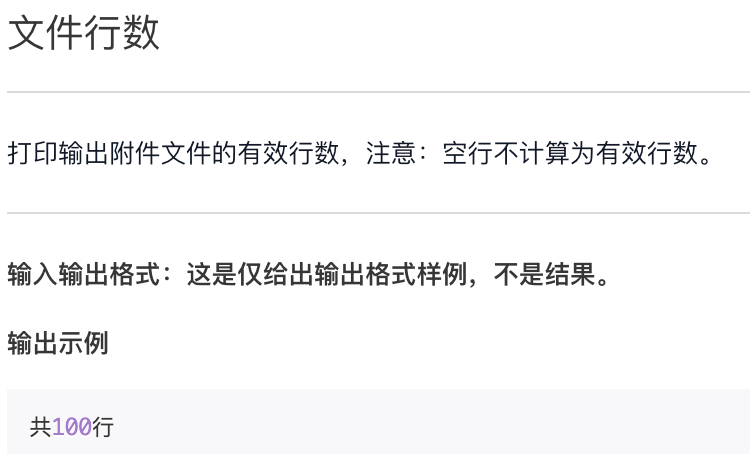
文件行数
附件:latex.log
f = open("latex.log")s = 0for line in f:line = line.strip("\n")if len(line) == 0:continues += 1print("共{}行".format(s)) # 共4951行
需要注意:for line in f 方式获得的每行内容(在变量line中)包含换行符,所以,要通过 strip() 函数去掉换行符后再进行统计。这里,空行指没有字符的行。
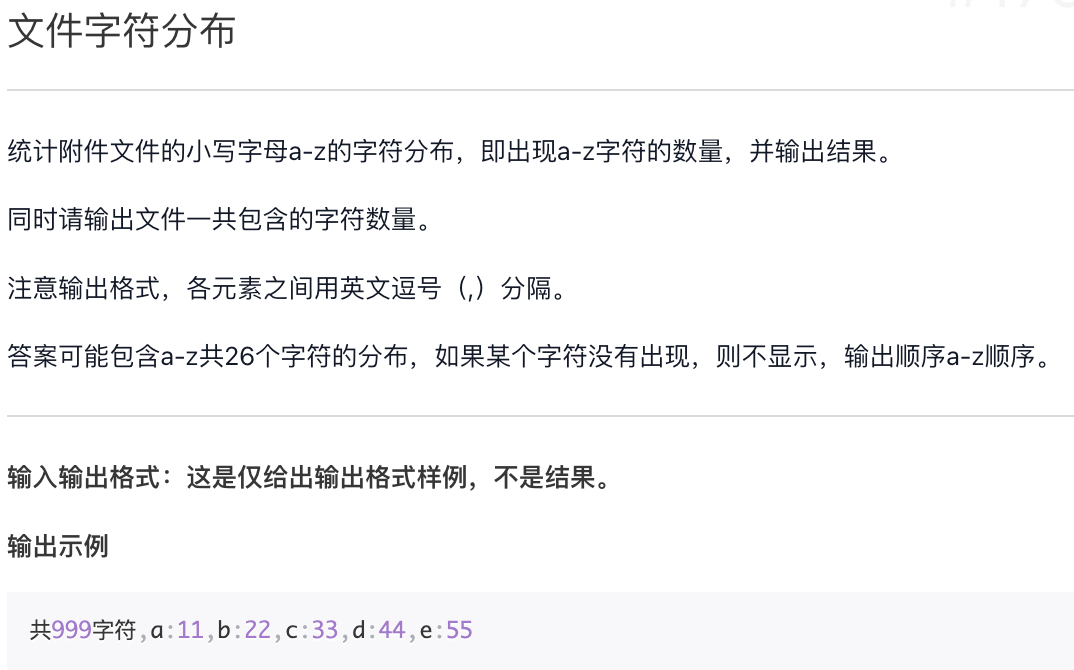
文件字符分布
附件:latex.log
f = open("latex.log")cc = 0# 初始化一个记录 26 个字母出现次数的字典d = {}for i in range(26):d[chr(ord("a") + i)] = 0for line in f:for c in line:d[c] = d.get(c, 0) + 1cc += 1print("共{}字符".format(cc), end="")for i in range(26):if d[chr(ord("a") + i)] != 0:print(",{}:{}".format(chr(ord("a") + i), d[chr(ord("a") + i)]), end="")"""共244019字符,a:9620,b:525,c:8769,d:1046,e:15585,f:8653,g:4548,h:8882,i:17587,j:62,k:122,l:9090,m:736,n:25730,o:13812,p:961,q:132,r:13755,s:12948,t:14049,u:4850,v:294,w:427,x:276,y:359,z:4"""
使用 ord(‘a’)+i 配合 range()函数 可以遍历一个连续的字符表。
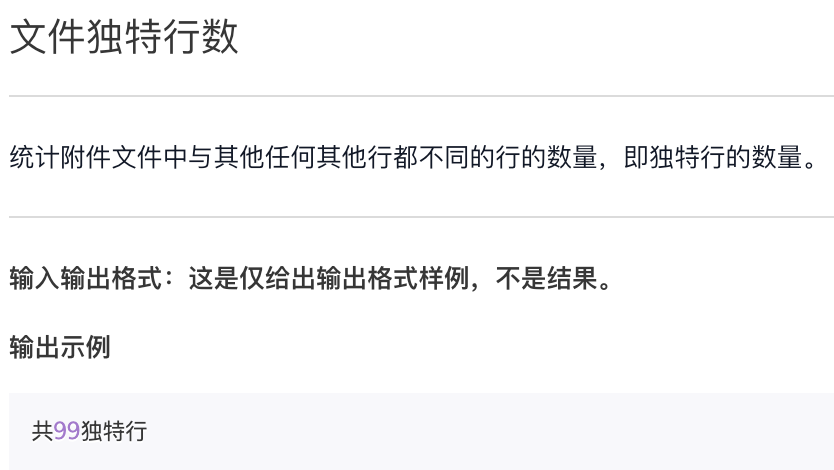
文件独特行数
附件:latex.log
f = open("latex.log")ls = f.readlines()s = set(ls)for i in s:ls.remove(i)t = set(ls)print("共{}独特行".format(len(s) - len(t))) # 共291独特行
记住:如果需要”去重”功能,请使用集合类型。
**ls.remove()** 可以去掉某一个元素,如果该行是独特行,去掉该元素后将不在集合 t 中出现。
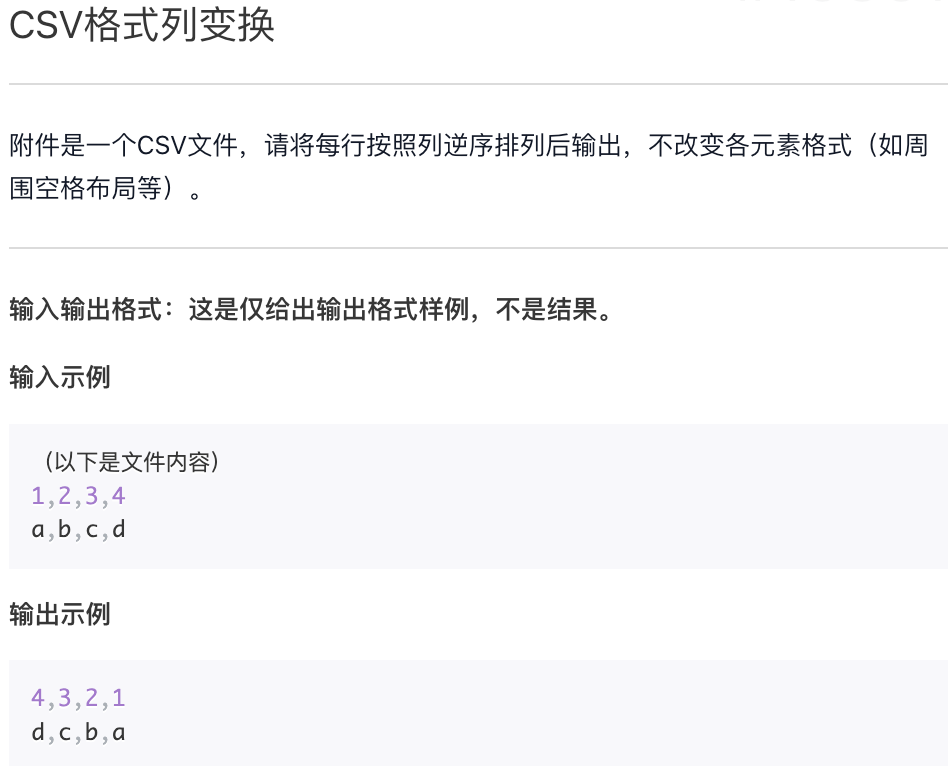
CSV 格式列变换
附件:data.csv
1,2,3,4,5,6,78, 3, 2, 7, 1, 4, 6, 56, 1, 3, 8, 5, 7, 4, 2'a','b','c','x','y','z','i','j','k''k', 'b', 'j', 'c', 'i', 'y', 'z', 'a', 'x''z', 'c', 'b', 'a', 'k', 'i', 'j', 'y', 'x''a', 'y', 'b', 'x', 'z', 'c', 'i', 'j', 'k'5, 2, 4, 7, 1, 6, 8, 3
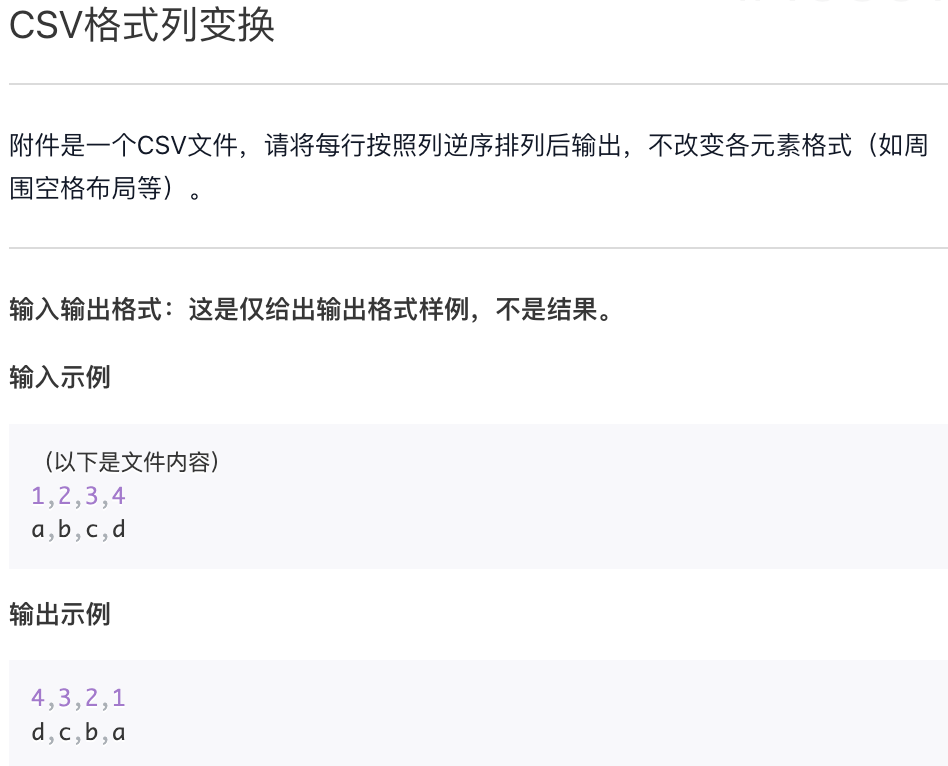
f = open("data.csv")for line in f:line = line.strip("\n")ls = line.split(",")ls = ls[::-1]print(",".join(ls))f.close()"""7,6,5,4,3,2,15, 6, 4, 1, 7, 2, 3,82, 4, 7, 5, 8, 3, 1,6'k','j','i','z','y','x','c','b','a''x', 'a', 'z', 'y', 'i', 'c', 'j', 'b','k''x', 'y', 'j', 'i', 'k', 'a', 'b', 'c','z''k', 'j', 'i', 'c', 'z', 'x', 'b', 'y','a'3, 8, 6, 1, 7, 4, 2,5"""
CSV 格式数据清洗
附件:data.csv
1,2,3,4,5,6,78, 3, 2, 7, 1, 4, 6, 56, 1, 3, 8, 5, 7, 4, 2'a','b','c','x','y','z','i','j','k''k', 'b', 'j', 'c', 'i', 'y', 'z', 'a', 'x''z', 'c', 'b', 'a', 'k', 'i', 'j', 'y', 'x''a', 'y', 'b', 'x', 'z', 'c', 'i', 'j', 'k'5, 2, 4, 7, 1, 6, 8, 3
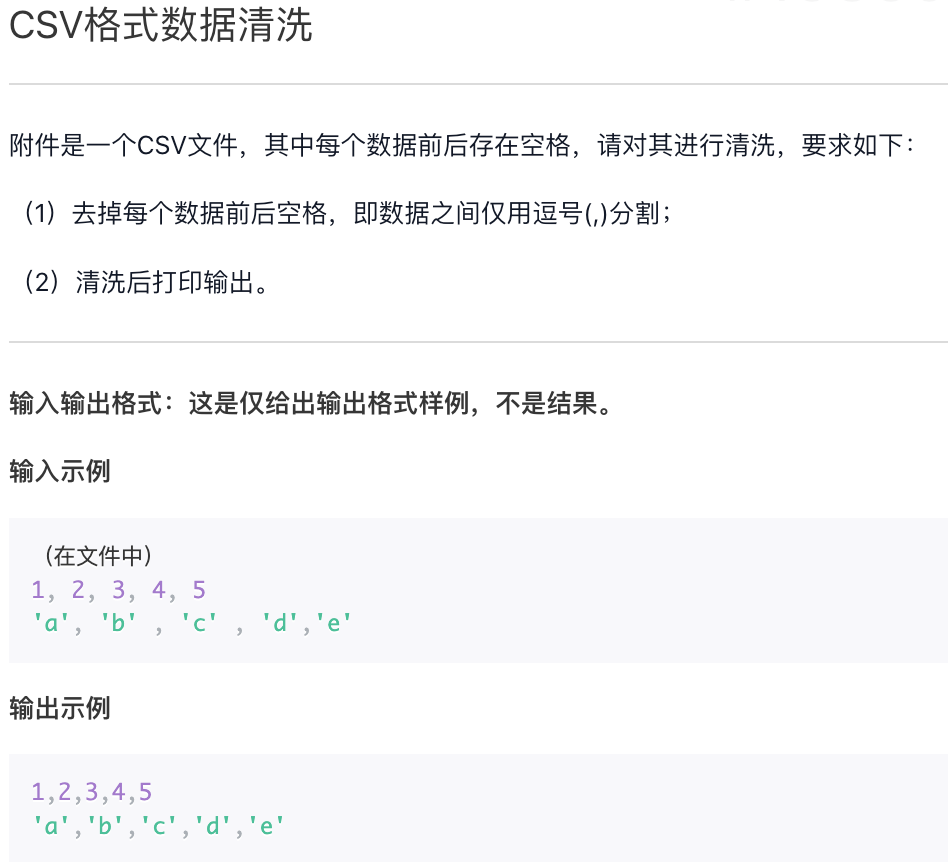
f = open("data.csv")s = f.read()s = s.replace(" ", "")print(s)f.close()"""1,2,3,4,5,6,78,3,2,7,1,4,6,56,1,3,8,5,7,4,2'a','b','c','x','y','z','i','j','k''k','b','j','c','i','y','z','a','x''z','c','b','a','k','i','j','y','x''a','y','b','x','z','c','i','j','k'5,2,4,7,1,6,8,3"""
该 CSV 文件的每个数据中不包含空格,因此,可以通过替换空格方式来清洗。如果数据中包含空格,该方法则不适用。
补充
计算机中的“文件”是什么?
在计算机科学中,文件是一个数据的存储单元。文件通常存储在某种形式的数据存储设备上,例如硬盘,SSD,USB 闪存驱动器,或网络存储设备。在大多数操作系统中,文件都是用于组织和存储数据的主要方式。
文件可以包含任何类型的数据,包括文本、图像、音频和视频数据。文件通常以某种特定的文件格式存储,这个格式定义了文件的结构和内容。例如,.txt 文件是纯文本格式,.jpg 文件是一种图像格式,.mp3 文件是一种音频格式。
每个文件都有一个名字和一个路径,这可以帮助用户和程序找到和访问文件。文件名通常由文件的“基本名字”和一个“扩展名”组成,扩展名通常用来表示文件的格式。例如,在文件名“image.jpg”中,“image”是基本名字,“.jpg”是扩展名。
文件也有一些元数据,称为文件属性,这些属性包括文件的创建日期,最后修改日期,大小,以及文件的权限等等。
因此,简单来说,计算机中的“文件”就是存储在某种媒介上的一组数据,它有一个名称,一个位置(路径),一个格式,以及一些关于该文件的元数据。
“文件后缀”的作用是什么?
文件后缀(也被称为文件扩展名)主要有两个作用:
- 识别文件类型:文件后缀可以帮助操作系统和应用程序确定文件的类型。例如,.docx 文件通常表示一个 Microsoft Word 文档,.jpg 或 .png 文件表示图像文件,.mp3 表示音频文件,.exe 表示可执行文件等等。这样,操作系统和应用程序就能知道如何正确地打开和处理这个文件。
- 关联默认应用程序:文件后缀还用于关联默认应用程序。操作系统通常会根据文件的扩展名来确定哪个程序被设置为默认打开该类型的文件。例如,如果你双击一个 .pdf 文件,系统就会打开与 .pdf 文件关联的默认应用程序(例如 Adobe Reader 或其他 PDF 阅读器)。
注意,虽然文件后缀通常可以表示文件的类型,但并不是绝对的。有的时候,文件的内容可能并不符合其后缀名。例如,如果你将一个图片文件的后缀从 .jpg 改为 .txt,那么操作系统会认为它是一个文本文件,尝试用文本编辑器打开它,但实际上它的内容仍然是图像数据。因此,在处理未知来源的文件时,不能仅仅依赖文件后缀来判断文件类型。
文件文件 VS 二进制文件
在计算机中,文件通常被分类为文本文件和二进制文件。这两种类型的文件有许多基本的区别:
文本文件:
文本文件只包含字符的可打印表示,如字母,数字和符号,还包括一些不可打印的字符,如制表符、换行符和回车符。这些都是 ASCII 或 Unicode 字符集中的字符。你可以使用一个简单的文本编辑器(如 Notepad,Vim 或 Emacs)打开和阅读这些文件。最常见的文本文件扩展名包括 .txt, .json, .xml, .html, .css, .js, .md 等。
二进制文件:
二进制文件包含了除文本字符之外的数据,或者说它们包含了特定格式的编码数据。这种文件类型通常包含一种或多种用于特定目的的数据类型,如图像、音频、视频或可执行程序等。如果你试图用文本编辑器打开一个二进制文件,你会看到一些无法解读的字符,因为它们并不一定属于人类可读的字符集。最常见的二进制文件扩展名包括 .jpg, .png, .exe, .class, .jar, .mp3 等。
总的来说,文本文件和二进制文件的主要区别在于它们的内容和如何解读这些内容。
- 文本文件通常只包含人类可读的文本
- 二进制文件包含编码的数据,这些数据需要特定的软件才能正确解读
在 Python 中,你会根据文件的内容和你打算如何使用这些内容来决定以文本模式还是二进制模式打开文件。
文本模式:
当你在处理人类可读的字符数据时,你会使用文本模式。这包括读写如.txt,.json,.xml,.csv,.py等格式的文件。这些文件通常包含像字母,数字和符号等可打印字符,以及一些非打印字符,如制表符,换行符和回车符。
例如,如果你正在编写一个程序来读取和修改一个 txt 文件(这是一个文本文件),那么你会以文本模式打开这个文件。
二进制模式:
当你在处理非文本文件,如图像,音频,视频或可执行文件等时,你需要以二进制模式打开文件。同样,当你需要读取或写入二进制数据,如字节串或字节对象时,你也应该使用二进制模式。
例如,如果你正在编写一个程序来处理图像(这是一个二进制文件),那么你会以二进制模式打开这个文件。
这些模式都非常重要,因为它们决定了 Python 如何读取和写入文件数据。
- 在文本模式下,Python 会处理文件的编码和解码,它会自动处理换行符的转换(在 Unix 和 Windows 之间)。
- 在二进制模式下,不会进行这些额外的处理,数据被原封不动地读取或写入。
“文件句柄”是什么意思?
“文件句柄”是一个抽象概念,是一个代表或引用打开的文件的值。
当你打开一个文件时,操作系统会返回一个文件句柄,你可以将其视为打开文件的 “句柄”或者”标识“,这个句柄可以用来进行后续的文件操作,比如读取、写入或者关闭文件。
在 Python 中,当你使用 open 函数打开一个文件时,open 函数会返回一个文件对象,这个文件对象就是所谓的 “文件句柄”。你可以使用这个文件对象来读取、写入或者关闭文件。
f = open('myfile.txt', 'r') # 'f' 就是一个文件句柄content = f.read() # 使用文件句柄读取文件f.close() # 使用文件句柄关闭文件
在这个例子中,f 就是一个文件句柄,它是 open 函数返回的文件对象。我们可以使用 f 来进行后续的文件操作。
比如,当教程中提到 <文件名>.close() 其中的 <文件名> 就是文件句柄,其实是在说使用你之前得到的文件句柄(文件对象)来关闭文件。
文件的 open、close
在 Python 中,当你使用 **open** 函数打开文件以后,最好是显式地调用 **close** 方法关闭文件。这是因为:
- 如果你忘记关闭文件,Python 的垃圾回收器最终会销毁对象并关闭打开的文件,但是你不能确定这会在什么时候发生。这意味着文件可能会在你不希望的时候保持打开状态。
- 留下打开的文件可能会导致资源泄露。操作系统通常会限制在同一时间可以打开的文件数量,如果你打开的文件过多并且忘记关闭,可能会达到这个限制。
- 文件在关闭之前可能不会立即写入磁盘。许多系统为了效率,在写入文件时,会先将数据保存在缓存中,然后在一个合适的时间写入磁盘。如果你没有正确关闭文件,可能会导致数据丢失。
在 Python 程序结束后,Python 解释器会尝试关闭所有未关闭的文件,但是依赖这个行为是不好的编程实践,因为你不能确定文件何时会被关闭。
为了确保文件总是被正确关闭,你可以使用 with 语句来打开文件,这样文件会在 with 代码块结束时自动关闭,无论是否发生异常:
with open('myfile.txt') as f:content = f.read()# 在这里,文件已经被关闭,你可以放心地继续你的代码。
这是一种更安全的打开和关闭文件的方式,推荐在处理文件时使用这种方式。
“CSV 格式数据”是什么?
CSV(Comma-Separated Values)通常被称为逗号分隔值,这是一种简单的文件格式,用于存储表格数据,比如一个电子表格或数据库。CSV 是一种广泛支持的格式,可以由任何电子表格程序阅读,如 Microsoft Excel、OpenOffice Calc 和 Google Spreadsheets。
在 CSV 中,数据表格以纯文本形式存储,其中每一行都是一个数据记录。每条记录由一个或多个字段组成,字段之间由逗号分隔。第一行通常是标题行,定义了各字段的名字。
例如,一个包含名字和电子邮件地址的简单CSV文件可能看起来像这样:
Name,EmailAlice,alice@example.comBob,bob@example.com
这里,“Name”和“Email”是字段名,”Alice”和”Bob”以及对应的电子邮件地址是数据记录。
需要注意的是,虽然“CSV”代表“逗号分隔值”,但许多CSV文件使用其他字符,如制表符或空格,来分隔值。这种情况下,这样的文件仍然被认为是CSV文件。

若有收获,就点个赞吧
0 人点赞
